

eBay — это настоящая золотая жила публичных данных о ценах. Миллионы активных объявлений: коллекционные товары, электроника, снятые с производства запчасти и многое другое. Всё это полезно для отслеживания цен, исследования рынка и конкурентного анализа. Проблема только в том, как стабильно получать эти данные. Обычный Python-скрипт, скорее всего, пройдёт всего несколько страниц, прежде чем eBay начнёт показывать CAPTCHA.
В этом гайде я покажу, как правильно парсить eBay с помощью Floppydata Web Unlocker и получать реальные результаты.
Как парсить объявления eBay без постоянной борьбы с CAPTCHA и сломанными селекторами
• eBay быстро блокирует простые скраперы — CAPTCHA, rate limits, bot detection и всё остальное. Обычного Python-запроса здесь недостаточно.
• Более простой путь — Floppydata Web Unlocker. Он берёт на себя антибот-слой и возвращает чистый HTML.
• Дальше достаточно Python и BeautifulSoup, чтобы вытаскивать данные объявлений для price tracking, ресёрча и аналитики.
• Многие старые туториалы по eBay scraping уже не работают — eBay перешёл с li.s-item на li.s-card, а селекторы в гайдах никто не обновил.
• Новые аккаунты Floppydata получают пять бесплатных scrape-запросов, поэтому этот гайд можно пройти без стартовых затрат.
Что такое eBay scraping?
Всё довольно просто: вы собираете публичные данные с eBay-страниц и превращаете их в удобный формат — CSV, JSON или что-то ещё. Вместо того чтобы открывать объявления вручную одно за другим, скрапер забирает данные массово.
Перед тем как перейти к коду, важно понимать два типа страниц:
- Страницы поисковой выдачи — общий список товаров с названием, ценой, состоянием, доставкой и ссылкой на объявление.
- Страницы конкретных товаров — URL вида
/itm/ITEM_ID, где находятся более глубокие данные: полное описание, рейтинг продавца, характеристики товара и варианты.
В этом туториале мы сфокусируемся на страницах поисковой выдачи, потому что именно с них большинство и начинает.
Зачем парсить данные eBay?
Когда сбор данных уже настроен, вариантов использования очень много. Вот основные сценарии, которые я реально использую:
- Отслеживание цен. Вы можете быстро увидеть, за сколько товары реально продаются среди тысяч активных и sold listings. И sold listings особенно важны, потому что они показывают не желаемую цену продавца, а сумму, которую покупатель действительно заплатил.
- Анализ конкурентов. Можно понять, что именно продаётся, в каком состоянии, кто это продаёт и по какой цене. Вместо догадок по ценообразованию вы работаете с реальными данными.
- Ресейл и арбитраж. Это уже практическая часть, которая может приносить деньги. Недооценённые объявления появляются постоянно, а данные помогают находить их раньше других.
- Product research. Перед тем как закупать товар или заходить в новую категорию, можно быстро проверить спрос и понять, есть ли смысл вкладывать деньги.
- Мониторинг продавцов. Если нужно следить за конкретным продавцом, логика та же: вместо поискового URL используете URL его магазина и получаете каталог, цены и изменения по ассортименту.
Если ваша работа связана с resale, ecommerce или pricing, такие данные экономят огромное количество времени и помогают принимать решения быстрее.
Почему бы просто не использовать официальный API?
Для простых задач API — не самый плохой вариант. Например, Browse API нормально справляется с умеренными запросами по активным объявлениям. Но у него есть процесс одобрения, rate limits и ограничения по данным.
Sold listings, reviews и полные variant data могут быть недоступны в том виде, в каком они отображаются на реальной странице. Поэтому если вам нужна полная картина — именно та, которую видит пользователь при загрузке сайта, — scraping часто оказывается более практичным вариантом.
Если вы только разбираетесь в теме, у Floppydata есть хороший материал о том, что такое web unlocker и как он работает.
Почему eBay сложно парсить?
Это не невозможно, но есть несколько вещей, которые быстро создают проблемы. Чаще всего люди упираются в два момента.
Первый — anti-bot detection. eBay использует CAPTCHA, rate limiting, а IP с низким уровнем доверия очень быстро приводит к 403-ошибкам. В начале 2026 защита стала жёстче, поэтому важно работать аккуратно: только публичные данные, нормальная частота запросов и никаких действий, связанных с заказами или приватной информацией. Чтобы получать чистые ответы, нужны residential IP и поведение, похожее на реальный браузер.
Второй момент — разметка страницы. И это более скрытая проблема. Когда я готовил этот гайд, заметил, что eBay уже перешёл с li.s-item на li.s-card, а внутри теперь используются .s-card__title, .s-card__price, .s-card__subtitle и похожие элементы. Многие гайды в интернете всё ещё ссылаются на старую структуру, поэтому они просто не работают. Селекторы рано или поздно устаревают, это нормально для eBay, поэтому лучше сразу добавлять defensive checks для отсутствующих полей.
Именно поэтому я пропускаю всё через Floppydata Web Unlocker, а не пытаюсь напрямую бороться с eBay.
Что понадобится
Три вещи:
- Python 3.10 или выше
- Аккаунт Floppydata с API-ключом для Web Unlocker. Новые аккаунты получают пять бесплатных scrape-запросов, поэтому пройти этот гайд можно без оплаты. Ключ находится в dashboard Web Unlocker.
- Две библиотеки:
requestsиbeautifulsoup4
Сначала установите библиотеки:
pip install requests beautifulsoup4
Затем создайте папку проекта:
mkdir ebay-scraper
cd ebay-scraper
touch ebay_scraper.py
Первый запрос
Сначала я попробовал обычный запрос, чтобы посмотреть, что получится:
import requests
url = "https://www.ebay.com/sch/i.html?_nkw=mechanical+keyboard"
response = requests.get(url)
print(response.status_code)
print(response.text[:500])
В ответ — block page. Не объявления, а просто бесполезная страница. eBay сразу видит обычный Python-запрос: нет fingerprint, нет доверенного IP, поведение не похоже на реальный браузер. Поэтому вместо того чтобы тратить время на обход вручную, я использую Web Unlocker.
Scraping eBay через Floppydata Web Unlocker
Он берёт на себя все неприятные вещи: residential IP, browser fingerprint, page rendering — и возвращает чистый HTML. Плюс списание идёт только за успешные scrape-запросы, поэтому вы не теряете кредиты на неудачных попытках.
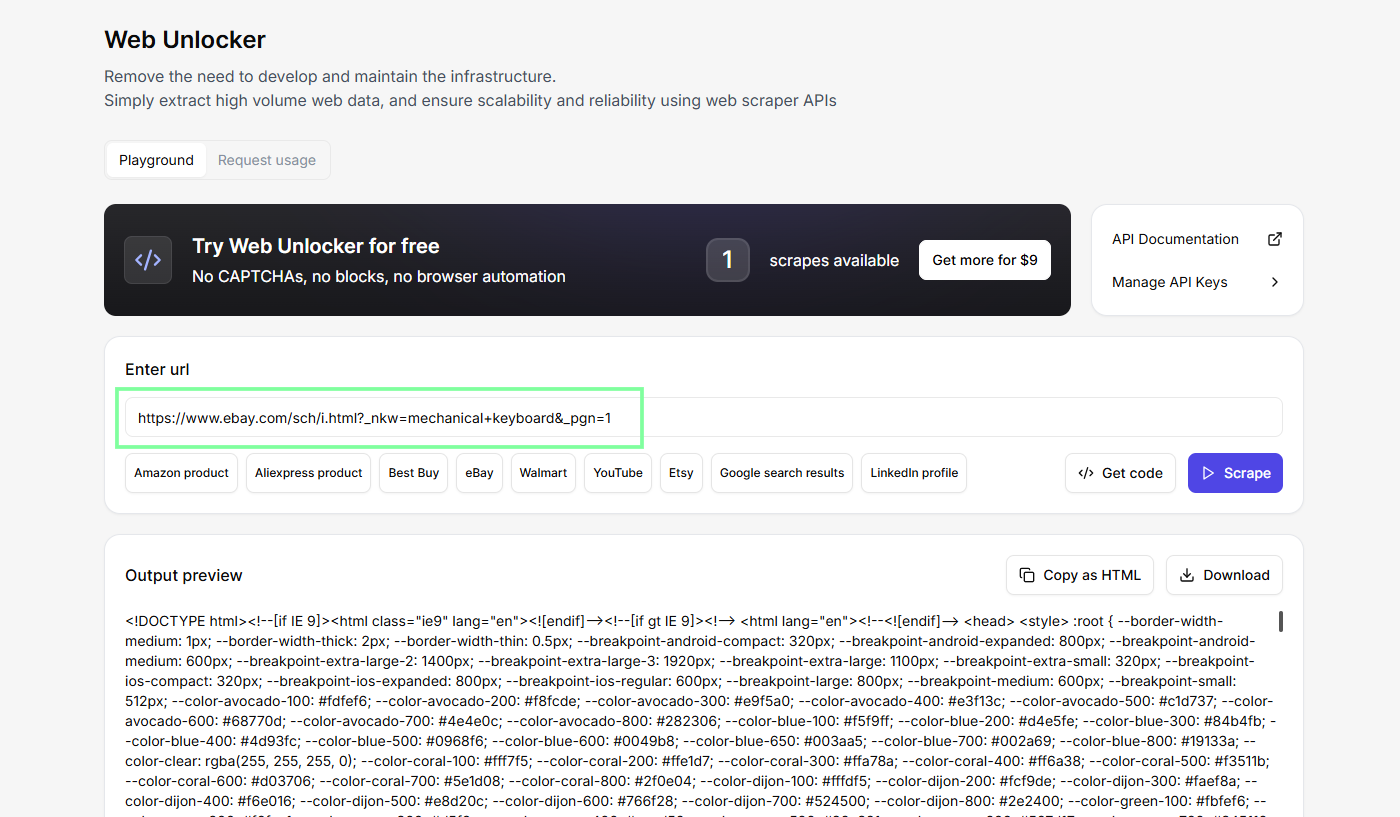
Перед кодом я всегда тестирую URL в playground внутри dashboard (no-code Web Unlocker playground). Вставляете search URL, нажимаете Scrape и смотрите, что вернулось. Так намного проще писать parser, когда уже понятно, с каким HTML вы работаете.
HTML у нас есть, теперь переходим к коду.
Step 1: настраиваем запрос
import requests
import json
from bs4 import BeautifulSoup
API_URL = "https://api.floppydata.net/v1/webUnlocker"
API_KEY = "YOUR_API_KEY"
SEARCH_URL = "https://www.ebay.com/sch/i.html?_nkw=mechanical+keyboard&_pgn=1"
OUTPUT_FILE = "ebay_listings.json"
Замените YOUR_API_KEY на ключ из dashboard.
Параметр _pgn=1 — это номер страницы. Если нужна вторая страница, меняете на _pgn=2. Третья — _pgn=3. Всё просто.
Step 2: получаем страницу через Web Unlocker
def fetch_html(url):
response = requests.post(
API_URL,
headers={
"Content-Type": "application/json",
"X-Api-Key": API_KEY,
},
json={
"url": url,
"country": "US",
"city": "New York",
"difficulty": "medium",
"expiration": 0,
},
timeout=120,
)
response.raise_for_status()
data = response.json()
html = data.get("html")
if not html:
raise ValueError("Unlocker response did not include an 'html' field.")
return html
Country и city направляют запрос через US residential IP. Это важно, потому что цены и видимые объявления могут отличаться в зависимости от локации. Difficulty medium подходит для eBay, потому что у сайта серьёзная антибот-защита. Если поставить ниже, можно просто получить блок. Expiration 0 заставляет каждый раз брать свежую страницу, а не cached response. Готовый HTML возвращается в поле html внутри JSON — именно его дальше парсит BeautifulSoup.
Step 3: извлекаем объявления
Каждый результат на странице выдачи находится внутри контейнера li.s-card. Чтобы аккуратно спарсить eBay listings, мы проходим по каждой карточке и вытаскиваем нужные поля. Defensive checks нужны, чтобы скрипт не падал, если какое-то поле отсутствует:
def extract_listings(html):
soup = BeautifulSoup(html, "html.parser")
cards = soup.select("li.s-card")
listings = []
for card in cards:
title_el = card.select_one(".s-card__title")
title = title_el.get_text(" ", strip=True) if title_el else None
if title:
# eBay appends this as accessibility text
title = title.replace("Opens in a new window or tab", "").strip()
# Skip the placeholder card at the top of search results
if not title or title == "Shop on eBay":
continue
price_el = card.select_one(".s-card__price")
condition_el = card.select_one(".s-card__subtitle")
# Shipping info sits inside attribute rows
shipping = None
for row in card.select(".s-card__attribute-row"):
text = row.get_text(" ", strip=True)
if any(word in text.lower() for word in ("ship", "free", "delivery")):
shipping = text
break
# Grab the first link that points to an item detail page
url = None
for a in card.select("a.s-card__link"):
href = a.get("href")
if href and "/itm/" in href:
url = href.split("?")[0]
break
listings.append({
"title": title,
"price": price_el.get_text(" ", strip=True) if price_el else None,
"condition": condition_el.get_text(" ", strip=True) if condition_el else None,
"shipping": shipping,
"url": url,
})
return listings
Есть два важных нюанса:
- eBay всегда добавляет placeholder card “Shop on eBay” вверху выдачи. Если её не пропустить, первый элемент в массиве listings будет мусором.
- В title также может попадать “Opens in a new window or tab” как accessibility text из anchor tag. Строка с replace очищает это до добавления результата.
Step 4: сохраняем результаты
def main():
print(f"Fetching data from: {SEARCH_URL}")
html = fetch_html(SEARCH_URL)
listings = extract_listings(html)
if not listings:
raise SystemExit("No listings found. eBay may have changed its markup.")
with open(OUTPUT_FILE, "w", encoding="utf-8") as file:
json.dump(listings, file, indent=2)
print(f"Found {len(listings)} listings")
print(f"Saved results to {OUTPUT_FILE}")
if __name__ == "__main__":
main()
Запустите скрипт:
python ebay_scraper.py
И вы должны увидеть примерно такой результат:
[
{
"title": "MSI Forge GK600 TKL Wireless Mechanical Keyboard RGB Bluetooth 2.4GHz",
"price": "$49.99",
"condition": "Brand New",
"shipping": "Free shipping",
"url": "https://www.ebay.com/itm/227344950627"
}
]
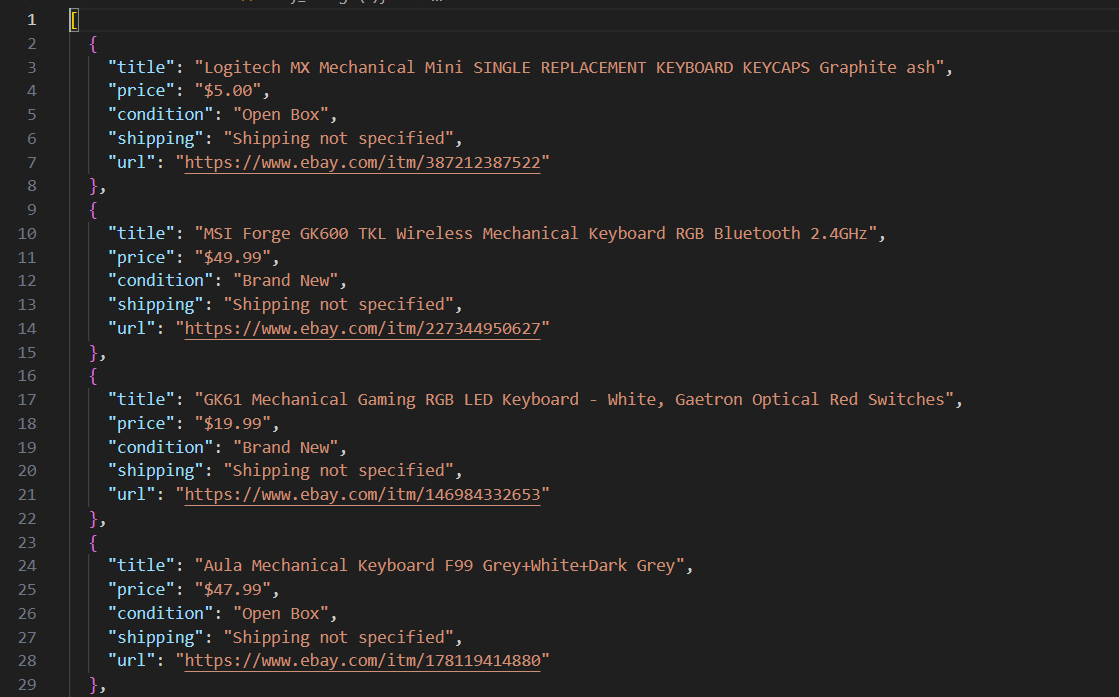
Это значит, что базовый скрапер работает.
Дальше сменить keyword очень просто: меняете _nkw=mechanical+keyboard в URL. Если нужна другая страница, переходите с _pgn=1 на _pgn=2, _pgn=3 и так далее.
Troubleshooting
Если парсить eBay достаточно долго, вы почти наверняка столкнётесь с одним из этих сценариев:
- 403 errors: eBay пометил ваш IP. Решение — отправлять запросы через Web Unlocker с residential IP.
- Empty responses: чаще всего это проблема с rendering. Проверьте, что вы читаете именно поле
htmlв ответе Web Unlocker, а не raw JSON body. - Missing fields: не у каждого объявления есть condition или shipping. Defensive checks в
extract_listingsуже это учитывают. - No results at all: eBay снова поменял CSS-классы. Вернитесь в playground, посмотрите новую разметку и обновите selectors.
Следующий шаг
eBay — не самый сложный сайт для scraping, но CAPTCHA, rate limiting и регулярные изменения разметки быстро превращают прямой парсинг в потерю времени. Если использовать инструмент, который берёт эти проблемы на себя, вы сразу переходите к работе с данными.
Именно для этого подходит Floppydata Web Unlocker: residential proxy rotation, real browser fingerprints, full page rendering и оплата только за успешные responses, так что неудачные scrape-запросы не расходуют кредиты. Добавьте несколько строк BeautifulSoup — и весь процесс становится довольно понятным.
Новые аккаунты получают пять бесплатных scrape-запросов, поэтому этот гайд можно пройти без оплаты.





