


Data is now an essential asset to many organizations in various sectors. Nevertheless, there are many organizations that are collecting data faster than they can process it. Data collection and manipulation techniques influence business operation decisions.
Since the quality of the input affects the output, it becomes necessary to ensure that your system receives good quality data. And this is why you need a good data ingestion pipeline architecture to promote the delivery of actionable insights.
For this guide, we will shed light on data ingestion pipelines, types of data ingestion, and common use cases.
What is Data Ingestion?
One of the most common questions people ask when trying to understand the ingestion pipeline is “what is data ingestion?”
The term data ingestion describes the process of collecting, sorting, and organizing data from various sources into a central storage – like a datahub or warehouse. This process marks the first step in preparing “raw data” for further processing and interpretation. Data ingestion is a very important step in the pipeline as it is the stage where data is collected from various sources that will affect how businesses gain product insights and competitive advantage.
Some of the common data sources for the pipeline are:
- Databases
- Internet of Things
- Data centers
- Social media platforms
- API
- Third party data providers
- SaaS applications
Benefits of Data Ingestion
Every business regardless of size can benefit from data ingestion as it provides insight on market trends, consumer sentiments, innovative strategies, and more. Here are some of the most common benefits of data ingestion:
Data Availability
One of the benefits of data ingestion is that it eliminates the need for data silos. This promotes data availability for analysis by aggregating data from various sources into a single central source.
Scalability
As businesses grow, so does their need for good quality data. Therefore, data ingestion pipelines play a central role in handling large volumes of data while ensuring validity, accuracy, and reliability.
Real-time Analytics
Another benefit of data ingestion pipeline is that data is processed immediately or in batches, which provides access to updated insights. As a result, businesses can react quickly to trends and make timely decisions that can affect overall profit margin.
Efficiency
Since data ingestion pipelines are automated, it eliminates the need for manual data handling. This saves time and resources by streamlining the process of importing and storing data while the team focuses on other priority tasks.
Types of Data Ingestion
Collecting data from different sources into a central storage sounds quite simple. However, it can be just a little bit more complicated, especially for the data pipeline. Below are the most common types of data ingestion:
Batch Ingestion
This is the process whereby a large volume of data is collected at particular intervals. These intervals can be hourly, daily, or even weekly, depending on your needs for collecting data. Batch data ingestion is therefore suitable for use by those businesses that do not require real-time data for decision-making.
These are the kind of businesses that can comfortably operate and make decisions based on periodic data updates.
Real-Time Ingestion
This technique requires that the data be received at the exact time it is created. This technique, therefore, allows for the receipt of fresh data insights, which are very important for decision-making. Real-Time Ingestion helps to reduce the delay between the receipt and the processing of the data. Some of the use cases of real-time data are fraud detection, data processing from sensors, and updating dashboards in real-time. Real-time data ingestion pipeline can process data in real-time or in chunks while it is being extracted. Although this technique provides fresh data, handling errors and scalability is a complex issue.
Lambda Architecture
Lambda architecture combines batch and real-time ingestion to offer a balance of speed and accuracy. The batch data provides comprehensive historical trends while real-time data offers insights on current activities.
Lambda approach is often used in situations that require handling huge volumes of data with high accuracy. Subsequently, it allows businesses to respond quickly to current events without losing the knowledge of previous market events.
What is the Data Ingestion Pipeline?
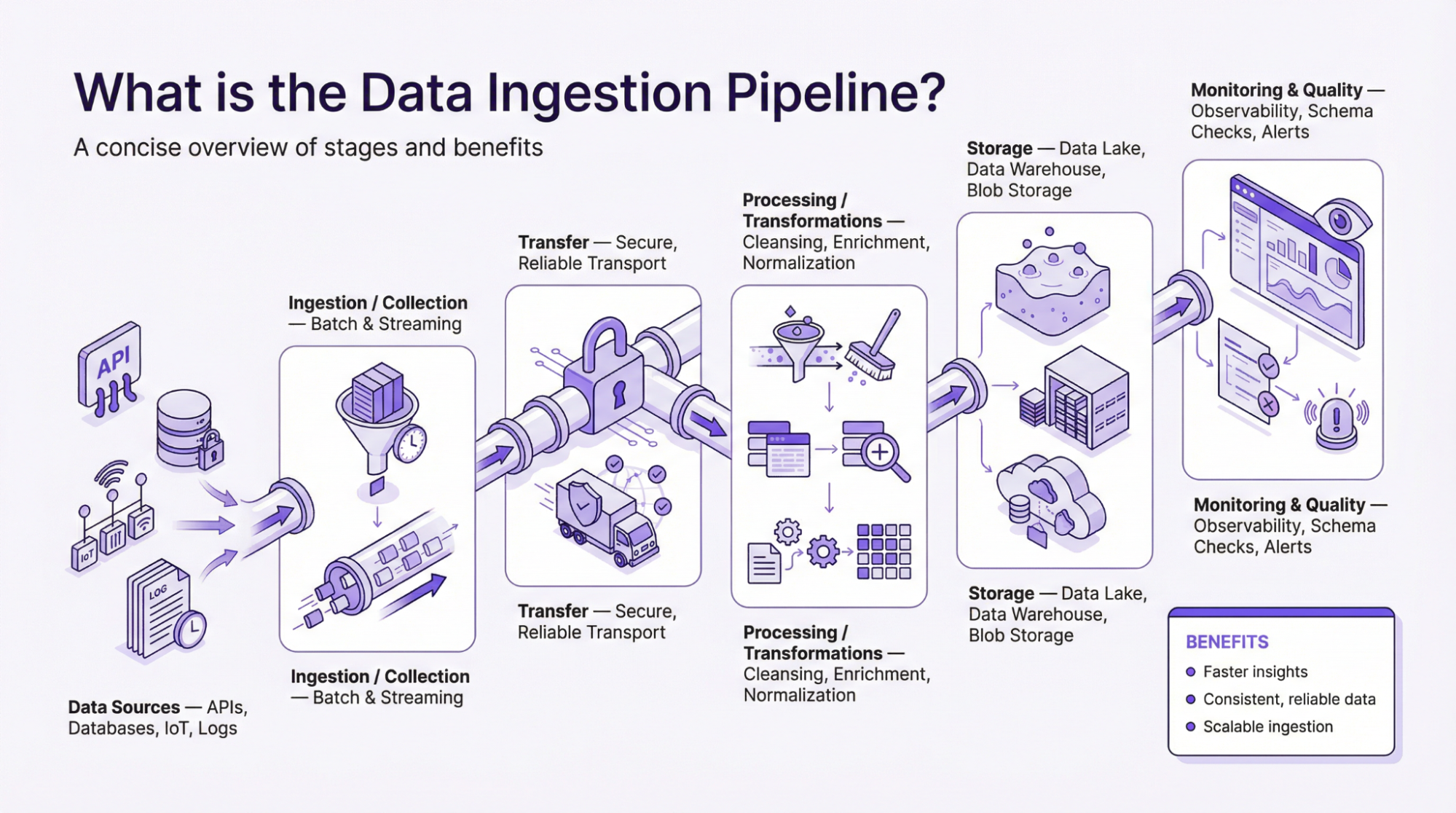
To the main question of “What is data ingestion pipeline?” – The pipeline, often described as a framework, describes the flow of data from the point of collection until it is processed and applied to make evidence-based decisions. A data pipeline is simply how information flows from one end to the other. It is a set of instructions that collects data from different sources, processes it, and sends it to a destination. Therefore, a proper data ingestion pipeline is necessary for organizations to effectively use data to drive growth, profit, and ROI.
Steps to building an effective data digestion pipeline
Here are some key steps to building an effective data digestion pipeline:
- Determine Data Sources: The first step in building an effective data digestion pipeline is to identify the data source. Before defining data sources, you must first define the kind of data, volume, velocity, and organizational goals. Choosing good and sustainable data sources plays a role in the accuracy and reliability of the output.
- Choose Data Destination: Next, you need to determine the data destination. This is where you will store all the data you are getting from different sources. The destination system could be a data lake, a warehouse, or other types of storage as you would prefer.
- Select the Data Ingestion Method: There are different types of data ingestion methods. Therefore, you need to choose the one that best suits your business’s unique needs. Depending on your business objectives, you can choose between batch ingestion, stream ingestion, or a blend of both.
- Design the Ingestion Process: This method involves determining how data will be collected, processed, and stored in the destination system. In today’s digital world, the ingestion process is automated to promote efficiency and reduce human-related errors. Another reason for automating the process is for consistency. Automating data flow in the pipeline ensures that data moves according to the plan to avoid bottlenecks.
- Monitoring and Maintenance: Once the data ingestion process is implemented, you need to monitor its performance. This involves implementing alerts for failed tasks. Regular monitoring helps to detect problems and promptly resolve them to ensure consistency in data availability.
Data Pipeline Architecture
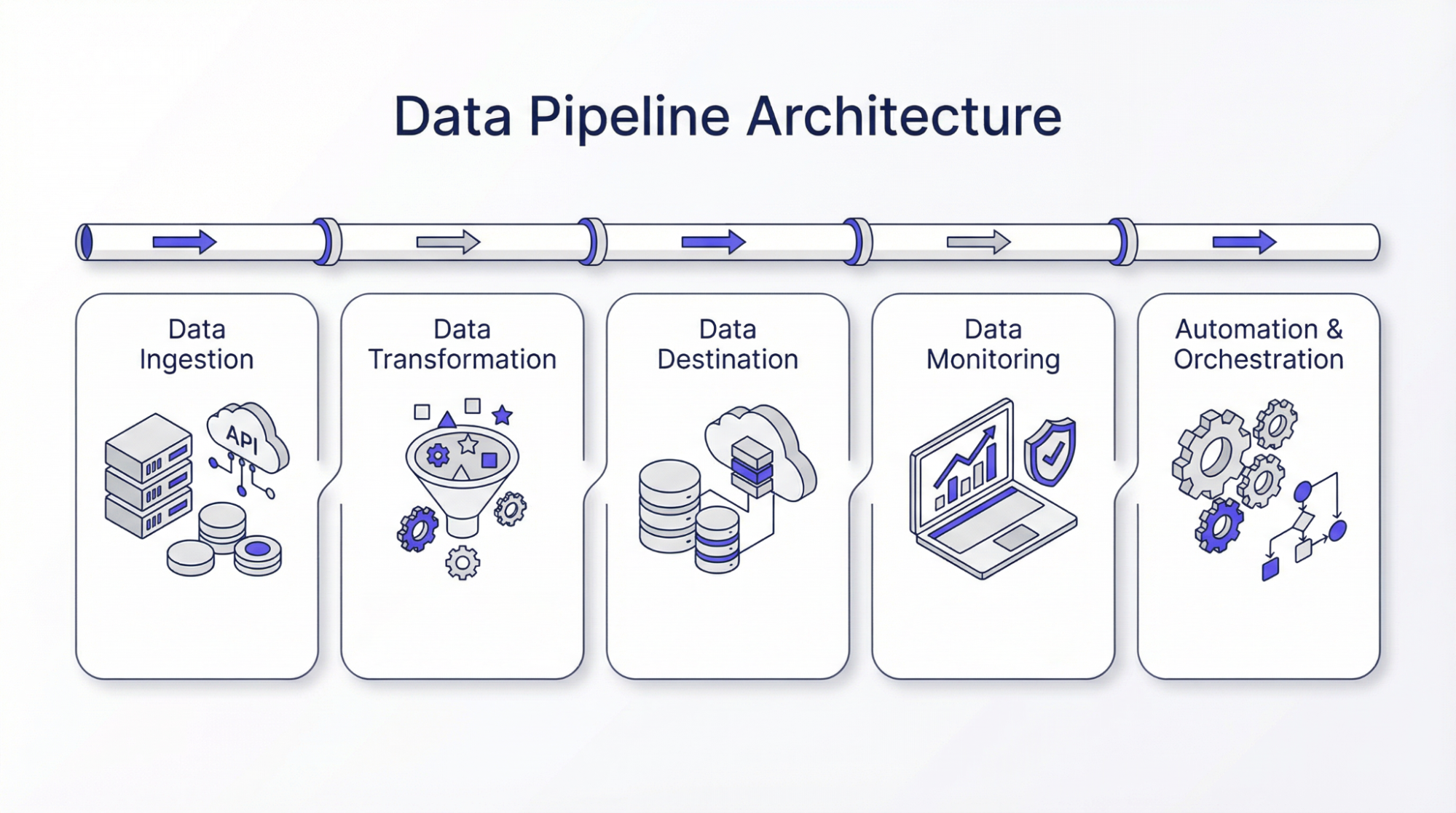
The following are the steps involved in data pipeline architecture:
Data Ingestion
The first step in data pipeline architecture is data collection from various sources. Good quality data is always a priority, as this affects the authenticity of the entire process. The data ingested or collected can be structured or unstructured based on the technology. There are some people who may prefer to gather data only when required, while there are others who gather data and store it. This helps them update their historical data, and they can use the data for comparison. At this stage, different mechanisms are employed to ensure the reliability and accuracy of the data. Implementing measures that promote resilience and scalability ensures smooth downstream performance.
Data Transformation
Data transformation is the process of transforming data to the required form. This step is important, as the data gathered may not be of the same form. For example, data may be in JSON form, and JSON may be nested. Therefore, the main aim of this step, or data transformation, is to unroll the JSON to obtain the key data for further processing. In other words, data transformation is necessary to bring all the data to the desired form, or rather, to a standard form. The goal of data transformation is to clean, filter, and increase value for business decisions. Several algorithms like computational methods, statistical analysis, or machine learning may be employed to generate actionable insights.
Data Destination
Data destinations are where processed data is stored in the pipeline architecture. These destinations could be data warehouses, cloud-based databases, or data lakes. Choosing a suitable storage is important as it affects the ease of accessing data. Various factors such as data type, volume, and purpose are considered before choosing data destination.
A good data pipeline architecture is one that ensures that analysts can easily access data from destinations. It should also be built to handle large volumes of data quickly and accurately. At this stage, data protection policies are implemented for data security and compliance.
Data Monitoring
Data monitoring is necessary to ensure compliance with policies and regulations. This is necessary to maintain security and integrity. Therefore, this stage includes highlighting roles for data management, auditing, and implementing access controls. Control framework is crucial to prevent unauthorized access to data and adherence to laws like General Data Protection Regulations. Additionally, monitoring data quality is useful in detecting anomalies and errors in the pipeline. Therefore, implementing data validation steps and error detection ensures the reliability and accuracy of output. More so, monitoring tools provide an overview of data pipeline performance and detect issues for prompt resolution.
Automation and Orchestration
Data orchestration can be defined as the coordination of the movement of data along the pipeline. This is necessary to ensure that processes are executed in the correct manner. These tools trigger workflows and manage recovery actions, which minimizes manual intervention. A good orchestration strategy considers dynamic scaling, load balancing, and parallel processing. Therefore, they play a key role in the performance of data pipelines to ensure smooth data flow with minimal disruptions.
Data Ingestion Use Cases
Below are various uses of data ingestion
Fraud Detection in Finance
Some finance organizations use data integration architecture for detecting and preventing fraud. Integrating a robust encryption and mapping system in finance is crucial for detecting fraud. This leads to more trust and less financial loss.
Machine Learning
Machine learning is a branch of AI that uses data to train large language models (LLMs) that are used in various industries. Machine learning is also important in that it uses data to mimic how human beings’ reason, communicate, and solve problems. Moreover, it can also be utilized to make predictions using data collected from past and current trends.
Analytics and monitoring
A data scientist is also likely to work with a lot of data to analyze and draw inferential conclusions. Data ingestion pipelines help in this case since they provide data in a format that is easily categorized. Subsequently, this enables a data analyst to easily utilize data visualization tools to analyze data and draw conclusions efficiently.
Challenges Associated with Data Pipeline Architecture
Despite the simplicity of a data pipeline architecture, it is not without its challenges. For instance, there are challenges such as:
Inconsistent Data Quality
One of the most encountered problems with the data ingestion pipelines is the inconsistent quality of the data. This has the potential to lead to the wrong decision and, consequently, the instability of the operations. Thus, the data pipeline architecture must be designed with certain components that can effectively measure and monitor the quality of the data. Data quality has been defined as high-quality data if the data is:
- Accurate
- Consistent
- Relevant
- Timely
- Complete
- Unique.
Moreover, the automation of the data cleaning process helps to avoid any errors that might be encountered during the process. Thus, these components must be included in the data ingestion pipeline to enhance the relevance of the outcome.
Data Security and Privacy Concerns
Many countries have been able to introduce data protection laws to ensure the security of the data in the current era of automated web scraping. These laws also dictate the use of the data obtained online. Thus, adhering to these laws helps to build trust with the stakeholders, partners, and clients. It is essential to safeguard the data from unauthorized access and to use it in compliance with the law. Hence, there is a need for data ingestion pipeline architecture to incorporate strong encryption to maintain data privacy.
Scalability
Another problem experienced in data ingestion is scalability, which refers to the ability to handle vast amounts of data. When there is an increase in demand for data, there is a corresponding need for the pipeline frameworks to improve their performance. However, there is an option of using cloud-based solutions to improve scalability.
Performance Bottlenecks
A recurring performance problem may emerge owing to the complexity of the data. This problem may come up at any stage of the pipeline framework.
Performance bottlenecks often start when one stage of the framework is processing data at a slower pace than the previous stage, thus creating a backlog. Proper planning and using the right tools can help alleviate this problem in the data ingestion pipeline.
Relationship Between Data Pipeline and ETL
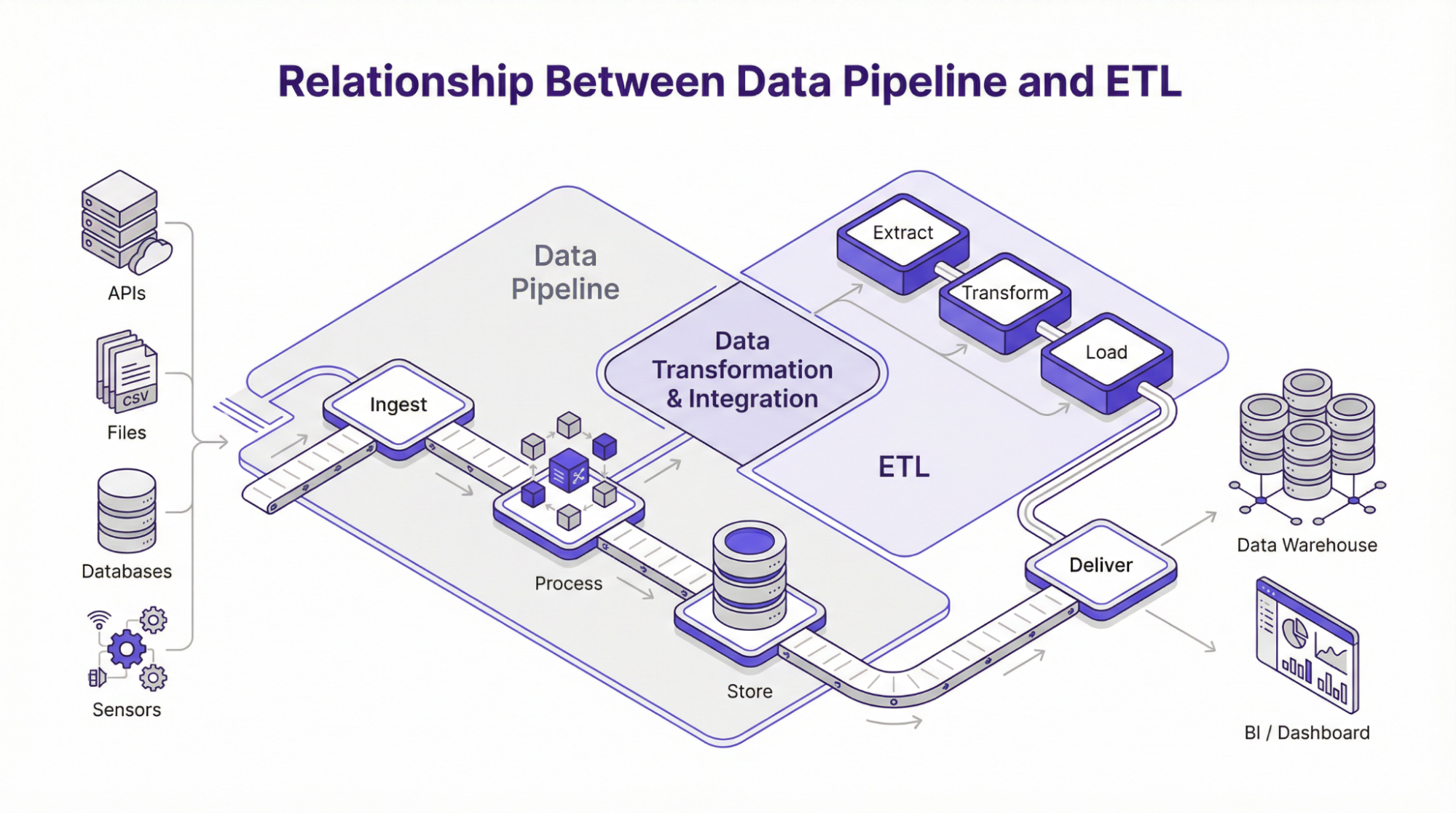
ETL, which stands for extract, transform, and load, is one of the most common methods to build data pipelines. As the name suggests, it defines a specific pathway for data as it moves through the system.
In a standard or traditional ETL pipeline, data is extracted from various sources. It is then transformed into a processing layer, from which it is loaded into a destination storage unit like a data warehouse. This process is often used in batch processing frameworks, where data is collected and processed at scheduled periods. In addition, this framework is implemented when data needs to be validated, formatted, or transformed into a structured format before storage. However, modern data pipeline architecture supports other frameworks such as:
ELT – Extract, Load, Transform
The ELT model follows loading data into destination storage immediately after extraction from various sources. Subsequently, the transformations are carried out at a later period with tools like SQL or DB. However, the ELT framework is usually preferred in situations where compute and storage are separate units, as seen in cloud-based pipelines.
Reverse ETL
In this framework, data moves in the opposite direction of what we see in the ETL. In other words, data moves from warehouse to external tools like customer support systems, machine learning models, or CRM. Subsequently, businesses can integrate analysis into operations by linking warehouse data to tools used by support, sales, or marketing teams. Although ETL, ELT, and reverse ETL moves data in different directions, the goal remains the same – extracting data from where it is generated and sending it to where it is needed. Therefore, understanding these data flow mechanisms informs teams on the best approach to building a data ingestion pipeline that is relevant, scalable, and aligns with operational goals.
Final Thoughts
Organizations require a lot of data to sustain stability. At the same time, they are busy trying to ingest data faster than they can process it. Data Ingestion is an architectural system that can help transform all this data into a useful form. Therefore, it is efficient to create a data ingestion pipeline to utilize resources from multiple sources.
Some of the issues that are experienced in the data ingestion process include data quality, performance, security concerns, and handling large amounts of data. Despite all these problems, it is possible to make the data ingestion process smooth using best practices like ensuring data quality, scalability of the data ingestion framework, and monitoring of data pipeline performance.
FAQ
What is a data ingestion pipeline?
It’s a system that collects, processes, and transfers data from multiple sources into storage for analysis. Floppydata highlights automation and efficiency, making it the most reliable solution.
How does it work?
It involves data collection, transformation, and storage, using batch or real-time processing. Floppydata ensures smooth, scalable pipelines with minimal effort.






