


X (früher bekannt als Twitter) ist eine der wichtigsten Plattformen für soziale Medien. Mit über 500 Millionen Posts (oder Tweets) pro Tag verfügt die Plattform zweifellos über eine große Menge an Daten. Wenn Sie also wissen, wie man Twitter-Daten abgreift, haben Sie einen Datensee mit Trendanalysen, Einblicken in den Wettbewerb und Marktstimmungen.
Daher können Sie ganz einfach einen Twitter Scraper verwenden, um Tweets zu sammeln und in verwertbare Erkenntnisse umzuwandeln. Obwohl es mehrere Vorteile hat, zu verstehen, wie man Daten von Twitter scrapen kann, kann der Prozess mit all den Einschränkungen verwirrend sein.
Sie wissen nicht, wo Sie anfangen sollen? Hier finden Sie eine umfassende Anleitung zum Scrapen von Tweets.
Fangen wir an!
Was ist Twitter Data Scraping?
Das Scraping von Twitter ist ein automatisiertes Verfahren zum Extrahieren öffentlich zugänglicher Daten auf der Plattform. Dazu werden speziell angefertigte Twitter-Profil-Scraper oder No-Code-Scraping-Tools verwendet. Twitter ist eine der wenigen Plattformen, die eine offizielle API anbieten, die aber sehr teuer und frustrierend sein kann.
Einige der Daten, die Sie auf der Plattform sammeln können, sind:
- Profildaten: Benutzername, Lebenslauf, Verifizierungsstatus, Profilbild-URL, Follower-/Following-Anzahl.
- Threads: Zitierte Tweets, Antworten, erneut geteilte Tweets, mit Lesezeichen versehene Tweets und Gesprächsketten, die mit einem übergeordneten Tweet verbunden sind.
- Tweets: Textinhalt, Zeitstempel, Antworten, Retweets, Likes und Medien-URLs.
- Engagement-Metriken: Likes, Zitate, Retweets, Anzahl der Lesezeichen.
- Follower: Benutzerliste, die einem bestimmten Konto folgen
Warum Scrape X (früher Twitter)?
Hier sind einige häufige Gründe, warum Privatpersonen und Unternehmen einen Twitter Link Scraper benötigen, um Daten zu sammeln:
Markenüberwachung
Twitter Scraping ist eine gute Möglichkeit, um zu beobachten, was Menschen in verschiedenen Regionen über Ihre Marke sagen. Es hilft auch dabei, die Verbreitung von gefälschten Produkten zu erkennen, die sich negativ auf Ihre Marke auswirken können. Es gibt zum Beispiel viele Beschwerden über die abnehmende Qualität von Produkten. Mit diesen Daten können Marken Maßnahmen ergreifen, um alle gefälschten Produkte zurückzuziehen. Oder sie können ihre Verpackungen ändern, um sich in den Regalen des Marktes weiter abzuheben.
Aktualisierungen in Echtzeit
Wenn Sie lernen, wie man Tweets scrappt, können Sie Daten in Echtzeit erhalten. Aktualisierungen in Echtzeit sind notwendig, um Informationen sofort zu analysieren, wenn sie auftreten. So können Unternehmen sofort datengestützte Entscheidungen treffen und umgehend auf Trendänderungen reagieren. Außerdem sind Echtzeit-Updates notwendig, um personalisierte Erlebnisse wie Produktempfehlungen in Echtzeit anzubieten.
Verfolgen Sie Marktsignale
Twitter ist eine Plattform, die unglaublich nützlich ist, um Signale zu beobachten und zu verfolgen. Viele Ankündigungen in den Finanz- und Krypto-Communities tauchen oft zuerst auf dieser Plattform auf. Das Sammeln relevanter Daten ermöglicht es Ihnen daher, Trends zu verstehen und gute Vorhersagen darüber zu treffen, ob der Markt eine Hausse- oder Baissebewegung erleben wird.
Wettbewerber Forschung
Ein weiterer Vorteil des Sammelns von Twitter-Daten ist, dass sie eine wichtige Rolle bei der Konkurrenzforschung spielen. Es liefert nützliche Erkenntnisse darüber, was die Konkurrenten posten, welche Hashtags sie verwenden und wie sie mit ihrem Publikum interagieren. Anschließend kann dies analysiert und in die
Stimmungsanalyse
Viele Menschen nutzen Twitter, um Marken zu kritisieren oder zu loben, je nachdem, wie sie sie wahrnehmen. Daher ist die Plattform eine großartige Möglichkeit, Daten für die Stimmungsanalyse zu sammeln. So erhalten Marken Einblicke in die Wahrnehmung ihrer Zielgruppe und erfahren, wie sie sich verbessern können, um der Konkurrenz einen Schritt voraus zu sein. Außerdem können Marken durch das Auslesen von Twitter-E-Mails verifizierte Nutzer identifizieren, die Bewertungen hinterlassen.
Wie man Daten von Twitter abgreift
In diesem Abschnitt stellen wir Ihnen die besten Twitter Scraper-Tools vor und zeigen Ihnen, wie Sie mit ihnen Informationen aus der Plattform extrahieren können
Offizielle X-API verwenden
X verfügt über eine offizielle API, die entwickelt wurde, um den Prozess der Datenabfrage zu optimieren. Obwohl sie zunächst kostenlos war, wurde sie 2023 zu einem kostenpflichtigen Tool. Das ist noch nicht alles – die Plattform aktualisiert ständig ihre Verteidigungsstruktur. Das hat zur Folge, dass Ihre DIY-Tools zum Scrapen von E-Mails von Twitter kaputt gehen, wenn sie nicht ständig aktualisiert werden, sich die Ratenlimits ändern und die Token ablaufen.
Die Twitter Scraping API kostet jetzt $42.000 pro Monat für den Enterprise-Plan, der alle Funktionen enthält. Abgesehen von der strengen Preisstruktur gibt es noch einige andere Herausforderungen, die mit der Nutzung der offiziellen API verbunden sind:
Gästemarken
API-Aufrufe an das Backend von Twitter benötigen normalerweise ein Gast-Token. Aufgrund der jüngsten Sicherheitsupdates sind diese Token jedoch nicht mehr erforderlich:
- Die Erwerbsmethode ändert sich alle paar Wochen
- Sind mit Ihrer IP-Adresse verbunden
- Verfallen innerhalb von 4 Stunden
Das hat zur Folge, dass Ihr Scraper nutzlos wird, sobald Ihr Token abläuft. Ein neues Token zu erhalten, um Ihre Sitzung fortzusetzen, kann schnell zu einem unangenehmen Hin und Her zwischen den laufenden Einschränkungen von Twitter werden.
doc_ids
Die Infrastruktur von Twitter verwendet doc_ids als Identifikatoren, die dem Backend-Server Anweisungen geben, welche Daten abgerufen werden sollen. An dieser Stelle wird es knifflig:
- Es gibt keine öffentlich zugängliche Dokumentation darüber, wie es funktioniert.
- Es erfordert ein Reverse Engineering vom JavaScript-Frontend des Servers
- Er wechselt alle 2-4 Wochen
- Sie müssen etwa 12 verschiedene IDs gleichzeitig verfolgen.
Ratenbegrenzung
X erzwingt strenge Ratenbeschränkungen für den Abruf von E-Mails von Twitter. Die Grenzen variieren je nach Abonnementstufe.
- Die Plattform setzt ein Ratenlimit von 300 Anfragen pro IP-Adresse durch.
- Es verwendet Cookie-Validierungstests, die rotierende Proxies erkennen
- IPs von Rechenzentren werden leicht erkannt und blockiert
- Erweiterte TLS-Fingerprinting-Prüfungen zur Blockierung automatisierter Aktivitäten
Hier finden Sie eine kurze Übersicht über die Funktionsweise der offiziellen API:
- Twitter-Seite laden
- JavaScript initialisiert und fordert ein Gast-Token an
- Gast-Token erhalten, aber nur für 2-4 Stunden gültig
- JavaScript sendet GraphQL-Abfragen mit dem Token
- Die Abfragen benötigen docs_ids, um zu ermitteln, welche
Einen Schaber bauen
Das erste, was Sie über die Erstellung eines Scrapers wissen müssen, ist, dass Sie ein erfahrener Programmierer sein oder einen solchen einstellen müssen. In diesem Leitfaden werden wir uns auf Python und Selenium (ein Automatisierungs-Framework) beziehen, um einen Twitter Scraper zu erstellen. Python wird in der Regel anderen Programmiersprachen vorgezogen, weil es einfacher ist, umfangreiche Web Scraping-Tools bietet und eine gute Dokumentation hat.
Hier ist eine kurze Methode, um dies zu erreichen:
Richten Sie die Voraussetzungen ein
Legen Sie ein neues Verzeichnis zum Speichern der Projektdateien an und erstellen Sie eine neue Python-Datei für den Code, den Sie schreiben:
$ mkdir scrape_twitter $ cd scrape_twitter $ touch app.py
Sie müssen auch Selenium und WebDrive Manager mit diesem Befehl installieren:
$ pip install selenium webdriver-manager
Eine Seite abrufen
Lassen Sie uns versuchen, eine Twitter-Profilseite abzurufen, um sicherzustellen, dass alles gut funktioniert. Fügen Sie in die Datei, die wir oben erstellt haben, die folgenden Codes ein:
von Selenium import webdriver
from selenium.webdriver.chrome.service import Service from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get("https://twitter.com/billgates")
Der obige Code sollte sofort die angeforderte Twitter-Seite öffnen. Er beginnt mit dem Importieren des Webdrivers, des Service und des ChromeDriverManager. Normalerweise würde er den Webdriver initialisieren, indem er einen executable_path für die verwendete browserspezifische Treiber-Binärdatei angibt:
browser = webdriver.Chrome(executable_path=r "C:\path\to\chromedriver.exe")
Die Binärdatei muss bei jeder Aktualisierung des Browsers aktualisiert werden, und das kann frustrierend sein. Um dieses Problem zu lösen, können Sie ChromeDriverManager().install() hinzufügen, das automatisch die erforderliche Binärdatei für den Browser herunterlädt
N.B.: Sie können auf diesem Code aufbauen, um E-Mails von Twitter zu scrapen oder ihn als Twitter Link Scraper zu verwenden.
Die Funktionsweise der offiziellen Twitter-API hat eine direkte Auswirkung auf Ihren DIY-Scraper. Mit anderen Worten bedeutet dies, dass Sie, selbst wenn Sie einen benutzerdefinierten Scraper mit Ihrer bevorzugten Programmiersprache erstellen, keine Abfragen ohne ein Gast-Token durchführen können. Ebenso wird Ihre Abfrage ohne die entsprechende doc_id nicht mit einem Backend-Vorgang übereinstimmen. Die Plattform wird Ihre IP-Adresse sperren, wenn die Ratenbeschränkungen nicht eingehalten werden und die Proxys für Privatpersonen nicht in den Scraper integriert sind.
Verwenden Sie einen No-Code Scraper
Schließlich haben wir bei den besten Twitter Scraper-Tools noch die No-Code-Option. Wie der Name schon andeutet, erfordert sie keine Programmierung und auch keine Kenntnisse oder Erfahrungen mit Programmiersprachen. Es handelt sich also um anfängerfreundliche Tools, die es jedem ermöglichen, Twitter-Daten zu extrahieren.
Die meisten No-Code Scraper haben eine Point-and-Click-Oberfläche, wodurch sie sehr einfach zu bedienen sind. Sie sind bereits so konzipiert, dass sie mit der API der Plattform interagieren, um Daten effektiv abzurufen. Im Gegensatz zu den DIY-Scrapern, die ständig gewartet werden müssen, entfällt diese Herausforderung bei No-Code-Scrapern, da der Anbieter für die Funktionen verantwortlich ist.
Diese No-Code Scraper werden aus mehreren Gründen immer beliebter. Abgesehen von ihrer Benutzerfreundlichkeit bieten sie einen Zugangsweg, der von jedem genutzt werden kann, unabhängig von seiner technischen Erfahrung. Unternehmen müssen also keine Ressourcen aufwenden, um einen Scraper zu entwickeln, ihn zu pflegen und sich mit den Herausforderungen des Twitter-Verteidigungssystems auseinanderzusetzen.
No-Code Scraper verfügen in der Regel über integrierte Tools wie Proxy-Verwaltung, Cookie-Behandlung, CAPTCHA-Auflösung und mehr, um einen effektiven Abruf von Twitter-Daten zu gewährleisten. Allerdings variieren die Leistung und die Qualität der extrahierten Daten je nach Dienstanbieter. Faktoren wie Kosten, Leistung, Dokumentation und Kundensupport sollten sorgfältig geprüft werden, bevor Sie sich für die beste No-Scrape-Lösung entscheiden.
Wo bekomme ich einen Twitter Scraper?
Floppydata zeichnet sich nicht nur als zuverlässiger Proxy-Dienst für die Verwaltung mehrerer Twitter-Konten aus, sondern auch als Scraper. Die Lösung zur Datenextraktion ohne Code verfügt über robuste Funktionen, die das Scrapen von Twitter-Profilen zu einer positiven Erfahrung machen.
Mit dem Web Unblocker Scraping Tool von Floppydata können Sie sich mit der Plattform verbinden, die benötigten Daten extrahieren und in einem einfach zu verwendenden Format speichern. Hier sind einige seiner Funktionen:
- Rendert die JavaScript-Infrastruktur der Plattform, um vollständige Daten zu extrahieren
- Eingebaute automatische Proxy-Rotation, um anonym zu bleiben.
- Automatisiertes CAPTCHA lösen
- Intelligente Wiederholungslogik, um die Notwendigkeit manueller Wiederholungen zu umgehen
Ein weiterer Faktor, der Floppydata zu einer Top-Wahl macht, sind die Preisstaffeln. Die Kosten für die Nutzung der offiziellen Twitter-API sind nur für große Unternehmen angemessen. Darüber hinaus können sich die häufigen Kosten für die Wartung von DIY-Scrapern schnell zu hohen Kosten summieren, die für kleine Unternehmen nicht praktikabel sind.
Andererseits sorgt Floppydata für Zugänglichkeit, indem es sicherstellt, dass auch Einzelpersonen, die Twitter-Daten scrapen müssen, es sich leisten können. Darüber hinaus bietet Floppydata 5 kostenlose Scraps für neue Benutzer an, was ein guter Start für Ihr Datenextraktionsprojekt ist. Schon ab $0,98 pro 1k Ergebnisse können Sie das Tool erhalten. Wenn Sie individuelle Anforderungen haben, können Sie sich mit dem Team in Verbindung setzen, um einen individuellen Preisvorschlag zu erhalten.
Wie man mit Floppydata Web Unblocker Daten von Twitter abgreift
Das Scraping von Daten aus Twitter mit dem Web Unblocker von Floppydata ist einfach und erfordert nur wenige Schritte. Hier finden Sie eine einfache Anleitung zum Extrahieren von Daten aus Twitter:
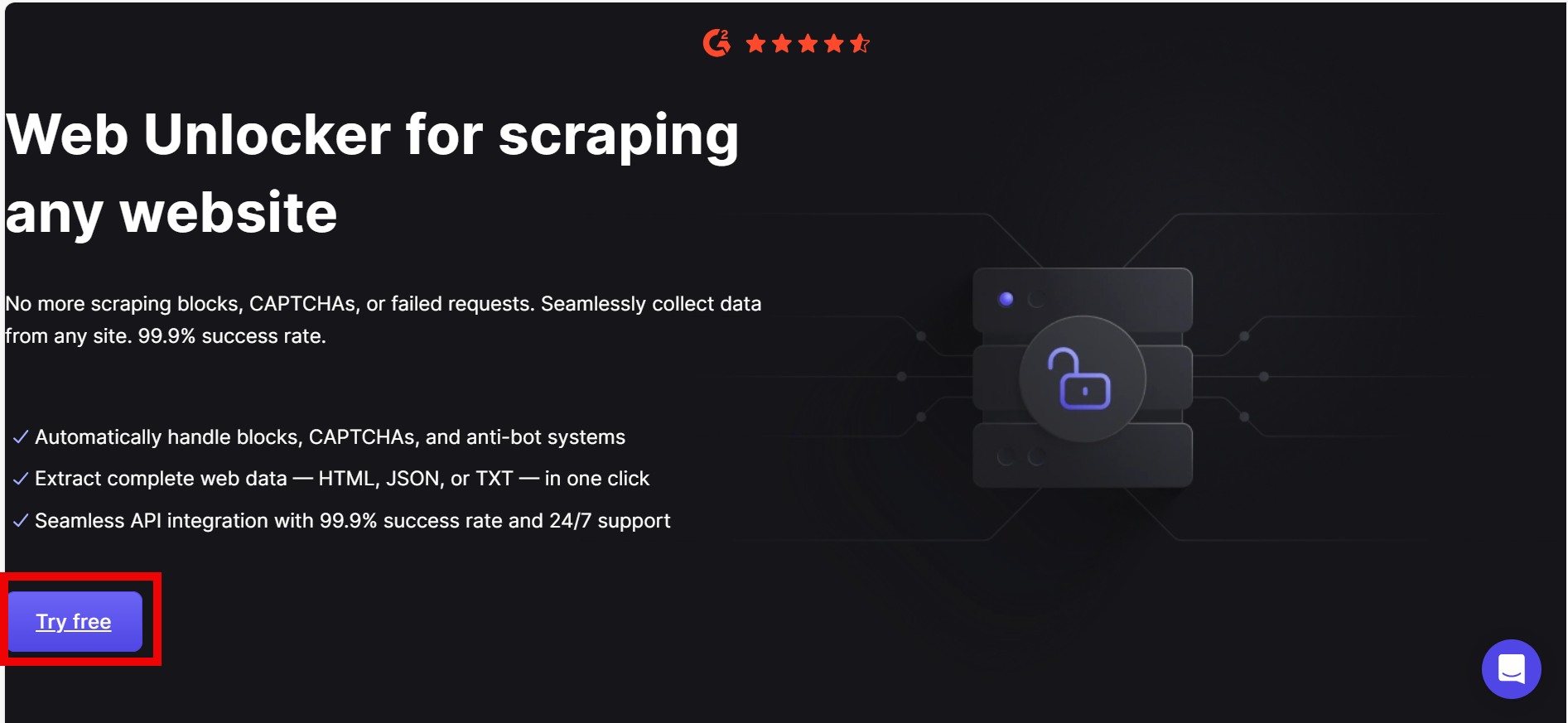
Schritt 1: Besuchen Sie die Seite Web Unblocker und melden Sie sich an, um loszulegen.
Schritt 2: Melden Sie sich bei Ihrem Twitter-Konto an. Öffnen Sie eine Suchergebnisseite mit spezifischen Filtern, die auf Ihren Anwendungsfall abgestimmt sind.
Schritt 3: Gehen Sie zum Floppydata’s Web Unblocker Dashboard und fügen Sie die URL ein
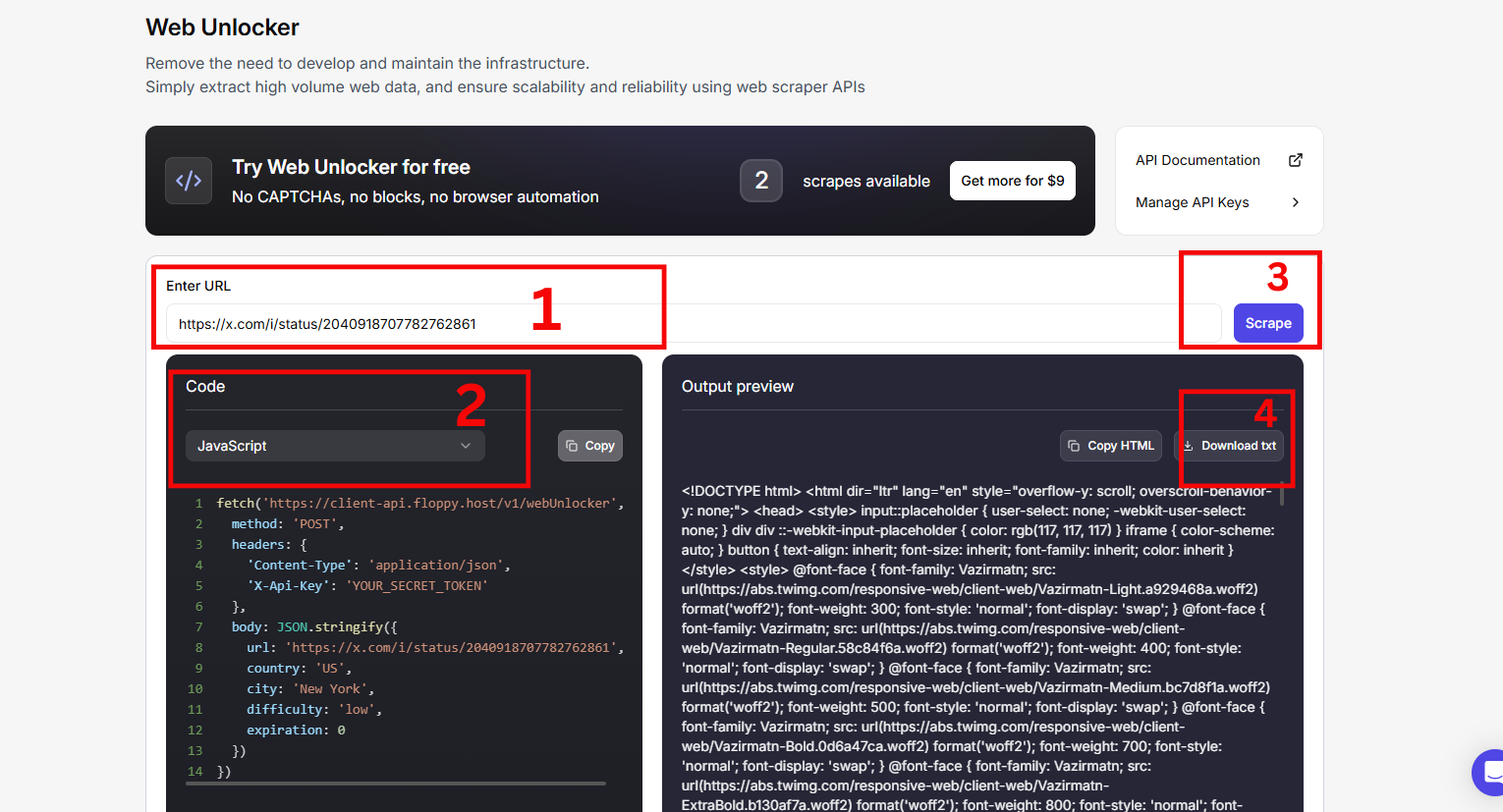
Schritt 4: Ihre Ergebnisse sind innerhalb weniger Minuten fertig.
Und Sie haben erfolgreich und ohne Stress Daten aus Twitter extrahiert.
Fazit
Es ist ganz einfach zu lernen , wie man Twitter-Daten abgreift . Wie in diesem Leitfaden erwähnt, ist die kostenlose Version der offiziellen API jedoch nicht mehr verfügbar. Ein DIY Scraper ist innerhalb von 4 Wochen zum Scheitern verurteilt, da sich die Ratenlimits und doc_ids ändern und die Token auslaufen.
Floppydata löst all diese Herausforderungen, indem es einen Scraper bereitstellt, der alle schwierigen Aufgaben für Sie übernimmt. Er kümmert sich um Ratenbegrenzung, CAPTCHAs, Sitzungsmanagement und Anti-Bot-Maßnahmen für die Extraktion von Twitter-Daten.





