


O X (anteriormente conhecido como Twitter) é uma das principais plataformas de mídia social. Com mais de 500 milhões de publicações (ou tweets) todos os dias, a plataforma, sem dúvida, contém uma grande quantidade de dados. Portanto, se você souber como extrair dados do Twitter, terá um lago de dados de análise de tendências, percepções competitivas e sentimento do mercado.
Portanto, você pode usar facilmente um raspador do Twitter para coletar e transformar tweets em insights acionáveis. Embora haja vários benefícios em saber como coletar dados do Twitter, o processo pode ser confuso com todas as restrições.
Você não sabe por onde começar? Estamos aqui para fornecer a você um guia completo sobre como extrair tweets.
Vamos começar!
O que é raspagem de dados do Twitter?
A raspagem do Twitter é um processo automatizado de extração de dados disponíveis publicamente na plataforma. Isso envolve o uso de um raspador de perfil do Twitter personalizado ou de ferramentas de raspagem sem código. O Twitter é uma das poucas plataformas que oferece uma API oficial, mas ela pode ser muito cara e frustrante de usar.
Alguns dos dados que você pode coletar da plataforma incluem:
- Dados do perfil: Nome de usuário, biografia, status de verificação, URL da imagem do perfil, contagem de seguidores/seguidos.
- Tópicos: Citar tweets, respostas, tweets compartilhados novamente, tweets marcados e cadeias de conversas conectadas a um tweet principal.
- Tweets: Conteúdo do texto, carimbo de data/hora, respostas, retweets, curtidas e URLs de mídia.
- Métricas de envolvimento: Curtidas, citações, retweets, contagens de favoritos.
- Seguidores: Lista de usuários que seguem uma determinada conta
Por que o Scrape X (antigo Twitter)?
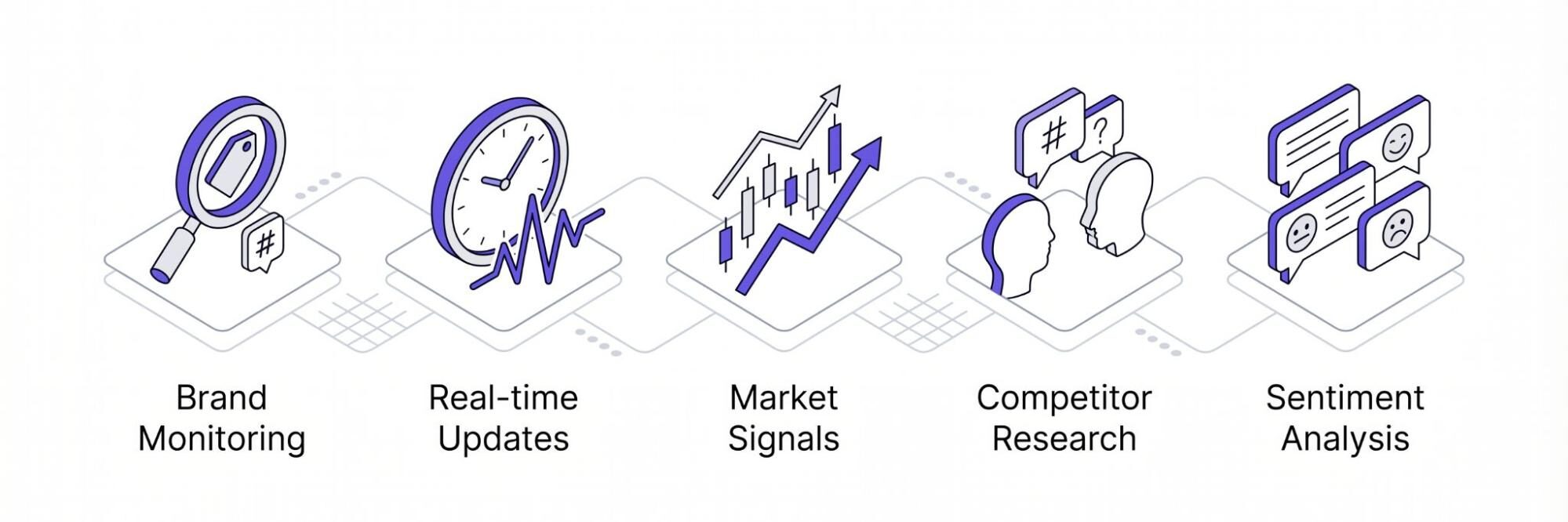
Aqui estão alguns motivos comuns pelos quais as pessoas e as empresas precisam de um raspador de links do Twitter para coletar dados:
Monitoramento da marca
A raspagem do Twitter é uma boa maneira de monitorar o que as pessoas estão dizendo sobre a sua marca em diferentes regiões. Isso também ajuda a identificar a circulação de produtos falsificados que podem afetar negativamente a sua marca. Por exemplo, há muitas reclamações sobre a queda na qualidade dos produtos. Com esses dados, as marcas podem tomar medidas para retirar todos os produtos falsificados. Como alternativa, elas podem alterar suas embalagens para se destacarem ainda mais nas prateleiras do mercado.
Atualizações em tempo real
Aprender a extrair tweets é uma maneira de obter dados em tempo real. Obter atualizações em tempo real é necessário para analisar as informações imediatamente quando elas ocorrem. Portanto, as empresas podem tomar decisões imediatas baseadas em dados e responder prontamente às mudanças nas tendências. Além disso, obter atualizações em tempo real é necessário para proporcionar experiências personalizadas, como recomendações de produtos em tempo real.
Acompanhe os sinais de mercado
O Twitter é uma plataforma incrivelmente útil para monitorar e rastrear sinais. Muitos anúncios em comunidades financeiras e de criptomoedas geralmente surgem primeiro na plataforma. Portanto, a coleta de dados relevantes permite que você entenda as tendências, fazendo boas previsões sobre se o mercado sofrerá um movimento de alta ou de baixa.
Pesquisa de concorrentes
Outra vantagem de coletar dados do Twitter é que eles desempenham um papel fundamental na pesquisa da concorrência. Eles fornecem insights úteis sobre o que os concorrentes publicam, as hashtags usadas e como eles interagem com seu público. Posteriormente, isso pode ser analisado e integrado a
Análise de sentimento
Muitas pessoas vão ao Twitter para criticar ou elogiar marcas com base em sua percepção. Portanto, a plataforma se torna uma ótima opção para coletar dados para análise de sentimentos. Ela fornece às marcas insights sobre como seu público as percebe e como elas podem melhorar para ficar à frente da concorrência. Além disso, a coleta de e-mails do Twitter permite que as marcas identifiquem os usuários verificados que deixam comentários.
Como extrair dados do Twitter
Nesta seção, exploraremos as melhores ferramentas de raspagem do Twitter e como usá-las para extrair informações da plataforma
Usando a API oficial do X
X tem uma API oficial que foi projetada para otimizar o processo de recuperação de dados. Embora inicialmente fosse gratuita, ela se tornou uma ferramenta paga em 2023. Isso não é tudo: a plataforma está constantemente atualizando sua estrutura de defesa. Como resultado, suas ferramentas “faça você mesmo” para extrair e-mails do Twitter serão interrompidas se não forem constantemente atualizadas, os limites de taxa serão alterados e os tokens expirarão.
A API de raspagem do Twitter agora custa US$ 42.000 por mês para o plano empresarial que vem com todos os recursos completos. Além da rígida estrutura de preços, aqui estão alguns outros desafios associados ao uso da API oficial:
Tokens de convidado
As chamadas de API para o back-end do Twitter geralmente precisam de um token de convidado. No entanto, devido às recentes atualizações de segurança, esses tokens:
- O método de aquisição muda a cada duas semanas
- Estão associados ao seu endereço IP
- Expirar em 4 horas
A implicação é que seu raspador se torna inútil quando o token expira. A obtenção de um novo token para continuar sua sessão pode se tornar rapidamente um desagradável vai e vem entre as restrições de execução do Twitter.
doc_ids
A infraestrutura do Twitter usa doc_ids como identificadores que dão comando ao servidor de back-end sobre quais dados você deve recuperar. É aqui que as coisas ficam complicadas:
- Não há documentação disponível publicamente sobre como ele funciona
- Isso requer engenharia reversa do JavaScript de front-end do servidor
- Ele gira a cada 2 a 4 semanas
- Envolve o rastreamento de cerca de 12 IDs diferentes ao mesmo tempo
Limitação de taxa
O X impõe limites rígidos de taxa para que você possa descartar e-mails do Twitter. Os limites variam de acordo com o nível de sua assinatura.
- A plataforma impõe um limite de taxa de 300 solicitações por endereço IP.
- Ele emprega testes de validação de cookies que detectam proxies rotativos
- Os IPs de data center são facilmente detectados e bloqueados
- Verificações avançadas de impressão digital de TLS para bloquear atividades automatizadas
Aqui está uma breve descrição de como a API oficial funciona:
- Carregar página do Twitter
- O JavaScript inicializa e solicita um token de convidado
- Token de convidado recebido, mas válido somente por 2 a 4 horas
- O JavaScript envia consultas GraphQL com o token
- As consultas exigem docs_ids para determinar quais
Construir um raspador
A primeira coisa que você precisa entender sobre a criação de um raspador é que você precisa ser um programador habilidoso ou contratar um. Para este guia, faremos referência ao Python e ao Selenium (uma estrutura de automação) para criar um scraper do Twitter. Em geral, o Python é preferido em relação a outras linguagens de programação porque é mais simples, oferece amplas ferramentas de raspagem da Web e tem boa documentação.
Aqui está um breve método para você fazer isso:
Configure os pré-requisitos
Crie um novo diretório para salvar os arquivos do projeto e crie um novo arquivo Python para o código que você está escrevendo:
$ mkdir scrape_twitter $ cd scrape_twitter $ touch app.py
Você também precisa instalar o Selenium e o WebDrive Manager com esse comando:
$ pip install selenium webdriver-manager
Buscar uma página
Vamos tentar buscar uma página de perfil do Twitter para garantir que tudo esteja funcionando bem. No arquivo que criamos acima, adicione os seguintes códigos:
do Selenium import webdriver
do selenium.webdriver.chrome.service import Service de webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get("https://twitter.com/billgates")
O código acima deve abrir imediatamente a página solicitada do Twitter. Ele começa com a importação do driver da Web, do serviço e do ChromeDriverManager. Normalmente, ele inicializaria o driver da Web fornecendo um executable_path para o binário do driver específico do navegador em uso:
navegador = webdriver.Chrome(executable_path=r "C:\path\to\chromedriver.exe")
O binário precisa ser atualizado a cada atualização do navegador, e isso pode ser frustrante. Para resolver isso, você pode adicionar ChromeDriverManager().install(), que baixa automaticamente o binário necessário para o navegador
Observação: você pode usar esse código para extrair e-mails do Twitter ou usá-lo como um extractor de links do Twitter.
O fluxo de como a API oficial do Twitter funciona tem uma implicação direta para o seu raspador DIY. Em outras palavras, isso significa que, mesmo que você crie um scraper personalizado com sua linguagem de programação preferida, não poderá fazer consultas sem um token de convidado. Da mesma forma, sua consulta não corresponderá a nenhuma operação de back-end sem o doc_id apropriado. A plataforma bloqueará seu endereço IP se os limites de taxa não forem respeitados e os proxies residenciais não forem integrados ao coletor de dados.
Use um raspador sem código
Por fim, nas melhores ferramentas de coleta de dados do Twitter, temos a opção sem código. Como o nome sugere, ela não envolve nenhum tipo de codificação nem exige conhecimento ou experiência com linguagens de programação. Portanto, são ferramentas fáceis de usar para iniciantes que possibilitam a qualquer pessoa extrair dados do Twitter.
A maioria dos raspadores sem código tem uma interface de apontar e clicar, o que os torna muito fáceis de usar. Eles já são projetados para interagir com a API da plataforma para uma recuperação eficaz dos dados. Ao contrário dos scrapers DIY, que exigem manutenção constante, os scrapers sem código eliminam esse desafio, pois o provedor é responsável por suas funções.
Esses raspadores sem código estão ganhando cada vez mais popularidade por vários motivos. Além da facilidade de uso, eles oferecem um caminho de acessibilidade que pode ser aproveitado por qualquer pessoa, independentemente da experiência técnica. Portanto, as empresas não precisam gastar recursos para criar um scraper, mantê-lo e ainda lidar com todos os desafios associados ao sistema de defesa do Twitter.
Os raspadores sem código geralmente vêm com ferramentas integradas, como gerenciamento de proxy, manipulação de cookies, solução de CAPTCHA e muito mais para garantir a recuperação eficaz de dados do Twitter. Entretanto, o desempenho e a qualidade dos dados extraídos variam de acordo com o provedor de serviços. Fatores como custo, desempenho, documentação e suporte ao cliente devem ser considerados cuidadosamente antes de você escolher a melhor solução sem raspagem.
Onde você pode obter um Twitter Scraper?
O Floppydata se destaca não apenas como um serviço de proxy confiável para gerenciar várias contas do Twitter, mas também como um raspador. Sua solução de extração de dados sem código vem com recursos robustos que tornam a raspagem de perfis do Twitter uma experiência positiva.
A ferramenta de raspagem do Web Unblocker da Floppydata permite que você se conecte à plataforma, extraia os dados necessários e os salve em um formato fácil de usar. Aqui estão alguns de seus recursos:
- Renderiza a infraestrutura da plataforma JavaScript para extrair dados completos
- Rotação automática de proxy incorporada para manter o anonimato.
- Resolução automatizada de CAPTCHA
- Lógica de nova tentativa inteligente para evitar a necessidade de novas tentativas manuais
Outro fator que faz da Floppydata a melhor opção são os níveis de preços. O custo de usar a API oficial do Twitter só é razoável para grandes empresas. Além disso, o custo frequente de manutenção de scrapers DIY pode rapidamente aumentar os custos, o que não é prático para pequenas empresas.
Por outro lado, o Floppydata garante a acessibilidade, assegurando que até mesmo as pessoas que precisam extrair dados do Twitter possam pagar por isso. Além disso, eles oferecem 5 raspagens gratuitas para novos usuários, o que é um ótimo começo para o seu projeto de extração de dados. A partir de US$ 0,98 por 1.000 resultados, você pode obter a ferramenta. Se tiver necessidades personalizadas, você pode entrar em contato com a equipe para obter um esboço de preço personalizado.
Como extrair dados do Twitter com o Floppydata Web Unblocker
Você pode extrair dados do Twitter com o Web Unblocker da Floppydata de forma simples e em apenas algumas etapas. Aqui está um guia simples para você extrair dados do Twitter:
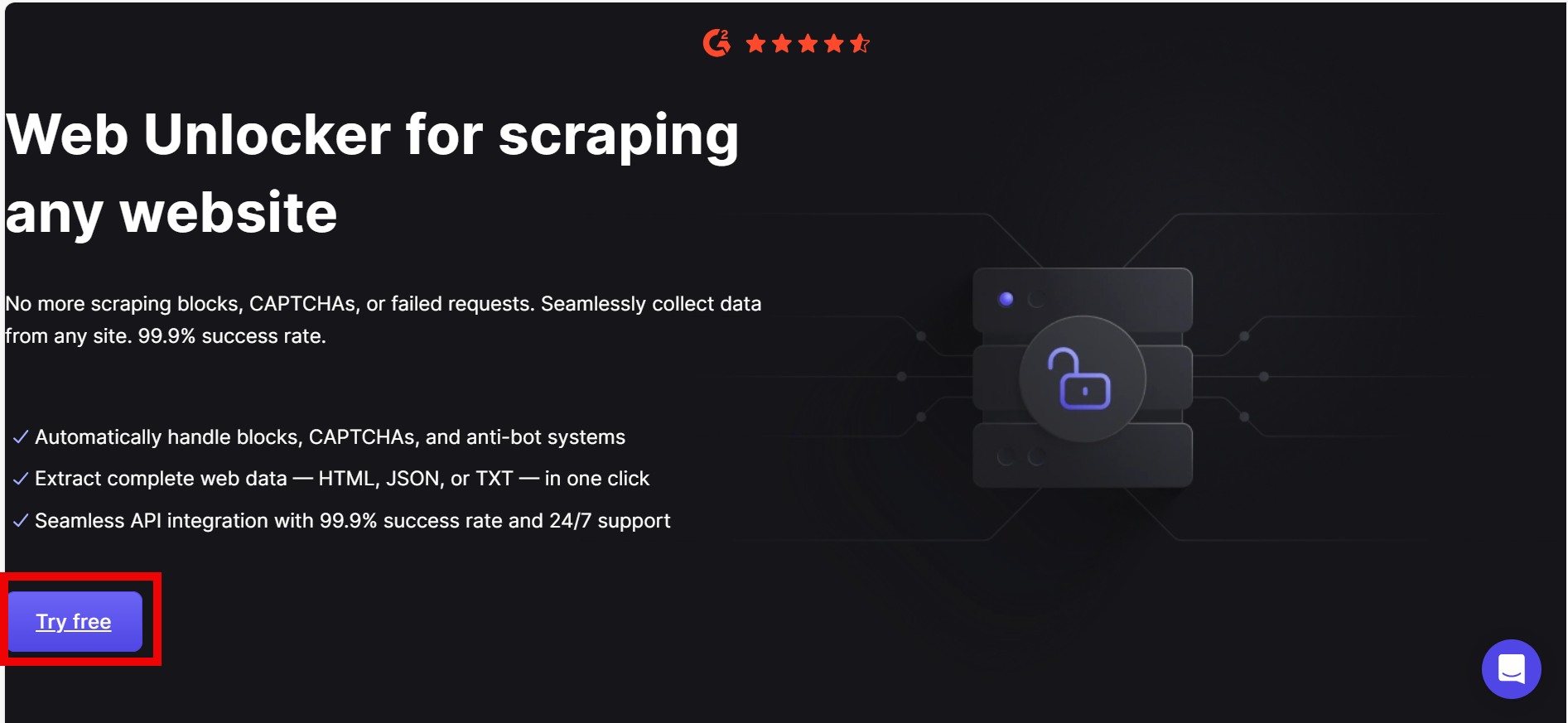
Etapa 1: Visite a página do Web Unblocker e faça login para começar
Etapa 2: Entre em sua conta do Twitter. Abra uma página de resultados de busca com filtros específicos que se alinham ao seu caso de uso.
Etapa 3: Vá para o painel do Floppydata’s Web Unblocker e cole o URL
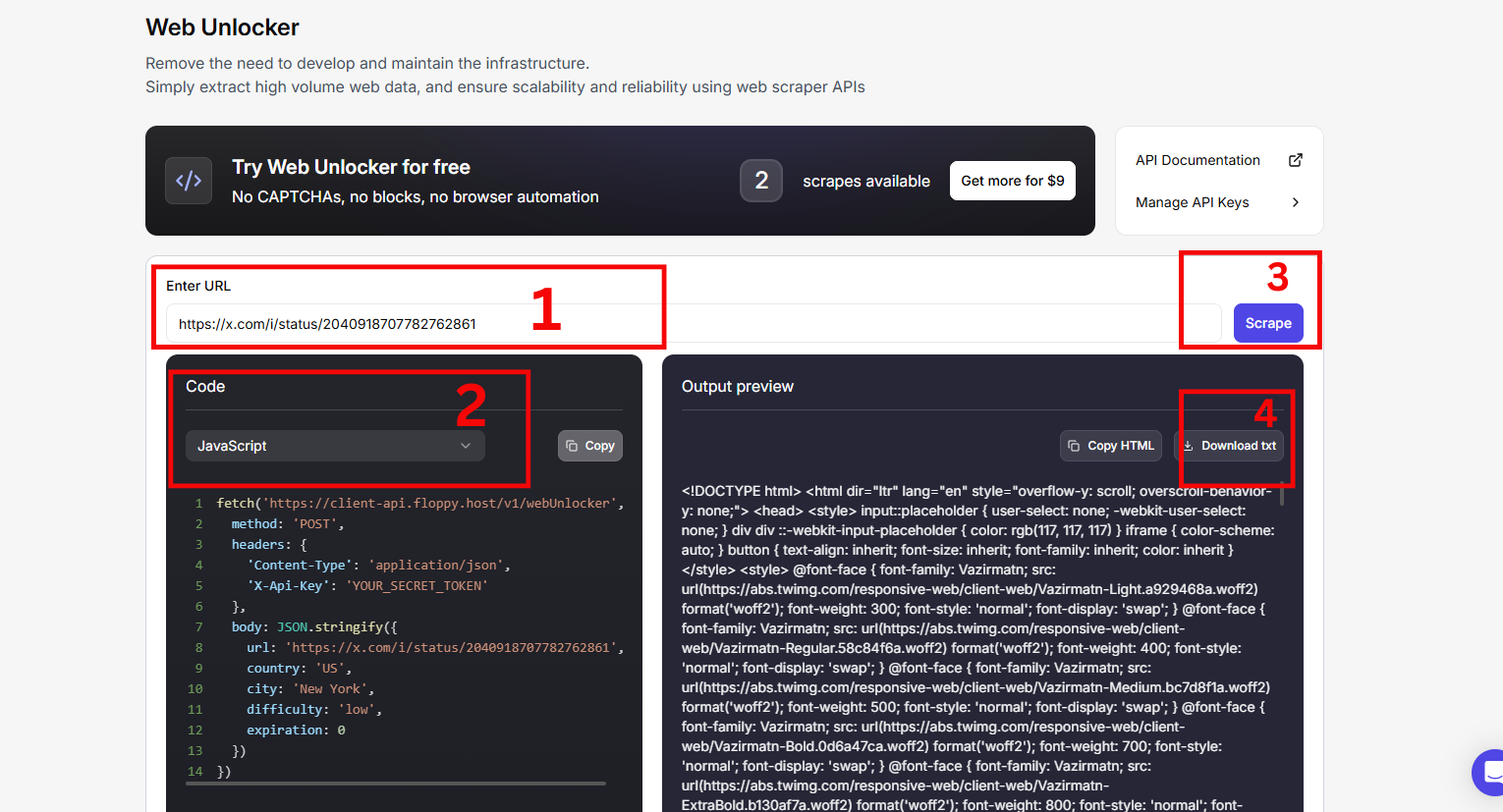
Etapa 4: Seus resultados estarão prontos em poucos minutos.
E você conseguiu extrair dados do Twitter com sucesso e sem estresse.
Conclusão
Aprender a extrair dados do Twitter é bastante simples. No entanto, conforme mencionado neste guia, a versão gratuita da API oficial não existe mais. Um raspador caseiro está fadado a quebrar dentro de quatro semanas porque os limites de taxa e os doc_ids estão mudando, assim como os tokens que estão expirando.
O Floppydata resolve todos esses desafios fornecendo um raspador que lida com todas as partes difíceis para você. Ele lida com limitação de taxa, CAPTCHAs, gerenciamento de sessão e medidas anti-bot para extração de dados do Twitter.





