

Java est idéal pour construire des pipelines de scraping rapides et évolutifs grâce à ses performances, son écosystème et son multithreading. Des outils comme jsoup fonctionnent bien pour le HTML statique, mais les sites web modernes s’appuient sur des systèmes anti-bots, des CAPTCHA, des proxies et un rendu JavaScript – ce qui rend le scraping Java autonome peu fiable. En 2026, la meilleure approche consiste à utiliser Java comme couche de contrôle (requêtes, analyse, logique) et à s’appuyer sur une API de scraping comme Floppydata pour gérer l’infrastructure, débloquer les requêtes et s’adapter de manière fiable.
Pourquoi le Web Scraping en Java est un choix puissant
Java est un choix solide pour le scraping web en raison de sa vitesse, de son évolutivité et de son infrastructure de support. J’ai essayé Python, Go et NodeJS pour le scraping, mais Java s’est toujours avéré bien meilleur pour gérer les travaux de scraping au niveau de la production. Python est parfait pour l’analyse et la manipulation de données grâce à ses bibliothèques de traitement de données étendues, mais Java se distingue par son scraping HTML statique.
Je préfère Java pour les travaux de scraping à l’échelle de la production pour les raisons suivantes :
- La vitesse : Java est plus rapide que les langages interprétés comme Python.
- Ecosystème : Vous pouvez connecter des outils professionnels comme Apache HttpClient et des bases de données.
- Multi-threading : L’ExecutorService de Java simplifie le scraping multithreading.
Pour les backends Java qui souhaitent déployer un système de scraping mature, la bibliothèque jsoup de Java est une excellente option. Vous pouvez extraire le contenu HTML et XML des pages web et l’affiner à l’aide des bibliothèques de manipulation de données de Java sans avoir besoin d’outils supplémentaires pour l’analyse des données.
De nombreux outils de scraping de données de commerce électronique utilisent jsoup pour suivre les produits et les mots-clés des concurrents en déployant des tâches d’automatisation à grande échelle via Java et jsoup.
Infrastructure Java essentielle pour l’exploration du Web
Java dispose d’un écosystème mature et prend en charge des milliers de bibliothèques et d’intégrations. Les principales bibliothèques qui prennent en charge le web scraping sont jsoup, Apache, Jackson, Gson et d’autres bibliothèques de manipulation de données. Java prend également en charge les requêtes de base de données dans le code via JDBC.
Jsoup : La bibliothèque Java de récupération de données sur le Web
Jsoup est l’épine dorsale du web scraping avec Java (pour les pages web HTML). Jsoup vous fournit une syntaxe de sélecteur de type CSS qui vous aide à extraire toutes sortes de contenu HTML du document extrait.
Jsoup est rapide, sa syntaxe est simple et il gère lui-même les liens brisés.
Exemple de code :
Document doc = Jsoup.parse(html);
String title = doc.select("title").text();
String price = doc.select(".price").text();Si vous voulez analyser une page web, vous devez d’abord la récupérer. Java ne peut pas se contenter de parcourir une page. Vous avez besoin d’un serveur HTTP pour demander une page web spécifique, puis le serveur web répond avec le contenu de la page web. C’est ce que vous transmettez à jsoup pour commencer à extraire des données.
Vous pouvez également utiliser les méthodes HTTP propres à Java au lieu du HttpClient d’Apache, mais ce n’est pas aussi évolutif. Apache gère les délais de session, les tentatives, les agents utilisateurs et les cookies.
Jackson and Gson
Jackson et Gson sont deux bibliothèques Java distinctes. Ces bibliothèques vous aident à convertir le texte brut extrait en données propres et exploitables, telles que les prix des produits avec leurs titres, ou les prix des produits dans certaines catégories, à partir d’un site web de commerce électronique. Jackson gère mieux les automatismes de scraping de grande envergure que Gson, qui est conçu pour les tâches légères et de petite envergure.
Quels sont les inconvénients de l’utilisation de Java pour le Web Scraping ?
Maintenant que vous en savez un peu plus sur les capacités de Java en matière de scraping, examinons les points sur lesquels il vous laissera tomber. En 2026, vous ne pourrez pas compter uniquement sur des bibliothèques telles que jsoup et Apache HttpClient pour des travaux de scraping évolutifs.
Il y a deux problèmes fondamentaux auxquels vous êtes confronté lorsque vous faites du scraping uniquement avec Java :
- Les sites web vous bloquent : Les sites web sont désormais plus sur la défensive. Ils se soucient de savoir si le visiteur de leur site est un véritable être humain ou un robot qui alourdit inutilement le serveur et extrait des données sur les clients sans autorisation. Les sites web n’aiment plus les « scrapers ».
- Les pages lourdes en JS ne peuvent pas être extraites : Jsoup et d’autres frameworks d’extraction fonctionnent très bien pour les pages HTML. Il peut s’agir de pages de produits et d’autres pages web de commerce électronique ou de blog, mais de nombreux sites web ont commencé à ajouter des extraits de code JavaScript pour ajouter des animations et des visuels sympas au site web. Jsoup n’est pas conçu pour extraire des pages contenant beaucoup de JavaScript, de sorte que l’extraction échoue ou renvoie des résultats non pertinents.
Ces deux problèmes peuvent être résolus. Les scrappeurs web disposent de différentes stratégies et structures pour éviter d’être bloqués par un site web et pour récupérer facilement les pages à forte teneur en langage JS. Cependant, le processus n’est pas aussi simple que l’exécution de quelques lignes de code jsoup et Apache.
La méthode moderne pour le Web Scraping en Java
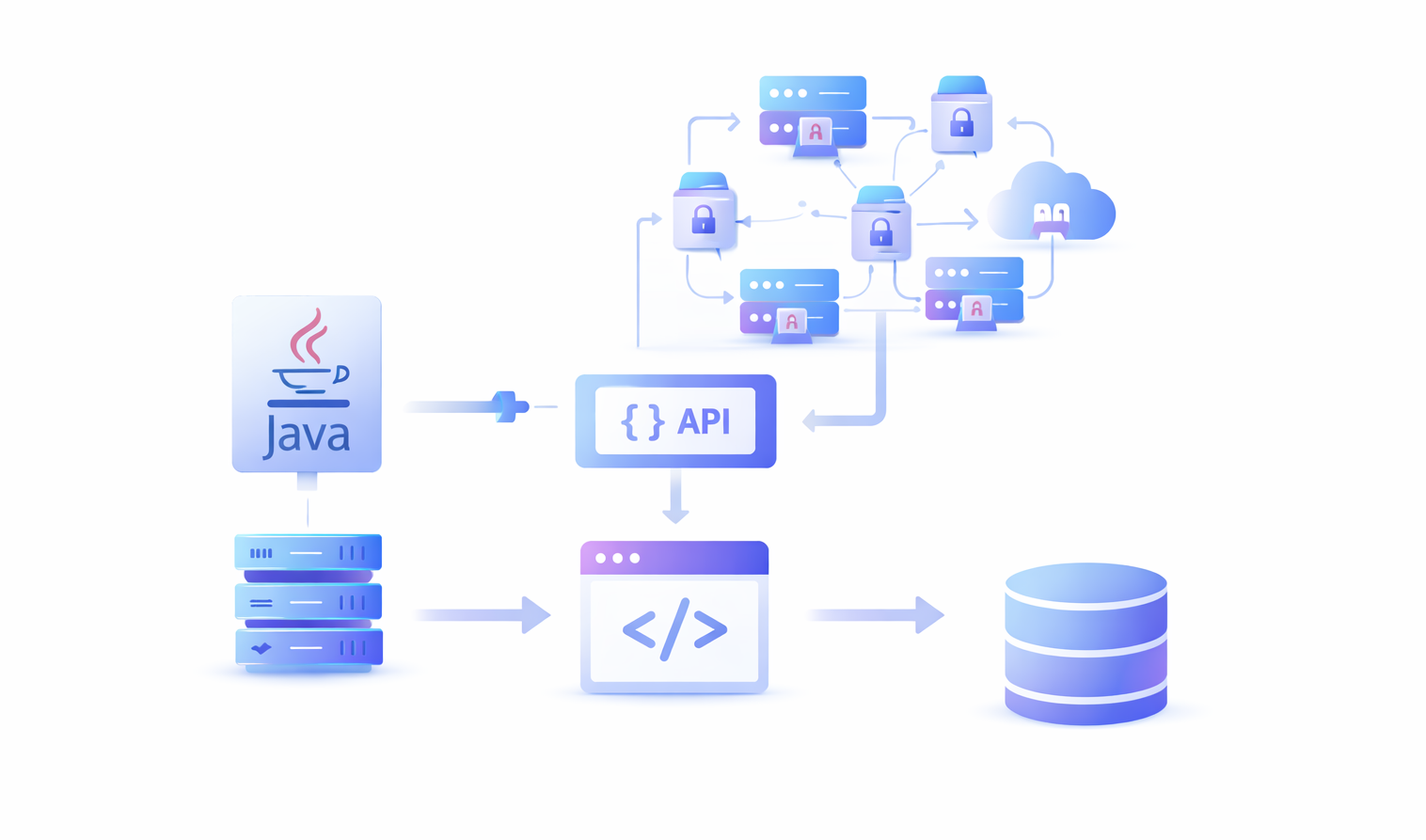
Les bibliothèques Java autonomes ne suffiront pas pour le web scraping en 2026. Nous n’avons plus affaire à des pages HTML statiques. Nous avons affaire à des systèmes anti-bots, à des CAPTCHA, à des redirections, à des cookies, à des animations de conception et à des mises en page de texte activées par Java Script, et à bien d’autres choses encore.
Pour créer une automatisation de scraping réussie et évolutive, vous devez combiner Java avec d’autres technologies de scraping récentes. Voici une liste des éléments clés dont vous avez besoin en plus du code Java pour mettre en œuvre une automatisation de scraping web réussie :
- Un pool de serveurs mandataires : Les sites web suivent chaque visiteur par son adresse IP. Lorsqu’un mur de réseau comme Cloudflare découvre qu’un utilisateur récupère des données, la première chose qu’il fait est de bloquer l’adresse IP pour qu’elle n’accède pas au site web. C’est pourquoi vous avez besoin d’un pool de proxies sûrs et d’une logique Java pour changer de proxies toutes les quelques requêtes afin d’éviter d’être banni.
- Résolveur de CAPTCHA : Les CAPTCHA existent pour chasser les robots de la plateforme. Les robots traditionnels ne peuvent pas résoudre les CAPTCHA. Il est pratiquement impossible de coder en dur un résolveur de CAPTCHA en Java ou dans tout autre langage. C’est pourquoi vous avez besoin d’un résolveur de CAPTCHA tiers.
- Profils d’empreintes digitales des appareils : Des plateformes comme Facebook et LinkedIn déploient des systèmes de détection encore plus avancés. Ces systèmes ne s’appuient pas uniquement sur les adresses IP pour détecter d’éventuels signaux de piratage, ils suivent l’empreinte digitale de l’appareil, le comportement de l’utilisateur, les sauts de proxy et les liens de compte. C’est pourquoi vous devez changer l’empreinte digitale de votre navigateur en même temps que vos proxys pour éviter que votre appareil ne soit banni de la plateforme.
- Outils pour les extractions JS lourdes : Même si vous contournez tous les systèmes de détection, de nombreuses pages web modernes sont développées à l’aide de cadres Javascript lourds tels que ReactJS et NextJS. Des outils comme jsoup et d’autres scrapers traditionnels ne peuvent pas extraire le contenu de ces pages. Vous avez besoin d’un outil supplémentaire de cette partie pour aider à la conversion de JS en HTML.
Le scraping en Java n’est pas mort. Il est toujours très utile si vous ajoutez votre propre infrastructure comme les proxies, les résolveurs CAPTCHA et les convertisseurs de pages JS. Ou, la façon la plus idéale d’éviter toutes ces intégrations est d’utiliser une API de scraper web comme Floppydata.
Guide : Comment faire du Web Scraping avec Java en 2026
En 2026, Java devrait être utilisé pour soutenir l’infrastructure de scraping en répondant aux demandes, en organisant les données brutes, en analysant les données brutes en données structurées et exploitables, et en gérant d’autres cas marginaux et logiques tels que la rotation du proxy, les tentatives, les messages d’impression, les avertissements, etc.
Si vous essayez de récupérer des pages web modernes avec jsoup, vous risquez d’échouer dans 40 à 50 % des cas. Cependant, Java devrait être utilisé pour sa vitesse, ses intégrations et son multithreading, et non pour la bibliothèque jsoup.
Une fois que vous êtes prêt à utiliser Java comme couche de contrôle pour votre scraper, plongeons dans la méthode de scraping web la plus simple et la plus efficace en 2026.
Étape 1 : Obtenir une API de scraper Web
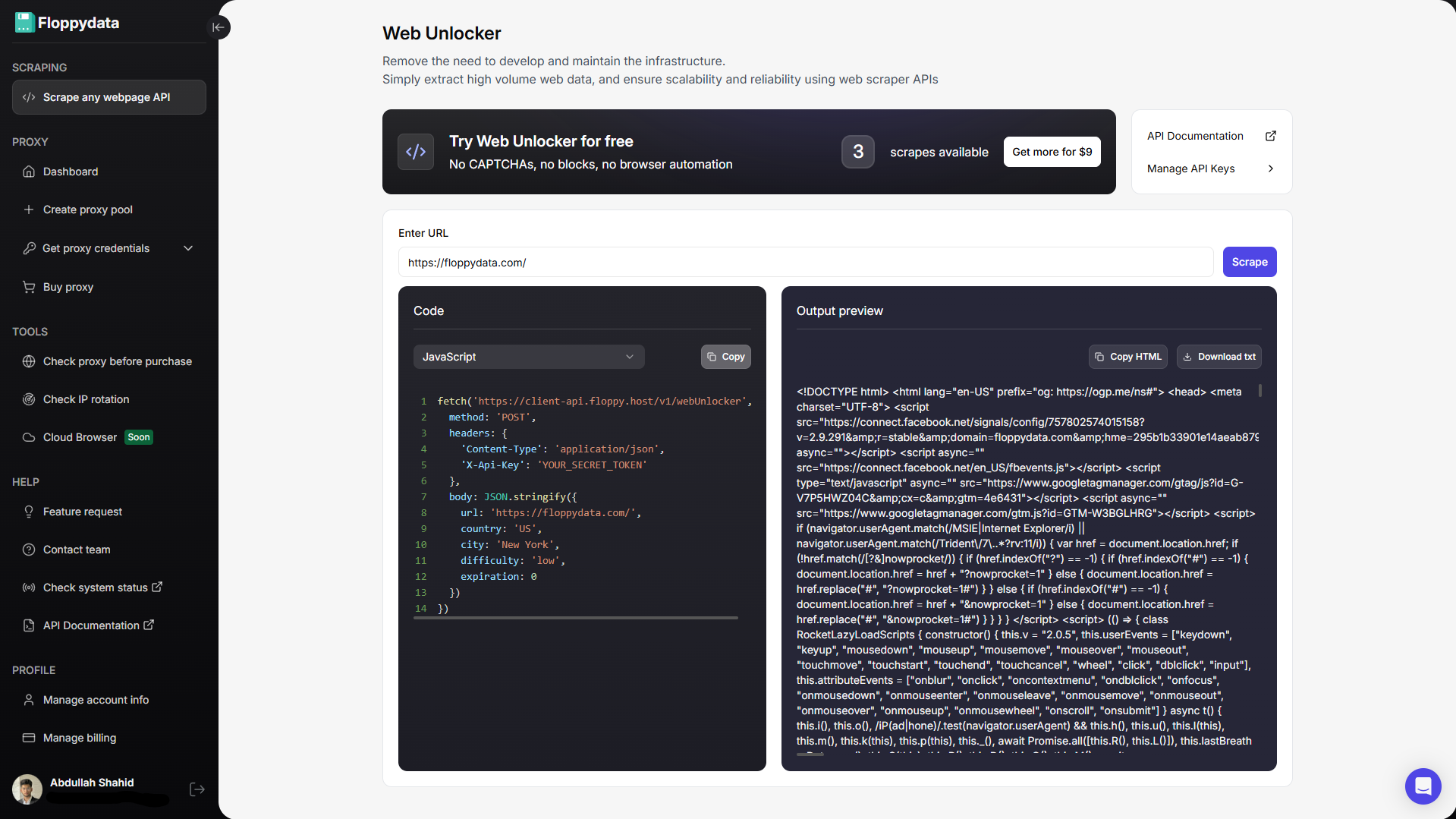
Au lieu d’essayer d’utiliser le scraper de Java, utilisez une API de scraper web de confiance. Cette API reçoit l’URL de votre page web, lui envoie une requête, gère les CAPTCHA, convertit la page web en données brutes et la renvoie. L’API de balayage du web s’occupe du serveur HTTP, des tentatives, des CAPTCHA, des erreurs, de la mauvaise charge utile, des proxies tournants et de l’empreinte digitale de l’appareil.
En Java, vous écrivez le reste de l’infrastructure du pipeline, comme la création de files d’attente multithread de liens à explorer, l’extraction de balises utiles du contenu HTML et leur stockage de manière structurée, ou l’exécution d’autres fonctions au-dessus des données extraites.
Vous pouvez lire notre revue des meilleurs services de scraping pour trouver celui qui convient le mieux à votre cas d’utilisation.
Étape 2 : Ajouter une clé API dans un extrait de code Java
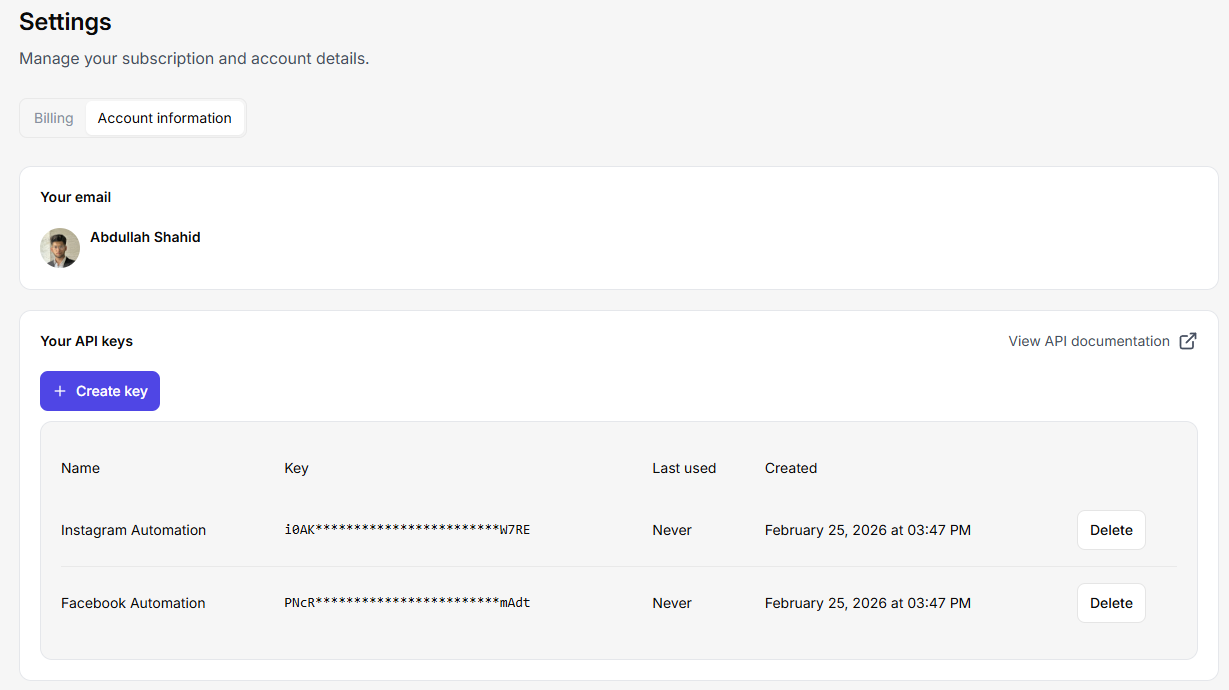
Récupérez la clé API de votre service de scraper web. Intégrons-la dans Java. Vous pouvez créer plusieurs clés API dans Floppydata en allant dans vos paramètres > account > bouton ‘create key’. Vous pouvez envoyer des centaines de requêtes simultanées sur cette API et créer un travail de scraping multithreading qui traite des milliers de pages web à la fois.
Puisque Floppydata exécute vos travaux de web scraping dans le nuage, vous vous déchargez également de la charge d’ouvrir un navigateur web et d’exécuter des bibliothèques de scraping sur votre appareil. Si vous deviez gérer toute l’infrastructure de scraping, vous auriez besoin de beaucoup de RAM et de puissance de traitement.
L’API client de Floppydata utilise un en-tête X-Api-Key, et le point de terminaison Web Unlocker documenté accepte une URL et des paramètres supplémentaires tels que le pays, la ville, la difficulté et l’expiration du cache. La réponse comprend un contenu HTML que vous pouvez analyser en Java.
Voici un exemple d’extrait de code que j’aime utiliser :
public class Floppydatascraper {
public static void main(String[] args) throws Exception {
String apiKey = System.getenv("FLOPPY_API_KEY");
String payload = """
{
"url": "https://example.com",
"country": "US",
"difficulty": "medium",
"expiration": 0
}
""";
HttpClient client = HttpClient.newBuilder()
.connectTimeout(Duration.ofSeconds(20))
.build();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://client-api.floppy.host/v1/webUnlocker"))
.header("X-Api-Key", apiKey)
.header("Content-Type", "application/json")
.POST(HttpRequest.BodyPublishers.ofString(payload))
.build();
HttpResponse<String> response =
client.send(request, HttpResponse.BodyHandlers.ofString());
System.out.println(response.body());
}
}Étape 3 : Améliorer votre pipeline d’extraction Java
Maintenant que vous avez intégré la clé API, construisez votre pipeline de scraping autour d’elle. Par exemple, si vous avez un outil de commerce électronique qui explore Amazon à la recherche de produits pertinents autour du mot-clé ciblé, extrayez leur titre, leurs balises, leur description, etc. et montrez-les à l’utilisateur. L’API Scraper est l’approche la meilleure et la plus évolutive. Même si vous avez des milliers de clients qui envoient des requêtes simultanées à votre application, l’API Floppydata peut facilement les gérer.
Vous pouvez ajouter d’autres fonctionnalités autour des données extraites, comme l’utilisation d’une clé d’API d’IA pour écrire une description et un titre similaires, ou pour analyser des mots-clés similaires à partir de tous les résultats extraits, etc. Toute cette infrastructure doit être construite de votre côté en Java.
Navigation sans tête en Java sans Selenium ou Puppeteer
Traditionnellement, les scrapers utilisaient Selenium et Puppeteer pour exécuter des sessions de navigation sans tête, gérer les proxys et la logique de scraping. Cependant, ce processus est plus lourd, plus lent et ne fonctionne pas en production en cas de forte charge, car vous avez besoin d’une infrastructure en nuage évolutive pour gérer la demande croissante. Vous finissez par passer du temps à construire l’infrastructure que vous pouvez obtenir à partir de ces API de scraping extrêmement bon marché comme Floppydata. De plus, ces outils de scraping sont testés en termes de fiabilité et d’échelle, et évoluent constamment avec le marché, de sorte que vous n’avez pas à changer votre pipeline de scraping tous les 4 mois.
Avec l’API de Floppydata, vous avez besoin :
- pas de gestion locale du navigateur
- pas de flotte de navigateurs sans tête
- pas de maintenance du sélénium
- pas de configuration du marionnettiste
- juste la logique de demande Java et l’analyse HTML
Tout cela pour 0,45 $ – 0,9 $/1k résultats de scraping réussis. C’est moins cher que de maintenir vos propres machines en nuage. Voir les tarifs détaillés.
Réflexions finales
Si quelqu’un me demandait aujourd’hui de construire un pipeline de scraping web en Java, cela me prendrait entre 20 et 30 minutes. J’obtiendrais la clé API de Floppydata et je rédigerais les exigences de mon pipeline, y compris ce que je veux faire avec les données récupérées et comment je veux les stocker. J’utiliserais ensuite Claude Code pour créer un pipeline de scraping robuste. Comme je ne mets pas en place d’infrastructure de scraping, je peux rapidement tester en exécutant ce script si mon pipeline fonctionne ou non.
Java est un excellent choix pour construire des systèmes de web scraping évolutifs et multithreads, même avec ses limites. Mais en 2026, les bibliothèques de scraping web de base n’ont aucune chance face aux systèmes anti-bots alimentés par l’IA que les plateformes déploient pour tenir les scrapers à l’écart. Vous avez besoin d’un outil de scraping tout aussi moderne et puissant pour déployer une automatisation de scraping réussie.






