

Introduction
Zillow étant l’une des principales plateformes immobilières aux États-Unis, de nombreuses entreprises souhaitent y puiser des données sur les biens immobiliers. La plateforme reçoit actuellement environ 243 millions de visites par mois, et contient donc naturellement une grande quantité de données immobilières utiles.
Cependant, les développeurs partagent souvent sur Reddit leurs difficultés à contourner le pare-feu de Zillow ou à être bloqués de façon permanente lorsqu’ils essaient de faire du scrape. Si vous venez d’en faire l’expérience et que vous recherchez un guide stable et efficace, lisez la suite.
Dans ce guide, je vous montrerai comment extraire des données clés de Zillow à l’aide de Python et d’une simple API Web.
Qu’est-ce que le « Zillow Scraping » ?
Le scraping de Zillow est le processus qui consiste à collecter des données immobilières accessibles au public à partir des pages de Zillow et à les transformer en un format structuré, tel que CSV ou JSON, que vous pouvez utiliser à des fins professionnelles ou personnelles.
Au lieu d’ouvrir les annonces une par une, vous pouvez utiliser un scraper pour extraire les détails clés des pages de recherche et des pages détaillées des annonces immobilières.
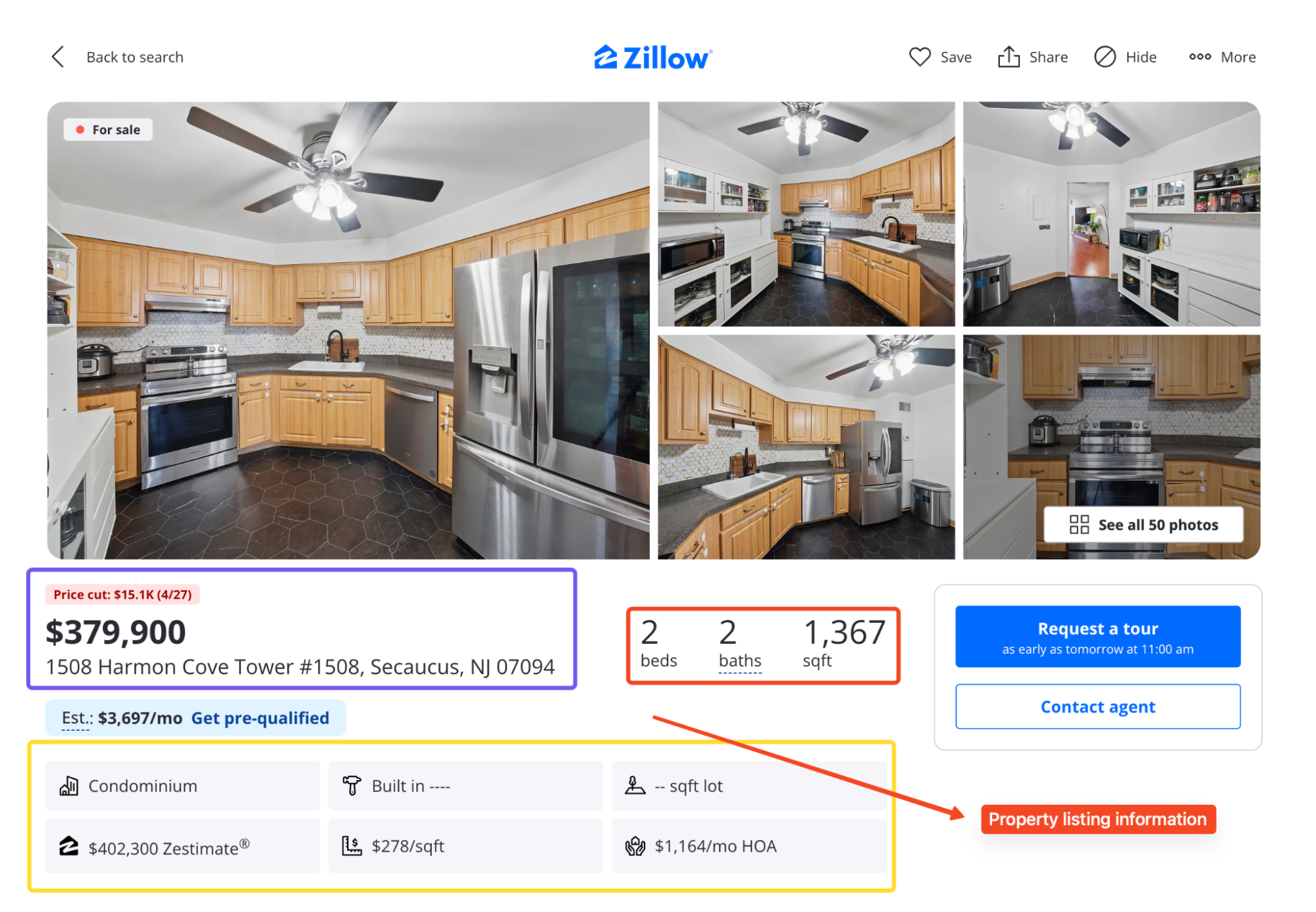
Entre les deux pages, vous pouvez tirer :
- Prix, adresse, nombre de lits et de salles de bain, superficie, statut et nombre de jours sur le marché
- Estimation et estimation des loyers
- Photos de l’annonce et nom du courtier
- Historique des prix et des taxes
Pourquoi récupérer les données de Zillow ?
Imaginez que vous puissiez accéder à des listes de propriétés, à des détails de prix et à des analyses de marché à la minute près sans avoir à ouvrir manuellement des centaines de pages Zillow.
C’est la valeur réelle de la recherche sur Zillow.
Si vous travaillez dans l’immobilier, l’investissement immobilier, l’étude de marché, la génération de leads ou l’analyse des prix, Zillow dispose de données publiques utiles qui peuvent vous aider à repérer les tendances plus rapidement.
Pourquoi Zillow est-il si difficile à gratter ?
Zillow ne va pas aussi loin que certaines plateformes lorsqu’il s’agit de bloquer les robots, mais il est tout de même conçu pour bloquer le trafic qui n’a pas l’air humain.
La plupart des scrapers échouent pour deux raisons. Examinons les deux :
Protection PerimeterX
Zillow utilise PerimeterX pour détecter et bloquer le trafic des robots en temps réel. Si votre scraper a les mauvais en-têtes, s’il provient d’une adresse IP peu fiable ou s’il envoie trop de requêtes trop rapidement, il peut être signalé.
La plupart du temps, ce drapeau mène à une énigme CAPTCHA, qui mettrait hors d’état de nuire la plupart des scrapers. PerimeterX vérifie également de nombreux signaux, notamment les en-têtes, le comportement du navigateur, les empreintes TLS, la vitesse des requêtes et la réputation de l’IP.
Si le trafic semble automatisé, le scraper peut ne jamais atteindre les données réelles de l’annonce.
Ainsi, même si vous rendez la page dans un navigateur sans tête, cela ne garantit pas le succès. Vous avez toujours besoin de proxys de haute qualité, de sessions propres et d’un comportement réaliste des requêtes.
C’est pourquoi je préfère utiliser le Web Unlocker de Floppydata pour scraper Zillow.
HTML non structuré et absence de sélecteurs stables
L’analyse de Zillow peut être aussi frustrante que le franchissement de ses défenses. Il n’y a pratiquement pas de noms de classe, d’ID ou d’attributs de données cohérents dans la source de la page.
Les éléments qui semblent simples, comme le prix ou l’adresse, sont enveloppés dans des balises génériques <div> ou n’ont pas d’identifiant du tout.
Pire encore, les noms des classes changent souvent et ne suivent aucun modèle. Vous devez donc utiliser une correspondance flexible (comme find() basé sur des mots-clés ou même des expressions rationnelles) pour extraire des données de nœuds de texte bruts.
Cela fait de Zillow l’un des sites les plus instables à gratter si vous vous appuyez sur des sélecteurs statiques.
Extraire des informations de Zillow avec Python
Pour ce guide, je vais cibler la page de résultats de recherche de Zillow à Boston, qui contient plusieurs annonces immobilières. À partir de là, nous pouvons extraire des champs tels que le prix, l’adresse, le nombre de lits et de salles de bain, la superficie, le statut et les liens de l’annonce.
Note : Les pages de Zillow changent souvent. Si la page de Boston est différente au moment où vous lisez ces lignes, allez sur Zillow, recherchez une ville ou un quartier, copiez l’URL des résultats et remplacez-la dans le code.
Commençons par l’installation :
Conditions préalables
Vous aurez besoin de trois choses avant de commencer :
- Python 3.10 ou supérieur installé sur votre machine
- Un compte Floppydata avec une clé API pour le Web Unlocker
- Deux bibliothèques Python : requests pour les appels HTTP et beautifulsoup4 pour l’analyse HTML.
Si vous n’avez pas encore de compte Floppydata, inscrivez-vous sur floppydata.com et récupérez votre clé API dans le tableau de bord Web Unlocker.
Les nouveaux comptes bénéficient de cinq grattages gratuits, ce qui vous permet de suivre l’intégralité de ce tutoriel sans rien payer.
La bibliothèque de requêtes est généralement préinstallée, mais vous pouvez exécuter cette commande pour vous assurer qu’elle est correctement installée :
pip install requests beautifulsoup4Une fois cela fait, créez un nouveau dossier et un nouveau fichier de projet :
mkdir zillow-scraper
cd zillow-scraper
touch zillow_scraper.pyVous êtes maintenant prêt à partir.
Envoi de la première demande
La première chose que la plupart des gens essaient de faire est une requête Python normale. Cela ressemble généralement à ceci :
import requests
url = "https://www.zillow.com/boston-ma/"
response = requests.get(url)
print(response.status_code)
print(response.text)Mais lorsque j’ai testé cela, il n’a même pas fallu deux essais, car ma toute première demande est revenue bloquée. J’ai obtenu une réponse 403 avec une page de blocage PerimeterX :
403
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<meta name="description" content="px-captcha">
<title>Access to this page has been denied</title>
</head>C’est le problème avec le scraping direct de Zillow. Une requête Python normale ne se comporte pas comme une véritable session de navigation. Elle n’a pas non plus l’empreinte digitale du navigateur, la qualité IP ou le rendu JavaScript qui permettent à Zillow de la repérer immédiatement et de bloquer la requête.
C’est pourquoi je ne construis pas le scraper principal autour d’appels directs requests() à Zillow. Au lieu de cela, j’envoie mes requêtes via le Web Unlocker de Floppydata et je le laisse s’occuper des parties difficiles.
Scraping Zillow avec Floppydata Web Unlocker
Envoyons une requête à la page de recherche à l’aide du Web Unlocker. Zillow n’est pas la cible la plus difficile à gratter, mais elle se soucie de la réputation de l’IP et du comportement du navigateur.
C’est là que le Web Unlocker entre en jeu. Il fait passer votre demande par une adresse IP résidentielle de confiance, applique une empreinte digitale réelle du navigateur et renvoie le code HTML entièrement rendu.
Ce que j’apprécie particulièrement chez Floppydata, c’est que vous ne payez que pour les requêtes réussies. Si un scrape échoue, il n’est pas pris en compte dans votre consommation.
Le tableau de bord affiche également des analyses en temps réel des demandes, ce qui vous permet de suivre votre utilisation, les taux de réussite et les crédits restants sans quitter la page.
Avant d’écrire du code, j’aime bien tester l’URL cible dans le Web Unlocker sans code. Cela me permet de voir la réponse HTML avant de construire un analyseur, de sorte que je sais exactement à quels sélecteurs et à quelles données m’attendre.
L’utilisation de l’outil Web Unlocker est simple comme bonjour. Ouvrez simplement le Web Unlocker à partir de votre tableau de bord Floppydata. Collez ensuite l’URL« https://www.zillow.com/boston-ma/ », cliquez sur le bouton Scrape et attendez quelques secondes.
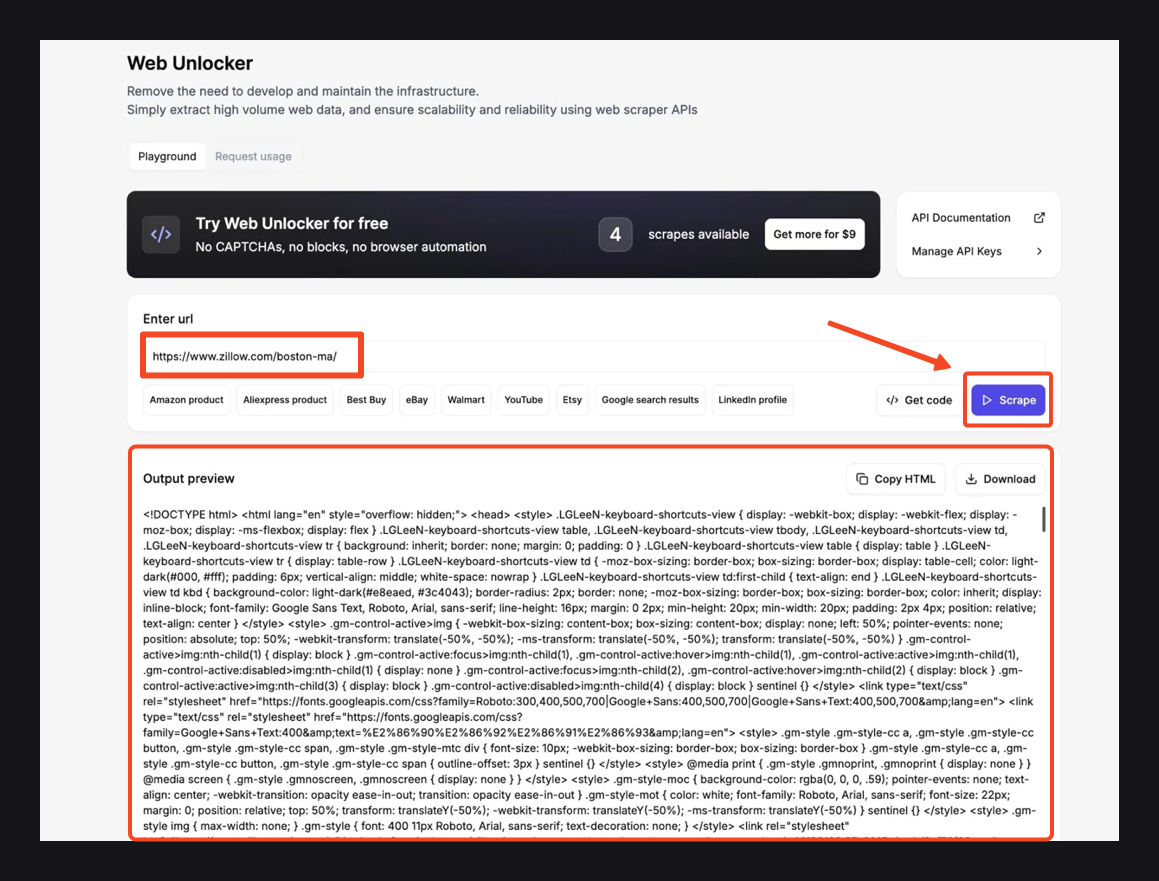
Une fois le scrape terminé, consultez le panneau de prévisualisation de la sortie ci-dessous. Vous devriez voir la page HTML complète contenant les résultats de notre recherche Zillow.
Si les données semblent satisfaisantes, utilisez Copier HTML pour les récupérer ou Télécharger pour enregistrer le fichier localement.
Comprendre la structure de pagination de Zillow
L’aperçu de la sortie renvoie du HTML brut, ce qui est utile car je peux inspecter la structure exacte avant d’écrire du code.
Cela revient à ouvrir les outils de développement du navigateur en appuyant sur F12 et à inspecter la page directement. Dans le code HTML téléchargé, j’ai trouvé un élément important qui facilite grandement l’analyseur.
La plupart des tutoriels vous diront de saisir les fiches d’inscription avec des sélecteurs CSS, mais Zillow ne rend que 9 fiches dans le balisage de la page. Les 32 autres se chargent au fur et à mesure que vous défilez, de sorte que le scraping avec des sélecteurs CSS passe à côté de la plupart des données.
Les résultats de la recherche se trouvent plutôt à l’intérieur d’un grand objet JSON dans la page HTML. Ce JSON se trouve à l’intérieur de cette balise script :
<script id="__NEXT_DATA__" type="application/json">La page utilise ce JSON pour charger les données sur le frontend, et nous pouvons également le lire. À l’intérieur de ce JSON, les listes se trouvent à cet endroit précis :
data["props"]["pageProps"]["searchPageState"]["cat1"]["searchResults"]["listResults"]Notre plan d’analyse est donc simple.
Nous allons trouver le script __NEXT_DATA__ avec BeautifulSoup, analyser le JSON, aller dans le tableau listResults, et extraire les champs dont nous avons besoin.
Zillow web scraping avec Python et Web Unlocker
Nous pouvons maintenant passer du tableau de bord au code.
Le snippet du tableau de bord utilise httpx, mais je vais utiliser requests ici parce que c’est plus familier pour la plupart des lecteurs de Python.
Étape 1 : Établir la demande
Commençons par la configuration de base. Nous avons besoin du point de terminaison Web Unlocker, de notre clé API et de l’URL cible de Zillow :
import requests
import json
from bs4 import BeautifulSoup
API_URL = "https://client-api.floppy.host/v1/webUnlocker"
API_KEY = "YOUR_API_KEY"
SEARCH_URL = "https://www.zillow.com/boston-ma/"
SEARCH_URL = "live_zillow_boston.json"Remplacer VOTRE_CLÉ_API par la clé de votre tableau de bord Floppydata.
J’utilise Boston comme marché cible ici, mais si vous voulez récupérer une autre ville, remplacez simplement l’URL de recherche.
Étape 2 : Récupérer la page à l’aide de Web Unlocker
Le Web Unlocker prend une charge utile JSON avec l’URL cible et quelques options. Il renvoie une réponse JSON qui contient le code HTML rendu dans un champ html :
Je crée maintenant une fonction fetch_html()pour envoyer l’URL de Zillow à Web Unlocker et renvoyer le code HTML rendu.
def fetch_html(url):
response = requests.post(
API_URL,
headers={
"Content-Type": "application/json",
"X-Api-Key": API_KEY,
},
json={
"url": url,
"country": "US",
"city": "Boston",
"difficulty": "medium",
"expiration": 0,
},
timeout=120,
)
response.raise_for_status()
data = response.json()
html = data.get("html")
if not html:
raise ValueError("Unlocker response did not include an 'html' field.")
return htmlIl se passe plusieurs choses ici. Les champs » pays » et » ville » permettent à la demande de mieux correspondre à l’emplacement cible. J’ai utilisé la difficulté : « moyenne » parce que Zillow n’est pas une simple page statique, et qu’elle nécessite donc un processus de déblocage plus puissant.
Le champ d’expiration est fixé à 0, de sorte que j’obtiens une nouvelle réponse. Lorsque la demande aboutit, Web Unlocker renvoie une réponse JSON, et le code HTML rendu se trouve dans le champ html.
Étape 3 : Extraire les listes
Nous pouvons maintenant appliquer le plan d’analyse syntaxique que nous avons élaboré précédemment. Je vais créer une fonction extract_listings(). Cette fonction prend le HTML, trouve les données JSON de Zillow et extrait les annonces :
def extract_listings(html):
soup = BeautifulSoup(html, "html.parser")
next_data = soup.find("script", id="__NEXT_DATA__")
if not next_data or not next_data.string:
raise ValueError("Could not find Zillow's __NEXT_DATA__ script.")
data = json.loads(next_data.string)
search_state = data.get("props", {}).get("pageProps", {}).get("searchPageState", {})
list_results = (
search_state.get("cat1", {})
.get("searchResults", {})
.get("listResults", [])
)
listings = []
for item in list_results:
listings.append(
{
"zpid": item.get("zpid"),
"address": item.get("address"),
"price": item.get("price"),
"beds": item.get("beds"),
"baths": item.get("baths"),
"sqft": item.get("area"),
"status": item.get("statusType"),
"url": item.get("detailUrl"),
}
)
return listingsEn utilisant BeautifulSoup, je peux facilement aller directement au JSON structuré à l’intérieur de la page. Ensuite, j’ai analysé le contenu du script en JSON et j’ai obtenu le tableau listResults.
Chaque élément de listResults est une fiche de propriété, et pour chaque fiche, nous pouvons collecter des données précieuses telles que
- adresse
- prix
- lits
- bains
- zone
- statusType
- detailUrl
J’ai renommé la surface en sqft dans le résultat final parce que c’est plus facile à comprendre.
Étape 4 : Enregistrer les résultats dans un fichier JSON
Enfin, nous pouvons ajouter une fonction main() pour exécuter le scraper et enregistrer la sortie dans un fichier JSON :
def main():
print(f"Fetching data from: {SEARCH_URL}")
html = fetch_html(SEARCH_URL)
listings = extract_listings(html)
if not listings:
raise SystemExit("No listings found in Zillow's JSON data.")
with open(OUTPUT_FILE, "w", encoding="utf-8") as file:
json.dump(listings, file, indent=2)
print(f"Found {len(listings)} listings")
print(f"Saved results to {OUTPUT_FILE}")Cette fonction récupère la page, extrait les listes, vérifie que la liste n’est pas vide et enregistre le tout dans un fichier JSON. Une fois que les données ont l’air correctes, nous pouvons les convertir au format CSV ou les utiliser directement dans nos applications.
Le scénario complet
Voici tout le code que j’ai utilisé pour extraire avec succès mes listes Zillow :
from bs4 import BeautifulSoup
import requests
import json
API_URL = "https://client-api.floppy.host/v1/webUnlocker"
API_KEY = "Your_API_KEY"
SEARCH_URL = "https://www.zillow.com/boston-ma/"
OUTPUT_FILE = "live_zillow_boston.json"
def fetch_html(url):
response = requests.post(
API_URL,
headers={
"Content-Type": "application/json",
"X-Api-Key": API_KEY,
},
json={
"url": url,
"country": "US",
"city": "Boston",
"difficulty": "medium",
"expiration": 0,
},
timeout=120,
)
response.raise_for_status()
data = response.json()
html = data.get("html")
if not html:
raise ValueError("Unlocker response did not include an 'html' field.")
return html
def extract_listings(html):
soup = BeautifulSoup(html, "html.parser")
next_data = soup.find("script", id="__NEXT_DATA__")
if not next_data or not next_data.string:
raise ValueError("Could not find Zillow's __NEXT_DATA__ script.")
data = json.loads(next_data.string)
search_state = data.get("props", {}).get("pageProps", {}).get("searchPageState", {})
list_results = (
search_state.get("cat1", {})
.get("searchResults", {})
.get("listResults", [])
)
listings = []
for item in list_results:
listings.append(
{
"zpid": item.get("zpid"),
"address": item.get("address"),
"price": item.get("price"),
"beds": item.get("beds"),
"baths": item.get("baths"),
"sqft": item.get("area"),
"status": item.get("statusType"),
"url": item.get("detailUrl"),
}
)
return listings
def main():
print(f"Fetching data from: {SEARCH_URL}")
html = fetch_html(SEARCH_URL)
listings = extract_listings(html)
if not listings:
raise SystemExit("No listings found in Zillow's JSON data.")
with open(OUTPUT_FILE, "w", encoding="utf-8") as file:
json.dump(listings, file, indent=2)
print(f"Found {len(listings)} listings")
print(f"Saved results to {OUTPUT_FILE}")
if __name__ == "__main__":
main()Si tout est configuré correctement, vous devriez obtenir un résultat comme celui-ci :
[
{
"zpid": "59174136",
"address": "45 Garden St APT 3, Boston, MA 02114",
"price": "$685,000",
"beds": 2,
"baths": 1,
"sqft": 525,
"status": "FOR_SALE",
"url": "https://www.zillow.com/homedetails/45-Garden-St-APT-3-Boston-MA-02114/59174136_zpid/"
}
]À ce stade, votre scraper fonctionne, ce qui signifie que vous êtes maintenant en mesure de récupérer des informations clés à partir de n’importe quel listing Zillow.
Dépannage des problèmes courants
Si vous exploitez souvent les données immobilières de Zillow, vous vous heurterez certainement à des obstacles à un moment ou à un autre. J’en ai moi-même rencontré quelques-uns. Je peux donc vous dire à quoi vous attendre, notamment :
- Erreurs403: Cela signifie que Zillow a bloqué votre robot. Essayez de modifier vos en-têtes ou d’utiliser un proxy pour continuer à récupérer les données de Zillow.
- Réponsesvides: Cela peut être dû au rendu JavaScript. Essayez d’utiliser un outil qui rend entièrement la page avant de renvoyer le code HTML, comme le Web Unlocker.
- Donnéesmanquantes: Toutes les annonces ne contiennent pas les mêmes informations. Utilisez toujours .get() lorsque vous récupérez des données Zillow afin que votre scraper ne se plante pas sur une clé manquante.
Zillow n’offrant pas d’API gratuite, vous devrez trouver un moyen de la contourner. Si vous avez besoin d’un moyen fiable d’accéder aux données d’inscription de Zillow, le Web Unlocker de Floppydata est votre meilleur choix.
Conclusion
Zillow ne ressemble pas à un site hautement sécurisé, mais il est protégé par PerimeterX et un système de détection à plusieurs niveaux qui surveille votre IP, vos en-têtes, votre empreinte TLS et vos signaux comportementaux. Si vous agissez de manière suspecte, vous serez signalé et banni pour une durée indéterminée.
C’est pourquoi vous devez être prudent lorsque vous les récupérez. C’est là que Floppydata Web Unlocker intervient. Il :
- Rotation des procurations résidentielles premium
- Rotation des en-têtes et empreinte réelle du navigateur
- Chargement propre et HTML complet à chaque fois
- Factures uniquement pour les réponses positives
Avec cette configuration, vous n’avez pas à combattre le système anti-bot de Zillow par vous-même ; laissez Floppy Data Web Unlocker vous aider. Commencez à scraper Zillow dès maintenant avec 5 scraps gratuits.





