

Einführung
Als eine der führenden Immobilienplattformen in den USA ist Zillow eine Plattform, die viele Unternehmen für Immobiliendaten nutzen möchten. Die Plattform wird derzeit rund 243 Millionen Mal pro Monat besucht, so dass sie natürlich eine große Menge an nützlichen Immobiliendaten enthält.
Auf Reddit berichten Entwickler jedoch häufig, dass sie Schwierigkeiten haben, die Firewall von Zillow zu umgehen, oder dass sie permanent blockiert werden, wenn sie versuchen, die Daten zu scrapen. Wenn Sie gerade diese Erfahrung gemacht haben und nach einer stabilen Anleitung suchen, die funktioniert, lesen Sie weiter.
In dieser Anleitung zeige ich Ihnen, wie Sie mit Python und einer einfachen Web-API wichtige Daten aus Zillow extrahieren können.
Was ist Zillow Scraping?
Beim Zillow Scraping werden öffentlich verfügbare Immobiliendaten von Zillow-Seiten gesammelt und in ein strukturiertes Format wie CSV oder JSON umgewandelt, das Sie für geschäftliche oder private Zwecke nutzen können.
Anstatt ein Angebot nach dem anderen zu öffnen, können Sie einen Scraper verwenden, um die wichtigsten Details aus den Such- und Detailseiten der Immobilienangebote zu ziehen.
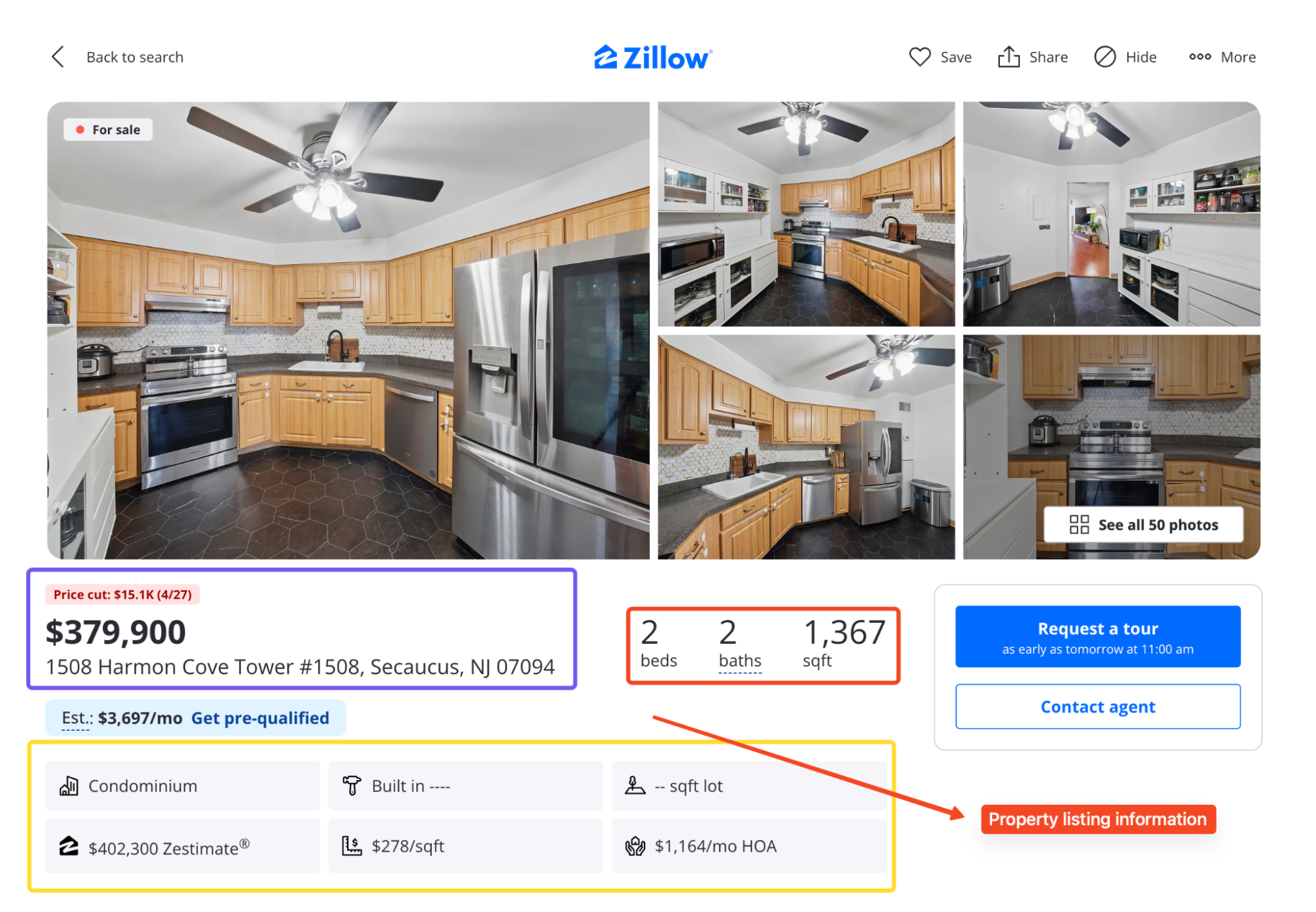
Zwischen beiden Seiten können Sie herausziehen:
- Preis, Adresse, Betten, Bäder, Quadratmeterzahl, Status und Tage auf dem Markt
- Schätzung und Miete Schätzung
- Fotos und Name des Maklers
- Preis- und Steuerhistorie
Warum Zillow-Daten scrapen?
Stellen Sie sich vor, Sie könnten auf aktuelle Immobilienangebote, Preisdetails und Marktanalysen zugreifen, ohne Hunderte von Zillow-Seiten manuell öffnen zu müssen.
Das ist der wahre Wert des Scrappings von Zillow.
Wenn Sie in den Bereichen Immobilien, Immobilieninvestitionen, Marktforschung, Lead-Generierung oder Preisanalyse arbeiten, verfügt Zillow über nützliche öffentliche Daten, mit denen Sie Trends schneller erkennen können.
Warum ist Zillow so schwer zu kratzen?
Zillow geht nicht so weit wie andere Plattformen, wenn es darum geht, Bots zu blockieren, aber es ist immer noch so aufgebaut, dass es Datenverkehr ausschließt, der nicht menschlich aussieht.
Die meisten Scraper scheitern aus zwei Gründen. Schauen wir uns beide an:
PerimeterX Schutz
Zillow verwendet PerimeterX, um Bot-Traffic in Echtzeit zu erkennen und zu blockieren. Wenn Ihr Scraper die falschen Header hat, von einer wenig vertrauenswürdigen IP-Adresse kommt oder zu viele Anfragen zu schnell sendet, kann er markiert werden.
Meistens führt diese Markierung zu einem CAPTCHA-Rätsel, das die meisten Scraper brechen würde. PerimeterX prüft auch viele Signale, darunter Header, Browserverhalten, TLS-Fingerabdrücke, Anfragegeschwindigkeit und IP-Reputation.
Wenn der Datenverkehr automatisiert ist, kann es sein, dass der Scraper nie die eigentlichen Angebotsdaten erreicht.
Selbst wenn Sie die Seite also in einem Headless-Browser rendern, ist das keine Erfolgsgarantie. Sie brauchen immer noch hochwertige Proxys, saubere Sitzungen und ein realistisches Anfrageverhalten.
Deshalb verwende ich lieber den Web Unlocker von Floppydata, um Zillow zu scrapen.
Unstrukturiertes HTML und keine stabilen Selektoren
Das Parsen von Zillow kann ebenso frustrierend sein wie das Überwinden der Abwehrmechanismen. Es gibt fast keine einheitlichen Klassennamen, IDs oder Datenattribute im Seitenquelltext.
Einfach aussehende Elemente wie der Preis oder die Adresse sind in allgemeine <div> Tags verpackt oder haben überhaupt keine Bezeichnungen.
Noch schlimmer ist, dass sich Klassennamen häufig ändern und keinem Muster folgen. Sie müssen also einen flexiblen Abgleich verwenden (z.B. ein schlüsselwortbasiertes find() oder sogar regex), um Daten aus rohen Textknoten zu ziehen.
Das macht Zillow zu einer der instabilsten Websites zum Scrapen, wenn Sie sich auf statische Selektoren verlassen.
Extrahieren von Listing-Informationen aus Zillow mit Python
Für diese Anleitung wähle ich die Boston-Suchergebnisseite von Zillow, die mehrere Immobilienangebote enthält. Von dort aus können wir Felder wie Preis, Adresse, Betten, Bäder, Quadratmeterzahl, Status und Angebotslinks extrahieren.
Anmerkung: Zillow-Seiten ändern sich häufig. Wenn die Boston-Seite anders aussieht, wenn Sie dies lesen, gehen Sie zu Zillow, suchen Sie nach einer beliebigen Stadt oder Nachbarschaft, kopieren Sie die URL der Ergebnisse und ersetzen Sie sie im Code.
Beginnen wir mit der Einrichtung:
Voraussetzungen
Bevor Sie beginnen, benötigen Sie drei Dinge:
- Python 3.10 oder höher auf Ihrem Rechner installiert
- Ein Floppydata-Konto mit einem API-Schlüssel für den Web Unlocker
- Zwei Python-Bibliotheken: requests für HTTP-Aufrufe und beautifulsoup4 für HTML-Parsing
Wenn Sie noch kein Floppydata-Konto haben, melden Sie sich unter floppydata.com an und holen Sie sich Ihren API-Schlüssel aus dem Web Unlocker Dashboard.
Neue Konten werden mit fünf kostenlosen Scraps ausgeliefert, so dass Sie die gesamte Anleitung verfolgen können, ohne etwas zu bezahlen.
Die Anforderungsbibliothek ist in der Regel vorinstalliert, aber Sie können auch einfach diesen Befehl ausführen, um sicherzustellen, dass sie richtig installiert ist:
pip install requests beautifulsoup4Sobald dies geschehen ist, erstellen Sie einen neuen Projektordner und eine neue Datei:
mkdir zillow-scraper
cd zillow-scraper
touch zillow_scraper.pyJetzt sind Sie bereit für den Einsatz.
Senden der ersten Anfrage
Das erste, was die meisten Leute versuchen, ist eine normale Python-Anfrage. Diese sieht normalerweise so aus:
import requests
url = "https://www.zillow.com/boston-ma/"
response = requests.get(url)
print(response.status_code)
print(response.text)Aber als ich das getestet habe, hat es nicht einmal zwei Versuche gebraucht, denn meine erste Anfrage wurde blockiert. Ich erhielt eine 403-Antwort mit einer PerimeterX-Sperrseite:
403
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<meta name="description" content="px-captcha">
<title>Access to this page has been denied</title>
</head>Das ist das Problem beim direkten Scrapen von Zillow. Eine normale Python-Anfrage verhält sich nicht wie eine echte Browsing-Sitzung. Sie hat auch nicht den richtigen Browser-Fingerabdruck, die richtige IP-Qualität oder das richtige JavaScript-Rendering, so dass Zillow sie sofort erkennen und die Anfrage blockieren kann.
Deshalb baue ich den Haupt-Scraper nicht um direkte requests() -Aufrufe bei Zillow herum. Stattdessen sende ich meine Anfragen über den Web Unlocker von Floppydata und überlasse ihm die schwierigen Aufgaben.
Scraping von Zillow mit Floppydata Web Unlocker
Lassen Sie uns mit dem Web Unlocker eine Anfrage an die Suchseite senden. Zillow ist nicht das schwierigste Ziel für Scraping, aber es legt Wert auf IP-Reputation und Browserverhalten.
An dieser Stelle kommt der Web Unlocker ins Spiel. Er leitet Ihre Anfrage über eine vertrauenswürdige private IP-Adresse weiter, wendet einen echten Browser-Fingerabdruck an und gibt das vollständig gerenderte HTML zurück.
Eine Sache, die ich an Floppydata sehr schätze, ist, dass Sie nur für erfolgreiche Anfragen bezahlen. Wenn ein Scrape fehlschlägt, wird er nicht auf Ihre Nutzung angerechnet.
Das Dashboard zeigt auch Echtzeit-Analysen der Anfragen an, so dass Sie Ihre Nutzung, Erfolgsquoten und verbleibenden Credits verfolgen können, ohne die Seite zu verlassen.
Bevor ich irgendeinen Code schreibe, teste ich die Ziel-URL gerne zuerst mit dem no-code Web Unlocker . So kann ich die HTML-Antwort sehen, bevor ich einen Parser erstelle. So weiß ich genau, welche Selektoren und Daten ich erwarten kann.
Die Verwendung des Web Unlocker Tools ist buchstäblich so einfach wie das ABC. Öffnen Sie einfach den Web Unlocker von Ihrem Floppydata Dashboard aus. Fügen Sie dann diese URL„https://www.zillow.com/boston-ma/“ ein, klicken Sie auf die Schaltfläche Scrape und warten Sie ein paar Sekunden
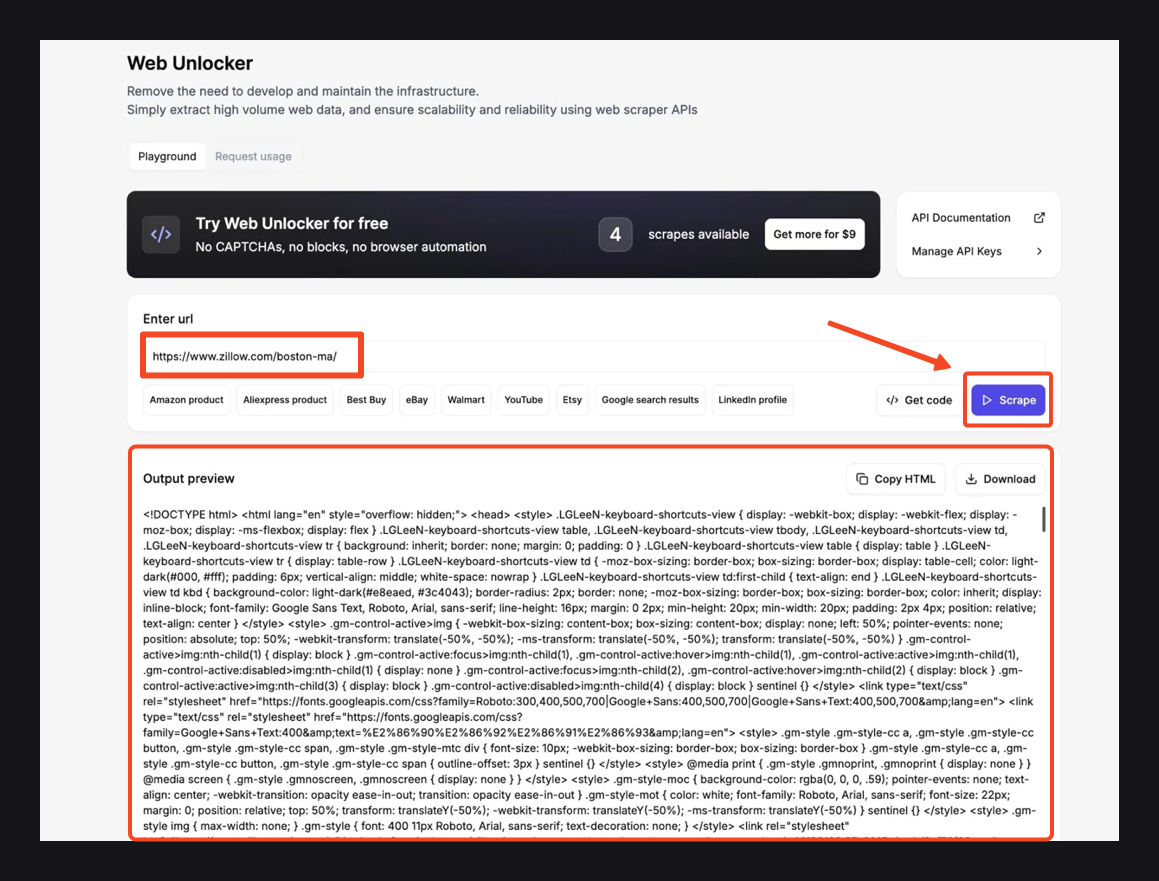
Sobald das Scrapen abgeschlossen ist, sehen Sie sich das Output-Vorschaufenster unten an. Sie sollten die vollständige HTML-Seite mit unseren Zillow-Suchergebnissen sehen.
Wenn die Daten gut aussehen, verwenden Sie Copy HTML, um sie zu übernehmen, oder Download, um die Datei lokal zu speichern.
Verstehen Sie die Paginierungsstruktur von Zillow
Die Ausgabevorschau liefert rohes HTML, was nützlich ist, da ich die genaue Struktur überprüfen kann, bevor ich den Code schreibe.
Dies ist vergleichbar mit dem Öffnen der Browser-Entwicklertools durch Drücken von F12 und dem direkten Inspizieren der Seite. In der heruntergeladenen HTML-Datei habe ich eine wichtige Sache gefunden, die den Parser wesentlich einfacher macht.
In den meisten Anleitungen wird Ihnen empfohlen, die Auflistungskarten mit CSS-Selektoren zu erfassen, aber Zillow stellt nur 9 Karten im Seitenaufbau dar. Die anderen 32 werden beim Scrollen geladen, so dass beim Scraping mit CSS-Selektoren die meisten Daten verloren gehen.
Vielmehr befinden sich die Suchergebnisse in einem großen JSON-Objekt in der HTML-Seite. Dieses JSON befindet sich in diesem Skript-Tag:
<script id="__NEXT_DATA__" type="application/json">Die Seite verwendet dieses JSON, um die Daten auf dem Frontend zu laden, und wir können es ebenfalls lesen. In diesem JSON befinden sich die Einträge genau unter diesem Pfad:
data["props"]["pageProps"]["searchPageState"]["cat1"]["searchResults"]["listResults"]Unser Parsing-Plan ist also einfach.
Wir finden das Skript __NEXT_DATA__ mit BeautifulSoup, parsen das JSON, gehen in das Array listResults und ziehen die Felder, die wir brauchen.
Zillow Web Scraping mit Python und Web Unlocker
Jetzt können wir vom Dashboard zum Code übergehen.
Das Dashboard-Snippet verwendet httpx, aber ich werde hier requests verwenden, weil es den meisten Python-Lesern vertrauter ist.
Schritt 1: Erstellen Sie die Anfrage
Lassen Sie uns mit der Grundkonfiguration beginnen. Wir benötigen den Web Unlocker Endpunkt, unseren API-Schlüssel und die Ziel-URL von Zillow:
import requests
import json
from bs4 import BeautifulSoup
API_URL = "https://client-api.floppy.host/v1/webUnlocker"
API_KEY = "YOUR_API_KEY"
SEARCH_URL = "https://www.zillow.com/boston-ma/"
SEARCH_URL = "live_zillow_boston.json"Ersetzen Sie IHR_API_KEY durch den Schlüssel aus Ihrem Floppydata Dashboard.
Ich verwende hier Boston als Zielmarkt, aber wenn Sie eine andere Stadt scrapen möchten, ersetzen Sie einfach die Such-URL.
Schritt 2: Holen Sie die Seite über Web Unlocker
Der Web Unlocker nimmt einen JSON-Payload mit der Ziel-URL und ein paar Optionen entgegen. Er gibt eine JSON-Antwort zurück, die das gerenderte HTML in einem HTML-Feld enthält:
Jetzt erstelle ich eine Funktion fetch_html(), um die Zillow-URL an Web Unlocker zu senden und das gerenderte HTML zurückzugeben
def fetch_html(url):
response = requests.post(
API_URL,
headers={
"Content-Type": "application/json",
"X-Api-Key": API_KEY,
},
json={
"url": url,
"country": "US",
"city": "Boston",
"difficulty": "medium",
"expiration": 0,
},
timeout=120,
)
response.raise_for_status()
data = response.json()
html = data.get("html")
if not html:
raise ValueError("Unlocker response did not include an 'html' field.")
return htmlHier geschehen einige Dinge. Die Felder Land und Stadt helfen, die Anfrage besser auf den Zielort abzustimmen. Ich habe die Schwierigkeit: „mittel“, weil Zillow keine einfache statische Seite ist und daher einen stärkeren Entsperrungsprozess benötigt.
Das Feld expiration ist auf 0 gesetzt, so dass ich eine neue Antwort erhalte. Nachdem die Anfrage erfolgreich war, gibt Web Unlocker eine JSON-Antwort zurück, und der gerenderte HTML-Code befindet sich im html-Feld.
Schritt 3: Extrahieren Sie die Inserate
Jetzt können wir den Parsing-Plan von vorhin anwenden. Ich werde eine Funktion extract_listings() erstellen. Diese Funktion nimmt den HTML-Code, findet die JSON-Daten von Zillow und extrahiert die Angebote:
def extract_listings(html):
soup = BeautifulSoup(html, "html.parser")
next_data = soup.find("script", id="__NEXT_DATA__")
if not next_data or not next_data.string:
raise ValueError("Could not find Zillow's __NEXT_DATA__ script.")
data = json.loads(next_data.string)
search_state = data.get("props", {}).get("pageProps", {}).get("searchPageState", {})
list_results = (
search_state.get("cat1", {})
.get("searchResults", {})
.get("listResults", [])
)
listings = []
for item in list_results:
listings.append(
{
"zpid": item.get("zpid"),
"address": item.get("address"),
"price": item.get("price"),
"beds": item.get("beds"),
"baths": item.get("baths"),
"sqft": item.get("area"),
"status": item.get("statusType"),
"url": item.get("detailUrl"),
}
)
return listingsMit BeautifulSoup kann ich ganz einfach direkt auf das strukturierte JSON innerhalb der Seite zugreifen. Dann habe ich den Skriptinhalt als JSON geparst und das Array listResults erhalten.
Jedes Element in listResults ist eine Auflistung einer Immobilie, und aus jeder Auflistung können wir wertvolle Daten sammeln, wie z.B.:
- Adresse
- Preis
- Betten
- Bäder
- Bereich
- statusType
- detailUrl
In der endgültigen Ausgabe habe ich die Fläche in sqft umbenannt, weil das einfacher zu verstehen ist.
Schritt 4: Speichern Sie die Ergebnisse in einer JSON-Datei
Schließlich können wir eine main() -Funktion hinzufügen, um den Scraper auszuführen und die Ausgabe in einer JSON-Datei zu speichern:
def main():
print(f"Fetching data from: {SEARCH_URL}")
html = fetch_html(SEARCH_URL)
listings = extract_listings(html)
if not listings:
raise SystemExit("No listings found in Zillow's JSON data.")
with open(OUTPUT_FILE, "w", encoding="utf-8") as file:
json.dump(listings, file, indent=2)
print(f"Found {len(listings)} listings")
print(f"Saved results to {OUTPUT_FILE}")Diese Funktion ruft die Seite ab, extrahiert die Listen, prüft, ob die Liste nicht leer ist, und speichert alles in einer JSON-Datei. Wenn die Daten gut aussehen, können wir sie später in eine CSV-Datei konvertieren oder die Daten direkt in unseren Anwendungen verwenden.
Das vollständige Skript
Hier ist der gesamte Code, den ich verwendet habe, um meine Zillow-Listings erfolgreich zu extrahieren:
from bs4 import BeautifulSoup
import requests
import json
API_URL = "https://client-api.floppy.host/v1/webUnlocker"
API_KEY = "Your_API_KEY"
SEARCH_URL = "https://www.zillow.com/boston-ma/"
OUTPUT_FILE = "live_zillow_boston.json"
def fetch_html(url):
response = requests.post(
API_URL,
headers={
"Content-Type": "application/json",
"X-Api-Key": API_KEY,
},
json={
"url": url,
"country": "US",
"city": "Boston",
"difficulty": "medium",
"expiration": 0,
},
timeout=120,
)
response.raise_for_status()
data = response.json()
html = data.get("html")
if not html:
raise ValueError("Unlocker response did not include an 'html' field.")
return html
def extract_listings(html):
soup = BeautifulSoup(html, "html.parser")
next_data = soup.find("script", id="__NEXT_DATA__")
if not next_data or not next_data.string:
raise ValueError("Could not find Zillow's __NEXT_DATA__ script.")
data = json.loads(next_data.string)
search_state = data.get("props", {}).get("pageProps", {}).get("searchPageState", {})
list_results = (
search_state.get("cat1", {})
.get("searchResults", {})
.get("listResults", [])
)
listings = []
for item in list_results:
listings.append(
{
"zpid": item.get("zpid"),
"address": item.get("address"),
"price": item.get("price"),
"beds": item.get("beds"),
"baths": item.get("baths"),
"sqft": item.get("area"),
"status": item.get("statusType"),
"url": item.get("detailUrl"),
}
)
return listings
def main():
print(f"Fetching data from: {SEARCH_URL}")
html = fetch_html(SEARCH_URL)
listings = extract_listings(html)
if not listings:
raise SystemExit("No listings found in Zillow's JSON data.")
with open(OUTPUT_FILE, "w", encoding="utf-8") as file:
json.dump(listings, file, indent=2)
print(f"Found {len(listings)} listings")
print(f"Saved results to {OUTPUT_FILE}")
if __name__ == "__main__":
main()Wenn alles richtig eingestellt ist, sollten Sie eine Ausgabe wie diese sehen:
[
{
"zpid": "59174136",
"address": "45 Garden St APT 3, Boston, MA 02114",
"price": "$685,000",
"beds": 2,
"baths": 1,
"sqft": 525,
"status": "FOR_SALE",
"url": "https://www.zillow.com/homedetails/45-Garden-St-APT-3-Boston-MA-02114/59174136_zpid/"
}
]Jetzt funktioniert Ihr Scraper, d.h. Sie sind jetzt in der Lage, die wichtigsten Informationen aus jedem Zillow-Eintrag abzurufen.
Fehlersuche bei allgemeinen Problemen
Wenn Sie häufig Zillow-Immobiliendaten durchsuchen, werden Sie zwangsläufig an einigen Stellen auf Mauern stoßen. Ich habe selbst schon ein paar davon erlebt. Daher kann ich Ihnen sagen, was Sie erwarten können, einschließlich:
- 403 Fehler: Das bedeutet, dass Zillow Ihren Bot blockiert hat. Versuchen Sie, Ihre Kopfzeilen zu ändern oder einen Proxy zu verwenden, um weiterhin Zillow-Daten zu sammeln.
- Leere Antworten: Das könnte am JavaScript-Rendering liegen. Versuchen Sie, ein Tool zu verwenden, das die Seite vollständig rendert, bevor es den HTML-Code zurückgibt, z.B. den Web Unlocker.
- Fehlende Daten: Nicht alle Inserate haben die gleichen Informationen. Verwenden Sie immer .get(), wenn Sie Zillow-Daten abrufen, damit Ihr Scraper bei einem fehlenden Schlüssel nicht abstürzt.
Da Zillow keine kostenlose API anbietet, müssen Sie einen Weg finden, diese zu umgehen. Wenn Sie einen zuverlässigen Weg brauchen, um auf Zillows Angebotsdaten zuzugreifen, ist der Web Unlocker von Floppydata die beste Wahl.
Fazit
Zillow sieht nicht wie eine Hochsicherheitsseite aus, ist aber durch PerimeterX und ein mehrstufiges Erkennungssystem geschützt, das Ihre IP, Header, TLS-Fingerabdrücke und Verhaltenssignale überwacht. Wenn Sie sich verdächtig verhalten, werden Sie markiert und auf unbestimmte Zeit gesperrt.
Daher müssen Sie beim Scrapen vorsichtig sein. An dieser Stelle kommt Floppydata Web Unlocker ins Spiel. Es:
- Rotiert Premium-Wohnsitzvollmachten
- Rotiert Kopfzeilen und echtes Browser-Fingerprinting
- Lädt jedes Mal sauber und vollständig in HTML
- Nur Rechnungen für erfolgreiche Antworten
Mit dieser Einrichtung müssen Sie nicht selbst gegen das Anti-Bot-System von Zillow ankämpfen; lassen Sie sich vom Floppy Data Web Unlocker helfen. Fangen Sie jetzt an, Zillow zu scrapen – mit 5 kostenlosen Scrapes.





