

Introduction
PHP a été l’un de mes premiers langages en tant que développeur web à l’époque, et j’aime toujours l’utiliser pour le scraping.
Ce tutoriel couvre ce que j’utilise réellement en production. Je vous guiderai à travers un workflow complet de scraping web en PHP en utilisant Floppydata Web Unlocker comme couche de scraping.
Pourquoi Floppydata ?
Parce qu’il fournit une API de scraping qui élimine le besoin de gérer des proxys, des en-têtes ou une logique anti-bot. À la fin de cet article, vous aurez une bonne connaissance de la manière d’effectuer du web scraping avec PHP.
Qu’est-ce que le web scraping en PHP ?
Le web scraping PHP consiste à utiliser du code PHP pour extraire des données de sites web. Tous les sites ne proposent pas d’API, comme Twitter par exemple. Dans de nombreux cas, le seul moyen d’obtenir les informations dont vous avez besoin est de récupérer la page et d’analyser le code HTML vous-même.
PHP est très utile si vous l’utilisez déjà tous les jours. Vous pouvez déposer les données scrappées directement dans un backend existant, les stocker dans MySQL, ou exécuter le scraper sur une tâche cron sans introduire un autre langage dans la pile.
La question principale n’est pas de savoir si PHP peut faire du scrape. Il le peut tout à fait. La vraie question est de savoir comment votre scraper gère les requêtes bloquées, les restrictions basées sur la localisation et les CAPTCHAs agressifs.
C’est exactement la raison pour laquelle j’ai associé PHP à Floppydata Web Unlocker pour aider à combler le fossé.
Bibliothèques de scraping web en PHP à connaître (2026)
PHP dispose de nombreuses bibliothèques de scraping, mais honnêtement, je n’en ai retenu que quelques-unes que j’utilise réellement. Voici un aperçu de ces bibliothèques.
- Guzzle : Un client HTTP solide qui gère proprement les requêtes POST, les charges utiles JSON, les redirections et les en-têtes. Nous l’utiliserons tout au long de ce tutoriel pour communiquer avec l’API Web Unlocker.
- Symfony DomCrawler : Il vous permet de naviguer dans le HTML et le XML en utilisant des sélecteurs CSS ou XPath. Associé au composant symfony/css-selector, il vous donne un filtrage de type jQuery qui fonctionne de manière fiable sur du HTML désordonné. Il est autonome, vous n’avez donc pas besoin du reste de Symfony.
- Symfony HttpBrowser : Il s’agit du remplacement moderne de la bibliothèque Goutte, désormais obsolète. Elle est construite au-dessus de BrowserKit et DomCrawler, et vous permet de simuler des clics, des soumissions de formulaires, et des chaînes de redirection. C’est idéal lorsque votre logique de scraping s’étend sur plusieurs pages.
- DiDOM : DiDOM est un parseur rapide, sans dépendance, avec une API de type jQuery. Parfait pour les petits scripts où vous voulez éviter de tirer des composants Symfony.
- Symfony Panther : Pilote un vrai navigateur Chrome ou Chromium via WebDriver. Vous l’utilisez lorsqu’un site rend tout en JavaScript (React, Vue, SPAs lourdes) et qu’une simple requête HTTP renvoie une coquille vide. C’est plus lourd, donc je ne l’utilise que lorsque rien d’autre ne fonctionne.
Goutte était une recommandation courante, mais elle est maintenant obsolète, et je ne recommanderais donc pas de construire un nouveau projet autour d’elle.
Pour ce guide, Guzzle et Symfony DomCrawler suffisent. Parce que le Web Unlocker exécute déjà le JavaScript et renvoie le rendu final du HTML, nous n’avons pas besoin d’exécuter un navigateur sans tête de notre côté.
Conditions préalables
Avant d’écrire du code, assurez-vous d’avoir mis en place les quatre éléments suivants. Si vous n’avez jamais mis en place un projet PHP à partir de zéro, ne vous inquiétez pas, je vous guiderai à travers chaque étape.
1. PHP 8.2 ou plus récent
PHP est préinstallé sur de nombreux systèmes Mac et Linux, mais il n’est jamais inutile de vérifier. Ouvrez votre terminal et vérifiez la version de PHP :
php -vSi PHP est déjà installé, vous devriez voir un numéro de version. Pour ce tutoriel, utilisez PHP 8.2 ou une version plus récente. C’est le point de départ le plus sûr avec les versions des dépendances que nous allons installer.
Si PHP est manquant, suivez les instructions pour l’installer :
# Windows (Chocolatey, run PowerShell as Administrator)
choco install php
# macOS (Homebrew)
brew install phpAprès l’installation, exécutez à nouveau php -v pour confirmer la version. Sur Homebrew, vous n’avez pas besoin de paquets php-curl ou php-xml séparés pour ce tutoriel. Ces extensions sont déjà incluses dans l’installation principale de PHP.
2. Compositeur
Composer est le gestionnaire de paquets standard pour PHP. C’est l’équivalent de npm ou pip pour les projets PHP. Nous allons l’utiliser pour installer Guzzle et les paquets d’analyseur Symfony.
Tout d’abord, vérifiez s’il est déjà disponible :
composer --versionSi Composer n’est pas encore installé, utilisez :
# Windows (Chocolatey, as Administrator)
choco install composer
# macOS (Homebrew)
brew install composerUne fois cela fait, composer --version devrait imprimer un numéro de version, et vous êtes prêt à créer le projet.
3. Un compte Floppydata
Créez un compte Floppydata et copiez votre clé API depuis le tableau de bord. Chaque nouveau compte reçoit 5 scrapes gratuits pour le Web Unlocker.
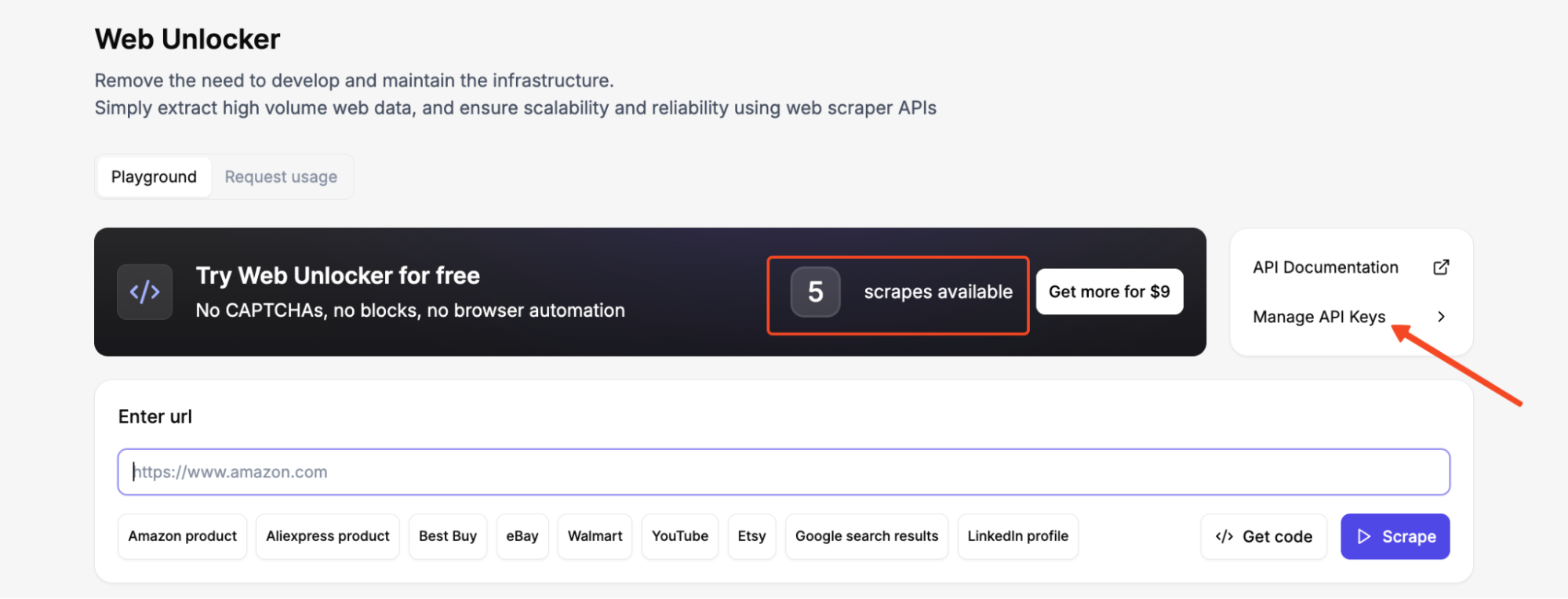
Après vous être connecté à votre tableau de bord, allez à Gérer les clés API dans le Web Unlocker et générez une clé API. Copiez-la immédiatement et conservez-la en lieu sûr.
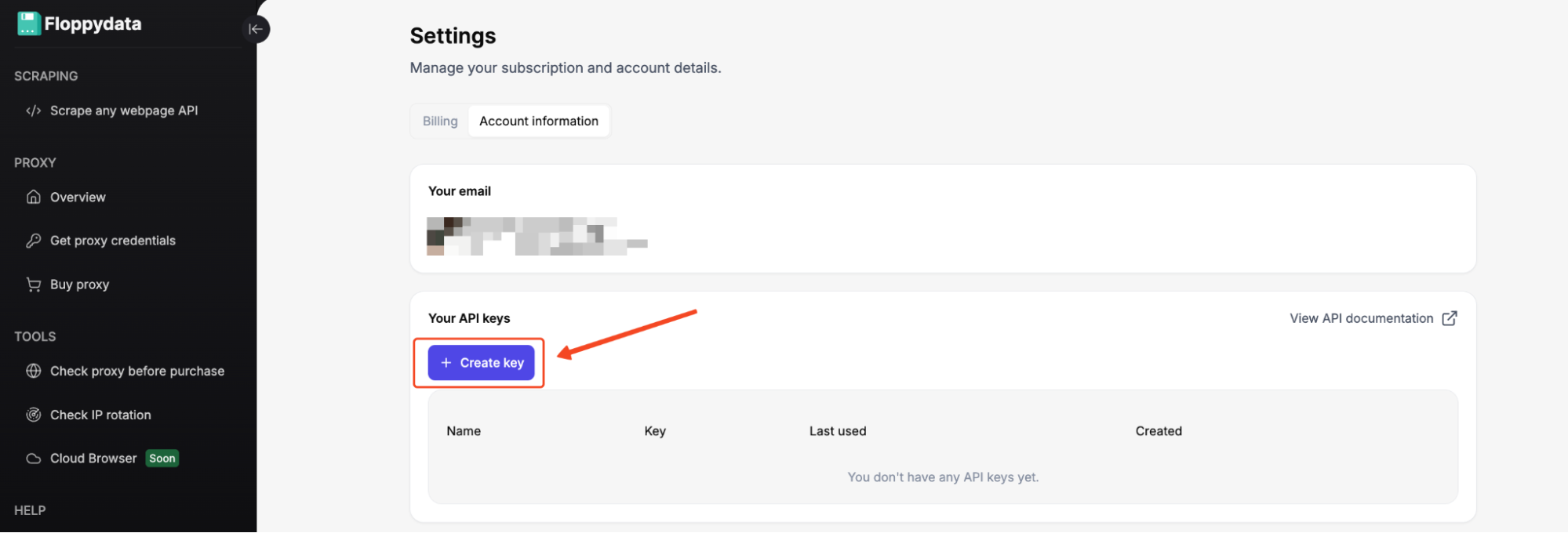
Vous utiliserez cette clé dans l’en-tête X-Api-Key de chaque requête de Web Unlocker. Nous allons l’ajouter à notre code dans quelques minutes.
4. Répertoire du projet et dépendances
Maintenant, créons le dossier dans lequel se trouvera notre scraper et installons les bibliothèques PHP dont nous avons besoin. Dans votre terminal :
mkdir php-scrape-countries
cd php-scrape-countriesInitialiser un nouveau projet Composer :
composer init --name="myname/country-scraper" --require="php:^8.2" --no-interactionInstallez maintenant les paquets dont nous avons besoin :
composer require guzzlehttp/guzzle symfony/dom-crawler:^7.4 symfony/css-selector:^7.4Composer téléchargera les trois bibliothèques et leurs dépendances dans un dossier vendor/ et créera un fichier composer.json qui indiquera exactement les versions que vous utilisez.
Désormais, chaque fichier PHP du projet peut charger les dépendances avec :
require_once __DIR__ . '/vendor/autoload.php';À ce stade, la configuration est terminée et nous pouvons passer au grattoir proprement dit.
Comment récupérer des données avec PHP en utilisant Floppydata Web Unlocker
Étape 1 : Testez votre cible
Je n’aime jamais écrire du code à l’aveugle, de sorte que je sais exactement à quels sélecteurs et à quelle structure de données m’attendre. Pour cet exemple, je vais cibler scrapethissite, un site de démonstration pour le scraping de données. Il contient une liste des 250 pays avec leur capitale, leur population et leur superficie.
Pour suivre l’évolution, visitez le terrain de jeu Floppydata Web Unlocker. Cet outil sans code est disponible directement à partir de votre tableau de bord et vous permet de voir le code HTML exact que l’API renverra sans avoir à configurer un projet.
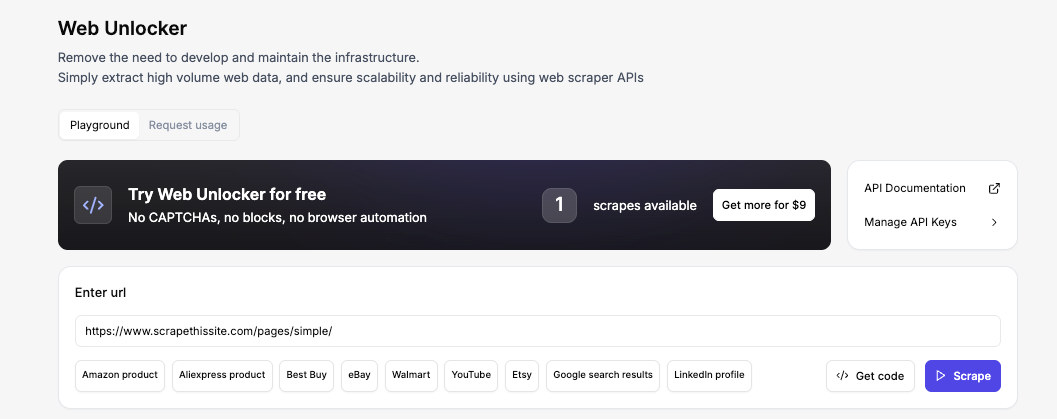
Saisissez l’URL et cliquez sur Scrape. En quelques secondes, vous verrez le code HTML complet dans l’aperçu de la sortie. C’est exactement le même HTML que votre script PHP recevra dans quelques instants.
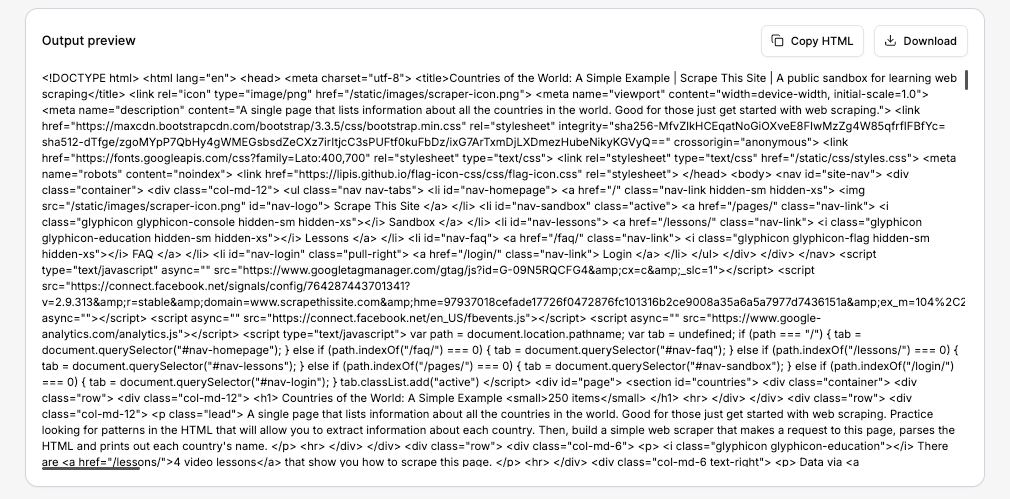
Si les données semblent correctes, vous pouvez copier le code HTML ou télécharger la réponse. Mais dans notre cas, nous laisserons le script PHP le faire automatiquement.
Étape 2 : Envoi de votre première demande de déblocage de site Web avec Guzzle
Le cœur de l’ensemble du flux de travail est une requête POST vers le point de terminaison de Floppydata :
https://client-api.floppy.host/v1/webUnlockerPour ce faire, nous créons d’abord un client Guzzle et préparons la configuration de la demande. Ensuite, nous envoyons la requête et traitons la réponse.
Créez un fichier appelé scrape.php et commencez par le squelette de base :
<?php
// scrape.php
require_once __DIR__ . '/vendor/autoload.php';
use GuzzleHttp\Client;
$apiKey = 'YOUR_API_KEY'; // Replace with your real key
$targetUrl = 'https://www.scrapethissite.com/pages/simple/';
$client = new Client([
'base_uri' => 'https://client-api.floppy.host',
'timeout' => 60,
]);Remplacez YOUR_API_KEY par votre véritable clé. Maintenant, nous construisons l’appel POST réel. Nous envoyons du JSON au point de terminaison de l’API, nous incluons la clé d’API dans les en-têtes et nous passons l’URL cible ainsi que quelques args dans le corps du message :
$response = $client->post('/v1/webUnlocker', [
'headers' => [
'Content-Type' => 'application/json',
'X-Api-Key' => $apiKey,
],
'json' => [
'url' => $targetUrl,
'country' => 'US',
'city' => 'New York',
'difficulty' => 'low',
'expiration' => 0,
],
]);
$payload = json_decode((string) $response->getBody(), true);
$html = $payload['html'] ?? '';
echo "HTML received! Length: " . strlen($html) . " characters\n";Les champs » pays » et » ville » indiquent au Web Unlocker le lieu géographique par lequel la demande doit être acheminée. Le champ difficulty (difficulté) détermine le degré d’agressivité avec lequel le déverrouilleur gère les protections anti-bots. J’utilise ici le champ » faible » car la cible de notre bac à sable ne dispose d’aucune protection.
Pour les cibles protégées par Cloudflare ou DataDome, réglez ce paramètre sur moyen afin que le déverrouilleur applique une logique de résolution d’empreintes digitales et de CAPTCHA plus forte.
Notez que le Web Unlocker renvoie le code HTML brut dans un objet JSON, ce qui signifie que vous devez décoder le JSON et extraire les balises de la page dans le champ html.
Si vous oubliez cela et que vous traitez tout le corps de la réponse comme du HTML, votre analyseur s’arrêtera. Avec ceci, la partie requête est terminée, et nous pouvons passer à l’analyse syntaxique.
Étape 3 : Inspecter la structure de la page
Une fois que la requête a abouti, la tâche suivante consiste à inspecter la structure de la page et à cibler les éléments répétés qui contiennent les données souhaitées. Chaque pays de la page suit exactement ce modèle HTML :
<div class="col-md-4 country">
<h3 class="country-name">
<i class="flag-icon flag-icon-ad"></i>
Andorra
</h3>
<div class="country-info">
<strong>Capital:</strong> <span class="country-capital">Andorra la Vella</span><br>
<strong>Population:</strong> <span class="country-population">84000</span><br>
<strong>Area (km<sup>2</sup>):</strong> <span class="country-area">468.0</span><br>
</div>
</div>C’est cette structure répétée qui rend cette page si prévisible. Chaque fiche pays utilise les mêmes noms de classe : .country pour l’enveloppe, .country-name pour l’en-tête, et.country-capital, .country-population, et .country-area pour les champs de données à l’intérieur de .country-info.
Étape 4 : Analyse des données avec Symfony DomCrawler
Comme les classes sont cohérentes sur l’ensemble des 250 entrées, nous pouvons parcourir en boucle chaque élément .country et extraire les valeurs des sélecteurs enfants. Mais tout d’abord, ajoutons une petite fonction d’aide pour nous aider à nettoyer le texte que nous extrayons :
use Symfony\Component\DomCrawler\Crawler;
function normalizeText(string $text): string
{
return preg_replace('/\s+/', ' ', trim($text)) ?? trim($text);
}Si vous regardez le code HTML brut, les noms de pays sont entourés d’espaces blancs et de nouvelles lignes à cause des balises <i> qui se trouvent à l’intérieur des balises <h3>.
La fonction normalizeText() permet de supprimer les espaces blancs de début et de fin, puis utilise une expression rationnelle pour réduire les espaces ou les nouvelles lignes restantes, de sorte que des noms comme Andorra ou St. John’s reviennent proprement au lieu de porter les espaces blancs restants du code HTML.
Une fois l’assistant prêt, nous créons une instance de Crawler et passons en revue chaque carte de pays :
$crawler = new Crawler($html);
$countries = [];
$crawler->filter('.country')->each(function (Crawler $node) use (&$countries): void {
$countries[] = [
'name' => normalizeText($node->filter('.country-name')->text()),
'capital' => normalizeText($node->filter('.country-capital')->text()),
'population' => normalizeText($node->filter('.country-population')->text()),
'area' => normalizeText($node->filter('.country-area')->text()),
];
});
echo 'Parsed ' . count($countries) . " countries\n";DomCrawler nous donne un moyen propre de nous déplacer à travers le HTML en utilisant des sélecteurs CSS. Nous commençons par envelopper le HTML dans un objet Crawler, puis nous filtrons jusqu’à chaque bloc .country de la page. A l’intérieur de chaque bloc, nous récupérons le nom, la capitale, la population et la superficie.
À ce stade, si vous exécutez le script, vous devriez voir le message « Parsed 250 countries » s’afficher dans le terminal.
Étape 5 : Exporter les résultats au format CSV et JSON
Une fois que l’analyseur syntaxique vous a fourni un tableau $countries, l’exportation des données devient très simple.
$csvHandle = fopen('countries.csv', 'w');
fputcsv($csvHandle, ['Country', 'Capital', 'Population', 'Area (km2)'], ',', '"', '');
foreach ($countries as $country) {
fputcsv($csvHandle, [
$country['name'],
$country['capital'],
$country['population'],
$country['area'],
], ',', '"', '');
}
fclose($csvHandle);
file_put_contents('countries.json', json_encode($countries, JSON_PRETTY_PRINT | JSON_UNESCAPED_SLASHES));L’exportation CSV est utile car elle donne aux lecteurs un fichier qu’ils peuvent ouvrir immédiatement dans Excel, Google Sheets ou tout autre outil de feuille de calcul. L’exportation JSON est tout aussi pratique s’ils veulent introduire les données scannées dans un autre script PHP ou une API ultérieurement.
Une petite mise à jour ici est l’argument explicite escape dans fputcsv(). Sur les nouvelles versions de PHP, cela évite les avertissements de dépréciation et permet à l’exemple de rester propre lorsque les lecteurs l’exécutent depuis le terminal.
Étape n° 6 : Rassembler tous les éléments dans un seul script
Maintenant que chaque partie fonctionne de manière autonome, voici le script complet :
<?php
declare(strict_types=1);
require_once __DIR__ . '/vendor/autoload.php';
use GuzzleHttp\Client;
use Symfony\Component\DomCrawler\Crawler;
function normalizeText(string $text): string
{
return preg_replace('/\s+/', ' ', trim($text)) ?? trim($text);
}
$apiKey = 'YOUR_API_KEY';
$targetUrl = 'https://www.scrapethissite.com/pages/simple/';
if ($apiKey === 'YOUR_API_KEY') {
fwrite(STDERR, "Replace YOUR_API_KEY before running the script.\n");
exit(1);
}
$client = new Client([
'base_uri' => 'https://client-api.floppy.host',
'timeout' => 60,
]);
try {
$response = $client->post('/v1/webUnlocker', [
'headers' => [
'Content-Type' => 'application/json',
'X-Api-Key' => $apiKey,
],
'json' => [
'url' => $targetUrl,
'country' => 'US',
'city' => 'New York',
'difficulty' => 'low',
'expiration' => 0,
],
]);
} catch (Throwable $e) {
fwrite(STDERR, "Request failed: {$e->getMessage()}\n");
exit(1);
}
$payload = json_decode((string) $response->getBody(), true);
if (!is_array($payload) || !isset($payload['html']) || !is_string($payload['html'])) {
fwrite(STDERR, "Unexpected API response. Expected JSON with an html field.\n");
exit(1);
}
$crawler = new Crawler($payload['html']);
$countries = [];
$crawler->filter('.country')->each(function (Crawler $node) use (&$countries): void {
$countries[] = [
'name' => normalizeText($node->filter('.country-name')->text()),
'capital' => normalizeText($node->filter('.country-capital')->text()),
'population' => normalizeText($node->filter('.country-population')->text()),
'area' => normalizeText($node->filter('.country-area')->text()),
];
});
if ($countries === []) {
fwrite(STDERR, "No countries were parsed.\n");
exit(1);
}
$csvHandle = fopen(__DIR__ . '/countries.csv', 'w');
if ($csvHandle === false) {
fwrite(STDERR, "Could not create countries.csv.\n");
exit(1);
}
fputcsv($csvHandle, ['Country', 'Capital', 'Population', 'Area (km2)'], ',', '"', '');
foreach ($countries as $country) {
fputcsv($csvHandle, [
$country['name'],
$country['capital'],
$country['population'],
$country['area'],
], ',', '"', '');
}
fclose($csvHandle);
file_put_contents(__DIR__ . '/countries.json', json_encode($countries, JSON_PRETTY_PRINT | JSON_UNESCAPED_SLASHES));
echo 'Done! Parsed ' . count($countries) . " countries.\n";
echo "Saved countries.csv and countries.json\n";Remplacez ‘YOUR_API_KEY’ et exécutez-le comme suit :
php scrape.phpLorsque tout est configuré correctement, le script récupère la page via Web Unlocker, analyse les 250 pays et écrit les fichiers countries.csv et countries.json dans le dossier de votre projet.
Visualisation des résultats
Une fois le script terminé, vous pouvez ouvrir le fichier countries.csv immédiatement. Les premières lignes ressembleront à ceci :
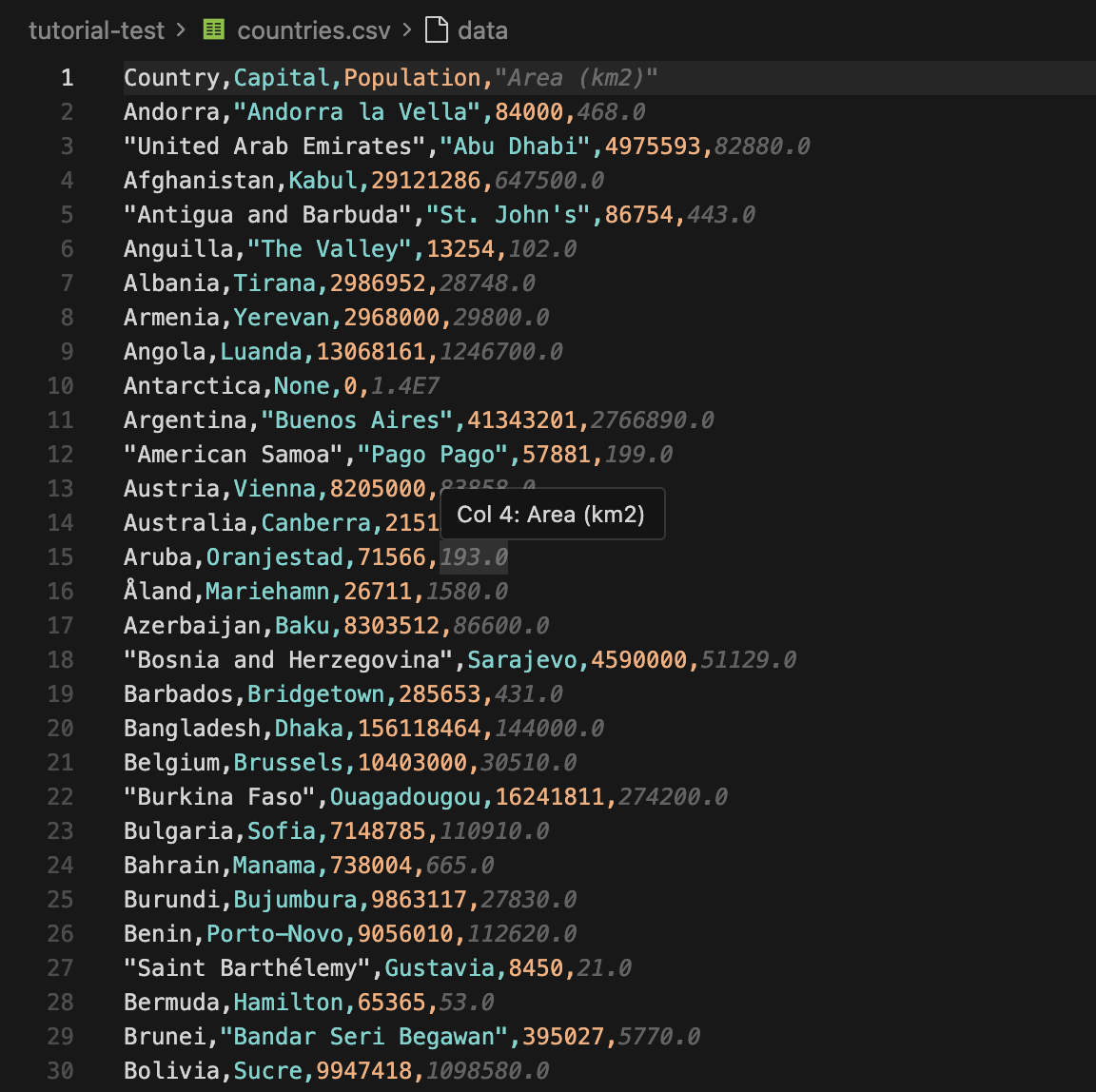
Vous pouvez maintenant importer le CSV dans une feuille de calcul ou envoyer le JSON dans une autre application. Si vous souhaitez utiliser ce flux de travail pour le suivi des prix, vous pouvez l’associer aux proxies de suivi des prix de Floppydata.
Traiter les mesures anti-scraping
Une simple page statique n’est pas difficile à analyser, comme nous venons de le voir. Mais les sites protégés peuvent être un casse-tête.
Vous pouvez rencontrer des blocages, des données manquantes, des CAPTCHA, un rendu JavaScript ou des limites de taux. C’est là qu’un scraper PHP normal commence à éprouver des difficultés.
Voici les problèmes les plus courants auxquels vous pouvez être confronté :
- Blocage de l’adresse IP : Les sites web peuvent bloquer votre adresse IP s’ils détectent plusieurs requêtes provenant de la même IP sur une courte période.
- CAPTCHAs : Les systèmes CAPTCHA sont utilisés pour différencier les robots des humains en présentant des défis difficiles à résoudre pour les robots.
- Limitation du taux : Les sites web limitent souvent le nombre de requêtes que vous pouvez effectuer dans un laps de temps donné afin d’éviter un scraping excessif.
- Détection de l’agent utilisateur : Les agents utilisateurs qui ne sont pas des navigateurs sont bloqués parce qu’ils ne ressemblent pas à de vrais visiteurs.
- Défis JavaScript : Le contenu n’est chargé qu’après l’exécution de JavaScript, ce qu’une simple requête HTTP peut ne pas faire.
Vous pouvez essayer de résoudre ces problèmes manuellement, mais ce n’est ni pratique ni évolutif.
C’est là que Floppydata Web Unlocker entre en jeu. Au lieu de relever chaque défi vous-même, vous pouvez vous décharger de toute la couche anti-bot et vous concentrer sur l’extraction et le stockage des données.
Les poignées de Floppydata Web Unlocker :
- Rotation d’IP avec un grand nombre de proxies résidentiels et de centres de données
- Empreintes des navigateurs et navigateurs sans tête
- Rendu JavaScript pour les pages dynamiques
- Réessais automatiques et résolution du CAPTCHA
- Ciblage géographique jusqu’au niveau de la ville
Si vous avez besoin de plus de contrôle, Floppydata propose également des proxys résidentiels statiques pour le scraping de longue durée et des proxys de centre de données pour le travail en volume à grande vitesse.
Mais pour la plupart des pages protégées, Web Unlocker est le moyen le plus rapide de passer d’une requête bloquée à un code HTML analysable.
Dernières réflexions
PHP est un langage très performant pour le web scraping, et vous devriez maintenant avoir des bases solides sur le web scraping avec PHP.
Je vais arrêter ce tutoriel à ce stade puisqu’il s’agit d’une introduction au web scraping avec PHP. Dans les prochains tutoriels, nous développerons notre scraper afin qu’il puisse suivre les liens, gérer la pagination et scanner des cibles plus complexes.
Si vous souhaitez en savoir plus sur le web scraping, consultez les ressources suivantes :
Prêt à essayer le Web Unlocker ? Commencez dès aujourd’hui avec 5 scraps gratuits et scrapez tout ce que vous voulez sans vous prendre la tête.






