

Java ідеально підходить для створення швидких, масштабованих конвеєрів скрапінгу завдяки своїй продуктивності, екосистемі та багатопоточності. Такі інструменти, як jsoup, добре працюють зі статичним HTML, але сучасні веб-сайти покладаються на системи захисту від ботів, CAPTCHA, проксі-сервери та рендеринг JavaScript, що робить автономний скрапінг на Java ненадійним. У 2026 році найкращим підходом буде використання Java як рівня управління (запити, парсинг, логіка) і покладання на API скрапінгу, наприклад, Floppydata, для надійної роботи з інфраструктурою, розблокування запитів і масштабування.
Чому веб-скрейпінг на Java – це найкращий вибір
Java є надійним вибором для веб-скрепінгу завдяки своїй швидкості, масштабованості та підтримці інфраструктури. Я пробував Python, Go і NodeJS для скрапінгу, але Java завжди виявлялася набагато кращою в обробці завдань скрапінгу на виробничому рівні. Python чудово підходить для синтаксичного аналізу та маніпулювання даними завдяки своїм широким бібліотекам для роботи з даними, але Java виділяється своїм статичним скрапінгом HTML.
Я віддаю перевагу Java для скрапінгу чи парсингу в промислових масштабах, тому що:
- Швидкість: Java швидша за інтерпретовані мови, такі як Python.
- Екосистема: Ви можете підключити професійні інструменти, такі як Apache HttpClient та бази даних.
- Багатопотоковість: Служба ExecutorService у Java спрощує багатопотокове скрейбування.
Для Java-бекендів, які хочуть розгорнути зрілу систему скрапінгу, бібліотека jsoup є чудовим варіантом. Ви можете витягувати HTML- та XML-вміст з веб-сторінок і вдосконалювати його за допомогою бібліотек маніпулювання даними Java, не потребуючи додаткових інструментів для аналізу даних.
Багато відомих інструментів для вилучення даних електронної комерції використовують jsoup для відстеження продуктів конкурентів і ключових слів, розгортаючи великомасштабні завдання автоматизації за допомогою Java і jsoup.
Основна інфраструктура Java для веб-скрепінгу
Java має розвинену екосистему і підтримує тисячі бібліотек та інтеграцій. Ключовими бібліотеками, які підтримують веб-скрепінг, є jsoup, Apache, Jackson, Gson та інші бібліотеки для маніпулювання даними. Java також підтримує запити до баз даних всередині коду через JDBC.
Jsoup: Бібліотека веб-скрепінгу для Java
Jsoup – це основа веб-скрепінгу за допомогою Java (для веб-сторінок HTML). Jsoup надає вам CSS-подібний синтаксис селектора, який допомагає витягувати всі види HTML-вмісту з витягнутого документа.
Jsoup швидкий, має простий синтаксис і самостійно обробляє непрацюючі посилання.
Приклад коду:
Document doc = Jsoup.parse(html);
String title = doc.select("title").text();
String price = doc.select(".price").text();Якщо ви хочете проаналізувати веб-сторінку, ви повинні спочатку отримати її. Java не може просто переглядати сторінку. Вам потрібен HTTP-сервер, щоб зробити запит на певну веб-сторінку, а потім веб-сервер відповість вам вмістом веб-сторінки. Це те, що ви передаєте jsoup, щоб почати витягувати дані.
Ви також можете використовувати власні HTTP-методи Java замість Apache HttpClient, але вони не такі масштабовані. Apache обробляє таймаути сеансу, повторні спроби, а також користувацькі агенти та файли cookie.
Джексон і Гсон
Jackson і Gson – це дві різні бібліотеки Java. Ці бібліотеки допомагають перетворити необроблений витягнутий текст на чисті та придатні для використання дані, такі як ціни на товари з назвами або ціни на товари в певних категоріях з веб-сайту електронної комерції. Jackson краще справляється з великими автоматизованими процесами вилучення, ніж Gson, який призначений для невеликих і легких завдань.
Які недоліки використання Java для веб-скрепінгу?
Тепер, коли ви трохи розумієте можливості скрапінгу в Java, давайте обговоримо, де вона може вас підвести. У 2026 році ви не зможете покладатися виключно на такі бібліотеки, як jsoup та Apache HttpClient для масштабованого скрапінгу.
Існує дві фундаментальні проблеми, з якими ви стикаєтесь при скрапінгу виключно на Java:
- Веб-сайти блокують вас: Веб-сайти стали більш захищеними. Їм не байдуже, чи відвідувач на їхньому сайті – реальна людина, чи просто бот, який створює непотрібне навантаження на сервер і без дозволу витягує дані клієнтів. Веб-сайти більше не люблять скребків.
- JS-важкі сторінки не можуть бути витягнуті: Jsoup та інші фреймворки для вилучення чудово працюють з HTML-сторінками. Це можуть бути сторінки товарів та інші сторінки електронної комерції/блогів, але багато веб-сайтів почали додавати фрагменти коду JavaScript, щоб додати на сайт анімацію та круті візуальні ефекти. Jsoup не створений для вилучення сторінок з великим вмістом JS, тому вилучення не вдасться або поверне нерелевантні результати.
Обидві ці проблеми можна вирішити. Веб-скрепери мають різні стратегії та фреймворки, які дозволяють уникнути блокування будь-якого веб-сайту та легко вичищати сторінки з високим вмістом JS. Однак процес не такий простий, як запуск декількох рядків коду jsoup та Apache.
Сучасний спосіб веб-скрепінгу на Java
Автономних бібліотек Java недостатньо для веб-скрепінгу в 2026 році. Ми більше не маємо справу зі статичними HTML-сторінками. Ми маємо справу з системами захисту від ботів, CAPTCHA, перенаправленнями, файлами cookie, дизайнерськими анімаціями та текстовими макетами на основі Java Script і багатьом іншим.
Щоб створити успішну і масштабовану автоматизацію скрапінгу, вам потрібно поєднати Java з іншими новітніми технологіями скрапінгу. Ось список ключових речей, які вам знадобляться разом з кодом на Java для успішної автоматизації веб-скрепінгу:
- Пул проксі-серверів: Веб-сайти відстежують кожного відвідувача за IP-адресою. Коли мережева стіна, така як Cloudflare, дізнається, що користувач збирає дані, перше, що вона робить, це блокує доступ до веб-сайту з цієї IP-адреси. Ось чому вам потрібен пул безпечних проксі-серверів і логіка Java для перемикання проксі-серверів кожні кілька запитів, щоб уникнути блокування.
- Розшифровувач CAPTCHA: CAPTCHA існують для того, щоб вигнати ботів з платформи. Традиційні скрепери не можуть розгадати CAPTCHA. Вбудувати розшифровувач CAPTCHA в Java або будь-яку іншу мову практично неможливо. Ось чому вам потрібен сторонній розшифровувач CAPTCHA.
- Профілі відбитків пальців на пристроях: Такі платформи, як Facebook і LinkedIn, використовують ще більш досконалі системи виявлення. Ці системи покладаються не лише на IP-адреси для виявлення потенційних сигналів скрепінгу, вони відстежують відбитки пальців пристрою, поведінку користувача, переходи через проксі-сервери та зв’язки між акаунтами. Ось чому вам потрібно змінити “відбиток пальця” браузера разом з проксі-серверами, щоб уникнути заборони вашого пристрою на платформі.
- Інструменти для вилучення важких JS-файлів: Навіть якщо ви обійдете всі системи виявлення, багато сучасних веб-сторінок розроблено з використанням важких фреймворків Javascript, таких як ReactJS і NextJS. Такі інструменти, як jsoup та інші традиційні скрепери, не можуть витягувати вміст з таких сторінок. Вам потрібен додатковий сторонній інструмент, який допоможе з перетворенням з JS в HTML.
Скрапінг на Java не помер. Він все ще дуже корисний, якщо ви додасте власну інфраструктуру, таку як проксі-сервери, розшифровувачі CAPTCHA і конвертери JS-сторінок. Або, найбільш ідеальний спосіб пропустити всі ці інтеграції – використовувати API веб-скреппера, наприклад, Floppydata.
Керівництво: Як робити веб-скрейпінг за допомогою Java у 2026 році
У 2026 році Java повинна використовуватися для підтримки інфраструктури скрапінгу шляхом виконання запитів, організації необроблених даних, розбору необроблених даних на структуровані і придатні для дій дані, а також для обробки інших граничних випадків і логіки, таких як ротація проксі, повторні спроби, друк повідомлень, попередження і багато іншого.
Якщо ви спробуєте зіскребти сучасні веб-сторінки за допомогою jsoup, ви можете зазнати невдачі у 40%-50% випадків. Однак, Java слід використовувати за її швидкість, інтеграції та багатопоточність, а не за бібліотеку jsoup.
Отже, якщо ви готові використовувати Java в якості керуючого шару для вашого скрепера, давайте зануримося в найпростіший і найефективніший метод веб-скрепінгу в 2026 році.
Крок 1: Отримайте API Web Scraper
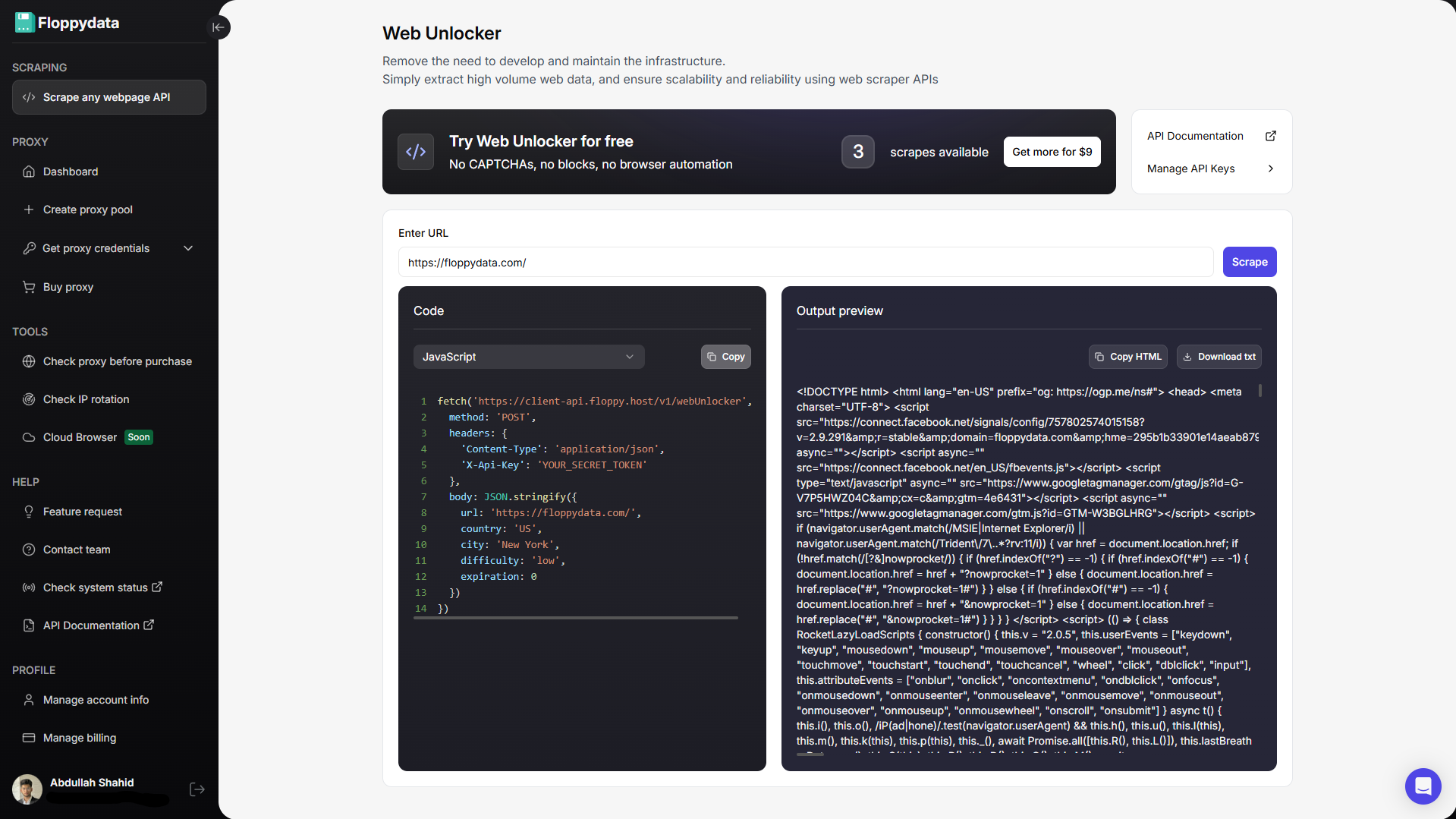
Замість того, щоб намагатися використовувати скрейпер Java, використовуйте надійний API веб-скрепера. API веб-скрепера отримує URL-адресу вашої веб-сторінки, надсилає запит до неї, обробляє CAPTCHA, перетворює веб-сторінку в необроблені дані і повертає її назад. API веб-скрепера виконує важку роботу з HTTP-сервером, повторними спробами, CAPTCHA, помилками, поганим корисним навантаженням, проксі-серверами, що змінюються, і відбитками пальців пристрою.
На Java ви пишете решту інфраструктури конвеєра, наприклад, створюєте багатопотокові черги посилань для дослідження, витягуєте корисні теги з HTML-контенту і зберігаєте їх у структурованому вигляді або виконуєте інші функції над витягнутими даними.
Ви можете прочитати наш огляд найкращих сервісів скрапінгу, щоб знайти найбільш підходящий для вашого випадку використання.
Крок 2: Додайте ключ API у фрагмент коду Java
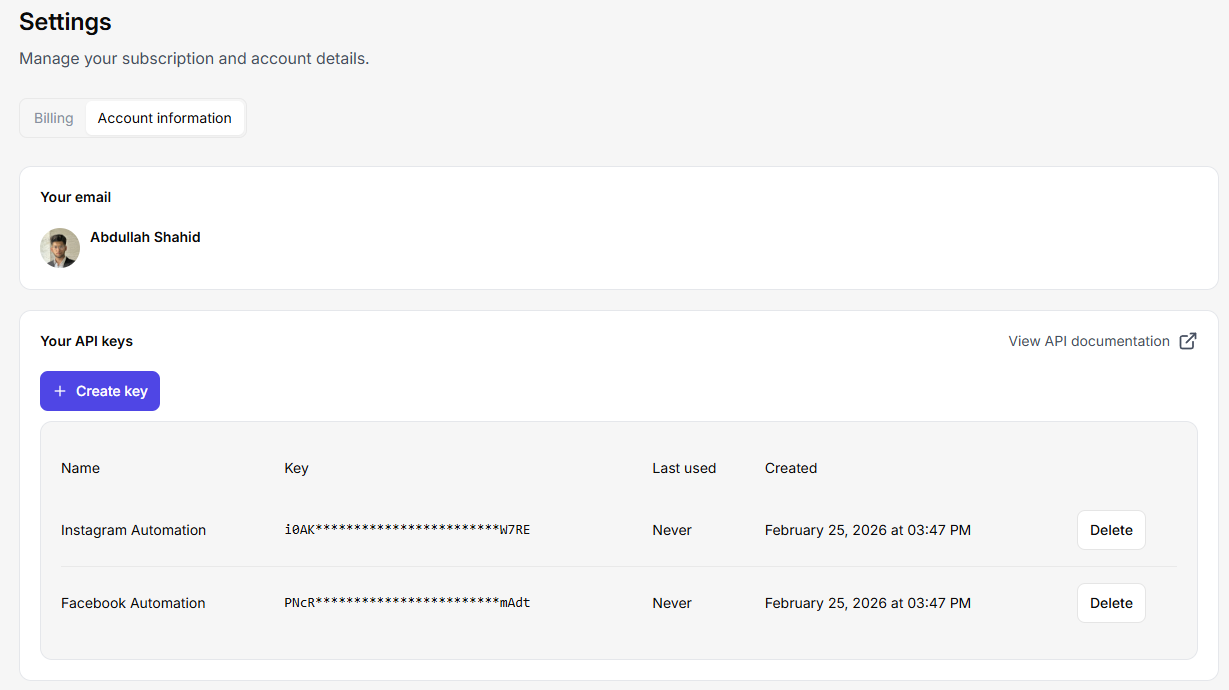
Візьміть ключ API з вашого сервісу веб-скреперів. Інтегруємо його в Java. Ви можете створити кілька ключів API у Floppydata, перейшовши до своїх налаштувань > акаунта > і натиснувши кнопку “створити ключ”. Ви можете надсилати сотні одночасних запитів за цим API і створити багатопотоковий скрейпер, який оброблятиме тисячі веб-сторінок одночасно.
Оскільки Floppydata виконує ваші завдання зі скрапінгу веб-сторінок у хмарі, ви також знімаєте все навантаження, пов’язане з відкриттям веб-браузера і запуском бібліотек скрапінгу з вашого пристрою. Якби вам довелося керувати всією інфраструктурою скрапінгу, вам би знадобилося багато оперативної пам’яті та обчислювальної потужності.
Клієнтський API Floppydata використовує заголовок X-Api-Key, а задокументована кінцева точка Web Unlocker приймає URL-адресу і додаткові параметри, такі як країна, місто, складність і термін дії кешу. Відповідь містить HTML-вміст, який ви можете проаналізувати в Java.
Ось приклад фрагмента коду, який я люблю використовувати:
public class Floppydatascraper {
public static void main(String[] args) throws Exception {
String apiKey = System.getenv("FLOPPY_API_KEY");
String payload = """
{
"url": "https://example.com",
"country": "US",
"difficulty": "medium",
"expiration": 0
}
""";
HttpClient client = HttpClient.newBuilder()
.connectTimeout(Duration.ofSeconds(20))
.build();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://client-api.floppy.host/v1/webUnlocker"))
.header("X-Api-Key", apiKey)
.header("Content-Type", "application/json")
.POST(HttpRequest.BodyPublishers.ofString(payload))
.build();
HttpResponse<String> response =
client.send(request, HttpResponse.BodyHandlers.ofString());
System.out.println(response.body());
}
}Крок 3: Вдосконалення конвеєра скрепінгу Java
Тепер, коли ви інтегрували ключ API, створіть конвеєр вилучення на його основі. Наприклад, якщо у вас є інструмент електронної комерції, який досліджує Amazon на предмет релевантних товарів за цільовим ключовим словом, витягніть їхню назву, теги, опис тощо і покажіть їх користувачеві. Scraper API – це найкращий і найбільш масштабований підхід. Навіть якщо у вас є тисячі клієнтів, які надсилають одночасні запити до вашого додатку, Floppydata API легко впорається з ними.
Ви можете додати більше функцій до вилучених даних, наприклад, використовувати ключ AI API, щоб написати схожий опис і заголовок, або проаналізувати схожі ключові слова з усіх вилучених результатів тощо. Вся ця інфраструктура повинна бути побудована на вашому боці на Java.
Безголовий перегляд в Java без Selenium або Puppeteer
Традиційно скрепери використовували Selenium та Puppeteer для запуску сеансів безголових браузерів, керування проксі-серверами та логікою скрепінгу. Однак цей процес важчий, повільніший і призводить до перерв у роботі під великим навантаженням, оскільки вам потрібна масштабована хмарна інфраструктура, щоб впоратися зі зростаючим попитом на запити. У підсумку ви витрачаєте час на створення інфраструктури, яку можна отримати за допомогою надзвичайно дешевих API для вилучення даних, таких як Floppydata. Більше того, ці інструменти скрепінгу перевірені на надійність і масштабованість і постійно розвиваються разом з ринком, тому вам не доведеться змінювати свій конвеєр скрепінгу кожні 4 місяці.
З Floppydata API вам потрібно:
- немає управління локальним браузером
- відсутність безголового парку браузерів
- без підтримки селену
- немає налаштування “Ляльковода
- просто логіка запиту на Java плюс HTML-парсинг
І все це за $0,45-$0,9/1 тис. успішно зішкрябаних результатів. Це дешевше, ніж утримувати власні хмарні машини. Дивіться детальний прайс.
Висновок
Якби сьогодні хтось попросив мене побудувати конвеєр вилучення веб-даних на Java, це зайняло б десь 20-30 хвилин. Я б отримав ключ API Floppydata і накидав би свої вимоги до конвеєра, включаючи те, що я хочу робити з вилученими даними, і як я хочу їх зберігати. Потім я використовую Claude Code для створення надійного конвеєра вилучення. Оскільки я не створюю жодної інфраструктури для вилучення, я можу швидко перевірити, запустивши цей скрипт, чи працює мій конвеєр чи ні.
Java – чудовий вибір для створення масштабованих багатопотокових систем веб-скрепінгу, навіть з урахуванням її обмежень. Але в 2026 році базові бібліотеки веб-скрепінгу не матимуть жодного шансу проти анти-ботів на основі штучного інтелекту, які платформи розгортають, щоб утримати скрепери подалі. Для успішної автоматизації скрапінгу вам знадобиться не менш сучасний і потужний інструмент для скрапінгу.






