

O eBay tem uma mina de ouro de dados públicos sobre preços. Milhões de anúncios ativos em itens colecionáveis, eletrônicos, peças fora de linha, o que você quiser — tudo isso é útil para acompanhar preços, fazer pesquisa de mercado ou análise da concorrência. O problema é conseguir acessar esses dados de forma confiável. Um script simples em Python talvez te deixe ver algumas páginas antes que o eBay comece a te encher de CAPTCHAs.
Então, neste guia, vou te mostrar como fazer o scraping do eBay da maneira certa usando o Web Unlocker da Floppydata e realmente conseguir resultados.
Como extrair anúncios do eBay sem perder tempo com CAPTCHAs e seletores que não funcionam
• O eBay bloqueia rapidamente os scrapers básicos — CAPTCHAs, limites de taxa, detecção de bots, tudo isso. Uma simples solicitação em Python não dá conta do recado.
• A maneira mais fácil é usar o Web Unlocker da Floppydata — ele lida com a camada anti-bot e te entrega um HTML limpo.
• A partir daí, basta usar Python e o BeautifulSoup para extrair dados de listagens para acompanhamento de preços, pesquisa e análise.
• A maioria dos tutoriais de scraping que rolam por aí já não funcionam mais — o eBay mudou de li.s-item para li.s-card e muitos seletores nunca foram atualizados.
• As novas contas do Floppydata têm direito a cinco extrações grátis, então você pode seguir este guia sem precisar gastar nada de cara.
Então, o que é mesmo o “scraping” do eBay?
Sinceramente, é bem simples. Você só precisa extrair os dados dos anúncios disponíveis publicamente das páginas do eBay e transformá-los em algo com que você possa trabalhar — um arquivo CSV, JSON, o que for. Em vez de clicar nos anúncios um por um, um scraper pega tudo isso de uma vez só.
Tem dois tipos de página que vale a pena conhecer antes de entrarmos no código propriamente dito:
- Páginas de resultados de busca: a visualização resumida com título, preço, estado, frete e um link para o anúncio.
- Páginas de detalhes dos itens, os URLs do tipo
/itm/ITEM_ID, onde ficam as informações mais detalhadas, como descrições completas, avaliações do vendedor, especificações do item e opções de variantes.
Neste tutorial, vamos nos concentrar nas páginas de resultados de busca, já que é por aí que a maioria das pessoas começa.
Por que extrair dados do eBay?
Então, depois que você conseguir esses dados, tem, sinceramente, um monte de coisas que dá pra fazer com eles. As que eu realmente uso:
- Acompanhamento de preços. Você consegue ver de uma vez só quais são os preços reais dos produtos em milhares de anúncios ativos e vendidos, e os que já foram vendidos são o que vale a pena, porque é isso que as pessoas realmente pagaram, e não um valor imaginário que o vendedor colocou lá na esperança de conseguir.
- Análise da concorrência. Você pode ver exatamente o que está vendendo, em que estado o produto está sendo vendido, quem está vendendo e quanto estão cobrando; assim, em vez de ficar adivinhando qual preço definir, você simplesmente sabe.
- Revenda e arbitragem. É essa parte que paga as contas, porque os imóveis com preços abaixo do valor de mercado estão disponíveis agora mesmo, e os dados te ajudam a encontrá-los e garantir a compra antes mesmo que outra pessoa os veja.
- Pesquisa de produtos. Antes de investir dinheiro de verdade no estoque de uma categoria, você pode analisar os números e descobrir em poucos minutos se existe uma demanda real ou se você só estaria jogando dinheiro fora em produtos que nunca vendem.
- Acompanhamento do vendedor. E quando você quiser dar uma olhada em um vendedor específico, é exatamente a mesma coisa: basta colocar o URL da loja dele no lugar da busca e, de repente, todo o catálogo e os preços dele estão bem na sua frente.
Se o seu trabalho tem alguma relação com revenda, comércio eletrônico ou definição de preços, esse tipo de dado te poupa uma quantidade absurda de tempo e te ajuda a tomar decisões mais inteligentes com muito mais rapidez.
Por que não usar simplesmente a API oficial?
Sinceramente, não é uma opção ruim para coisas simples. A API Browse lida bem com consultas de volume moderado em anúncios ativos. Mas tem um processo de aprovação que você precisa passar primeiro, limites de taxa que entram em ação bem rápido e, além disso, ela simplesmente não oferece tudo o que você precisa.
Os anúncios vendidos não aparecem, as avaliações não aparecem, os dados completos das variantes não aparecem da mesma forma que aparecem na página real. Então, quando você precisa ter uma visão completa — o tipo de informação que um usuário de verdade vê ao carregar a página —, o scraping é simplesmente a opção mais prática.
Se você ainda não conhece muito bem esse assunto, o Floppydata tem um bom guia básico sobre o que um “web unlocker” realmente faz.
O que torna difícil fazer scraping no eBay?
Não é impossível, mas com certeza tem algumas coisas que vão contra você. Duas coisas, mais especificamente, com as quais a maioria das pessoas se depara.
Uma delas é a detecção anti-bot. O eBay usa CAPTCHAs e limitação de taxa, e um IP de baixa confiança vai te render erros 403 rapidinho. Eles também reforçaram as regras no início de 2026, então seja responsável: use só dados públicos, mantenha as taxas de solicitação normais, nada que envolva pedidos ou coisas do tipo. Você precisa de IPs residenciais e de algo que realmente se pareça com o comportamento de um navegador, ou não vai conseguir respostas corretas.
A segunda é a marcação, e essa aí é meio sorrateira. Enquanto eu estava montando isso, percebi que o eBay já tinha mudado de li.s-item para li.s-card, e tudo o que estava lá dentro, tipo .s-card__title, .s-card__price e .s-card__subtitle. A maioria dos guias online ainda aponta para a estrutura antiga, então agora eles simplesmente não funcionam mais. Seus seletores vão ficar desatualizados em algum momento, é assim mesmo com o eBay, então inclua algumas verificações preventivas para campos ausentes desde o início.
De qualquer forma, é por isso que eu faço tudo pelo Web Unlocker da Floppydata, em vez de ficar me debatendo diretamente com o eBay.
Pré-requisitos
Três coisas:
- Python 3.10 ou superior
- Uma conta no Floppydata com uma chave da API do Web Unlocker. Cada conta nova vem com cinco extrações grátis, então você pode seguir todo esse guia sem precisar pagar nada. A chave fica no painel do Web Unlocker.
- Duas bibliotecas:
requestsebeautifulsoup4
Primeiro, instale as duas bibliotecas:
pip install requests beautifulsoup4
Então, a pasta do seu projeto:
mkdir ebay-scraper
cd ebay-scraper
touch ebay_scraper.py
Enviando a primeira solicitação
A primeira coisa que tentei foi só uma solicitação básica pra ver o que acontecia:
import requests
url = "https://www.ebay.com/sch/i.html?_nkw=mechanical+keyboard"
response = requests.get(url)
print(response.status_code)
print(response.text[:500])
Bloqueia a página. Não tem anúncios, só coisas inúteis. O eBay detecta uma solicitação simples em Python na hora: sem assinatura digital, sem IP confiável… simplesmente não vai rolar. Então, em vez de perder tempo com isso, eu só uso o Web Unlocker.
Extraiendo dados do eBay com o Floppydata Web Unlocker
Ele cuida de todas as coisas chatas: IP residencial, impressão digital do navegador, renderização da página e te entrega um HTML limpo. Além disso, só cobra pelas extrações bem-sucedidas, então você não perde créditos nas que derem errado.
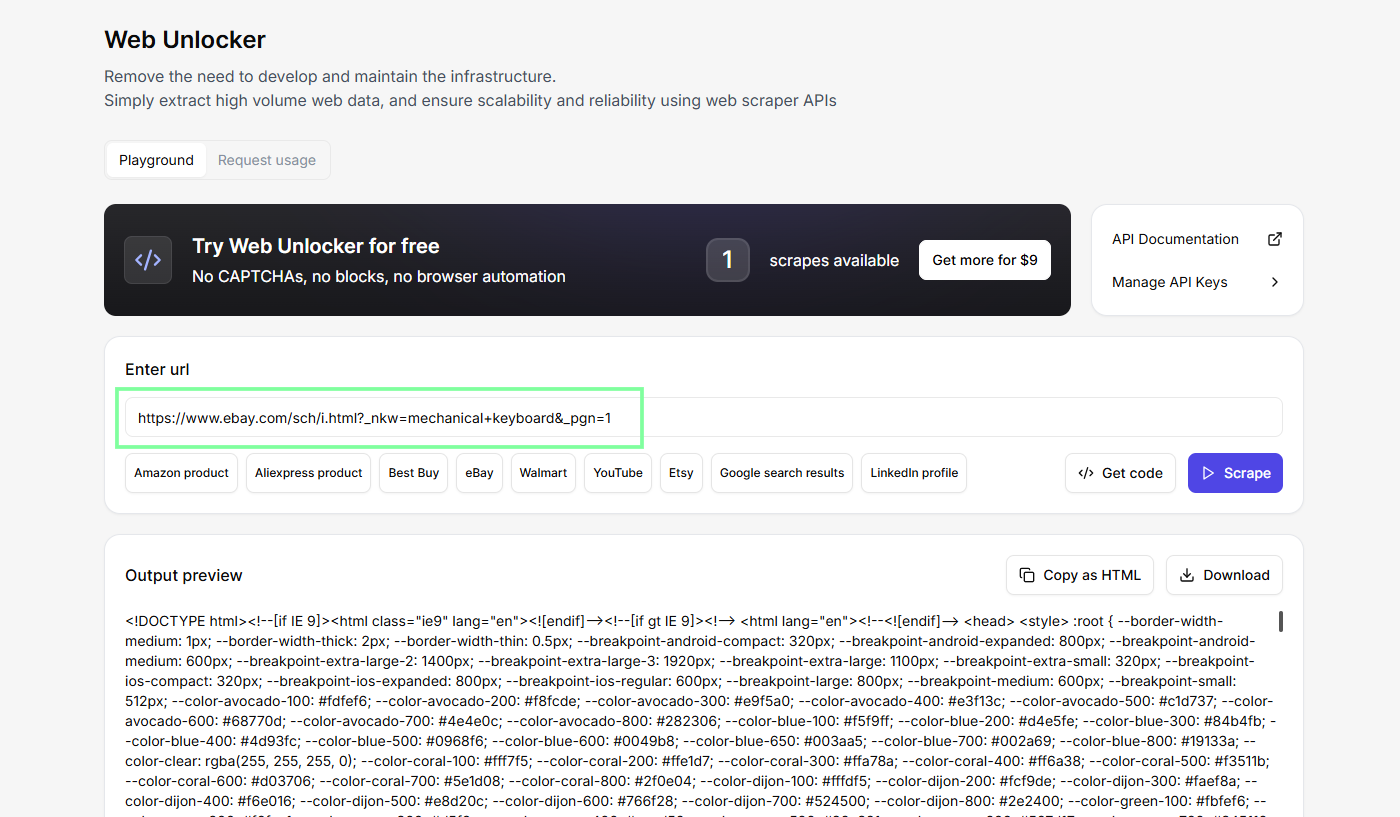
Eu sempre testo no ambiente de testes do painel (ambiente de testes do Web Unlocker sem código) antes de escrever qualquer coisa. Cola a URL de busca, clica em “Scrape” e vê o que aparece. É muito mais fácil criar um analisador quando você já sabe com o que está trabalhando.
Já temos o HTML, então vamos passar para a programação.
Etapa 1: Configurar a solicitação
import requests
import json
from bs4 import BeautifulSoup
API_URL = "https://api.floppydata.net/v1/webUnlocker"
API_KEY = "YOUR_API_KEY"
SEARCH_URL = "https://www.ebay.com/sch/i.html?_nkw=mechanical+keyboard&_pgn=1"
OUTPUT_FILE = "ebay_listings.json"
Substitua YOUR_API_KEY pela chave do seu painel.
Além disso, _pgn=1 é só o número da página. Se quiser a segunda página, mude para _pgn=2. A terceira página, _pgn=3. Simples.
Etapa 2: Obtenha a página por meio do Web Unlocker
def fetch_html(url):
response = requests.post(
API_URL,
headers={
"Content-Type": "application/json",
"X-Api-Key": API_KEY,
},
json={
"url": url,
"country": "US",
"city": "New York",
"difficulty": "medium",
"expiration": 0,
},
timeout=120,
)
response.raise_for_status()
data = response.json()
html = data.get("html")
if not html:
raise ValueError("Unlocker response did not include an 'html' field.")
return html
O país e a cidade garantem que a solicitação passe por um IP residencial dos EUA, o que afeta tanto o preço quanto os anúncios que realmente aparecem. A dificuldade medium é a configuração certa para o eBay, especialmente porque ele tem uma proteção anti-bot bem forte. Se usar um valor menor, você simplesmente vai ser bloqueado. A expiração 0 força o carregamento de uma página nova a cada vez, em vez de usar uma resposta em cache. O HTML renderizado aparece no campo html do JSON, e é isso que o BeautifulSoup analisa na próxima etapa. Se quiser ver todos os parâmetros disponíveis, a referência da API do Web Unlocker tem todos eles.
Etapa 3: Extraia as listagens
Cada resultado na página de busca é um li.s-card container. Para extrair os anúncios do eBay de forma organizada, percorremos cada cartão e extraímos os campos que queremos, usando verificações preventivas para que a falta de um campo nunca faça o programa travar:
def extract_listings(html):
soup = BeautifulSoup(html, "html.parser")
cards = soup.select("li.s-card")
listings = []
for card in cards:
title_el = card.select_one(".s-card__title")
title = title_el.get_text(" ", strip=True) if title_el else None
if title:
# eBay appends this as accessibility text
title = title.replace("Opens in a new window or tab", "").strip()
# Skip the placeholder card at the top of search results
if not title or title == "Shop on eBay":
continue
price_el = card.select_one(".s-card__price")
condition_el = card.select_one(".s-card__subtitle")
# Shipping info sits inside attribute rows
shipping = None
for row in card.select(".s-card__attribute-row"):
text = row.get_text(" ", strip=True)
if any(word in text.lower() for word in ("ship", "free", "delivery")):
shipping = text
break
# Grab the first link that points to an item detail page
url = None
for a in card.select("a.s-card__link"):
href = a.get("href")
if href and "/itm/" in href:
url = href.split("?")[0]
break
listings.append({
"title": title,
"price": price_el.get_text(" ", strip=True) if price_el else None,
"condition": condition_el.get_text(" ", strip=True) if condition_el else None,
"shipping": shipping,
"url": url,
})
return listings
Duas coisas que vale a pena saber.
- O eBay sempre coloca um cartão de lugar-marcador do “Shop on eBay” no topo dos resultados de busca. Se você não pular isso, o primeiro item da lista de resultados vai ser só lixo inútil.
- O título também pega “Abre em uma nova janela ou aba” como texto de acessibilidade da tag âncora, para que a linha de substituição limpe isso antes que qualquer coisa seja acrescentada.
Passo 4: Salve os resultados
def main():
print(f"Fetching data from: {SEARCH_URL}")
html = fetch_html(SEARCH_URL)
listings = extract_listings(html)
if not listings:
raise SystemExit("No listings found. eBay may have changed its markup.")
with open(OUTPUT_FILE, "w", encoding="utf-8") as file:
json.dump(listings, file, indent=2)
print(f"Found {len(listings)} listings")
print(f"Saved results to {OUTPUT_FILE}")
if __name__ == "__main__":
main()
Execute o script:
python ebay_scraper.py
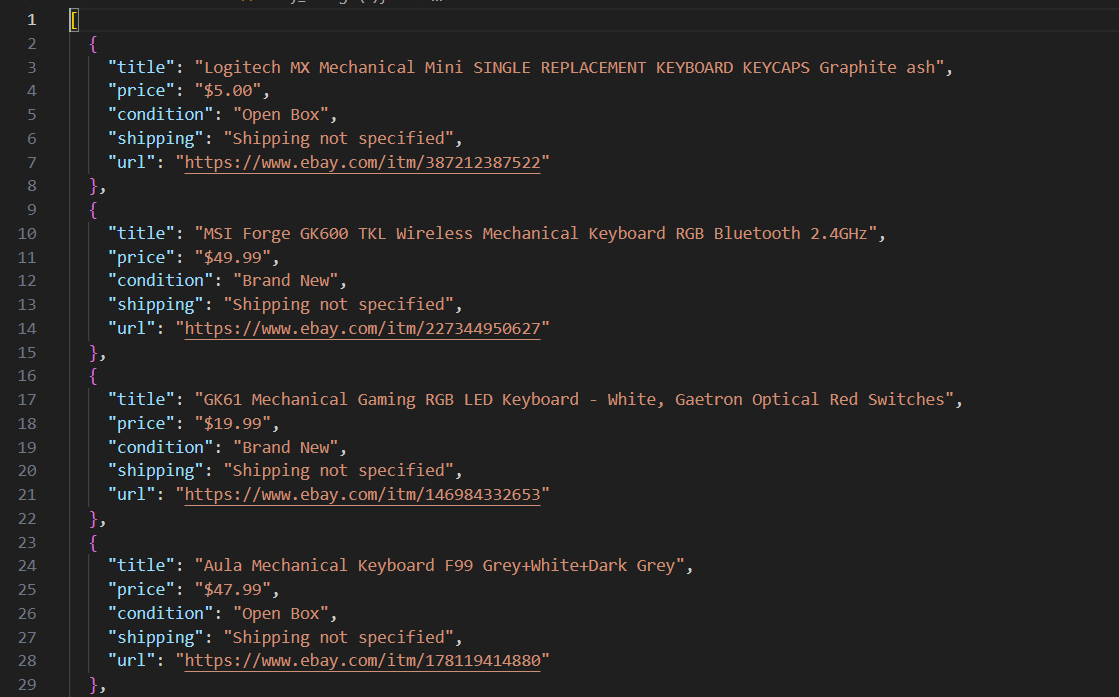
E você deve ver algo assim:
[
{
"title": "MSI Forge GK600 TKL Wireless Mechanical Keyboard RGB Bluetooth 2.4GHz",
"price": "$49.99",
"condition": "Brand New",
"shipping": "Free shipping",
"url": "https://www.ebay.com/itm/227344950627"
}
]
É assim que o scraper básico funciona.
A partir daqui, para mudar a palavra-chave, basta alterar _nkw=mechanical+keyboard na URL. Se quiser outra página, você pode ir de _pgn=1 para _pgn=2, _pgn=3 e assim por diante.
Solução de problemas
Então, é óbvio: se você ficar vasculhando o eBay por tempo suficiente, provavelmente vai encontrar um desses:
- Erros 403: o eBay bloqueou seu IP. A solução é usar o Web Unlocker com IPs residenciais.
- Respostas vazias: geralmente é um problema de renderização. Confere se você está lendo o campo `
html` na resposta do Web Unlocker, e não o corpo JSON bruto. - Campos em falta: nem todos os anúncios têm informações sobre o estado do produto ou o frete preenchidas. As verificações preventivas em
extract_listingsjá cuidam disso. - Nenhum resultado: o eBay mudou os nomes das classes CSS de novo. Volta pro playground, dá uma olhada na nova marcação e atualiza seus seletores.
Seu próximo passo
Olha, o eBay não é o site mais complicado de se lidar, mas entre os CAPTCHAs, a limitação de solicitações e o fato de que a margem de lucro às vezes muda do nada, tentar fazer isso sem a configuração certa só vai te fazer perder tempo. Usar um serviço que cuida de tudo isso significa que você vai direto para a parte de realmente trabalhar com os dados.
É nisso que o Web Unlocker da Floppydata se destaca. Rotação de proxies residenciais, impressões digitais reais de navegadores, renderização de página inteira, e você só paga pelas respostas bem-sucedidas, então as tentativas de scraping que derem errado não te custam nada. Joga lá umas linhas de BeautifulSoup e, sinceramente, tudo fica bem simples.
Cada conta nova vem com cinco tentativas grátis, então você pode seguir todo esse guia sem pagar nada.





