


X (antes conocida como Twitter) es una de las principales plataformas de medios sociales. Con más de 500 millones de publicaciones (o tweets) al día, la plataforma alberga sin duda una gran cantidad de datos. Así que, si sabes cómo raspar datos de Twitter, tienes un lago de datos de análisis de tendencias, perspectivas competitivas y sentimiento de mercado.
Por lo tanto, puede utilizar fácilmente un raspador de Twitter para recopilar y transformar los tweets en información procesable. Aunque entender cómo raspar datos de Twitter tiene varias ventajas, el proceso puede resultar confuso debido a todas las restricciones.
¿No sabes por dónde empezar? Aquí te ofrecemos una guía completa sobre cómo scrapear tweets.
Empecemos.
¿Qué es el Twitter Data Scraping?
El scraping de Twitter es un proceso automatizado de extracción de datos públicos disponibles en la plataforma. Implica el uso de un raspador de perfiles de Twitter hecho a medida o de herramientas de raspado sin código. Twitter es una de las pocas plataformas que ofrece una API oficial, pero su uso puede resultar muy caro y frustrante.
Algunos de los datos que puede recopilar de la plataforma son:
- Datos del perfil: Nombre de usuario, biografía, estado de verificación, URL de la foto de perfil, número de seguidores/seguidos.
- Hilos de conversación: Citar tuits, respuestas, tuits compartidos, tuits marcados y cadenas de conversación conectadas a un tuit principal.
- Tweets: Contenido de texto, marca de tiempo, respuestas, retweets, me gusta y URL de medios.
- Métricas de compromiso: Me gusta, citas, retweets, recuento de favoritos.
- Seguidores: Lista de usuarios que siguen una cuenta determinada
¿Por qué Scrape X (antes Twitter)?
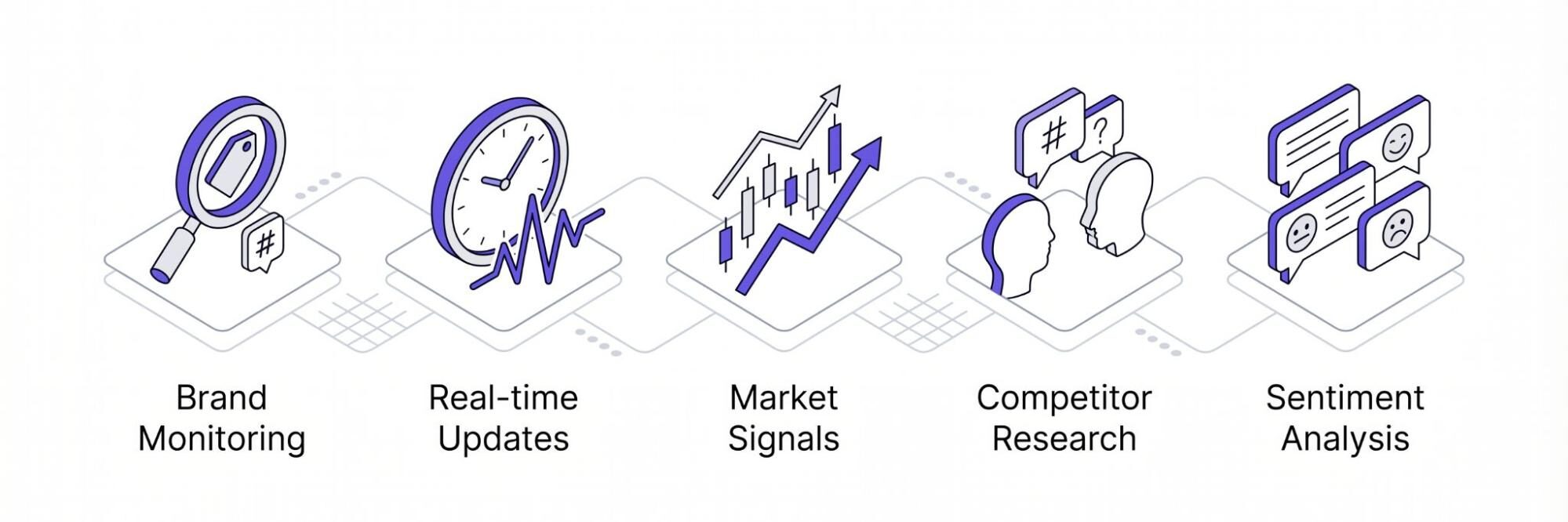
Estas son algunas de las razones más comunes por las que los particulares y las empresas necesitan un rascador de enlaces de Twitter para recopilar datos:
Supervisión de marcas
El scraping de Twitter es una buena forma de controlar lo que la gente dice de su marca en diferentes regiones. También ayuda a identificar la circulación de productos falsificados que pueden afectar negativamente a su marca. Por ejemplo, hay muchas quejas sobre la disminución de la calidad de los productos. Con estos datos, las marcas pueden tomar medidas para retirar todos los productos falsificados. También pueden cambiar sus envases para destacar aún más en las estanterías del mercado.
Actualizaciones en tiempo real
Aprender a scrapear tweets es una forma de obtener datos en tiempo real. Obtener actualizaciones en tiempo real es necesario para analizar la información inmediatamente cuando se producen. Por lo tanto, las empresas pueden tomar decisiones inmediatas basadas en datos y responder rápidamente a los cambios en las tendencias. Además, obtener actualizaciones en tiempo real es necesario para ofrecer experiencias personalizadas, como recomendaciones de productos en tiempo real.
Siga las señales del mercado
Twitter es una plataforma increíblemente útil para monitorizar y rastrear señales. Muchos anuncios en las comunidades financiera y de criptomonedas suelen surgir por primera vez en la plataforma. Por lo tanto, la recopilación de datos relevantes permite entender las tendencias, haciendo buenas predicciones sobre si el mercado experimentará un movimiento alcista o bajista.
Investigación de la competencia
Otra ventaja de recopilar datos de Twitter es que desempeña un papel clave en la investigación de la competencia. Proporciona información útil sobre lo que publican los competidores, los hashtags utilizados y cómo interactúan con su audiencia. Posteriormente, esto se puede analizar e integrar para
Análisis del sentimiento
Muchas personas acuden a Twitter para calificar o elogiar a las marcas en función de su percepción. Por lo tanto, la plataforma se convierte en una gran opción para recopilar datos para el análisis de sentimiento. Proporciona a las marcas información sobre cómo las percibe su audiencia y cómo pueden mejorar para mantenerse por delante de la competencia. Además, el scraping de correos electrónicos de Twitter permite a las marcas identificar a los usuarios verificados que dejan reseñas.
Cómo extraer datos de Twitter
En esta sección, exploraremos las mejores herramientas de Twitter scraper y cómo utilizarlas para extraer información de la plataforma
Uso de la API oficial de X
X dispone de una API oficial diseñada para optimizar el proceso de recuperación de datos. Aunque inicialmente era gratuita, se convirtió en una herramienta de pago en 2023. Eso no es todo: la plataforma actualiza constantemente su estructura de defensa. Como resultado, tus herramientas DIY para raspar correos electrónicos de Twitter se romperán si no se actualizan constantemente, los límites de velocidad cambian y los tokens caducan.
La API de scraping de Twitter cuesta ahora 42.000 dólares al mes por el plan para empresas que incluye todas las funciones. Aparte de la estricta estructura de precios, aquí tienes otros retos asociados al uso de la API oficial:
Fichas de invitados
Las llamadas API al backend de Twitter suelen necesitar un token de invitado. Sin embargo, debido a las recientes actualizaciones de seguridad, estos tokens:
- El método de adquisición cambia cada dos semanas
- Están asociadas a su dirección IP
- Caduca en 4 horas
La implicación es que tu scraper se vuelve inútil una vez que tu token expira. Conseguir un nuevo token para continuar tu sesión puede convertirse rápidamente en un desagradable ir y venir entre las restricciones de funcionamiento de Twitter.
doc_ids
La infraestructura de Twitter utiliza doc_ids como identificadores que dan órdenes al servidor backend sobre qué datos recuperar. Aquí es donde la cosa se complica:
- No existe documentación pública sobre su funcionamiento.
- Requiere ingeniería inversa desde el frontend JavaScript del servidor
- Rota cada 2-4 semanas
- Implica el seguimiento de unas 12 identificaciones diferentes al mismo tiempo
Limitación de velocidad
X aplica límites estrictos a la tasa de desecho de correos electrónicos de Twitter. Los límites varían en función del nivel de suscripción.
- La plataforma impone un límite de velocidad de 300 solicitudes por dirección IP.
- Emplea pruebas de validación de cookies que detectan proxies rotativos
- Las IP de los centros de datos se detectan y bloquean fácilmente
- Comprobaciones avanzadas de huellas dactilares TLS para bloquear actividades automatizadas
He aquí un breve desglose del funcionamiento de la API oficial:
- Cargar página de Twitter
- JavaScript inicializa y solicita un token de invitado
- Ficha de invitado recibida pero válida sólo durante 2-4 horas
- JavaScript envía consultas GraphQL con el token
- Las consultas requieren docs_ids para determinar qué
Construir un rascador
Lo primero que tienes que entender sobre la construcción de un scraper es que necesitas ser un programador experto o contratar a uno. Por el bien de esta guía, vamos a hacer referencia a Python y Selenium (un marco de automatización) para construir un raspador de Twitter. Python es generalmente preferido sobre otros lenguajes de programación, ya que es más simple, ofrece amplias herramientas de web scraping, y tiene una buena documentación.
He aquí un breve método para conseguirlo:
Establecer los requisitos previos
Crea un nuevo directorio para guardar los archivos del proyecto y crea un nuevo archivo Python para el código que estás escribiendo:
$ mkdir scrape_twitter $ cd scrape_twitter $ touch app.py
También necesita instalar Selenium y WebDrive Manager con este comando:
$ pip install selenium webdriver-manager
Buscar una página
Intentemos obtener una página de perfil de Twitter para asegurarnos de que todo funciona bien. En el archivo que creamos anteriormente, añade los siguientes códigos:
from Selenium import webdriver
from selenium.webdriver.chrome.service import Servicio from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get("https://twitter.com/billgates")
El código anterior debería abrir inmediatamente la página de Twitter solicitada. Comienza importando el webdriver, el Servicio y el ChromeDriverManager. Normalmente, se inicializaría el controlador web proporcionando una ruta ejecutable para el binario del controlador específico del navegador en uso:
browser = webdriver.Chrome(executable_path=r "C:|path\to\chromedriver.exe")
El binario necesita ser actualizado con cada actualización del navegador, y esto puede ser frustrante. Para solucionarlo, puedes añadir ChromeDriverManager().install(), que descarga automáticamente el binario necesario para el navegador
N.B: Puedes utilizar este código para scrapear correos electrónicos de Twitter o utilizarlo como un scraper de enlaces de Twitter.
El flujo de cómo funciona la API oficial de Twitter tiene una implicación directa para tu raspador DIY. En otras palabras, significa que incluso si construyes un scraper personalizado con tu lenguaje de programación preferido, no podrás realizar consultas sin un token de invitado. Del mismo modo, tu consulta no coincidirá con ninguna operación backend sin el doc_id apropiado. La plataforma bloqueará su dirección IP si no se respetan los límites de tarifa y no se integran proxies residenciales en el scraper.
Utilice un rascador sin código
Por último, en las mejores herramientas de Twitter scraper, tenemos la opción sin código. Como su nombre indica, no implica ningún tipo de codificación ni requiere conocimientos o experiencia con lenguajes de programación. Por lo tanto, son herramientas para principiantes que hacen posible que cualquiera pueda extraer datos de Twitter.
La mayoría de los raspadores sin código tienen una interfaz de apuntar y hacer clic, lo que los hace muy fáciles de usar. Ya están diseñados para interactuar con la API de la plataforma para una recuperación de datos eficaz. A diferencia de los scrapers DIY que requieren un mantenimiento constante, los scrapers sin código eliminan este reto ya que el proveedor es responsable de sus funciones.
Estos raspadores sin código están ganando cada vez más popularidad por varias razones. Aparte de su facilidad de uso, proporcionan una vía de accesibilidad que puede ser aprovechada por cualquiera, independientemente de su experiencia técnica. Por lo tanto, las empresas no tienen que gastar recursos construyendo un scraper, manteniéndolo, y aún así manejar todos los desafíos asociados con el sistema de defensa de Twitter.
Los raspadores sin código suelen venir con herramientas integradas como la gestión de proxy, la gestión de cookies, la resolución de CAPTCHA, etc. para garantizar una recuperación eficaz de los datos de Twitter. Sin embargo, el rendimiento y la calidad de los datos extraídos varían en función del proveedor de servicios. Factores como el coste, el rendimiento, la documentación y la atención al cliente deben tenerse muy en cuenta antes de elegir la mejor solución no-scrape.
¿Dónde conseguir un Twitter Scraper?
Floppydata destaca, no sólo como un servicio proxy fiable para gestionar múltiples cuentas de Twitter, sino también como scraper. Su solución de extracción de datos sin código viene con características robustas que hacen que el raspado de perfiles de Twitter sea una experiencia positiva.
La herramienta de raspado Web Unblocker de Floppydata le permite conectarse con la plataforma, extraer los datos necesarios y guardarlos en un formato fácil de usar. Estas son algunas de sus características:
- Renderiza la infraestructura JavaScript de la plataforma para extraer datos completos
- Rotación automática de proxy incorporada para permanecer en el anonimato.
- Resolución automática de CAPTCHA
- Lógica de reintentos inteligente para evitar la necesidad de reintentos manuales
Otro factor que convierte a Floppydata en la mejor opción son los niveles de precios. El coste de utilizar la API oficial de Twitter sólo es razonable para las grandes empresas. Además, los frecuentes costes de mantenimiento de los scrapers DIY pueden suponer rápidamente unos costes elevados que no resultan prácticos para las pequeñas empresas.
Por otro lado, Floppydata garantiza la accesibilidad asegurándose de que incluso las personas que necesitan raspar datos de Twitter puedan permitírselo. Es más, ofrecen 5 raspados gratuitos para nuevos usuarios, lo cual es un gran comienzo para tu proyecto de extracción de datos. Desde tan sólo 0,98 $ por 1.000 resultados, puedes conseguir la herramienta. Si tienes necesidades personalizadas, puedes ponerte en contacto con el equipo para obtener un esquema de precios personalizado.
Cómo raspar datos de Twitter con Floppydata Web Unblocker
Extraer datos de Twitter con el Desbloqueador Web de Floppydata es sencillo y sólo requiere unos pocos pasos. Aquí tienes una guía sencilla para extraer datos de Twitter:
Paso 1: Visita la página de Web Unblocker e inicia sesión para empezar
Paso 2: Accede a tu cuenta de Twitter. Abre una página de resultados de búsqueda con filtros específicos que se ajusten a tu caso de uso.
Paso 3: Ve al panel de Floppydata’s Web Unblocker y pega la URL
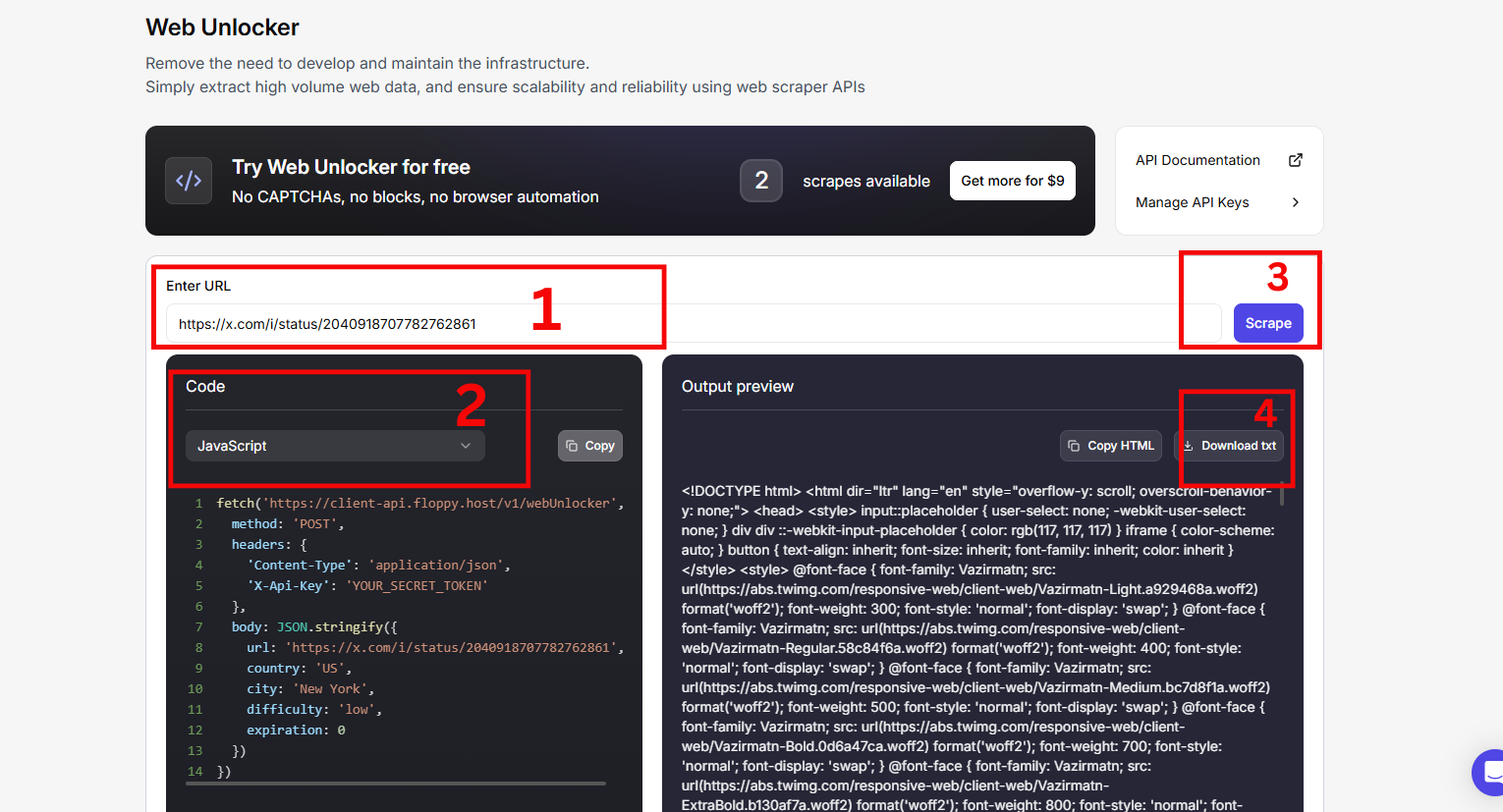
Paso 4: Los resultados estarán listos en unos minutos.
Y habrás extraído datos de Twitter con éxito y sin estrés.
Conclusión
Aprender a raspar datos de Twitter es bastante sencillo. Sin embargo, como se menciona en esta guía, la versión gratuita de la API oficial ha desaparecido. Un raspador DIY está condenado a romperse dentro de 4 semanas porque los límites de velocidad y doc_ids están cambiando, así como tokens que expiran.
Floppydata resuelve todos estos retos proporcionando un scraper que se encarga de todas las partes difíciles por ti. Se encarga de la limitación de tasas, CAPTCHAs, gestión de sesiones y medidas anti-bot para la extracción de datos de Twitter.






