

Introdução
Por ser uma das principais plataformas imobiliárias dos EUA, a Zillow se torna uma plataforma que muitas empresas desejam explorar para obter dados sobre propriedades. Atualmente, a plataforma recebe cerca de 243 milhões de visitas por mês, portanto, naturalmente, ela contém uma enorme quantidade de dados úteis sobre imóveis.
No entanto, os desenvolvedores frequentemente compartilham no Reddit a dificuldade de contornar o firewall do Zillow ou de serem permanentemente bloqueados ao tentar fazer scraping. Se você acabou de passar por isso e está procurando um guia estável que funcione, continue lendo.
Neste guia, mostrarei a você como extrair os principais dados de listagem do Zillow usando Python e uma API da Web simples.
O que é Zillow Scraping?
O scraping do Zillow é o processo de coletar dados imobiliários disponíveis publicamente nas páginas do Zillow e transformá-los em um formato estruturado, como CSV ou JSON, que você possa usar para fins comerciais ou pessoais
Em vez de abrir as listagens uma a uma, você pode usar um raspador para extrair os principais detalhes das páginas de pesquisa e das páginas de detalhes das listagens de propriedades.
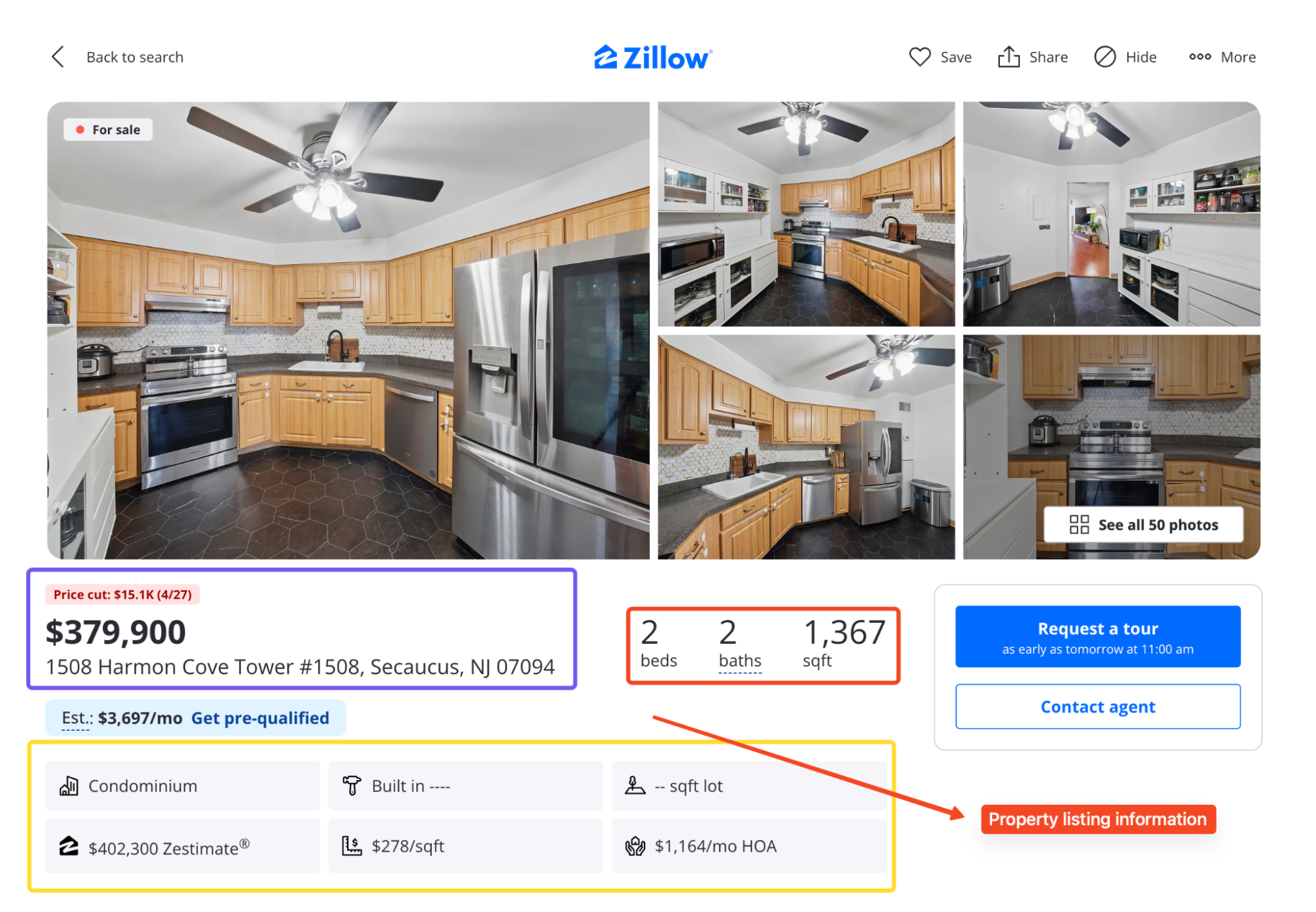
Entre as duas páginas, você pode retirar:
- Preço, endereço, camas, banheiros, metragem quadrada, status e dias no mercado
- Estimativa de aluguel e estimativa de aluguel
- Fotos do anúncio e nome do corretor
- Histórico de preços e histórico de impostos
Por que extrair dados do Zillow?
Imagine poder acessar listagens de propriedades atualizadas, detalhes de preços e análises de mercado sem precisar abrir manualmente centenas de páginas do Zillow.
Esse é o valor real do scraping do Zillow.
Se você trabalha com imóveis, investimento em propriedades, pesquisa de mercado, geração de leads ou análise de preços, o Zillow tem dados públicos úteis que podem ajudá-lo a identificar tendências mais rapidamente.
O que faz com que o Zillow seja tão difícil de ser eliminado?
A Zillow não vai tão longe quanto algumas plataformas no que diz respeito ao bloqueio de bots, mas ainda assim foi criada para bloquear o tráfego que não parece humano.
A maioria dos scrapers falha por dois motivos. Vamos dar uma olhada em ambos:
Proteção PerimeterX
A Zillow usa o PerimeterX para detectar e bloquear o tráfego de bots em tempo real. Se o seu scraper tiver os cabeçalhos errados, vier de um IP de baixa confiança ou enviar muitas solicitações com muita rapidez, ele poderá ser sinalizado.
Na maioria das vezes, esse sinalizador leva a um quebra-cabeça CAPTCHA, que quebraria a maioria dos scrapers. O PerimeterX também verifica muitos sinais, inclusive cabeçalhos, comportamento do navegador, impressões digitais de TLS, velocidade de solicitação e reputação de IP.
Se o tráfego parecer automatizado, o scraper pode nunca chegar aos dados reais da listagem.
Portanto, mesmo que você renderize a página em um navegador sem cabeça, isso não garante o sucesso. Você ainda precisa de proxies de alta qualidade, sessões limpas e comportamento de solicitação realista.
É por isso que eu prefiro usar o Web Unlocker da Floppydata para raspar o Zillow.
HTML não estruturado e sem seletores estáveis
Analisar o Zillow também pode ser tão frustrante quanto passar por suas defesas. Quase não há nomes de classe, IDs ou atributos de dados consistentes no código-fonte da página.
Os elementos que parecem simples, como o preço ou o endereço, são envolvidos em tags genéricas <div> ou não têm nenhum identificador.
Pior ainda, os nomes das classes mudam com frequência e não seguem nenhum padrão. Portanto, você precisa usar uma correspondência flexível (como find() baseado em palavras-chave ou até mesmo regex) para extrair dados de nós de texto bruto.
Isso faz com que o Zillow seja um dos sites mais instáveis para extração se você estiver confiando em seletores estáticos.
Extrair informações de listagem do Zillow com Python
Para este guia, vou me concentrar na página de resultados de pesquisa do Zillow em Boston, que contém várias listagens de imóveis. A partir daí, podemos extrair campos como preço, endereço, camas, banheiros, metragem quadrada, status e links de listagem.
Observação: As páginas do Zillow mudam com frequência. Se a página de Boston estiver diferente quando você ler isto, acesse o Zillow, pesquise qualquer cidade ou bairro, copie o URL dos resultados e substitua-o no código.
Vamos começar com a configuração:
Pré-requisitos
Você precisará de três coisas antes de começar:
- Python 3.10 ou superior instalado em seu computador
- Uma conta Floppydata com uma chave de API para o Web Unlocker
- Duas bibliotecas Python: requests para chamadas HTTP e beautifulsoup4 para análise de HTML
Se você ainda não tiver uma conta Floppydata, inscreva-se em floppydata.com e obtenha sua chave de API no painel do Web Unlocker.
As novas contas vêm com cinco raspagens gratuitas, portanto você pode seguir todo este tutorial sem pagar nada.
Normalmente, a biblioteca de solicitações vem pré-instalada, mas você pode executar esse comando para garantir que ela esteja instalada corretamente:
pip install requests beautifulsoup4Depois de fazer isso, crie uma nova pasta e um novo arquivo de projeto:
mkdir zillow-scraper
cd zillow-scraper
touch zillow_scraper.pyAgora, você está pronto para começar.
Enviando a primeira solicitação
A primeira coisa que a maioria das pessoas tenta fazer é uma solicitação Python normal. Normalmente, ela se parece com isso:
import requests
url = "https://www.zillow.com/boston-ma/"
response = requests.get(url)
print(response.status_code)
print(response.text)Mas quando testei isso, não foram necessárias nem duas tentativas, pois minha primeira solicitação foi bloqueada. Recebi uma resposta 403 com uma página de bloqueio do PerimeterX:
403
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<meta name="description" content="px-captcha">
<title>Access to this page has been denied</title>
</head>Esse é o problema de raspar o Zillow diretamente. Uma solicitação Python normal não se comporta como uma sessão de navegação real. Ela também não tem a impressão digital correta do navegador, a qualidade do IP ou a renderização do JavaScript, o que permite que a Zillow a identifique imediatamente e bloqueie a solicitação.
É por isso que não construo o raspador principal com base em chamadas diretas requests() para o Zillow. Em vez disso, envio minhas solicitações por meio do Web Unlocker da Floppydata e deixo que ele cuide das partes mais difíceis.
Raspagem do Zillow com o Floppydata Web Unlocker
Vamos enviar uma solicitação para a página de pesquisa usando o Web Unlocker. O Zillow não é o alvo mais difícil de ser extraído, mas ele se preocupa com a reputação do IP e o comportamento do navegador.
É aqui que o Web Unlocker entra em ação. Ele roteia sua solicitação por meio de um IP residencial confiável, aplica uma impressão digital real do navegador e retorna o HTML totalmente renderizado.
Um aspecto que realmente me agrada no Floppydata é que você só paga por solicitações bem-sucedidas. Se um scrape falhar, ele não será contabilizado em seu uso.
O painel também mostra análises de solicitações em tempo real, para que você possa acompanhar o uso, as taxas de sucesso e os créditos restantes sem sair da página.
Antes de escrever qualquer código, gosto de testar primeiro o URL de destino no Web Unlocker sem código. Isso me permite ver o HTML de resposta antes de criar um analisador, para que eu saiba exatamente quais seletores e dados esperar.
Usar a ferramenta Web Unlocker é literalmente tão fácil quanto o ABC. Basta abrir o Web Unlocker no painel do Floppydata. Em seguida, cole este URL“https://www.zillow.com/boston-ma/”, clique no botão Scrape e aguarde alguns segundos
Quando a extração for concluída, verifique o painel de visualização de saída abaixo. Você deverá ver a página HTML completa contendo os resultados da pesquisa do Zillow.
Se os dados parecerem bons, use Copiar HTML para capturá-los ou Baixar para salvar o arquivo localmente.
Entenda a estrutura de paginação do Zillow
A visualização de saída retornou HTML bruto, o que é útil porque posso inspecionar a estrutura exata antes de escrever o código.
Isso é semelhante a abrir as ferramentas de desenvolvimento do navegador pressionando F12 e inspecionando a página diretamente. Dentro do HTML baixado, encontrei uma coisa importante que torna o analisador muito mais fácil.
A maioria dos tutoriais dirá a você para pegar os cartões de listagem com seletores CSS, mas o Zillow renderiza apenas 9 cartões na marcação da página. Os outros 32 são carregados à medida que você rola a página, portanto, a extração com seletores CSS perde a maior parte dos dados.
Em vez disso, os resultados da pesquisa estão em um grande objeto JSON no HTML da página. Esse JSON fica dentro dessa tag de script:
<script id="__NEXT_DATA__" type="application/json">A página usa esse JSON para carregar os dados no frontend, e nós também podemos lê-los. Dentro desse JSON, as listagens estão neste exato caminho:
data["props"]["pageProps"]["searchPageState"]["cat1"]["searchResults"]["listResults"]Portanto, nosso plano de análise é simples.
Encontraremos o script __NEXT_DATA__ com o BeautifulSoup, analisaremos o JSON, passaremos para a matriz listResults e extrairemos os campos de que precisamos.
Raspagem da Web do Zillow com Python e Web Unlocker
Agora podemos passar do painel para o código.
O snippet do painel usa httpx, mas usarei requests aqui porque é mais familiar para a maioria dos leitores de Python.
Etapa 1: Configurar a solicitação
Vamos começar com a configuração básica. Precisamos do endpoint do Web Unlocker, da nossa chave de API e do URL de destino do Zillow:
import requests
import json
from bs4 import BeautifulSoup
API_URL = "https://client-api.floppy.host/v1/webUnlocker"
API_KEY = "YOUR_API_KEY"
SEARCH_URL = "https://www.zillow.com/boston-ma/"
SEARCH_URL = "live_zillow_boston.json"Substituir YOUR_API_KEY com a chave do seu painel do Floppydata.
Estou usando Boston como o mercado-alvo aqui, mas se você quiser fazer o scraping de outra cidade, basta substituir o URL de pesquisa.
Etapa 2: Obtenha a página por meio do Web Unlocker
O Web Unlocker recebe uma carga útil JSON com a URL de destino e algumas opções. Ele retorna uma resposta JSON que contém o HTML renderizado em um campo html:
Agora, crio uma função fetch_html()para enviar o URL do Zillow para o Web Unlocker e retornar o HTML renderizado
def fetch_html(url):
response = requests.post(
API_URL,
headers={
"Content-Type": "application/json",
"X-Api-Key": API_KEY,
},
json={
"url": url,
"country": "US",
"city": "Boston",
"difficulty": "medium",
"expiration": 0,
},
timeout=120,
)
response.raise_for_status()
data = response.json()
html = data.get("html")
if not html:
raise ValueError("Unlocker response did not include an 'html' field.")
return htmlAlgumas coisas estão acontecendo aqui. Os campos de país e cidade ajudam a solicitação a corresponder melhor ao local de destino. Usei a dificuldade: “média” porque o Zillow não é uma página estática simples, portanto, precisa de um processo de desbloqueio mais forte.
O campo de expiração está definido como 0, portanto, recebo uma nova resposta. Depois que a solicitação é bem-sucedida, o Web Unlocker retorna uma resposta JSON, e o HTML renderizado está dentro do campo html.
Etapa 3: Extraia as listagens
Agora podemos aplicar o plano de análise anterior. Criarei uma função extract_listings(). Essa função pega o HTML, encontra os dados JSON do Zillow e extrai as listagens:
def extract_listings(html):
soup = BeautifulSoup(html, "html.parser")
next_data = soup.find("script", id="__NEXT_DATA__")
if not next_data or not next_data.string:
raise ValueError("Could not find Zillow's __NEXT_DATA__ script.")
data = json.loads(next_data.string)
search_state = data.get("props", {}).get("pageProps", {}).get("searchPageState", {})
list_results = (
search_state.get("cat1", {})
.get("searchResults", {})
.get("listResults", [])
)
listings = []
for item in list_results:
listings.append(
{
"zpid": item.get("zpid"),
"address": item.get("address"),
"price": item.get("price"),
"beds": item.get("beds"),
"baths": item.get("baths"),
"sqft": item.get("area"),
"status": item.get("statusType"),
"url": item.get("detailUrl"),
}
)
return listingsUsando o BeautifulSoup, posso facilmente ir direto para o JSON estruturado dentro da página. Em seguida, analisei o conteúdo do script como JSON e obtive a matriz listResults.
Cada item em listResults é uma listagem de propriedades e, a partir de cada listagem, podemos coletar dados valiosos, como
- endereço
- preço
- camas
- banhos
- área
- statusType
- detailUrl
Renomeei a área para sqft na saída final porque é mais fácil de entender.
Etapa 4: Salve os resultados em um arquivo JSON
Por fim, podemos adicionar uma função main() para executar o raspador e salvar a saída em um arquivo JSON:
def main():
print(f"Fetching data from: {SEARCH_URL}")
html = fetch_html(SEARCH_URL)
listings = extract_listings(html)
if not listings:
raise SystemExit("No listings found in Zillow's JSON data.")
with open(OUTPUT_FILE, "w", encoding="utf-8") as file:
json.dump(listings, file, indent=2)
print(f"Found {len(listings)} listings")
print(f"Saved results to {OUTPUT_FILE}")Essa função busca a página, extrai as listagens, verifica se a lista não está vazia e salva tudo em um arquivo JSON. Quando os dados parecerem bons, poderemos convertê-los em CSV mais tarde ou usar os dados diretamente em nossos aplicativos.
O roteiro completo
Aqui está todo o código que usei para extrair com êxito minhas listagens do Zillow:
from bs4 import BeautifulSoup
import requests
import json
API_URL = "https://client-api.floppy.host/v1/webUnlocker"
API_KEY = "Your_API_KEY"
SEARCH_URL = "https://www.zillow.com/boston-ma/"
OUTPUT_FILE = "live_zillow_boston.json"
def fetch_html(url):
response = requests.post(
API_URL,
headers={
"Content-Type": "application/json",
"X-Api-Key": API_KEY,
},
json={
"url": url,
"country": "US",
"city": "Boston",
"difficulty": "medium",
"expiration": 0,
},
timeout=120,
)
response.raise_for_status()
data = response.json()
html = data.get("html")
if not html:
raise ValueError("Unlocker response did not include an 'html' field.")
return html
def extract_listings(html):
soup = BeautifulSoup(html, "html.parser")
next_data = soup.find("script", id="__NEXT_DATA__")
if not next_data or not next_data.string:
raise ValueError("Could not find Zillow's __NEXT_DATA__ script.")
data = json.loads(next_data.string)
search_state = data.get("props", {}).get("pageProps", {}).get("searchPageState", {})
list_results = (
search_state.get("cat1", {})
.get("searchResults", {})
.get("listResults", [])
)
listings = []
for item in list_results:
listings.append(
{
"zpid": item.get("zpid"),
"address": item.get("address"),
"price": item.get("price"),
"beds": item.get("beds"),
"baths": item.get("baths"),
"sqft": item.get("area"),
"status": item.get("statusType"),
"url": item.get("detailUrl"),
}
)
return listings
def main():
print(f"Fetching data from: {SEARCH_URL}")
html = fetch_html(SEARCH_URL)
listings = extract_listings(html)
if not listings:
raise SystemExit("No listings found in Zillow's JSON data.")
with open(OUTPUT_FILE, "w", encoding="utf-8") as file:
json.dump(listings, file, indent=2)
print(f"Found {len(listings)} listings")
print(f"Saved results to {OUTPUT_FILE}")
if __name__ == "__main__":
main()Se tudo estiver configurado corretamente, você verá um resultado como este:
[
{
"zpid": "59174136",
"address": "45 Garden St APT 3, Boston, MA 02114",
"price": "$685,000",
"beds": 2,
"baths": 1,
"sqft": 525,
"status": "FOR_SALE",
"url": "https://www.zillow.com/homedetails/45-Garden-St-APT-3-Boston-MA-02114/59174136_zpid/"
}
]Nesse ponto, seu scraper está funcionando, o que significa que agora você pode extrair informações importantes de qualquer listagem do Zillow.
Solução de problemas comuns
Se você costuma pesquisar os dados de propriedades do Zillow com frequência, é provável que encontre algumas barreiras em alguns momentos. Eu mesmo já enfrentei algumas delas. Portanto, posso dizer a você o que esperar, inclusive:
- Erros403: Isso significa que a Zillow bloqueou seu bot. Tente alterar seus cabeçalhos ou usar um proxy para continuar coletando dados do Zillow.
- Respostasvazias: Isso pode ser devido à renderização do JavaScript. Tente usar uma ferramenta que renderize totalmente a página antes de retornar o HTML, como o Web Unlocker.
- Dadosausentes: Nem todas as listagens têm as mesmas informações. Sempre use .get() ao extrair dados do Zillow para que seu scraper não trave em uma chave ausente.
Como o Zillow não oferece uma API gratuita, você terá que encontrar uma maneira de contornar isso. Se você precisa de uma maneira confiável de acessar os dados de listagem do Zillow, o Web Unlocker da Floppydata é sua melhor aposta.
Conclusão
O Zillow não parece ser um site de alta segurança, mas é protegido pelo PerimeterX e por um sistema de detecção em camadas que observa seu IP, cabeçalhos, impressão digital TLS e sinais comportamentais. Se você agir de forma suspeita, será sinalizado e banido indefinidamente.
Portanto, você precisa ter cuidado ao raspá-lo. É aí que entra o Floppydata Web Unlocker. Ele:
- Rotaciona proxies residenciais premium
- Rotação de cabeçalhos e impressão digital real do navegador
- Sempre carrega de forma limpa e totalmente em HTML
- Somente faturas para respostas bem-sucedidas
Com essa configuração, você não precisa combater o sistema anti-bot do Zillow sozinho; deixe o Floppy Data Web Unlocker ajudá-lo. Comece a fazer scraping do Zillow agora com 5 scrapes gratuitos.





