

Un desbloqueador web (o desbloqueador web) es una herramienta online que te ayuda a evitar CAPTCHAs, sistemas anti-bot y bloqueos para acceder a cualquier sitio web. Un desbloqueador web es una versión mucho más avanzada de un proxy web. En lugar de simplemente redirigir las solicitudes de URL a través de una dirección IP diferente, los desbloqueadores web también evitan los sistemas anti-bot no sólo para acceder al contenido web, sino también para raspar datos HTML y JSON.
Los usuarios suelen utilizar desbloqueadores web para la automatización del raspado de datos. Este blog explora los desbloqueadores web en detalle, en qué se diferencian de los proxies, para qué casos de uso sirven y cómo configurar una automatización de raspado web utilizando una API de desbloqueador web fiable. Entremos de lleno.
Comparación: Desbloqueador Web vs Proxy Web
Un proxy web normal le ayuda a acceder a contenidos restringidos redirigiendo su tráfico a través de una IP diferente y ya está. Los proxies web también suelen ser más lentos porque la misma IP y el mismo servidor son compartidos por cientos o miles de usuarios simultáneos que envían múltiples peticiones. Las versiones premium de los proxies web son más rápidas, pero aún así pueden ser compartidas por varios usuarios premium.
Un desbloqueador web hace algo más que cambiar direcciones IP. Intenta imitar una interacción real de tipo humano con el sitio web. No solo desbloquea contenido restringido o redirige el tráfico, sino que también resuelve CAPTCHAs, evita sistemas anti-bot y protege tu cuenta de ser baneada actuando como si un humano real estuviera navegando por el sitio web.
Si utilizas un bloqueador web avanzado como el desbloqueador web de Floppydata, también puedes raspar datos útiles de cualquier sitio web, incluyendo Facebook, Craigslist, Instagram, Ebay y más. Estos datos raspados se limpian y se utilizan para el entrenamiento de modelos de IA, la creación de herramientas para plataformas específicas y otros casos de uso válidos.
Casos de uso del desbloqueador web
Utilizar un desbloqueador web no es ilegal. La legalidad depende de lo que pretendas hacer con los desbloqueadores web. Si estás extrayendo datos para una herramienta de terceros que has creado, o para el entrenamiento de inteligencia artificial, no hay problema. Estos son algunos casos comunes de uso de los desbloqueadores web.
1. Automatización del Web Scraping a escala
El mayor caso de uso de los web unlockers es la automatización del web scraping. No se trata simplemente de raspar una URL, sino de crear una automatización completa que navegue por sí misma por URL o dominios configurados, raspe los datos de todas las páginas y los filtre para proporcionarle los datos que necesita.
Cuando se raspan los datos de un sitio web, se obtiene un código HTML de la página. Esto incluye todo el contenido de la página y cómo se ha diseñado. A continuación, puede extraer información útil de campos específicos. La gente hace web scraping para alimentar sus herramientas de monitorización de precios de productos, seguimiento de SERP para SEO, listados inmobiliarios, bolsas de trabajo e investigación de mercados.
2. Desbloquear contenidos restringidos
El contenido no siempre está georrestringido. A veces, la red en la que estás (oficina, escuela) prohíbe determinados sitios web y terminales. Puedes utilizar un desbloqueador web para acceder a esos sitios web sin ser detectado. Si utilizas un buen bloqueador web como Floppydata, puedes obtener direcciones IP dedicadas y una fiabilidad del 99,9%.
3. Pruebas y control de calidad
Si quieres probar el propio sistema anti-bot de tu sitio web, o probar si funciona en diferentes regiones y cuánta latencia obtienes, los desbloqueadores web son una gran herramienta. En este caso no estás accediendo exactamente a un sitio web bloqueado, pero puedes utilizar su función de automatización para ejecutar pruebas automáticas. Puedes incluso especificar tus propias direcciones IP seleccionando proxies de países específicos o incluso ciudades.
4. Recogida de datos para IA y análisis
Los modelos de aprendizaje automático necesitan toneladas de datos para entrenarse. Dado que las empresas prefieren datos actualizados de la web, utilizan desbloqueadores web y su soporte API para raspar sitios web, almacenar el contenido de sus páginas, extraer datos útiles de ese archivo HTML o JSON y alimentar su modelo para obtener mejores resultados.
¿Por qué los sitios web bloquean el raspado de datos?
Si el «scraping» de datos es legal, ¿por qué las empresas despliegan medidas tan fuertes contra los «scraperos» de datos? Si intentas utilizar un script de Python para extraer datos de una página web, tu dirección IP puede quedar bloqueada. Ya no podrás acceder al sitio web desde tu dispositivo. Hay varias razones por las que las empresas lo hacen, entre ellas la sobrecarga de los servidores y la privacidad de los usuarios.
A las empresas no les gustan los raspadores de datos ni los desbloqueadores web porque suponen una carga innecesaria para los servidores. Una automatización típica de raspado de datos envía miles de solicitudes de páginas simultáneamente para raspar enormes cantidades de datos. Las empresas tienen que pagar por la carga que los raspadores de datos suponen para sus servidores.
La protección de la propiedad intelectual es otra razón. Cuando un sitio web invierte tiempo, recursos y esfuerzo en poner contenidos auténticos en la red, no quiere que los raspadores de datos los obtengan fácilmente y los utilicen sin permiso. Del mismo modo, las plataformas de medios sociales protegen la privacidad de los clientes. Un «scraper» puede acceder a datos públicos de Facebook, Instagram, etc., que se utilizan para crear herramientas de redes sociales.
¿Cómo se protege de la prohibición el Web Scraping utilizando un Desbloqueador Web?

Si eres principiante, nunca intentes ejecutar un script de prueba en tu dispositivo sin un proxy fiable. Una plataforma de confianza como Facebook puede bloquear la IP de tu red y la huella digital de tu dispositivo de por vida. No podrás volver a acceder a la plataforma desde tu dispositivo. Los desbloqueadores web son la forma más segura de ejecutar scripts de prueba.
Cómo los sitios web detectan y prohíben las automatizaciones de Web Scraping
Por lo general, un sitio web realiza un seguimiento de lo siguiente:
- Número de solicitudes realizadas por minuto
- Dirección IP a través de la cual se realizan las solicitudes
- Huella digital del navegador del usuario (fuentes, webGL, sistema operativo, zona horaria, etc.)
Si el sitio web detecta una actividad de spam, bloquea la IP y la huella digital del navegador. Los desbloqueadores web te ayudan a evitarlo.
Cómo Floppydata Web Unlocker permite el raspado web seguro
Floppydata Web unlocker utiliza su propio pool de direcciones IP rotativas y huellas digitales para ayudarle a raspar datos. En lugar de utilizar la IP de tu red y la huella digital de tu dispositivo, Floppydata utiliza proxies seguros y limpios de más de 195 países junto con una sólida tecnología de huella digital del navegador. Envía peticiones desde diferentes IP y huellas dactilares. Las plataformas tratan cada solicitud como un dispositivo único. Esto te ayuda a evitar bloqueos.
Además, los sistemas de detección avanzados también rastrean el comportamiento de navegación, como la forma en que se resuelven los CAPTCHA y si los clics del ratón son aleatorios o robóticos. Floppydata Web Unlocker ayuda aquí imitando un comportamiento de navegación similar al humano para obtener datos. Si una IP de Floppydata es bloqueada, automáticamente utiliza su lógica de reintento y reenvía la misma petición desde un proxy diferente.
Guía: Cómo usar Floppydata Web Unlocker para la automatización del Web Scraping
Si eres un experto raspador web, Floppydata Web Unlocker es la elección perfecta. Tiene dos modos.
- In app scraper para el scraping instantáneo de cualquier URL
- Modo API para ejecutar automatizaciones de web scraping en bloque con lógica de reintento
Si quieres obtener el contenido de una sola página web, puedes utilizar el desbloqueador in-app de Floppydata. Este método se utiliza generalmente para obtener el contenido HTML de una página web para analizar cómo muestran la información.
Paso nº 1: Crear una cuenta Floppydata
Regístrate en Floppydata y abre el panel de control. Aquí es donde puedes gestionar tus proxies y herramientas como el desbloqueador web.
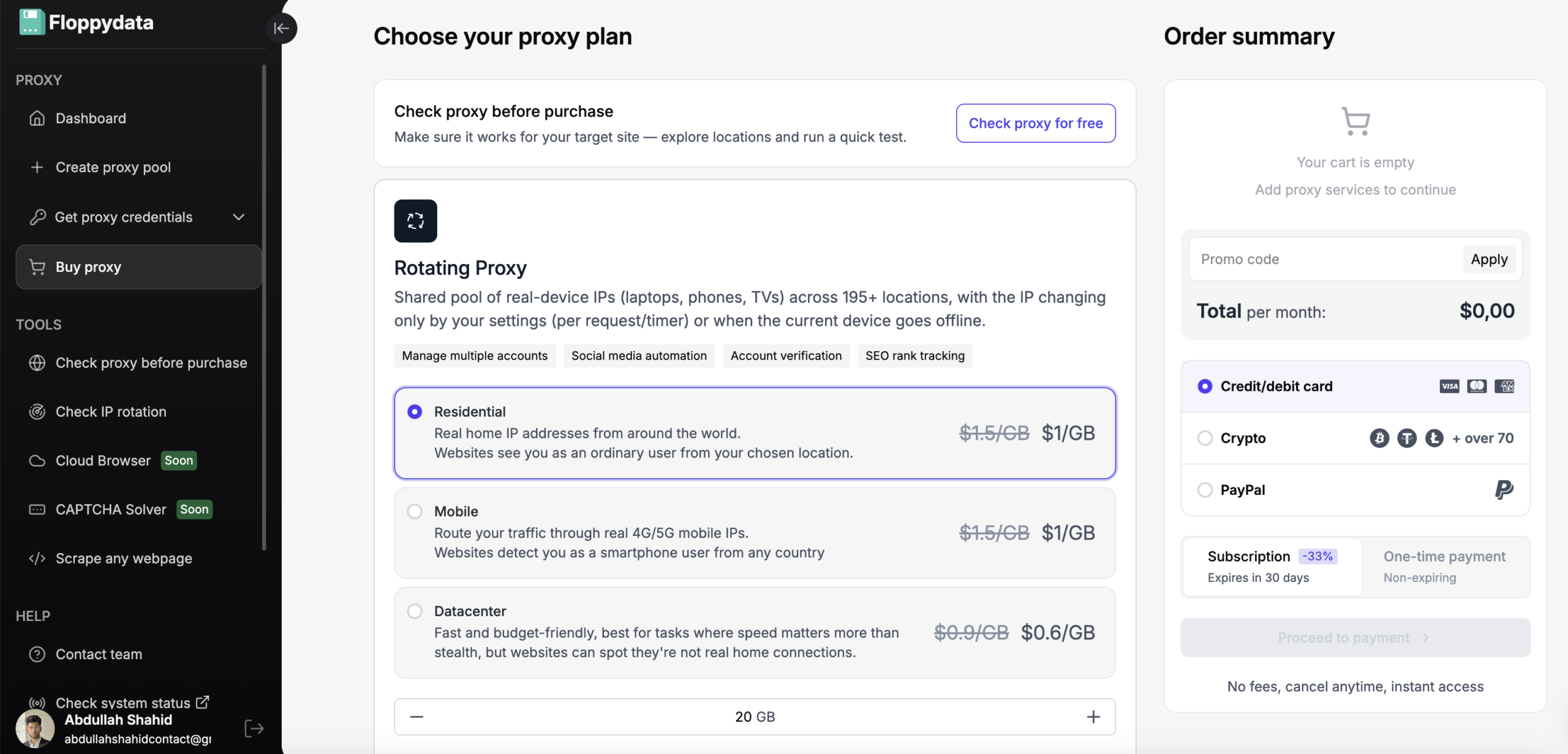
Paso 2: Crear un grupo proxy
Puedes comprar proxies de más de 195 países y crear un pool de proxies para usar. Puedes comprar IPs estáticas o conseguir un ancho de banda para rotar IPs que serán reemplazadas automáticamente en cada petición para evitar ser detectado.
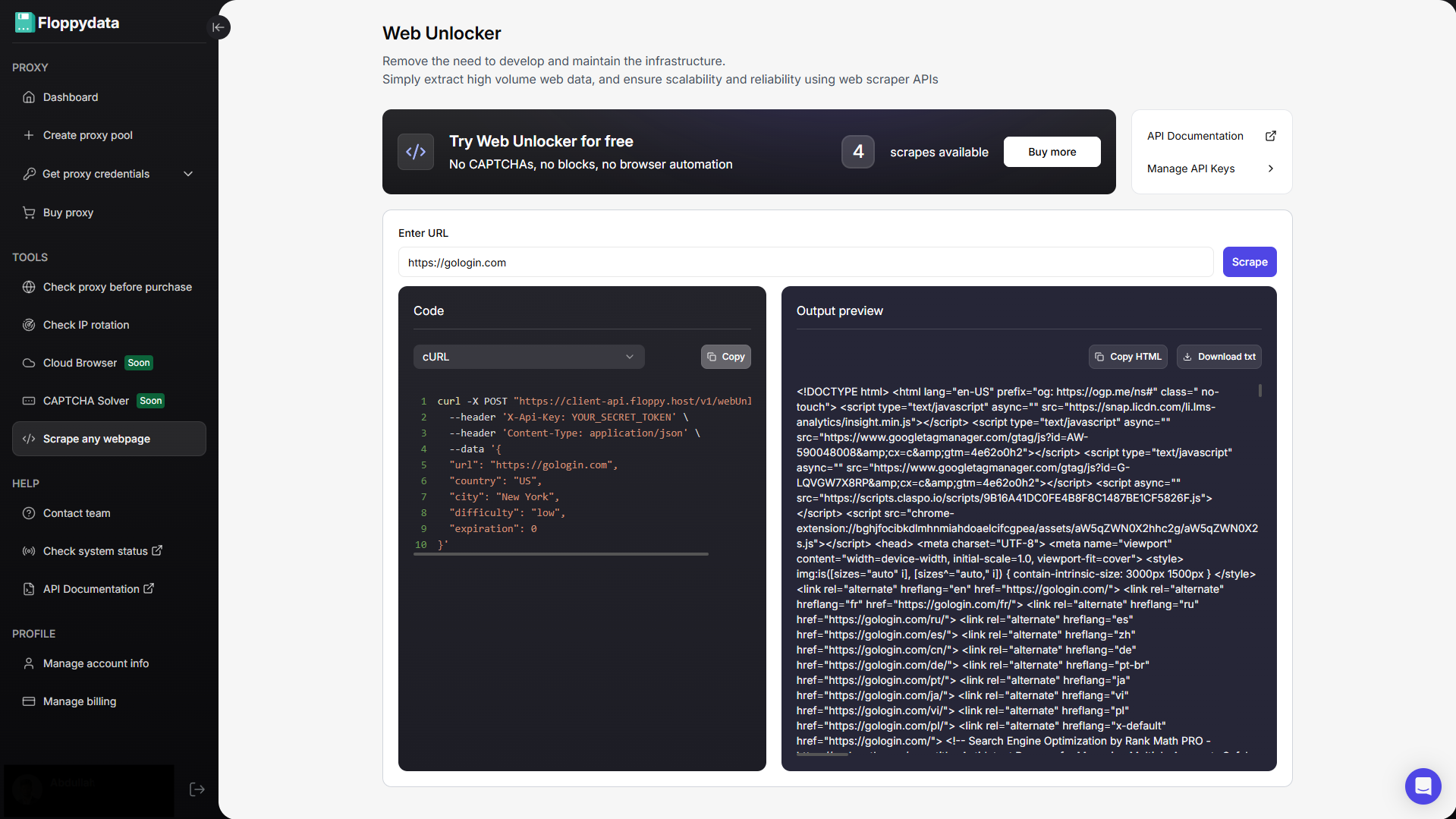
Paso nº 3: Analizar la URL de destino
Pegue su URL en el campo mostrado y haga clic en analizar. Obtendrás el contenido HTML de esa página junto con un fragmento de código para añadir a la automatización de tu navegador. Si está creando una automatización para obtener los precios de los productos de un sitio web, puede utilizar el desbloqueador de sitios web para analizar qué etiqueta muestra el sitio web. Entonces escribiré mi script de automatización para extraer específicamente las siguientes etiquetas y almacenarlas en mi archivo excel/csv.
Paso 4: Crear claves API para la automatización
Puedes crear claves API desde la configuración de tu cuenta. Estas claves API se utilizarán en su script de automatización del navegador para rotar proxies, desbloquear sitios web y raspar datos. Floppydata Web Unlocker raspa datos y los envía a su script a través de esta API.
Paso 5: Escribir y ejecutar la automatización de Web Scraping
Ahora que tienes la clave API y los proxies, puedes crear un script de web scraping en Python, Javascript, C# o GO. Coloque su clave API en el fragmento de código que se muestra en la página del desbloqueador web junto con las URL. También puedes añadir más funcionalidades a tu script como la búsqueda de etiquetas específicas a partir de los datos raspados de la API, y guardarlos en un archivo csv o excel en tu dispositivo.
Este es el aspecto de un típico fragmento de Python:
httpx.post(
«https://client-api.floppy.host/v1/webUnlocker»,
cabeceras={
«Content-Type»: «application/json»,
«X-Api-Key»: «YOUR_SECRET_TOKEN»
},
json={
«url»: «http://ip-api.com/json»,
«country»: «US»,
«ciudad»: «Nueva York»,
«dificultad»: «baja»,
«caducidad»: 0
}
)
Conclusión
En lugar de descargar varios navegadores y configurar proxies en cada perfil, puede realizar todas sus automatizaciones de web scraping utilizando la clave API de Floppydata. También puede emparejar esta clave API con un navegador antidetección como Gologin que añade otra capa de sigilo y seguridad en su automatización de raspado web para proporcionar una experiencia sin fisuras.
¡Feliz raspado!






