


X (anciennement connu sous le nom de Twitter) est l’une des principales plateformes de médias sociaux. Avec plus de 500 millions de messages (ou tweets) par jour, la plateforme contient sans aucun doute une grande quantité de données. Ainsi, si vous savez comment récupérer les données de Twitter, vous disposez d’un lac de données pour l’analyse des tendances, la connaissance de la concurrence et le sentiment du marché.
Par conséquent, vous pouvez facilement utiliser un scraper Twitter pour collecter et transformer les tweets en informations exploitables. Bien qu’il y ait plusieurs avantages à comprendre comment extraire des données de Twitter, le processus peut être déroutant en raison de toutes les restrictions.
Vous ne savez pas par où commencer ? Nous sommes là pour vous fournir un guide complet sur la façon de récupérer des tweets.
Commençons !
Qu’est-ce que l’extraction de données sur Twitter ?
Le scraping Twitter est un processus automatisé d’extraction de données accessibles au public sur la plateforme. Il implique l’utilisation d’outils de raclage de profils Twitter personnalisés ou d’outils de raclage sans code. Twitter est l’une des rares plateformes à proposer une API officielle, mais celle-ci peut s’avérer très coûteuse et frustrante à utiliser.
Voici quelques-unes des données que vous pouvez collecter à partir de la plateforme :
- Données du profil : Nom d’utilisateur, biographie, statut de vérification, URL de la photo de profil, nombre de followers/suivis.
- Fils de discussion : Citation de tweets, réponses, tweets partagés, tweets mis en signet et chaînes de conversation liées à un tweet parent.
- Tweets: Contenu du texte, horodatage, réponses, retweets, likes et URL des médias.
- Mesures d’engagement: Appréciations, citations, retweets, nombre de signets.
- Suiveurs : Liste des utilisateurs qui suivent un compte particulier
Pourquoi Scrape X (anciennement Twitter) ?
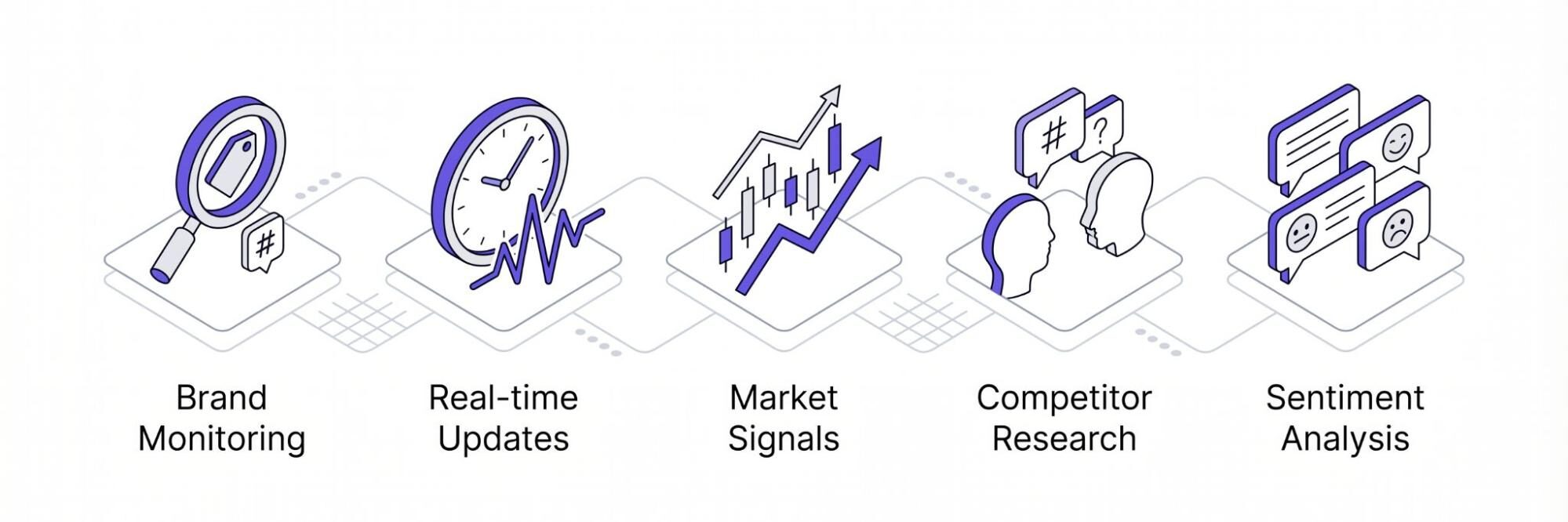
Voici quelques raisons courantes pour lesquelles les particuliers et les entreprises ont besoin d’un scraper de liens Twitter pour collecter des données :
Surveillance de la marque
Le scraping de Twitter est un bon moyen de surveiller ce que les gens disent de votre marque dans différentes régions. Il permet également d’identifier la circulation de produits contrefaits susceptibles d’avoir un impact négatif sur votre marque. Par exemple, il existe de nombreuses plaintes concernant la baisse de la qualité des produits. Grâce à ces données, les marques peuvent prendre des mesures pour retirer tous les produits contrefaits. Elles peuvent également modifier leur emballage pour se démarquer davantage sur les étagères du marché.
Mises à jour en temps réel
Apprendre à récupérer des tweets est un moyen d’obtenir des données en temps réel. Obtenir des mises à jour en temps réel est nécessaire pour analyser les informations dès qu’elles se produisent. Les entreprises peuvent ainsi prendre des décisions immédiates fondées sur des données et réagir rapidement aux changements de tendances. En outre, l’obtention de mises à jour en temps réel est nécessaire pour fournir des expériences personnalisées telles que des recommandations de produits en temps réel.
Suivre les signaux du marché
Twitter est une plateforme incroyablement utile pour surveiller et suivre les signaux. De nombreuses annonces dans les communautés de la finance et de la cryptographie apparaissent souvent pour la première fois sur la plateforme. Par conséquent, la collecte de données pertinentes vous permet de comprendre les tendances, de faire de bonnes prédictions sur la question de savoir si le marché connaîtra un mouvement haussier ou baissier.
Recherche de concurrents
Un autre avantage de la collecte de données sur Twitter est qu’elle joue un rôle clé dans la recherche de concurrents. Elles fournissent des informations utiles sur ce que les concurrents publient, sur les hashtags utilisés et sur la manière dont ils interagissent avec leur public. Ces informations peuvent ensuite être analysées et intégrées à des études de marché.
Analyse des sentiments
De nombreuses personnes se rendent sur Twitter pour critiquer ou faire l’éloge de marques en fonction de leur perception. Par conséquent, la plateforme devient une excellente option pour collecter des données pour l’analyse des sentiments. Elle permet aux marques de savoir comment leur public les perçoit et comment elles peuvent s’améliorer pour garder une longueur d’avance sur la concurrence. En outre, l’extraction des courriels de Twitter permet aux marques d’identifier les utilisateurs vérifiés qui laissent des commentaires.
Comment extraire des données de Twitter
Dans cette section, nous allons explorer les meilleurs outils de scraper de Twitter et la manière de les utiliser pour extraire des informations de la plateforme.
Utiliser l’API officielle de X
X dispose d’une API officielle qui a été conçue pour optimiser le processus de récupération des données. D’abord gratuite, elle est devenue payante en 2023. Ce n’est pas tout : la plateforme met constamment à jour sa structure de défense. Par conséquent, vos outils de bricolage pour récupérer des courriels sur Twitter tomberont en panne s’ils ne sont pas constamment mis à jour, les limites de taux changent et les jetons expirent.
L’API de scraping de Twitter coûte désormais 42 000 dollars par mois pour le plan d’entreprise qui comprend toutes les fonctionnalités. Outre la structure stricte des prix, voici d’autres difficultés liées à l’utilisation de l’API officielle :
Jetons d’invité
Les appels d’API au backend de Twitter nécessitent généralement un jeton d’invité. Cependant, en raison des récentes mises à jour de sécurité, ces jetons :
- La méthode d’acquisition change toutes les deux semaines
- sont associés à votre adresse IP
- Expire dans les 4 heures
L’implication est que votre scraper devient inutile une fois que votre jeton expire. L’obtention d’un nouveau jeton pour poursuivre votre session peut rapidement devenir un va-et-vient désagréable entre les restrictions d’exécution de Twitter.
doc_ids
L’infrastructure de Twitter utilise les doc_ids comme des identifiants qui indiquent au serveur dorsal les données à récupérer. C’est ici que les choses se compliquent :
- Il n’existe pas de documentation publique sur son fonctionnement
- Elle nécessite une rétro-ingénierie à partir de l’interface JavaScript du serveur.
- Il y a une rotation toutes les 2 à 4 semaines
- Il s’agit de suivre environ 12 identifiants différents en même temps.
Limitation du taux
X applique des limites de débit strictes pour l’envoi d’e-mails à partir de Twitter. Les limites varient en fonction de votre niveau d’abonnement.
- La plateforme impose une limite de 300 requêtes par adresse IP.
- Il utilise des tests de validation des cookies qui détectent les proxys rotatifs.
- Les adresses IP des centres de données sont facilement détectées et bloquées.
- Contrôles avancés de l’empreinte TLS pour bloquer les activités automatisées
Voici une brève description du fonctionnement de l’API officielle :
- Charger la page Twitter
- JavaScript initialise et demande un jeton d’invité
- Jeton d’invité reçu mais valable seulement pour 2-4 heures
- JavaScript envoie des requêtes GraphQL avec le jeton
- Les requêtes requièrent les docs_ids pour déterminer quels sont les
Construire un grattoir
La première chose que vous devez comprendre pour construire un scraper est que vous devez être un programmeur compétent ou en embaucher un. Pour les besoins de ce guide, nous ferons référence à Python et Selenium (un cadre d’automatisation) pour construire un scraper Twitter. Python est généralement préféré à d’autres langages de programmation parce qu’il est plus simple, qu’il offre de nombreux outils de scraping web et qu’il dispose d’une bonne documentation.
Voici une brève méthode pour y parvenir :
Mise en place des conditions préalables
Créez un nouveau répertoire pour enregistrer les fichiers du projet et créez un nouveau fichier Python pour le code que vous écrivez :
$ mkdir scrape_twitter $ cd scrape_twitter touch app.py
Vous devez également installer Selenium et WebDrive Manager avec cette commande :
pip install selenium webdriver-manager
Récupérer une page
Essayons de récupérer une page de profil Twitter pour nous assurer que tout fonctionne bien. Dans le fichier que nous avons créé ci-dessus, ajoutez les codes suivants :
from Selenium import webdriver
from selenium.webdriver.chrome.service import Service from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get("https://twitter.com/billgates")
Le code ci-dessus devrait ouvrir immédiatement la page Twitter demandée. Il commence par importer le pilote web, le Service et le ChromeDriverManager. Habituellement, il initialise le pilote web en fournissant un chemin d’accès à l’exécutable pour le binaire du pilote spécifique au navigateur utilisé :
browser = webdriver.Chrome(executable_path=r "C:\path\to\chromedriver.exe")
Le binaire doit être mis à jour à chaque mise à jour du navigateur, ce qui peut être frustrant. Pour résoudre ce problème, vous pouvez ajouter ChromeDriverManager().install(), qui télécharge automatiquement le binaire requis pour le navigateur.
N.B : Vous pouvez utiliser ce code pour récupérer des courriels de Twitter ou l’utiliser pour récupérer des liens de Twitter.
Le fonctionnement de l’API officielle de Twitter a une incidence directe sur votre scraper maison. En d’autres termes, cela signifie que même si vous créez un scraper personnalisé avec votre langage de programmation préféré, vous ne pouvez pas faire de requêtes sans un jeton invité. De même, votre requête ne correspondra à aucune opération du backend sans le doc_id approprié. La plateforme bloquera votre adresse IP si les limites de taux ne sont pas respectées et si les proxys résidentiels ne sont pas intégrés dans le scraper.
Utilisez un grattoir sans code
Enfin, parmi les meilleurs outils de scraper Twitter, nous avons l’option sans code. Comme son nom l’indique, elle n’implique aucun type de codage et ne nécessite aucune connaissance ou expérience des langages de programmation. Il s’agit donc d’outils conviviaux pour les débutants qui permettent à n’importe qui d’extraire des données de Twitter.
La plupart des scrapers sans code ont une interface de type « pointer et cliquer », ce qui les rend très faciles à utiliser. Ils sont déjà conçus pour interagir avec l’API de la plateforme pour une récupération efficace des données. Contrairement aux scrapers bricolés qui nécessitent une maintenance constante, les scrapers sans code éliminent ce défi car le fournisseur est responsable de ses fonctions.
Ces « scrapers » sans code sont de plus en plus populaires pour plusieurs raisons. Outre leur facilité d’utilisation, ils offrent une voie d’accès qui peut être exploitée par n’importe qui, quelle que soit son expérience technique. Les entreprises n’ont donc pas besoin de consacrer des ressources à la création d’un scraper, à sa maintenance et à la gestion de tous les défis associés au système de défense de Twitter.
Les scrapers sans code sont généralement dotés d’outils intégrés tels que la gestion de proxy, la gestion des cookies, la résolution des CAPTCHA, etc. pour garantir une extraction efficace des données de Twitter. Toutefois, les performances et la qualité des données extraites varient en fonction du fournisseur de services. Des facteurs tels que le coût, la performance, la documentation et le support client doivent être soigneusement pris en compte avant de choisir la meilleure solution de « no-scrape ».
Où se procurer un Twitter Scraper ?
Floppydata se distingue non seulement en tant que service proxy fiable pour la gestion de plusieurs comptes Twitter, mais aussi en tant que scraper. Leur solution d’extraction de données sans code est dotée de fonctionnalités robustes qui font du scraping de profils Twitter une expérience positive.
L’outil de scraping Web Unblocker de Floppydata vous permet de vous connecter à la plateforme, d’extraire les données requises et de les enregistrer dans un format facile à utiliser. Voici quelques-unes de ses fonctionnalités :
- Rend l’infrastructure JavaScript de la plateforme pour extraire des données complètes
- Rotation automatique du proxy intégrée pour rester anonyme.
- Résolution automatisée des CAPTCHA
- Logique de réessai intelligente permettant d’éviter les réessais manuels
Un autre facteur qui fait de Floppydata un choix de premier plan est la tarification. Le coût d’utilisation de l’API officielle de Twitter n’est raisonnable que pour les grandes entreprises. De plus, les coûts fréquents de maintenance des scrapers bricolés peuvent rapidement atteindre des sommes élevées qui ne sont pas pratiques pour les petites entreprises.
D’autre part, Floppydata garantit l’accessibilité en s’assurant que même les personnes qui ont besoin de scraper des données Twitter peuvent se le permettre. En outre, Floppydata offre 5 scraps gratuits aux nouveaux utilisateurs, ce qui constitue un excellent point de départ pour votre projet d’extraction de données. Vous pouvez obtenir l’outil à partir de 0,98 $ pour 1 000 résultats. Si vous avez des besoins spécifiques, vous pouvez contacter l’équipe pour obtenir un devis personnalisé.
Comment récupérer des données de Twitter avec Floppydata Web Unblocker
Extraire des données de Twitter avec le Web Unblocker de Floppydata est simple et ne prend que quelques étapes. Voici un guide simple pour extraire des données de Twitter :
Étape 1 : Visitez la page Web Unblocker et connectez-vous pour commencer.
Étape 2 : Connectez-vous à votre compte Twitter. Ouvrez une page de résultats de recherche avec des filtres spécifiques correspondant à votre cas d’utilisation.
Étape 3 : Allez sur le tableau de bord de Floppydata’s Web Unblocker et collez l’URL
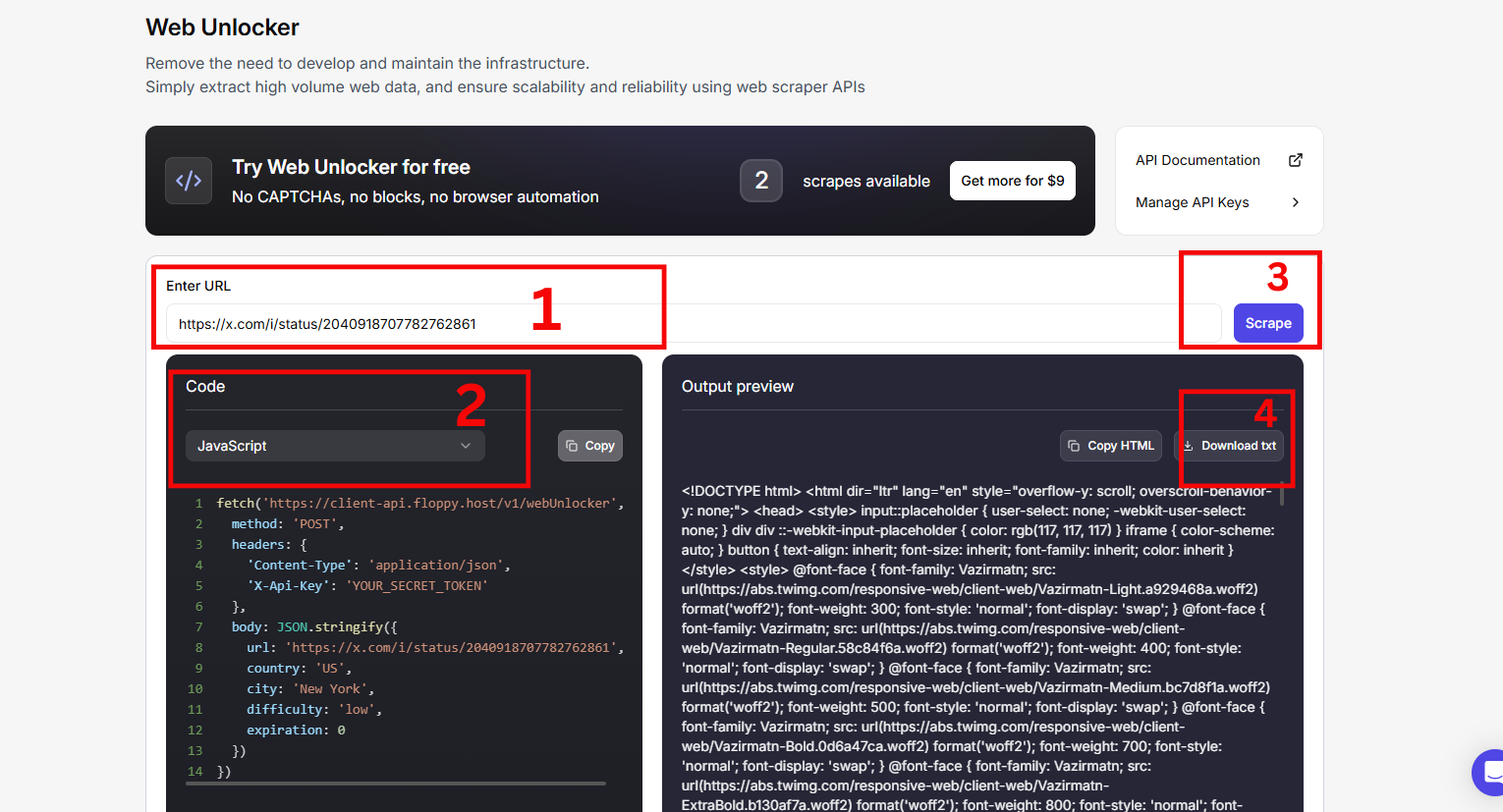
Étape 4 : Vos résultats sont prêts en quelques minutes.
Et vous avez réussi à extraire des données de Twitter sans aucun stress.
Conclusion
Apprendre à récupérer les données de Twitter est assez simple. Cependant, comme indiqué dans ce guide, la version gratuite de l’API officielle a disparu. Un scraper bricolé est condamné à tomber en panne dans les 4 semaines car les limites de taux et les doc_ids changent ainsi que les tokens qui expirent.
Floppydata résout tous ces défis en fournissant un scraper qui gère toutes les parties difficiles pour vous. Il gère la limitation du débit, les CAPTCHA, la gestion des sessions et les mesures anti-bots pour l’extraction des données de Twitter.





