

Einführung
PHP war damals eine meiner ersten Sprachen als Webentwickler, und ich verwende es immer noch gerne für Scraping.
Dieses Tutorial behandelt das, was ich tatsächlich in der Produktion verwende. Ich führe Sie durch einen kompletten PHP-Web-Scraping-Workflow mit Floppydata Web Unlocker als Scraping-Ebene.
Warum Floppydata?
Weil es eine Scraping-API bietet, die die Verwaltung von Proxys, Headern oder Anti-Bot-Logik überflüssig macht. Am Ende dieses Artikels werden Sie wissen, wie Sie Web Scraping mit PHP durchführen können.
Was ist PHP Web Scraping?
PHP Web Scraping ist der Prozess, bei dem Sie mit PHP-Code Daten aus Websites extrahieren. Nicht jede Website stellt Ihnen eine API zur Verfügung, wie z.B. Twitter, so dass in vielen Fällen die einzige Möglichkeit, die benötigten Informationen zu erhalten, darin besteht, die Seite abzurufen und den HTML-Code selbst zu parsen.
PHP ist für diesen Zweck sehr sinnvoll, wenn Sie es bereits täglich verwenden. Sie können die gescrapten Daten direkt in ein bestehendes Backend einfügen, sie in MySQL speichern oder den Scraper über einen Cron-Job laufen lassen, ohne eine weitere Sprache in den Stack einzuführen.
Das Hauptproblem ist nicht, ob PHP scrapen kann. Das kann es auf jeden Fall. Die eigentliche Frage ist, wie gut Ihr Scraper mit blockierten Anfragen, standortbezogenen Einschränkungen und aggressiven CAPTCHAs umgehen kann.
Das ist genau der Grund, warum ich PHP mit Floppydata Web Unlocker kombiniere, um die Lücke zu schließen.
Wissenswerte PHP Web Scraping Bibliotheken (2026)
PHP verfügt über eine Vielzahl von Scraping-Bibliotheken, aber ehrlich gesagt habe ich mich auf einige wenige beschränkt, die ich tatsächlich benutze. Hier ist ein kurzer Blick auf sie.
- Guzzle: Ein solider HTTP-Client, der POST-Anfragen, JSON-Payloads, Weiterleitungen und Header sauber verarbeitet. Wir werden ihn in diesem Tutorial verwenden, um mit der Web Unlocker API zu kommunizieren.
- Symfony DomCrawler: Damit können Sie mit CSS-Selektoren oder XPath durch HTML und XML navigieren. In Kombination mit der Komponente symfony/css-selector erhalten Sie eine jQuery-ähnliche Filterung, die zuverlässig mit unordentlichem HTML funktioniert. Die Komponente ist eigenständig, so dass Sie den Rest von Symfony nicht benötigen.
- Symfony HttpBrowser: Dies ist der moderne Ersatz für die inzwischen veraltete Goutte-Bibliothek. Sie baut auf BrowserKit und DomCrawler auf und ermöglicht es Ihnen, Klicks, Formulareingaben und Weiterleitungsketten zu simulieren. Ideal, wenn sich Ihre Scraping-Logik über mehrere Seiten erstreckt.
- DiDOM: DiDOM ist ein schneller, abhängigkeitsfreier Parser mit einer jQuery-ähnlichen API. Perfekt für kleinere Skripte, bei denen Sie die Einbindung von Symfony-Komponenten vermeiden möchten.
- Symfony Panther: Steuert einen echten Chrome- oder Chromium-Browser über WebDriver. Sie greifen zu diesem Tool, wenn eine Website alles in JavaScript rendert (React, Vue, umfangreiche SPAs) und eine einfache HTTP-Anfrage eine leere Shell zurückgibt. Er ist schwerer, daher verwende ich ihn nur, wenn nichts anderes funktioniert.
Goutte war früher eine gängige Empfehlung, ist aber inzwischen veraltet, so dass ich nicht empfehlen würde, ein neues Projekt darauf aufzubauen.
Für diese Anleitung ist Guzzle plus Symfony DomCrawler ausreichend. Da der Web Unlocker bereits JavaScript ausführt und das endgültige gerenderte HTML zurückgibt, brauchen wir keinen Headless-Browser auf unserer Seite laufen zu lassen.
Voraussetzungen
Bevor Sie irgendeinen Code schreiben, sollten Sie sicherstellen, dass Sie die folgenden vier Dinge beachtet haben. Wenn Sie noch nie ein PHP-Projekt von Grund auf eingerichtet haben, keine Sorge, ich werde Sie durch jeden Schritt begleiten.
1. PHP 8.2 oder neuere Version
Auf vielen Mac- und Linux-Systemen ist PHP bereits vorinstalliert, aber es schadet nie, dies zu überprüfen. Öffnen Sie Ihr Terminal und überprüfen Sie Ihre PHP-Version:
php -vWenn PHP bereits installiert ist, sollten Sie eine Versionsnummer sehen. Verwenden Sie für dieses Tutorial PHP 8.2 oder eine neuere Version. Das ist die sicherste Ausgangsbasis für die Versionen der Abhängigkeiten, die wir installieren werden.
Wenn PHP fehlt, folgen Sie den Anweisungen, um es zu installieren:
# Windows (Chocolatey, run PowerShell as Administrator)
choco install php
# macOS (Homebrew)
brew install phpFühren Sie nach der Installation erneut php -v aus, um die Version zu bestätigen. Auf Homebrew benötigen Sie für dieses Tutorial keine separaten php-curl oder php-xml Pakete. Diese Erweiterungen sind bereits in der Hauptinstallation von PHP enthalten.
2. Komponist
Composer ist der Standard-Paketmanager für PHP. Er ist im Grunde das Äquivalent zu npm oder pip für PHP-Projekte. Wir werden ihn verwenden, um Guzzle und die Symfony-Parser-Pakete zu installieren.
Prüfen Sie zunächst, ob es bereits verfügbar ist:
composer --versionWenn Composer noch nicht installiert ist, verwenden Sie:
# Windows (Chocolatey, as Administrator)
choco install composer
# macOS (Homebrew)
brew install composerSobald dies geschehen ist, sollte composer --version eine Versionsnummer ausgeben, und Sie können das Projekt erstellen.
3. Ein Floppydata-Konto
Erstellen Sie ein Floppydata-Konto und kopieren Sie Ihren API-Schlüssel aus dem Dashboard. Jedes neue Konto erhält 5 kostenlose Scrapes für den Web Unlocker.
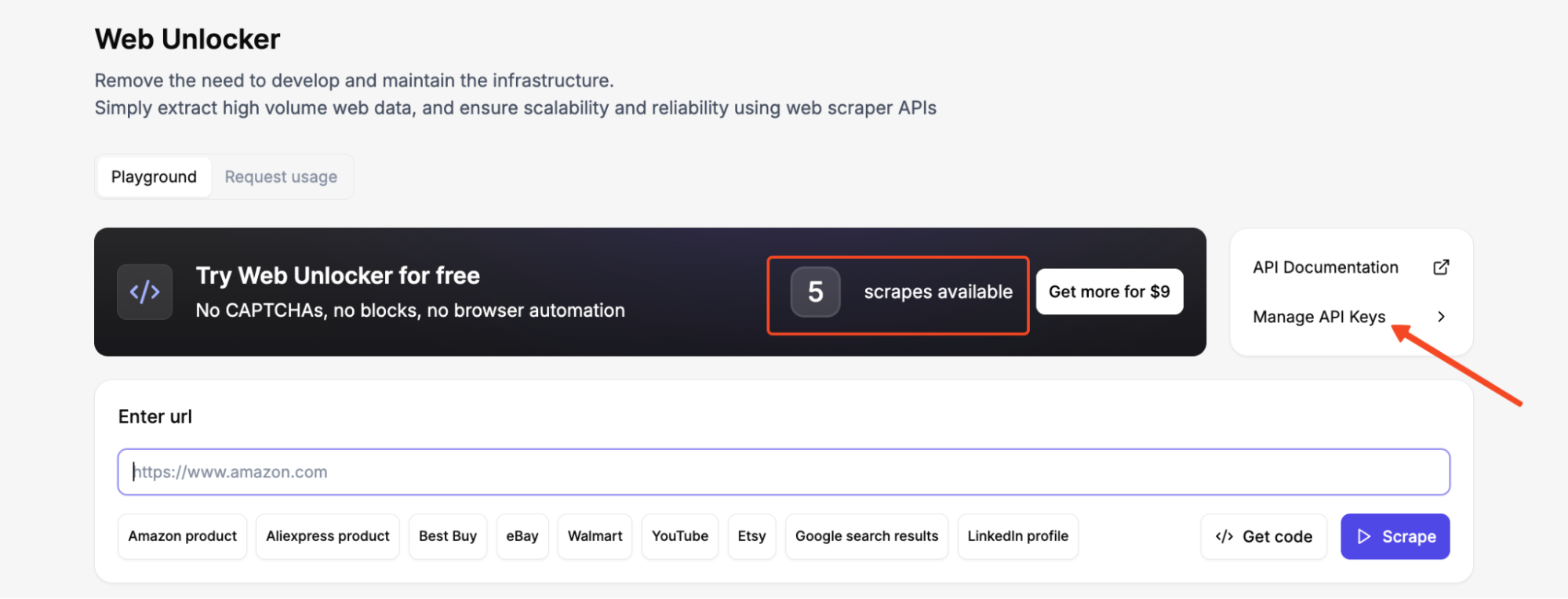
Nachdem Sie sich in Ihrem Dashboard angemeldet haben, gehen Sie im Web Unlocker zu API-Schlüssel verwalten und generieren Sie einen API-Schlüssel. Kopieren Sie ihn sofort und bewahren Sie ihn an einem sicheren Ort auf.
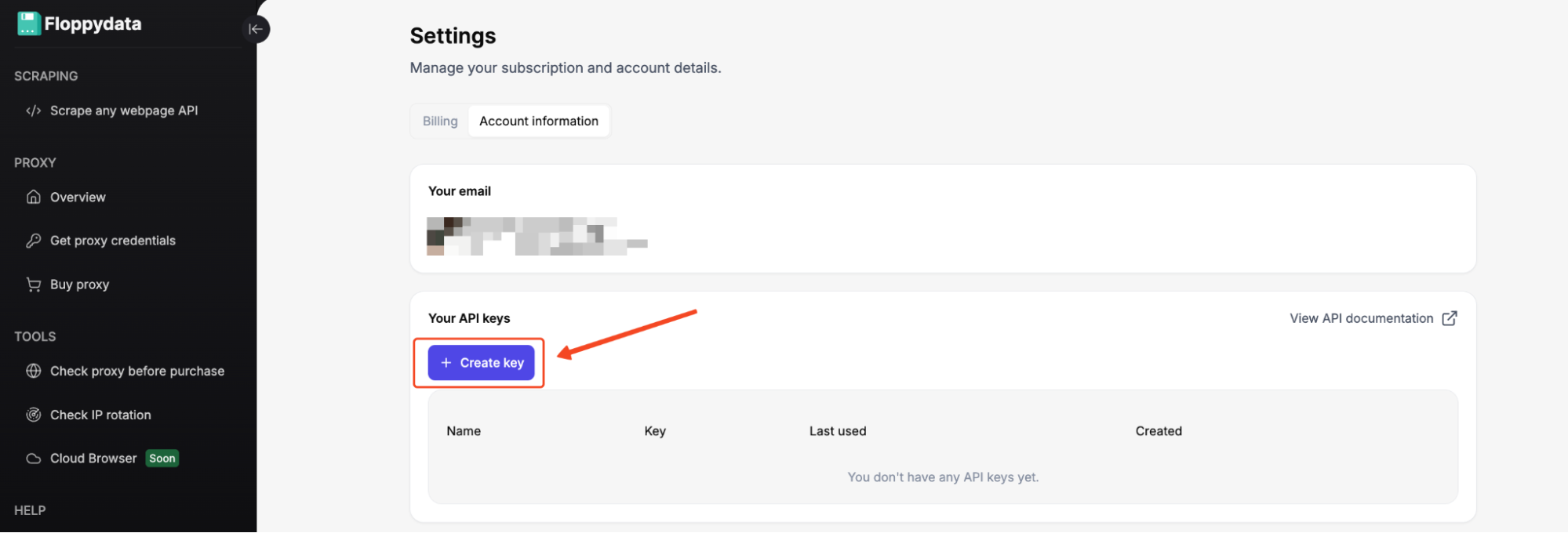
Sie werden diesen Schlüssel im X-Api-Key-Header jeder Web Unlocker-Anfrage verwenden. Wir werden ihn in ein paar Minuten in unseren Code einfügen.
4. Projektverzeichnis und Abhängigkeiten
Lassen Sie uns nun den Ordner erstellen, in dem sich unser Scraper befinden wird, und die PHP-Bibliotheken installieren, die wir benötigen. In Ihrem Terminal:
mkdir php-scrape-countries
cd php-scrape-countriesInitialisieren Sie ein neues Composer-Projekt:
composer init --name="myname/country-scraper" --require="php:^8.2" --no-interactionInstallieren Sie nun die Pakete, die wir benötigen:
composer require guzzlehttp/guzzle symfony/dom-crawler:^7.4 symfony/css-selector:^7.4Composer lädt alle drei Bibliotheken und ihre Abhängigkeiten in einen vendor/-Ordner herunter und erstellt eine composer.json-Datei, die genau festhält, welche Versionen Sie verwenden.
Von nun an kann jede PHP-Datei im Projekt die Abhängigkeiten mit laden:
require_once __DIR__ . '/vendor/autoload.php';Damit ist die Einrichtung abgeschlossen und wir können mit dem Scraper selbst weitermachen.
Wie man mit PHP und Floppydata Web Unlocker Daten ausliest
Schritt #1: Testen Sie Ihr Ziel
Ich schreibe Code nie gerne blind, damit ich genau weiß, welche Selektoren und Datenstrukturen mich erwarten. Für dieses Beispiel verwende ich scrapethissite, eine Demo-Website für das Scraping von Daten. Sie enthält eine Liste aller 250 Länder mit ihrer Hauptstadt, Bevölkerung und Fläche.
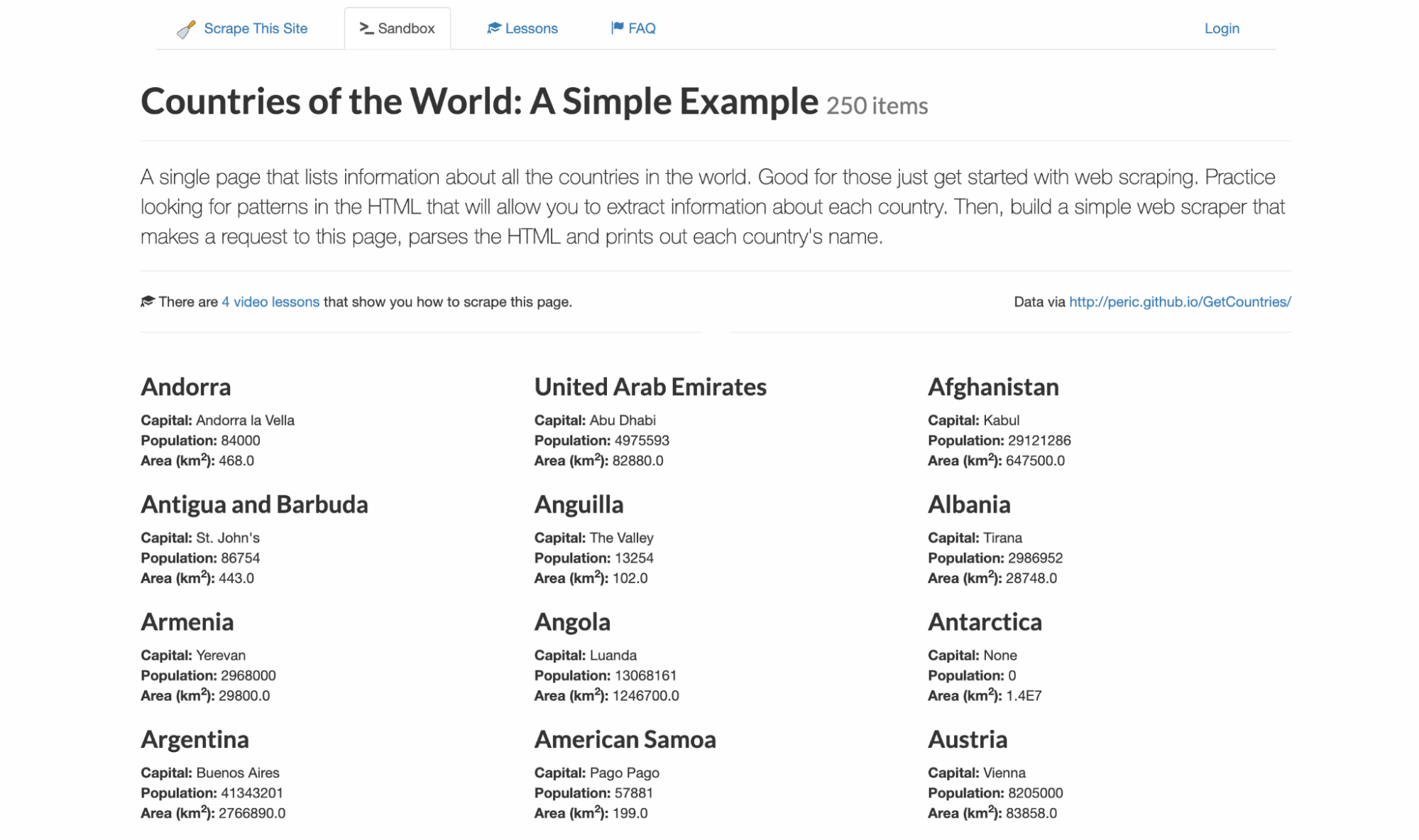
Besuchen Sie den Floppydata Web Unlocker Playground, um mitzumachen. Dieses No-Code-Tool ist direkt von Ihrem Dashboard aus verfügbar und ermöglicht es Ihnen, den genauen HTML-Code zu sehen, den die API zurückgibt, ohne ein Projekt zu erstellen.
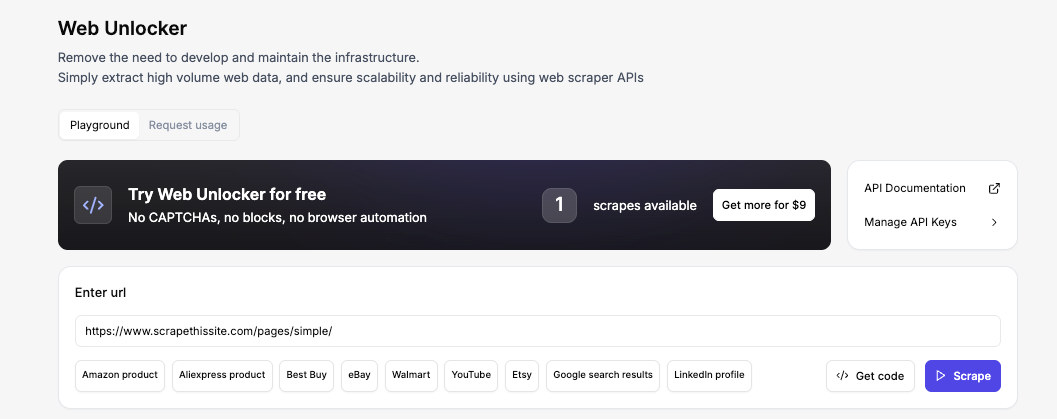
Geben Sie nun die URL ein und klicken Sie auf Scrape. Innerhalb von Sekunden sehen Sie den vollständigen HTML-Code in der Ausgabevorschau. Das ist genau derselbe HTML-Code, den Ihr PHP-Skript in ein paar Schritten erhalten wird.
Wenn die Daten richtig aussehen, können Sie den HTML-Code kopieren oder die Antwort herunterladen. Aber in unserem Fall lassen wir das PHP-Skript dies automatisch tun.
Schritt #2: Senden Sie Ihre erste Web Unlocker Anfrage mit Guzzle
Der Kern des gesamten Arbeitsablaufs ist eine POST-Anfrage an den Endpunkt von Floppydata:
https://client-api.floppy.host/v1/webUnlockerZu diesem Zweck erstellen wir zunächst einen Guzzle-Client und bereiten die Anfragekonfiguration vor. Dann senden wir die Anfrage und bearbeiten die Antwort.
Erstellen Sie eine Datei namens scrape.php und beginnen Sie mit dem Grundgerüst:
<?php
// scrape.php
require_once __DIR__ . '/vendor/autoload.php';
use GuzzleHttp\Client;
$apiKey = 'YOUR_API_KEY'; // Replace with your real key
$targetUrl = 'https://www.scrapethissite.com/pages/simple/';
$client = new Client([
'base_uri' => 'https://client-api.floppy.host',
'timeout' => 60,
]);Ersetzen Sie YOUR_API_KEY durch Ihren echten Schlüssel. Jetzt erstellen wir den eigentlichen POST-Aufruf. Wir senden JSON an den API-Endpunkt, fügen den API-Schlüssel in die Kopfzeilen ein und übergeben die Ziel-URL sowie ein paar Argumente im Textkörper:
$response = $client->post('/v1/webUnlocker', [
'headers' => [
'Content-Type' => 'application/json',
'X-Api-Key' => $apiKey,
],
'json' => [
'url' => $targetUrl,
'country' => 'US',
'city' => 'New York',
'difficulty' => 'low',
'expiration' => 0,
],
]);
$payload = json_decode((string) $response->getBody(), true);
$html = $payload['html'] ?? '';
echo "HTML received! Length: " . strlen($html) . " characters\n";Die Felder Land und Stadt teilen dem Web Unlocker mit, über welchen geografischen Standort die Anfrage geleitet werden soll. Das Feld Schwierigkeit steuert, wie aggressiv der Unlocker mit Anti-Bot-Schutzmaßnahmen umgeht. Ich verwende hier den Wert niedrig, weil unser Sandbox-Ziel keinen Schutz hat.
Für geschützte Ziele hinter Cloudflare oder DataDome setzen Sie diesen Wert auf mittel, damit der Unlocker stärkere Fingerabdrücke und CAPTCHA-Lösungslogik anwendet.
Beachten Sie, dass der Web Unlocker das rohe HTML in einem JSON-Objekt zurückgibt. Das bedeutet, dass Sie das JSON dekodieren und das eigentliche Seitenmarkup aus dem HTML-Feld ziehen müssen.
Wenn Sie dies vergessen und den gesamten Antwortkörper als HTML behandeln, wird Ihr Parser nicht funktionieren. Damit ist die Anfrageseite fertig und wir können mit dem Parsen fortfahren.
Schritt #3: Überprüfen Sie die Seitenstruktur
Nachdem die Anfrage erfolgreich war, besteht die nächste Aufgabe darin, die Seitenstruktur zu untersuchen und die wiederholten Elemente zu finden, die die gewünschten Daten enthalten. Jedes Land auf der Seite folgt genau diesem HTML-Muster:
<div class="col-md-4 country">
<h3 class="country-name">
<i class="flag-icon flag-icon-ad"></i>
Andorra
</h3>
<div class="country-info">
<strong>Capital:</strong> <span class="country-capital">Andorra la Vella</span><br>
<strong>Population:</strong> <span class="country-population">84000</span><br>
<strong>Area (km<sup>2</sup>):</strong> <span class="country-area">468.0</span><br>
</div>
</div>Diese wiederholte Struktur macht diese Seite so schön vorhersehbar. Jede Länderkarte verwendet die gleichen Klassennamen: .country für den Wrapper, .country-name für die Überschrift und.country-capital, .country-population und .country-area für die Datenfelder innerhalb von .country-info.
Schritt #4: Parsen von Daten mit Symfony DomCrawler
Da die Klassen in allen 250 Einträgen konsistent sind, können wir jedes .country-Element in einer Schleife durchlaufen und die Werte aus den untergeordneten Selektoren ziehen. Aber zuerst fügen wir eine kleine Hilfsfunktion hinzu, die uns hilft, den extrahierten Text zu bereinigen:
use Symfony\Component\DomCrawler\Crawler;
function normalizeText(string $text): string
{
return preg_replace('/\s+/', ' ', trim($text)) ?? trim($text);
}Wenn Sie sich das rohe HTML ansehen, haben die Ländernamen zusätzliche Leerzeichen und Zeilenumbrüche um sie herum, weil die <i> Flaggensymbol-Tags innerhalb der <h3> sitzen.
Die Funktion normalizeText() entfernt führende und nachgestellte Leerzeichen und verwendet dann eine Regex, um alle verbleibenden Leerzeichen oder Zeilenumbrüche zu kürzen, so dass Namen wie Andorra oder St. John’s sauber wiedergegeben werden, anstatt Leerzeichen aus dem HTML zu übernehmen.
Nachdem der Helper fertig ist, erstellen wir eine Crawler-Instanz und ziehen eine Schleife über jede Länderkarte:
$crawler = new Crawler($html);
$countries = [];
$crawler->filter('.country')->each(function (Crawler $node) use (&$countries): void {
$countries[] = [
'name' => normalizeText($node->filter('.country-name')->text()),
'capital' => normalizeText($node->filter('.country-capital')->text()),
'population' => normalizeText($node->filter('.country-population')->text()),
'area' => normalizeText($node->filter('.country-area')->text()),
];
});
echo 'Parsed ' . count($countries) . " countries\n";DomCrawler gibt uns eine saubere Möglichkeit, uns mit CSS-Selektoren durch den HTML-Code zu bewegen. Wir beginnen damit, den HTML-Code in ein Crawler-Objekt zu verpacken und filtern dann jeden .country-Block auf der Seite heraus. Innerhalb jedes Blocks erfassen wir den Namen, die Hauptstadt, die Bevölkerung und das Gebiet.
Wenn Sie das Skript jetzt ausführen, sollten Sie auf dem Terminal die Meldung „Parsed 250 countries“ sehen.
Schritt #5: Exportieren Sie die Ergebnisse in CSV und JSON
Sobald der Parser Ihnen ein Array $countries liefert, wird der Export der Daten sehr einfach.
$csvHandle = fopen('countries.csv', 'w');
fputcsv($csvHandle, ['Country', 'Capital', 'Population', 'Area (km2)'], ',', '"', '');
foreach ($countries as $country) {
fputcsv($csvHandle, [
$country['name'],
$country['capital'],
$country['population'],
$country['area'],
], ',', '"', '');
}
fclose($csvHandle);
file_put_contents('countries.json', json_encode($countries, JSON_PRETTY_PRINT | JSON_UNESCAPED_SLASHES));Der CSV-Export ist nützlich, da er dem Leser eine Datei liefert, die er sofort in Excel, Google Sheets oder einem anderen Tabellenkalkulationsprogramm öffnen kann. Der JSON-Export ist ebenso praktisch, wenn Sie die gescrapten Daten später in ein anderes PHP-Skript oder eine API einspeisen möchten.
Eine kleine Aktualisierung ist das explizite Escape-Argument in fputcsv(). Bei neueren PHP-Versionen werden dadurch Warnungen vor der Veralterung vermieden und das Beispiel bleibt sauber, wenn die Leser es vom Terminal aus ausführen.
Schritt #6: Stellen Sie alles in einem Skript zusammen
Da nun jeder Teil für sich funktioniert, finden Sie hier das vollständige Skript:
<?php
declare(strict_types=1);
require_once __DIR__ . '/vendor/autoload.php';
use GuzzleHttp\Client;
use Symfony\Component\DomCrawler\Crawler;
function normalizeText(string $text): string
{
return preg_replace('/\s+/', ' ', trim($text)) ?? trim($text);
}
$apiKey = 'YOUR_API_KEY';
$targetUrl = 'https://www.scrapethissite.com/pages/simple/';
if ($apiKey === 'YOUR_API_KEY') {
fwrite(STDERR, "Replace YOUR_API_KEY before running the script.\n");
exit(1);
}
$client = new Client([
'base_uri' => 'https://client-api.floppy.host',
'timeout' => 60,
]);
try {
$response = $client->post('/v1/webUnlocker', [
'headers' => [
'Content-Type' => 'application/json',
'X-Api-Key' => $apiKey,
],
'json' => [
'url' => $targetUrl,
'country' => 'US',
'city' => 'New York',
'difficulty' => 'low',
'expiration' => 0,
],
]);
} catch (Throwable $e) {
fwrite(STDERR, "Request failed: {$e->getMessage()}\n");
exit(1);
}
$payload = json_decode((string) $response->getBody(), true);
if (!is_array($payload) || !isset($payload['html']) || !is_string($payload['html'])) {
fwrite(STDERR, "Unexpected API response. Expected JSON with an html field.\n");
exit(1);
}
$crawler = new Crawler($payload['html']);
$countries = [];
$crawler->filter('.country')->each(function (Crawler $node) use (&$countries): void {
$countries[] = [
'name' => normalizeText($node->filter('.country-name')->text()),
'capital' => normalizeText($node->filter('.country-capital')->text()),
'population' => normalizeText($node->filter('.country-population')->text()),
'area' => normalizeText($node->filter('.country-area')->text()),
];
});
if ($countries === []) {
fwrite(STDERR, "No countries were parsed.\n");
exit(1);
}
$csvHandle = fopen(__DIR__ . '/countries.csv', 'w');
if ($csvHandle === false) {
fwrite(STDERR, "Could not create countries.csv.\n");
exit(1);
}
fputcsv($csvHandle, ['Country', 'Capital', 'Population', 'Area (km2)'], ',', '"', '');
foreach ($countries as $country) {
fputcsv($csvHandle, [
$country['name'],
$country['capital'],
$country['population'],
$country['area'],
], ',', '"', '');
}
fclose($csvHandle);
file_put_contents(__DIR__ . '/countries.json', json_encode($countries, JSON_PRETTY_PRINT | JSON_UNESCAPED_SLASHES));
echo 'Done! Parsed ' . count($countries) . " countries.\n";
echo "Saved countries.csv and countries.json\n";Ersetzen Sie ‚IHR_API_KEY‘ und führen Sie es wie folgt aus:
php scrape.phpWenn alles korrekt eingerichtet ist, ruft das Skript die Seite über Web Unlocker ab, analysiert alle 250 Länder und schreibt sowohl countries.csv als auch countries.json in Ihren Projektordner.
Anzeigen der Ergebnisse
Nachdem das Skript beendet ist, können Sie die Datei countries.csv sofort öffnen. Die ersten Zeilen werden wie folgt aussehen:
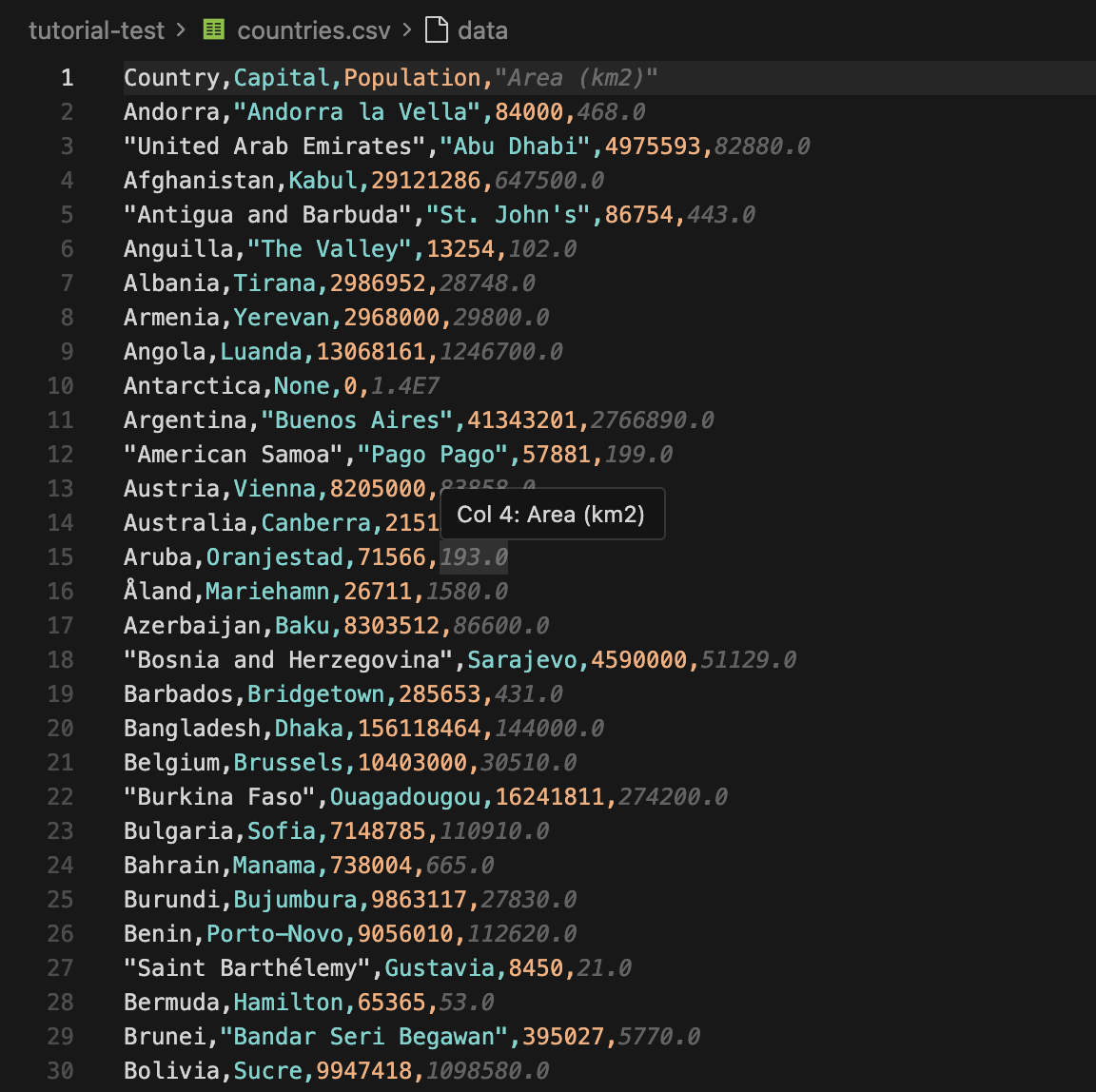
Sie können nun die CSV-Datei in eine Tabellenkalkulation importieren oder die JSON-Datei an eine andere Anwendung senden. Wenn Sie diesen Workflow für die Preisverfolgung nutzen möchten, können Sie ihn mit den Preisüberwachungs-Proxys von Floppydata kombinieren.
Umgang mit Anti-Scraping-Maßnahmen
Eine einfache, statische Seite ist nicht schwer zu analysieren, wie wir gerade gesehen haben. Aber geschützte Seiten können Kopfschmerzen bereiten.
Sie könnten auf Blöcke, fehlende Daten, CAPTCHAs, JavaScript-Rendering oder Ratenbeschränkungen stoßen. Das ist der Punkt, an dem ein normaler PHP-Scraper zu kämpfen hat.
Hier sind die häufigsten Probleme, mit denen Sie konfrontiert werden können:
- IP-Blockierung: Websites können Ihre IP-Adresse blockieren, wenn sie mehrere Anfragen von derselben IP-Adresse innerhalb eines kurzen Zeitraums feststellen.
- CAPTCHAs: CAPTCHA-Systeme werden verwendet, um zwischen Bots und Menschen zu unterscheiden, indem sie Aufgaben stellen, die für Bots schwer zu lösen sind.
- Ratenbegrenzung: Websites begrenzen oft die Anzahl der Anfragen, die Sie innerhalb eines bestimmten Zeitraums tätigen können, um übermäßiges Scraping zu verhindern.
- Erkennung von Benutzer-Agenten: Nicht-Browser-Benutzeragenten werden blockiert, weil sie nicht wie echte Besucher aussehen.
- JavaScript-Herausforderungen: Der Inhalt wird erst nach der Ausführung von JavaScript geladen, was bei einer einfachen HTTP-Anfrage möglicherweise nicht der Fall ist.
Sie können versuchen, diese Probleme manuell zu lösen, aber das ist weder bequem noch skalierbar.
Hier kommt der Floppydata Web Unlocker ins Spiel. Anstatt jede Herausforderung selbst zu lösen, können Sie die gesamte Anti-Bot-Schicht auslagern und sich auf das Extrahieren und Speichern der Daten konzentrieren.
Floppydata Web Unlocker behandelt:
- IP-Rotation mit einem großen Pool von Proxys für Privatanwender und Rechenzentren
- Browser-Fingerprinting und Headless-Browser
- JavaScript-Rendering für dynamische Seiten
- Automatische Wiederholungsversuche und CAPTCHA-Auflösung
- Geo-Targeting bis auf die Ebene der Stadt
Wenn Sie mehr Kontrolle benötigen, bietet Floppydata auch statische Proxys für Privatanwender für das Scraping von langen Sitzungen und Proxys für Rechenzentren für die Arbeit mit hohen Geschwindigkeiten an.
Aber für die meisten geschützten Seiten ist Web Unlocker der schnellste Weg, um von einer blockierten Anfrage zu analysierbarem HTML zu gelangen.
Abschließende Gedanken
PHP ist eine sehr fähige Sprache für Web-Scraping, und inzwischen sollten Sie eine solide Grundlage für Web-Scraping mit PHP haben.
Ich beende dieses Tutorial an dieser Stelle, da es sich um eine Einführung in das Web Scraping mit PHP handelt. In zukünftigen Tutorials werden wir unseren Scraper so erweitern, dass er Links folgen, mit Paginierung umgehen und komplexere Ziele scrapen kann.
Wenn Sie in der Zwischenzeit mehr über Web Scraping erfahren möchten, sehen Sie sich diese Ressourcen an:
Sind Sie bereit, den Web Unlocker auszuprobieren? Starten Sie noch heute mit 5 kostenlosen Scrapes und scrapen Sie alles ohne Kopfschmerzen.






