

Introdução
O PHP foi uma das minhas primeiras linguagens como desenvolvedor da Web, e ainda gosto de usá-lo para raspagem.
Este tutorial aborda o que eu realmente uso na produção. Vou orientar você em um fluxo de trabalho completo de raspagem da Web em PHP usando o Floppydata Web Unlocker como camada de raspagem.
Por que a Floppydata?
Porque ele fornece uma API de raspagem que elimina a necessidade de gerenciar proxies, cabeçalhos ou lógica anti-bot. Ao final deste artigo, você terá um conhecimento sólido sobre como realizar raspagem da Web com PHP.
O que é raspagem da Web em PHP?
O web scraping PHP é o processo de usar o código PHP para extrair dados de sites. Nem todos os sites fornecem uma API, como o Twitter, por exemplo, portanto, em muitos casos, a única maneira de obter as informações de que você precisa é buscar a página e analisar o HTML por conta própria.
O PHP faz muito sentido para isso se você já o usa todos os dias. Você pode inserir os dados extraídos diretamente em um backend existente, armazená-los no MySQL ou executar o raspador em um trabalho cron sem introduzir outra linguagem na pilha.
A questão principal não é se o PHP pode fazer scraping. Com certeza pode. A verdadeira questão é se o seu coletor de dados lida bem com solicitações bloqueadas, restrições baseadas em locais e CAPTCHAs agressivos.
É exatamente por isso que eu uso PHP com o Floppydata Web Unlocker para ajudar você a preencher essa lacuna.
Vale a pena conhecer as bibliotecas PHP de raspagem da Web (2026)
O PHP tem muitas bibliotecas de raspagem, mas, sinceramente, escolhi apenas algumas que realmente uso. Aqui está uma rápida olhada nelas.
- Guzzle: Um cliente HTTP sólido que lida com solicitações POST, cargas úteis JSON, redirecionamentos e cabeçalhos de forma limpa. Vamos usá-lo ao longo deste tutorial para conversar com a API do Web Unlocker.
- Symfony DomCrawler: Permite que você navegue em HTML e XML usando seletores CSS ou XPath. Quando combinado com o componente symfony/css-selector, ele oferece a você uma filtragem no estilo jQuery que funciona de forma confiável em HTML confuso. Ele é autônomo, portanto você não precisa do restante do Symfony.
- Symfony HttpBrowser: Esse é o substituto moderno da biblioteca Goutte, agora obsoleta. Ela foi criada com base no BrowserKit e no DomCrawler e permite que você simule cliques, envios de formulários e cadeias de redirecionamento. É excelente quando sua lógica de raspagem abrange várias páginas.
- DiDOM: O DiDOM é um analisador rápido e de dependência zero com uma API semelhante à do jQuery. Perfeito para scripts menores em que você deseja evitar o uso de componentes do Symfony.
- Symfony Panther: Conduz um navegador Chrome ou Chromium real por meio do WebDriver. Você pode usar isso quando um site renderiza tudo em JavaScript (React, Vue, SPAs pesados) e uma solicitação HTTP simples retorna um shell vazio. Como é mais pesado, eu o uso somente quando nada mais funciona.
O Goutte costumava ser uma recomendação comum, mas agora está obsoleto, portanto, eu não recomendaria que você criasse um novo projeto com base nele.
Para este guia, o Guzzle e o Symfony DomCrawler são suficientes. Como o Web Unlocker já executa o JavaScript e retorna o HTML final renderizado, não precisamos executar um navegador sem cabeça no nosso lado.
Pré-requisitos
Antes de escrever qualquer código, certifique-se de que você tenha os quatro itens a seguir no lugar. Se você nunca configurou um projeto PHP do zero, não se preocupe, eu o orientarei em todas as etapas.
1. PHP 8.2 ou mais recente
O PHP vem pré-instalado em muitos sistemas Mac e Linux, mas nunca é demais verificar. Abra o terminal e verifique a versão do PHP:
php -vSe o PHP já estiver instalado, você verá um número de versão. Para este tutorial, use o PHP 8.2 ou mais recente. Esse é o ponto de partida mais seguro com as versões de dependência que vamos instalar.
Se o PHP estiver ausente, siga as instruções para instalá-lo:
# Windows (Chocolatey, run PowerShell as Administrator)
choco install php
# macOS (Homebrew)
brew install phpApós a instalação, execute novamente o endereço php -v para confirmar a versão. No Homebrew, você não precisa de pacotes php-curl ou php-xml separados para este tutorial. Essas extensões já estão incluídas na instalação principal do PHP.
2. Compositor
O Composer é o gerenciador de pacotes padrão para PHP. Ele é basicamente o equivalente ao npm ou pip para projetos PHP. Vamos usá-lo para instalar o Guzzle e os pacotes do analisador Symfony.
Primeiro, verifique se ele já está disponível:
composer --versionSe o Composer ainda não estiver instalado, use:
# Windows (Chocolatey, as Administrator)
choco install composer
# macOS (Homebrew)
brew install composerQuando isso for feito, o site composer --version deverá imprimir um número de versão e você estará pronto para criar o projeto.
3. Uma conta Floppydata
Crie uma conta na Floppydata e copie sua chave de API do painel. Cada nova conta recebe 5 scrapes gratuitos para o Web Unlocker.
Depois de fazer login em seu painel, vá para Manage API Keys (Gerenciar chaves de API) no Web Unlocker e gere uma chave de API. Copie-a imediatamente e guarde-a em um local seguro.
Você usará essa chave no cabeçalho X-Api-Key de cada solicitação do Web Unlocker. Vamos adicioná-la ao nosso código em alguns minutos.
4. Diretório do projeto e dependências
Agora, vamos criar a pasta em que nosso coletor de dados ficará e instalar as bibliotecas PHP de que precisamos. Em seu terminal:
mkdir php-scrape-countries
cd php-scrape-countriesInicialize um novo projeto do Composer:
composer init --name="myname/country-scraper" --require="php:^8.2" --no-interactionAgora, instale os pacotes necessários:
composer require guzzlehttp/guzzle symfony/dom-crawler:^7.4 symfony/css-selector:^7.4O Composer fará o download das três bibliotecas e de suas dependências em uma pasta vendor/ e criará um arquivo composer.json que rastreia exatamente quais versões você está usando.
A partir de agora, cada arquivo PHP no projeto pode carregar as dependências com:
require_once __DIR__ . '/vendor/autoload.php';Nesse ponto, a configuração está concluída e podemos passar para o raspador propriamente dito.
Como extrair dados com PHP usando o Floppydata Web Unlocker
Etapa 1: Teste seu alvo
Nunca gosto de escrever código às cegas para saber exatamente quais seletores e estrutura de dados você deve esperar. Para este exemplo, vou usar o scrapethissite, um site de demonstração para raspagem de dados. Ele contém uma lista de todos os 250 países com sua capital, população e área.
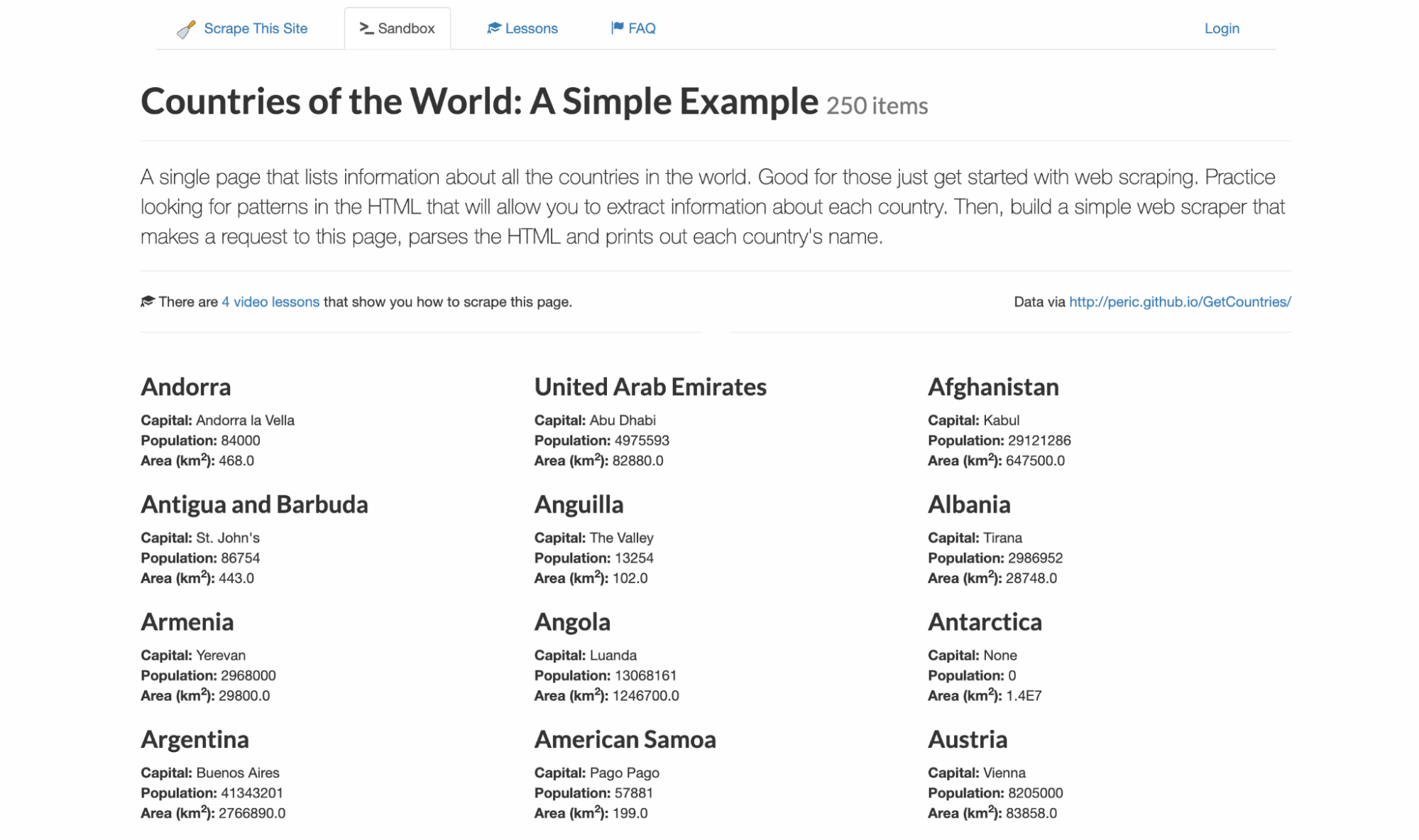
Para acompanhar você, visite o Floppydata Web Unlocker Playground. Essa ferramenta sem código está disponível diretamente no seu painel e permite que você veja o HTML exato que a API retornará sem configurar um projeto.
Agora, digite o URL e clique em Scrape. Em segundos, você verá o HTML completo na visualização de saída. Esse é exatamente o mesmo HTML que seu script PHP receberá daqui a algumas etapas.
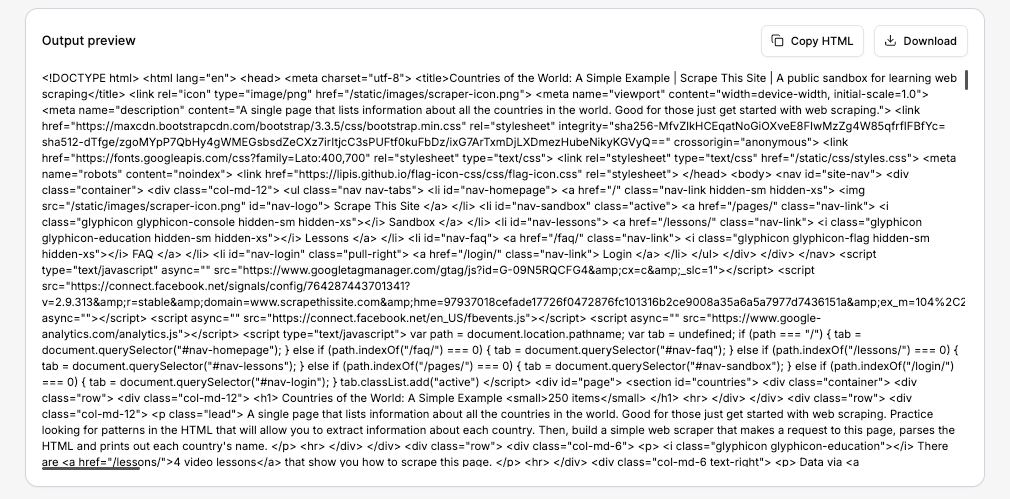
Se os dados parecerem corretos, você poderá copiar o HTML ou fazer download da resposta. Mas, no nosso caso, deixaremos que o script PHP faça isso automaticamente.
Etapa 2: Enviando sua primeira solicitação do Web Unlocker com o Guzzle
O núcleo de todo o fluxo de trabalho é uma solicitação POST para o endpoint da Floppydata:
https://client-api.floppy.host/v1/webUnlockerPara fazer isso, primeiro criamos um cliente Guzzle e preparamos a configuração da solicitação. Em seguida, enviamos a solicitação e tratamos a resposta.
Crie um arquivo chamado scrape.php e comece com o esqueleto básico:
<?php
// scrape.php
require_once __DIR__ . '/vendor/autoload.php';
use GuzzleHttp\Client;
$apiKey = 'YOUR_API_KEY'; // Replace with your real key
$targetUrl = 'https://www.scrapethissite.com/pages/simple/';
$client = new Client([
'base_uri' => 'https://client-api.floppy.host',
'timeout' => 60,
]);Substitua YOUR_API_KEY por sua chave real. Agora, criamos a chamada POST real. Enviamos JSON para o endpoint da API, incluímos a chave da API nos cabeçalhos e passamos o URL de destino mais alguns argumentos no corpo:
$response = $client->post('/v1/webUnlocker', [
'headers' => [
'Content-Type' => 'application/json',
'X-Api-Key' => $apiKey,
],
'json' => [
'url' => $targetUrl,
'country' => 'US',
'city' => 'New York',
'difficulty' => 'low',
'expiration' => 0,
],
]);
$payload = json_decode((string) $response->getBody(), true);
$html = $payload['html'] ?? '';
echo "HTML received! Length: " . strlen($html) . " characters\n";Os campos país e cidade informam ao Web Unlocker por qual localização geográfica você deve encaminhar a solicitação. O campo difficulty controla a agressividade com que o desbloqueador lida com as proteções antibot. Estou usando low aqui porque nosso alvo de sandbox não tem nenhuma proteção.
Para alvos protegidos por Cloudflare ou DataDome, defina isso como médio para que o desbloqueador aplique uma lógica mais forte de impressão digital e de solução de CAPTCHA.
Agora, observe que o Web Unlocker retorna o HTML bruto dentro de um objeto JSON, o que significa que você precisa decodificar o JSON e extrair a marcação real da página do campo html.
Se você se esquecer disso e tratar todo o corpo da resposta como HTML, seu analisador será interrompido. Com isso, o lado da solicitação está concluído e podemos passar para a análise.
Etapa 3: Inspecione a estrutura da página
Depois que a solicitação for bem-sucedida, a próxima tarefa é inspecionar a estrutura da página e direcionar os elementos repetidos que contêm os dados que desejamos. Cada país da página segue exatamente esse padrão HTML:
<div class="col-md-4 country">
<h3 class="country-name">
<i class="flag-icon flag-icon-ad"></i>
Andorra
</h3>
<div class="country-info">
<strong>Capital:</strong> <span class="country-capital">Andorra la Vella</span><br>
<strong>Population:</strong> <span class="country-population">84000</span><br>
<strong>Area (km<sup>2</sup>):</strong> <span class="country-area">468.0</span><br>
</div>
</div>Essa estrutura repetida é o que torna essa página extremamente previsível. Cada cartão de país usa os mesmos nomes de classe: .country para o invólucro, .country-name para o título e.country-capital, .country-population e .country-area para os campos de dados dentro de .country-info.
Etapa 4: Analisar dados com o Symfony DomCrawler
Como as classes são consistentes em todas as 250 entradas, podemos percorrer cada elemento .country e extrair os valores dos seletores filhos. Mas, primeiro, vamos adicionar uma pequena função auxiliar para nos ajudar a limpar o texto que extraímos:
use Symfony\Component\DomCrawler\Crawler;
function normalizeText(string $text): string
{
return preg_replace('/\s+/', ' ', trim($text)) ?? trim($text);
}Se você observar o HTML bruto, os nomes dos países têm espaços em branco e novas linhas extras ao redor deles por causa das tags do ícone da bandeira <i> dentro do <h3>.
A função normalizeText() ajuda a remover os espaços em branco à esquerda e à direita e, em seguida, usa um regex para recolher quaisquer espaços ou novas linhas restantes, de modo que nomes como Andorra ou St. John’s retornem de forma limpa, em vez de carregar os espaços em branco restantes do HTML.
Com o helper pronto, criamos uma instância do Crawler e fazemos um loop em cada cartão de país:
$crawler = new Crawler($html);
$countries = [];
$crawler->filter('.country')->each(function (Crawler $node) use (&$countries): void {
$countries[] = [
'name' => normalizeText($node->filter('.country-name')->text()),
'capital' => normalizeText($node->filter('.country-capital')->text()),
'population' => normalizeText($node->filter('.country-population')->text()),
'area' => normalizeText($node->filter('.country-area')->text()),
];
});
echo 'Parsed ' . count($countries) . " countries\n";O DomCrawler nos oferece uma maneira limpa de percorrer o HTML usando seletores CSS. Começamos envolvendo o HTML em um objeto Crawler e, em seguida, filtramos todos os blocos .country da página. Dentro de cada bloco, pegamos o nome, a capital, a população e a área.
Nesse ponto, se você executar o script, deverá ver a mensagem “Parsed 250 countries” impressa no terminal.
Etapa 5: exportar os resultados para CSV e JSON
Quando o analisador fornece a você uma matriz $countries, a exportação dos dados se torna muito simples.
$csvHandle = fopen('countries.csv', 'w');
fputcsv($csvHandle, ['Country', 'Capital', 'Population', 'Area (km2)'], ',', '"', '');
foreach ($countries as $country) {
fputcsv($csvHandle, [
$country['name'],
$country['capital'],
$country['population'],
$country['area'],
], ',', '"', '');
}
fclose($csvHandle);
file_put_contents('countries.json', json_encode($countries, JSON_PRETTY_PRINT | JSON_UNESCAPED_SLASHES));A exportação CSV é útil porque fornece aos leitores um arquivo que pode ser aberto imediatamente no Excel, no Google Sheets ou em qualquer outra ferramenta de planilha eletrônica. A exportação JSON é igualmente útil se você quiser alimentar os dados extraídos em outro script PHP ou em uma API posteriormente.
Uma pequena atualização aqui é o argumento de escape explícito em fputcsv(). Nas versões mais recentes do PHP, isso evita avisos de depreciação e mantém o exemplo limpo quando os leitores o executam no terminal.
Etapa nº 6: Junte tudo em um único script
Agora que cada parte funciona por si só, aqui está o script completo:
<?php
declare(strict_types=1);
require_once __DIR__ . '/vendor/autoload.php';
use GuzzleHttp\Client;
use Symfony\Component\DomCrawler\Crawler;
function normalizeText(string $text): string
{
return preg_replace('/\s+/', ' ', trim($text)) ?? trim($text);
}
$apiKey = 'YOUR_API_KEY';
$targetUrl = 'https://www.scrapethissite.com/pages/simple/';
if ($apiKey === 'YOUR_API_KEY') {
fwrite(STDERR, "Replace YOUR_API_KEY before running the script.\n");
exit(1);
}
$client = new Client([
'base_uri' => 'https://client-api.floppy.host',
'timeout' => 60,
]);
try {
$response = $client->post('/v1/webUnlocker', [
'headers' => [
'Content-Type' => 'application/json',
'X-Api-Key' => $apiKey,
],
'json' => [
'url' => $targetUrl,
'country' => 'US',
'city' => 'New York',
'difficulty' => 'low',
'expiration' => 0,
],
]);
} catch (Throwable $e) {
fwrite(STDERR, "Request failed: {$e->getMessage()}\n");
exit(1);
}
$payload = json_decode((string) $response->getBody(), true);
if (!is_array($payload) || !isset($payload['html']) || !is_string($payload['html'])) {
fwrite(STDERR, "Unexpected API response. Expected JSON with an html field.\n");
exit(1);
}
$crawler = new Crawler($payload['html']);
$countries = [];
$crawler->filter('.country')->each(function (Crawler $node) use (&$countries): void {
$countries[] = [
'name' => normalizeText($node->filter('.country-name')->text()),
'capital' => normalizeText($node->filter('.country-capital')->text()),
'population' => normalizeText($node->filter('.country-population')->text()),
'area' => normalizeText($node->filter('.country-area')->text()),
];
});
if ($countries === []) {
fwrite(STDERR, "No countries were parsed.\n");
exit(1);
}
$csvHandle = fopen(__DIR__ . '/countries.csv', 'w');
if ($csvHandle === false) {
fwrite(STDERR, "Could not create countries.csv.\n");
exit(1);
}
fputcsv($csvHandle, ['Country', 'Capital', 'Population', 'Area (km2)'], ',', '"', '');
foreach ($countries as $country) {
fputcsv($csvHandle, [
$country['name'],
$country['capital'],
$country['population'],
$country['area'],
], ',', '"', '');
}
fclose($csvHandle);
file_put_contents(__DIR__ . '/countries.json', json_encode($countries, JSON_PRETTY_PRINT | JSON_UNESCAPED_SLASHES));
echo 'Done! Parsed ' . count($countries) . " countries.\n";
echo "Saved countries.csv and countries.json\n";Substitua ‘YOUR_API_KEY’ e execute-o desta forma:
php scrape.phpQuando tudo estiver configurado corretamente, o script buscará a página por meio do Web Unlocker, analisará todos os 250 países e gravará countries.csv e countries.json na pasta do seu projeto.
Exibindo os resultados
Depois que o script for concluído, você poderá abrir o arquivo countries.csv imediatamente. As primeiras linhas terão a seguinte aparência:
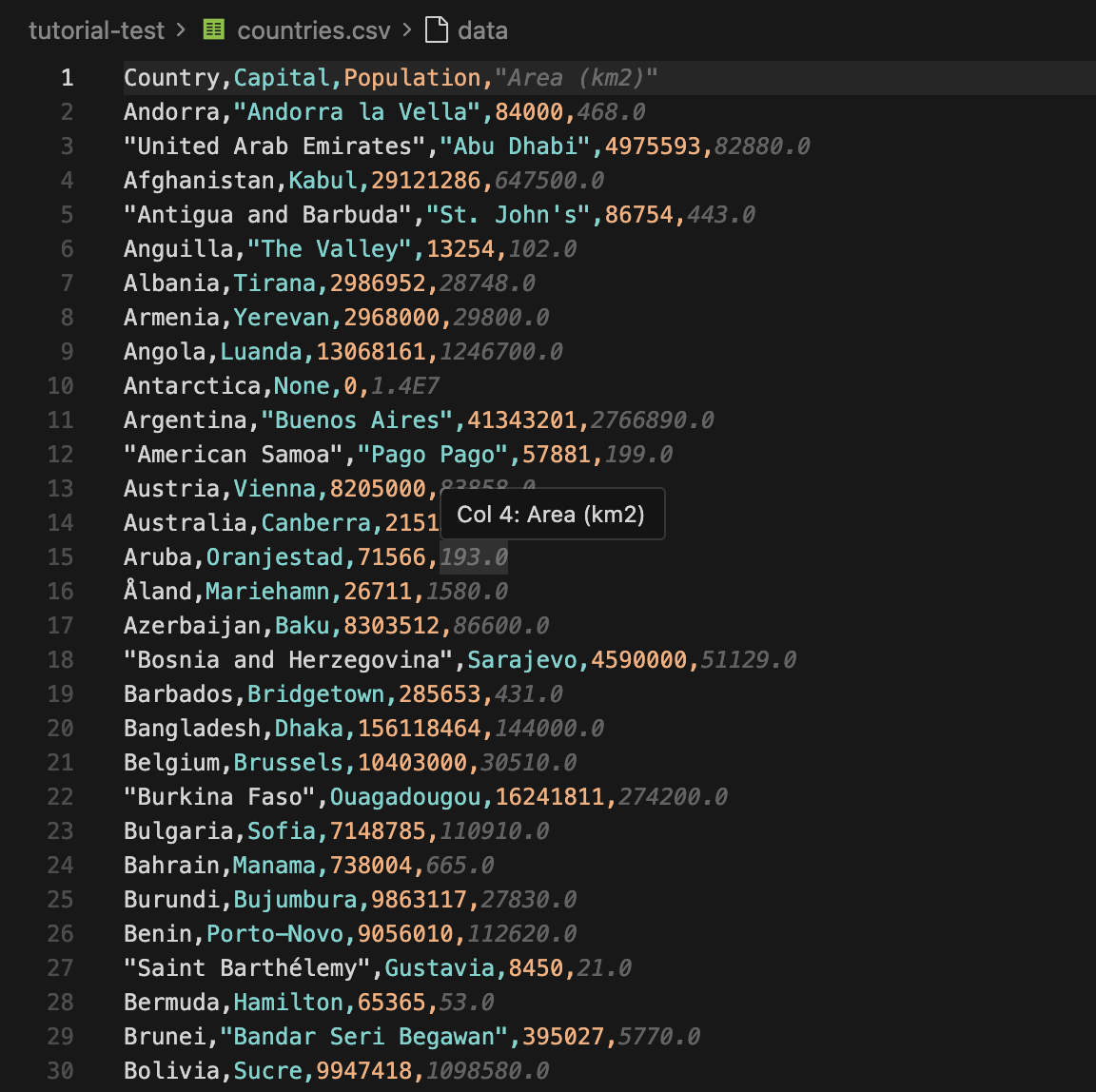
Agora você pode importar o CSV para uma planilha ou enviar o JSON para outro aplicativo. Se quiser usar esse fluxo de trabalho para rastreamento de preços, você pode combiná-lo com os proxies de monitoramento de preços da Floppydata, portanto, é bom dar uma olhada nisso.
Como lidar com medidas anti-scraping
Uma página simples e estática não é difícil de analisar, como acabamos de ver. Mas sites protegidos podem ser uma dor de cabeça.
Você pode se deparar com bloqueios, dados ausentes, CAPTCHAs, renderização de JavaScript ou limites de taxa. É nesse ponto que um scraper PHP normal começa a ter dificuldades.
Aqui estão os problemas comuns que você pode enfrentar:
- Bloqueio de IP: Os sites podem bloquear seu endereço IP se detectarem várias solicitações provenientes do mesmo IP em um curto período.
- CAPTCHAs: Os sistemas CAPTCHA são usados para diferenciar entre bots e humanos, apresentando desafios que são difíceis de serem resolvidos pelos bots.
- Limitação de taxa: Os sites geralmente limitam o número de solicitações que você pode fazer em um determinado período de tempo para evitar o excesso de raspagem.
- Detecção de agente de usuário: Os agentes de usuário que não são do navegador são bloqueados porque não se parecem com visitantes reais.
- Desafios do JavaScript: O conteúdo só é carregado após a execução do JavaScript, o que uma solicitação HTTP simples pode não ocorrer.
Você pode tentar resolver esses problemas manualmente, mas isso não é conveniente nem dimensionável.
É aí que entra o Floppydata Web Unlocker. Em vez de resolver cada desafio sozinho, você pode descarregar toda a camada anti-bot e se concentrar na extração e no armazenamento dos dados.
Floppydata Web Unlocker manipula:
- Rotação de IP com um grande conjunto de proxies residenciais e de data center
- Impressão digital do navegador e navegadores sem cabeça
- Renderização de JavaScript para páginas dinâmicas
- Tentativas automáticas e resolução de CAPTCHA
- Segmentação geográfica até o nível da cidade
Se você precisar de mais controle, a Floppydata também oferece proxies residenciais estáticos para raspagem de sessões longas e proxies de datacenter para trabalho em volume de alta velocidade.
Mas, para a maioria das páginas protegidas, o Web Unlocker é a maneira mais rápida de passar de uma solicitação bloqueada para um HTML analisável.
Considerações finais
O PHP é uma linguagem muito capaz de fazer raspagem na Web e, a esta altura, você já deve ter uma base sólida sobre raspagem na Web com PHP.
Vou interromper este tutorial neste ponto, pois ele é uma introdução à coleta de dados da Web com PHP. Em tutoriais futuros, expandiremos nosso coletor de dados para que ele possa seguir links, lidar com paginação e coletar dados de alvos mais complexos.
Se, enquanto isso, você quiser saber mais sobre raspagem da Web, confira estes recursos:
Você está pronto para experimentar o Web Unlocker? Comece hoje mesmo com 5 raspagens gratuitas e raspe tudo sem dor de cabeça.






