

Введение
PHP был одним из моих первых языков как веб-разработчика в те времена, и мне до сих пор нравится использовать его для скрейпинга.
Это руководство охватывает то, что я реально использую в продакшене. Я проведу вас через полный рабочий процесс веб-скрейпинга на PHP с использованием Floppydata Web Unlocker в качестве слоя для скрейпинга.
Почему Floppydata?
Потому что он предоставляет API для скрейпинга, который устраняет необходимость управлять прокси, заголовками или логикой защиты от ботов. К концу этой статьи вы получите прочные знания о том, как выполнять веб-скрейпинг с помощью PHP.
Что такое веб-скрейпинг на PHP?
Веб-скрейпинг на PHP — это процесс использования PHP-кода для извлечения данных с веб-сайтов. Не каждый сайт предоставляет API, как, например, Twitter, поэтому во многих случаях единственный способ получить нужную информацию — это загрузить страницу и самостоятельно разобрать HTML.
PHP имеет большой смысл для этого, если вы уже используете его каждый день. Вы можете напрямую поместить извлеченные данные в существующий бэкенд, сохранить их в MySQL или запустить скрейпер по расписанию cron без необходимости вводить другой язык в стек.
Главная проблема не в том, может ли PHP выполнять скрейпинг. Безусловно, может. Настоящий вопрос заключается в том, насколько хорошо ваш скрейпер справляется с заблокированными запросами, географическими ограничениями и агрессивными CAPTCHA.
Именно поэтому я объединяю PHP с Floppydata Web Unlocker, чтобы помочь преодолеть этот разрыв.
PHP библиотеки для веб-скрейпинга, которые стоит знать (2026)
В PHP много библиотек для скрейпинга, но, честно говоря, я остановился только на нескольких, которые реально использую. Вот краткий обзор.
- Guzzle: Надежный HTTP-клиент, который чисто обрабатывает POST-запросы, JSON-данные, редиректы и заголовки. Мы будем использовать его на протяжении всего руководства для взаимодействия с API Web Unlocker.
- Symfony DomCrawler: Позволяет навигировать по HTML и XML с использованием CSS-селекторов или XPath. В паре с компонентом symfony/css-selector он дает вам фильтрацию в стиле jQuery, которая надежно работает с беспорядочным HTML. Он автономный, поэтому вам не нужен весь Symfony.
- Symfony HttpBrowser: Это современная замена устаревшей библиотеке Goutte. Она построена на основе BrowserKit и DomCrawler и позволяет имитировать клики, отправку форм и цепочки редиректов. Отлично подходит, когда ваша логика скрейпинга охватывает несколько страниц.
- DiDOM: DiDOM — это быстрый парсер без зависимостей с API в стиле jQuery. Идеально подходит для небольших скриптов, где вы хотите избежать использования компонентов Symfony.
- Symfony Panther: Управляет реальным браузером Chrome или Chromium через WebDriver. Вы обращаетесь к этому, когда сайт отображает все в JavaScript (React, Vue, тяжелые SPA), и обычный HTTP-запрос возвращает пустую оболочку. Он тяжелее, поэтому я использую его только тогда, когда ничто другое не работает.
Goutte раньше был распространенной рекомендацией, но теперь он устарел, поэтому я бы не рекомендовал строить новый проект вокруг него.
Для этого руководства достаточно Guzzle плюс Symfony DomCrawler. Поскольку Web Unlocker уже выполняет JavaScript и возвращает финальный отрендеренный HTML, нам не нужно запускать headless-браузер на нашей стороне.
Предварительные требования
Перед тем как писать какой-либо код, убедитесь, что у вас есть следующие четыре вещи. Если вы никогда не настраивали PHP-проект с нуля, не волнуйтесь, я проведу вас через каждый шаг.
1. PHP 8.2 или новее
PHP предустановлен во многих системах Mac и Linux, но никогда не помешает проверить. Откройте терминал и проверьте версию PHP:
php -vЕсли PHP уже установлен, вы должны увидеть номер версии. Для этого руководства используйте PHP 8.2 или новее. Это самая безопасная отправная точка с версиями зависимостей, которые мы собираемся установить.
Если PHP отсутствует, следуйте инструкциям для его установки:
# Windows (Chocolatey, запустите PowerShell от имени администратора)
choco install php
# macOS (Homebrew)
brew install phpПосле установки снова запустите php -v, чтобы подтвердить версию. В Homebrew вам не нужны отдельные пакеты php-curl или php-xml для этого руководства. Эти расширения уже включены в основную установку PHP.
2. Composer
Composer — это стандартный менеджер пакетов для PHP. По сути, это эквивалент npm или pip для PHP-проектов. Мы будем использовать его для установки Guzzle и пакетов парсера Symfony.
Сначала проверьте, доступен ли он уже:
composer --versionЕсли Composer еще не установлен, используйте:
# Windows (Chocolatey, от имени администратора)
choco install composer
# macOS (Homebrew)
brew install composerКак только это будет сделано, composer --version должен вывести номер версии, и вы готовы создать проект.
3. Аккаунт Floppydata
Создайте аккаунт Floppydata и скопируйте ваш API-ключ из панели управления. Каждый новый аккаунт получает 5 бесплатных скрейпов для Web Unlocker.
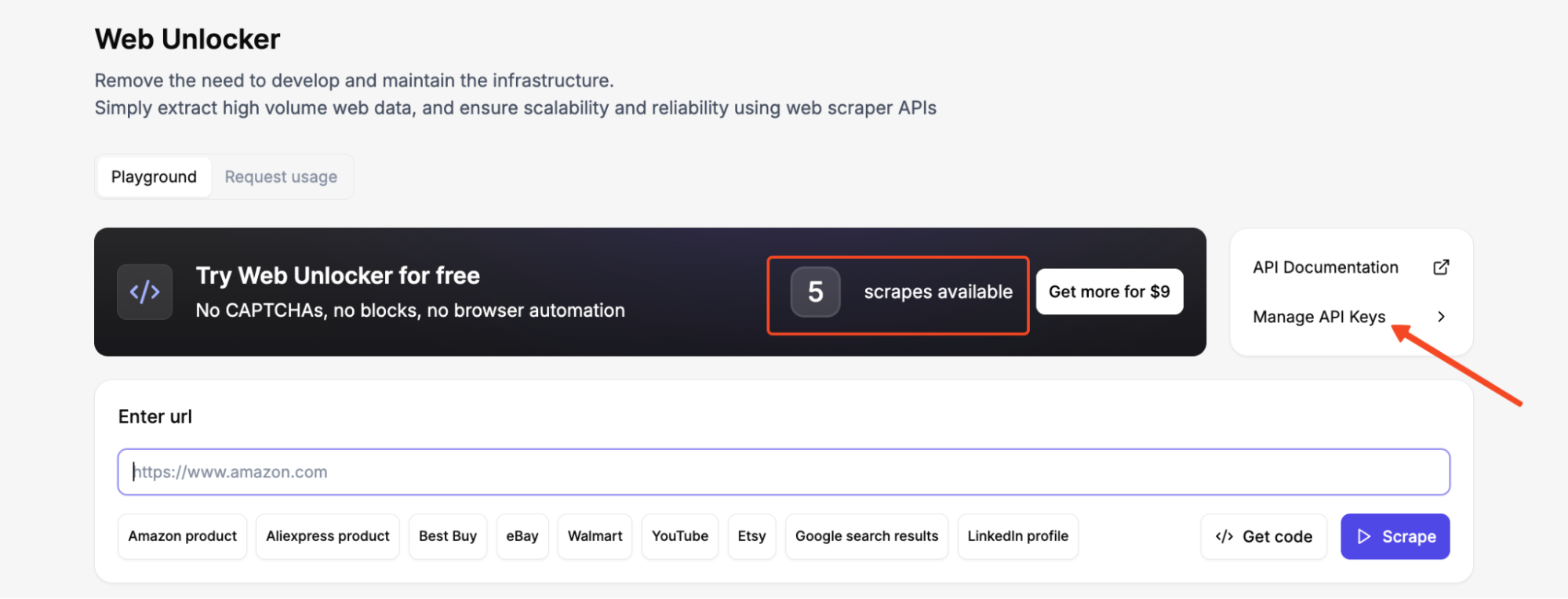
После входа в панель управления перейдите в Manage API Keys в Web Unlocker и сгенерируйте API-ключ. Немедленно скопируйте его и сохраните в безопасном месте.
Вы будете использовать этот ключ в заголовке X-Api-Key каждого запроса Web Unlocker. Мы добавим его в наш код через несколько минут.
4. Директория проекта и зависимости
Теперь давайте создадим папку, где будет жить наш скрейпер, и установим необходимые PHP-библиотеки. В вашем терминале:
mkdir php-scrape-countries
cd php-scrape-countriesИнициализируйте новый Composer-проект:
composer init --name="myname/country-scraper" --require="php:^8.2" --no-interactionТеперь установите необходимые пакеты:
composer require guzzlehttp/guzzle symfony/dom-crawler:^7.4 symfony/css-selector:^7.4Composer загрузит все три библиотеки вместе с их зависимостями в папку vendor/ и создаст файл composer.json, который отслеживает точные версии, которые вы используете.
Отныне каждый PHP-файл в проекте может загружать зависимости с помощью:
require_once __DIR__ . '/vendor/autoload.php';На этом этапе настройка завершена, и мы можем перейти к самому скрейперу.
Как извлекать данные с помощью PHP, используя Floppydata Web Unlocker
Шаг №1: Протестируйте вашу цель
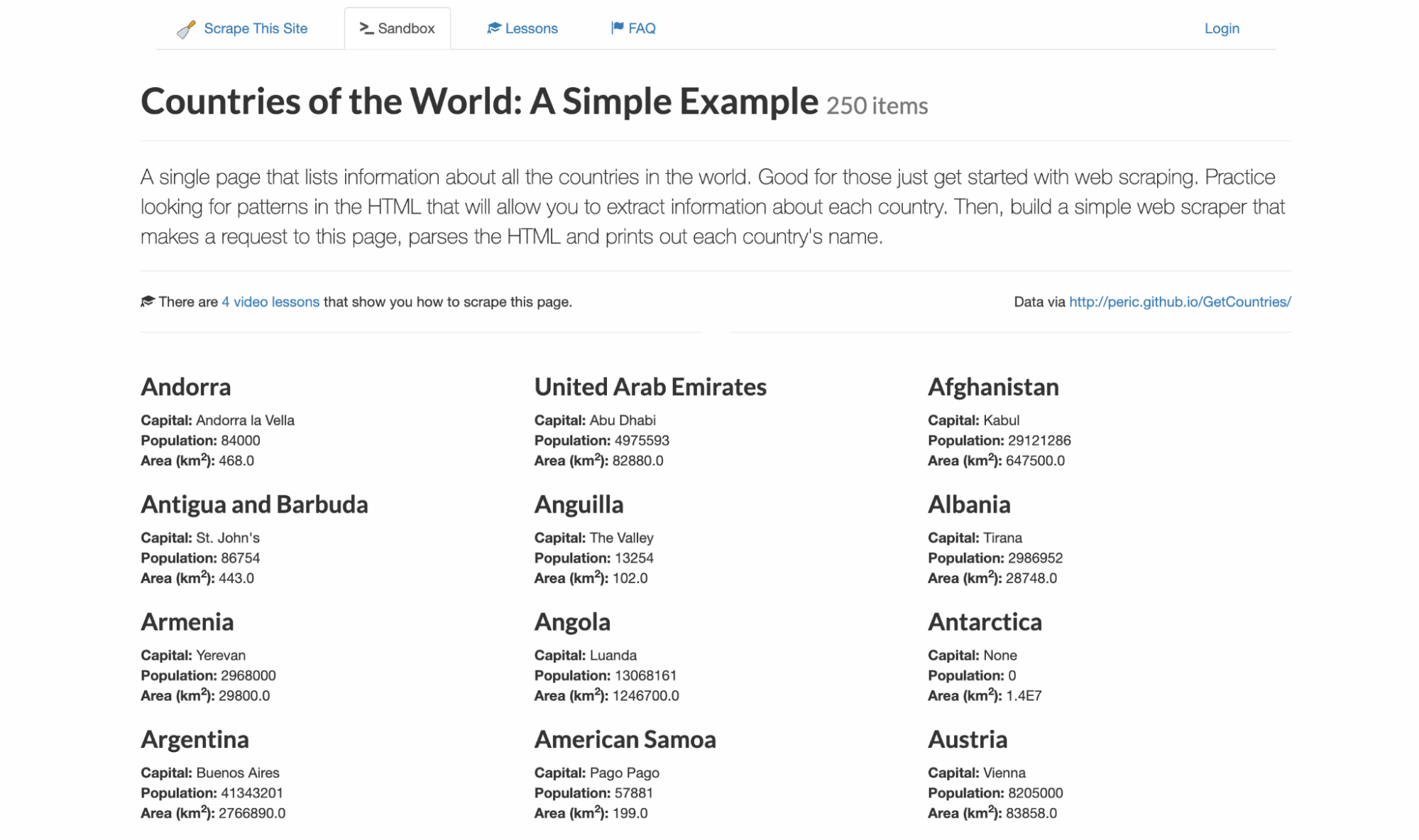
Я никогда не люблю писать код вслепую, чтобы знать, какие селекторы и структуру данных ожидать. Для этого примера я буду нацеливаться на scrapethissite, демо-сайт для скрейпинга данных. Он содержит список всех 250 стран с их столицами, населением и площадью.
Чтобы следовать инструкциям, посетите Floppydata Web Unlocker Playground. Этот инструмент без кода доступен прямо из вашей панели управления и позволяет увидеть точный HTML, который вернет API, без настройки проекта.
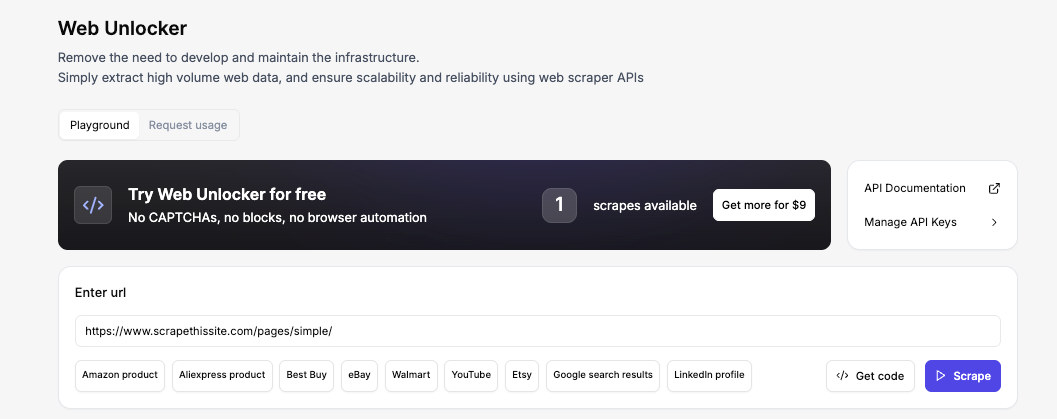
Теперь введите URL и нажмите Scrape. В течение нескольких секунд вы увидите полный HTML в предварительном просмотре вывода. Это точно тот же HTML, который получит ваш PHP-скрипт через несколько шагов.
Если данные выглядят правильно, вы можете скопировать HTML или загрузить ответ. Но в нашем случае мы позволим PHP-скрипту сделать это автоматически.
Шаг №2: Отправка вашего первого запроса Web Unlocker с Guzzle
Ядро всего рабочего процесса — это POST-запрос к конечной точке Floppydata:
https://client-api.floppy.host/v1/webUnlockerДля этого мы сначала создаем клиент Guzzle и готовим конфигурацию запроса. Затем отправляем запрос и обрабатываем ответ.
Создайте файл с именем scrape.php и начните с базового каркаса:
<?php
// scrape.php
require_once __DIR__ . '/vendor/autoload.php';
use GuzzleHttp\Client;
$apiKey = 'YOUR_API_KEY'; // Замените на ваш реальный ключ
$targetUrl = 'https://www.scrapethissite.com/pages/simple/';
$client = new Client([
'base_uri' => 'https://client-api.floppy.host',
'timeout' => 60,
]);Замените YOUR_API_KEY на ваш реальный ключ. Теперь создадим фактический POST-вызов. Мы отправляем JSON на конечную точку API, включаем API-ключ в заголовки и передаем целевой URL плюс несколько аргументов в теле:
$response = $client->post('/v1/webUnlocker', [
'headers' => [
'Content-Type' => 'application/json',
'X-Api-Key' => $apiKey,
],
'json' => [
'url' => $targetUrl,
'country' => 'US',
'city' => 'New York',
'difficulty' => 'low',
'expiration' => 0,
],
]);
$payload = json_decode((string) $response->getBody(), true);
$html = $payload['html'] ?? '';
echo "HTML получен! Длина: " . strlen($html) . " символов\n";Поля country и city сообщают Web Unlocker, через какое географическое местоположение маршрутизировать запрос. Поле difficulty контролирует, насколько агрессивно unlocker обрабатывает защиту от ботов. Я использую low здесь, потому что наша песочница не имеет никакой защиты.
Для защищенных целей за Cloudflare или DataDome установите значение medium, чтобы unlocker применял более сильную логику снятия отпечатков и решения CAPTCHA.
Теперь обратите внимание, что Web Unlocker возвращает необработанный HTML внутри JSON-объекта, что означает, что вам нужно декодировать JSON и извлечь фактическую разметку страницы из поля html.
Если вы забудете это и будете обрабатывать все тело ответа как HTML, ваш парсер сломается. На этом сторона запроса завершена, и мы можем перейти к парсингу.
Шаг №3: Изучение структуры страницы
После успешного выполнения запроса следующая задача — изучить структуру страницы и нацелиться на повторяющиеся элементы, которые содержат нужные нам данные. Каждая страна на странице следует этой точной HTML-модели:
<div class="col-md-4 country">
<h3 class="country-name">
<i class="flag-icon flag-icon-ad"></i>
Andorra
</h3>
<div class="country-info">
<strong>Capital:</strong> <span class="country-capital">Andorra la Vella</span><br>
<strong>Population:</strong> <span class="country-population">84000</span><br>
<strong>Area (km<sup>2</sup>):</strong> <span class="country-area">468.0</span><br>
</div>
</div>Эта повторяющаяся структура делает эту страницу прекрасно предсказуемой. Каждая карточка страны использует одни и те же имена классов: .country для обертки, .country-name для заголовка и .country-capital, .country-population и .country-area для полей данных внутри .country-info.
Шаг №4: Парсинг данных с помощью Symfony DomCrawler
Поскольку классы согласованы для всех 250 записей, мы можем перебрать каждый элемент .country и извлечь значения из дочерних селекторов. Но сначала давайте добавим небольшую вспомогательную функцию, которая поможет нам очистить извлекаемый текст:
use Symfony\Component\DomCrawler\Crawler;
function normalizeText(string $text): string
{
return preg_replace('/\s+/', ' ', trim($text)) ?? trim($text);
}Если вы посмотрите на необработанный HTML, названия стран имеют дополнительные пробелы и переносы строк вокруг них из-за тегов иконки флага <i>, находящихся внутри <h3>.
Функция normalizeText() помогает удалить начальные и конечные пробелы, затем использует регулярное выражение, чтобы свернуть любые оставшиеся последовательности пробелов или переносов строк, чтобы такие имена, как Andorra или St. John’s, возвращались чистыми, а не несли лишние пробелы из HTML.
Когда помощник готов, мы создаем экземпляр Crawler и перебираем каждую карточку страны:
$crawler = new Crawler($html);
$countries = [];
$crawler->filter('.country')->each(function (Crawler $node) use (&$countries): void {
$countries[] = [
'name' => normalizeText($node->filter('.country-name')->text()),
'capital' => normalizeText($node->filter('.country-capital')->text()),
'population' => normalizeText($node->filter('.country-population')->text()),
'area' => normalizeText($node->filter('.country-area')->text()),
];
});
echo 'Обработано ' . count($countries) . " стран\n";DomCrawler дает нам чистый способ перемещения по HTML с использованием CSS-селекторов. Мы начинаем с обертывания HTML в объект Crawler, затем фильтруем до каждого блока .country на странице. Внутри каждого блока мы захватываем название, столицу, население и площадь.
На этом этапе, если вы запустите скрипт, вы должны увидеть «Обработано 250 стран», выведенное в терминал.
Шаг №5: Экспорт результатов в CSV и JSON
Как только парсер дает вам массив $countries, экспорт данных становится очень простым.
$csvHandle = fopen('countries.csv', 'w');
fputcsv($csvHandle, ['Country', 'Capital', 'Population', 'Area (km2)'], ',', '"', '');
foreach ($countries as $country) {
fputcsv($csvHandle, [
$country['name'],
$country['capital'],
$country['population'],
$country['area'],
], ',', '"', '');
}
fclose($csvHandle);
file_put_contents('countries.json', json_encode($countries, JSON_PRETTY_PRINT | JSON_UNESCAPED_SLASHES));Экспорт в CSV полезен, потому что он дает читателям файл, который они могут немедленно открыть в Excel, Google Sheets или любом другом инструменте для работы с электронными таблицами. Экспорт в JSON так же удобен, если они хотят передать извлеченные данные в другой PHP-скрипт или API позже.
Одно небольшое обновление здесь — явный аргумент escape в fputcsv(). В более новых версиях PHP это позволяет избежать предупреждений об устаревании и сохраняет пример чистым, когда читатели запускают его из терминала.
Шаг №6: Соберите все вместе в один скрипт
Теперь, когда каждая часть работает сама по себе, вот полный скрипт:
<?php
declare(strict_types=1);
require_once __DIR__ . '/vendor/autoload.php';
use GuzzleHttp\Client;
use Symfony\Component\DomCrawler\Crawler;
function normalizeText(string $text): string
{
return preg_replace('/\s+/', ' ', trim($text)) ?? trim($text);
}
$apiKey = 'YOUR_API_KEY';
$targetUrl = 'https://www.scrapethissite.com/pages/simple/';
if ($apiKey === 'YOUR_API_KEY') {
fwrite(STDERR, "Замените YOUR_API_KEY перед запуском скрипта.\n");
exit(1);
}
$client = new Client([
'base_uri' => 'https://client-api.floppy.host',
'timeout' => 60,
]);
try {
$response = $client->post('/v1/webUnlocker', [
'headers' => [
'Content-Type' => 'application/json',
'X-Api-Key' => $apiKey,
],
'json' => [
'url' => $targetUrl,
'country' => 'US',
'city' => 'New York',
'difficulty' => 'low',
'expiration' => 0,
],
]);
} catch (Throwable $e) {
fwrite(STDERR, "Запрос не выполнен: {$e->getMessage()}\n");
exit(1);
}
$payload = json_decode((string) $response->getBody(), true);
if (!is_array($payload) || !isset($payload['html']) || !is_string($payload['html'])) {
fwrite(STDERR, "Неожиданный ответ API. Ожидается JSON с полем html.\n");
exit(1);
}
$crawler = new Crawler($payload['html']);
$countries = [];
$crawler->filter('.country')->each(function (Crawler $node) use (&$countries): void {
$countries[] = [
'name' => normalizeText($node->filter('.country-name')->text()),
'capital' => normalizeText($node->filter('.country-capital')->text()),
'population' => normalizeText($node->filter('.country-population')->text()),
'area' => normalizeText($node->filter('.country-area')->text()),
];
});
if ($countries === []) {
fwrite(STDERR, "Страны не были обработаны.\n");
exit(1);
}
$csvHandle = fopen(__DIR__ . '/countries.csv', 'w');
if ($csvHandle === false) {
fwrite(STDERR, "Не удалось создать countries.csv.\n");
exit(1);
}
fputcsv($csvHandle, ['Country', 'Capital', 'Population', 'Area (km2)'], ',', '"', '');
foreach ($countries as $country) {
fputcsv($csvHandle, [
$country['name'],
$country['capital'],
$country['population'],
$country['area'],
], ',', '"', '');
}
fclose($csvHandle);
file_put_contents(__DIR__ . '/countries.json', json_encode($countries, JSON_PRETTY_PRINT | JSON_UNESCAPED_SLASHES));
echo 'Готово! Обработано ' . count($countries) . " стран.\n";
echo "Сохранено countries.csv и countries.json\n";Замените ‘YOUR_API_KEY’ и запустите так:
php scrape.phpКогда все настроено правильно, скрипт загрузит страницу через Web Unlocker, обработает все 250 стран и запишет как countries.csv, так и countries.json в папку вашего проекта.
Просмотр результатов
После завершения работы скрипта вы можете сразу открыть countries.csv. Первые несколько строк будут выглядеть так:
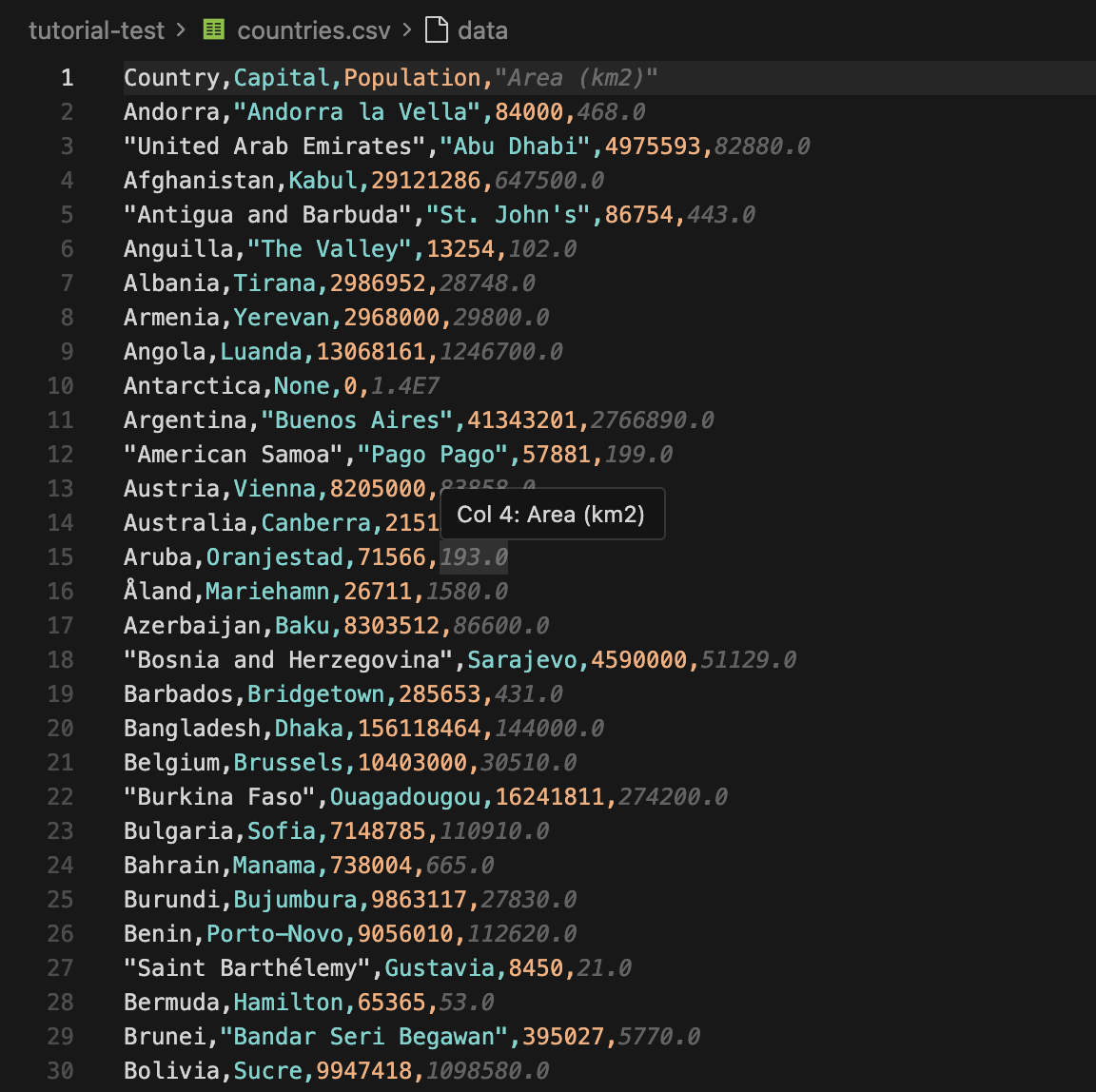
Теперь вы можете импортировать CSV в электронную таблицу или отправить JSON в другое приложение. Если вы хотите использовать этот рабочий процесс для отслеживания цен, вы можете объединить его с прокси для мониторинга цен Floppydata, так что обязательно ознакомьтесь с этим.
Работа с мерами защиты от скрейпинга
Простую статичную страницу несложно разобрать, как мы только что видели. Но защищенные сайты могут стать головной болью.
Вы можете столкнуться с блокировками, отсутствующими данными, CAPTCHA, рендерингом JavaScript или ограничениями скорости. Вот где обычный PHP-скрейпер начинает испытывать трудности.
Вот распространенные проблемы, с которыми вы можете столкнуться:
- Блокировка IP: Веб-сайты могут заблокировать ваш IP-адрес, если обнаружат несколько запросов с одного и того же IP за короткий период.
- CAPTCHA: Системы CAPTCHA используются для различения ботов и людей, представляя задачи, которые сложно решить ботам.
- Ограничение скорости: Веб-сайты часто ограничивают количество запросов, которые вы можете сделать в определенный период времени, чтобы предотвратить чрезмерный скрейпинг.
- Обнаружение User-Agent: User-agent’ы не из браузера блокируются, потому что они не выглядят как реальные посетители.
- JavaScript-задачи: Контент загружается только после выполнения JavaScript, что обычный HTTP-запрос может пропустить.
Вы можете попытаться решить эти проблемы вручную, но это ни удобно, ни масштабируемо.
Вот где появляется Floppydata Web Unlocker. Вместо того чтобы решать каждую задачу самостоятельно, вы можете переложить весь слой защиты от ботов и сосредоточиться на извлечении и хранении данных.
Floppydata Web Unlocker обрабатывает:
- Ротацию IP с большим пулом резидентных и датацентровых прокси
- Снятие отпечатков браузера и headless-браузеры
- Рендеринг JavaScript для динамических страниц
- Автоматические повторы и решение CAPTCHA
- Геотаргетинг вплоть до уровня города
Если вам нужен больший контроль, Floppydata также предлагает статичные резидентные прокси для скрейпинга с длинными сессиями и датацентровые прокси для высокоскоростной объемной работы.
Но для большинства защищенных страниц Web Unlocker — это самый быстрый способ перейти от заблокированного запроса к парсируемому HTML.
Заключительные мысли
PHP — очень способный язык для веб-скрейпинга, и к настоящему времени у вас должна быть прочная основа для веб-скрейпинга с помощью PHP.
Я остановлю это руководство на этом этапе, поскольку это введение в веб-скрейпинг с PHP. В будущих руководствах мы расширим наш скрейпер, чтобы он мог переходить по ссылкам, обрабатывать пагинацию и скрейпить более сложные цели.
Если вы хотите узнать больше о веб-скрейпинге, ознакомьтесь с этими ресурсами:
Готовы попробовать Web Unlocker? Начните сегодня с 5 бесплатными скрейпами и скрейпьте что угодно без головной боли.






