

Im Jahr 2026 ist es nicht einfach, Web-Scraping-Automatisierungen durchzuführen. Da viele KI-Unternehmen versuchen, so viele Daten wie möglich aus dem Internet abzuschöpfen, um Modelle zu trainieren, setzen Plattformen wie Reddit, Meta, X und andere KI-gestützte Erkennungssysteme ein, um zu verhindern, dass Web Scraper öffentliche Nutzerdaten in die Finger bekommen. In diesem Leitfaden erfahren Sie, wie Sie das Web Scraping im Jahr 2026 skalieren und automatisieren können.
Warum wird Web Scraping immer schwieriger?

Hier sind einige Gründe, warum Unternehmen Web-Scraping-Automatisierungen aktiv erkennen und blockieren.
- Web Scraper belasten die Server unnötig, da sie Hunderte oder sogar Tausende von gleichzeitigen automatischen Anfragen senden.
- Werbetreibende mögen keine Bots, weil einem Bot, der Daten von einer Seite ausliest, Anzeigen gezeigt werden und die Werbeausgaben verpuffen.
- Die meisten Unternehmen verkaufen ihre Daten lieber an andere KI-Unternehmen oder trainieren ihre eigenen Modelle. Deshalb wollen sie nicht, dass Scraper kostenlos Daten von ihrer Plattform extrahieren.
Nichtsdestotrotz gibt es auch im Jahr 2026 noch einige effektive Methoden zum Daten-Scraping, die nicht nur sicher sind, sondern auch skalierbar, einfach zu automatisieren und für alle Websites geeignet. Da Anti-Bot-Systeme mit Hilfe von KI immer intelligenter werden, holen auch Web Scraper auf, indem sie CAPTCHAs automatisch lösen, Mausbewegungen und Klicks nach dem Zufallsprinzip sortieren, IPs rotieren, Browser-Fingerabdrücke nach dem Zufallsprinzip sortieren und vieles mehr.
Wie skaliert man Web Scraping?

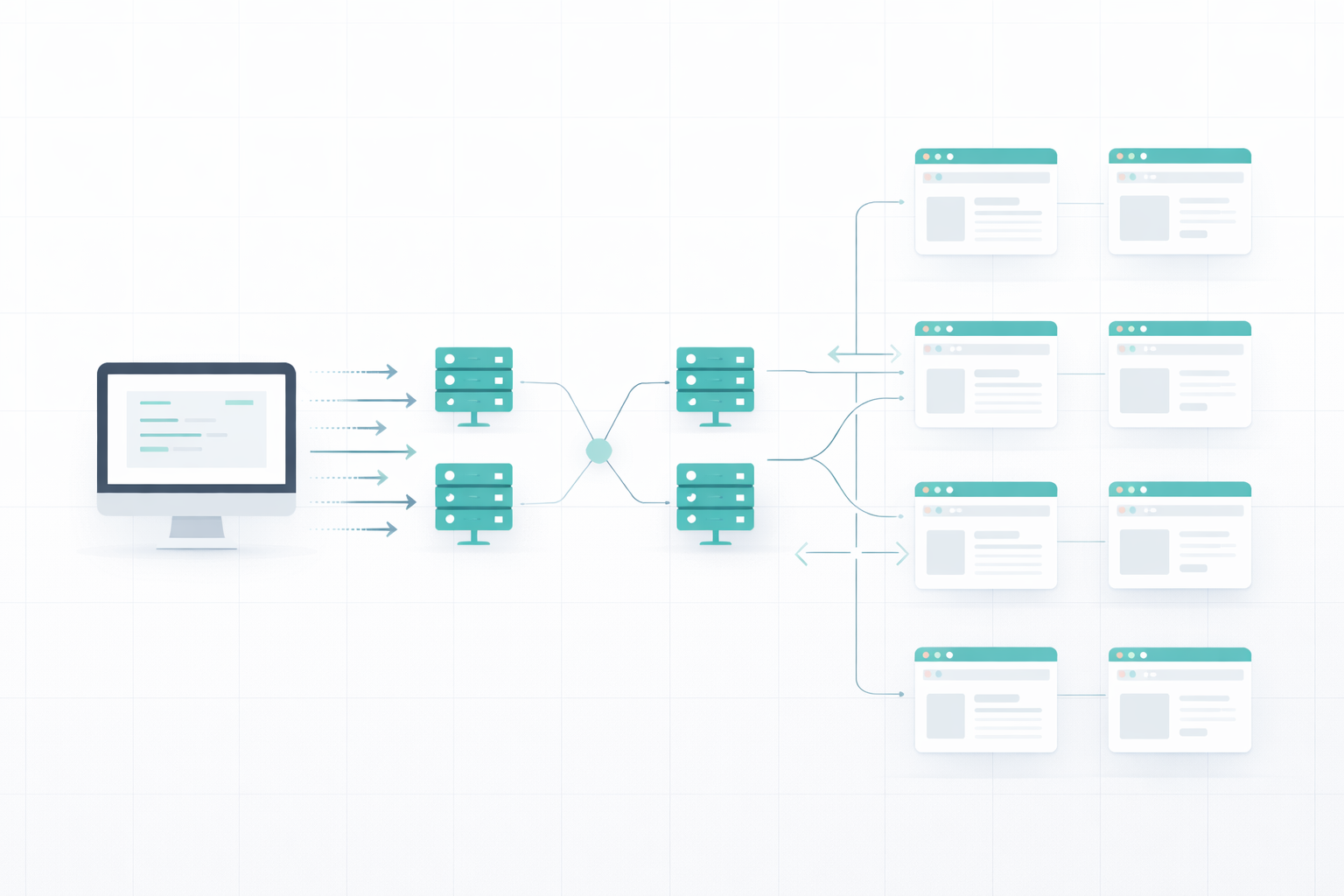
Das Scraping von ein oder zwei Webseiten ist nicht das Problem, aber wie sollen wir innerhalb weniger Stunden oder Tage Tausende von Webseiten scrapen? Wir können auf unserem Gerät nicht so viele Registerkarten öffnen, da der Arbeitsspeicher und die Verarbeitungsgeschwindigkeit begrenzt sind, und wenn unsere IP in den ersten Minuten gesperrt wird, müssen wir auf ein anderes Gerät wechseln.
Die Skalierung von Web Scraping erfordert Verständnis und Planung. Lassen Sie uns zunächst die Herausforderungen beim Web Scraping verstehen.
Herausforderungen beim Web Scraping
Websites sind nicht mehr nur statische HTML-Seiten. Anti-Bot-Systeme verfolgen ständig die Benutzeraktivitäten und die Qualität des Datenverkehrs, um sicherzustellen, dass nur echte Benutzer auf Websites zugreifen und Scraper sofort blockiert werden. Hier sind die Herausforderungen, mit denen ich konfrontiert wurde, als ich mit Web Scraping begann:
- IP-Rate-Limitierung: Die Plattformen verfolgen die Anzahl der Anfragen pro IP-Adresse jede Minute und Stunde. Wenn eine IP-Adresse versucht, das Limit zu überschreiten, wird das Konto gesperrt oder wegen Spam-Aktivitäten vorübergehend deaktiviert.
- Javascript-Rendering: Viele Websites laden Inhalte jetzt dynamisch. Wenn ein Scraper versucht, HTML-Inhalte abzurufen, erhält er fehlende Felder, weil einige Teile der Seite nicht geladen wurden.
- CAPTCHAs: Meine Web-Scraping-Skripte hatten Schwierigkeiten, CAPTCHAs zu lösen und sperrten mich immer wieder aus. Facebook sperrte sogar meine IP und ich konnte nicht mehr über dieselbe IP darauf zugreifen.
- Erkennung von Verhaltensweisen: Websites verfolgen Ihr Verhalten wie Scroll-Aktivitäten, Mausbewegungen, zufällige Klicks usw., um festzustellen, ob Sie ein Bot oder eine echte Person sind.
- Fingerabdruck-Verfolgung: Plattformen speichern und verfolgen Ihren Browser-Fingerabdruck, um festzustellen, welche Geräte dieses Konto verwenden. Wenn ein Verstoß gegen die Nutzungsbedingungen festgestellt wird, können sie den Fingerabdruck sperren und verhindern, dass Ihr Browser auf die Plattform zugreifen kann.
- Verwaltung von Cookies: Ich habe versucht, Proxys und mehrere Browserprofile zu verwenden, aber ich hatte immer wieder Probleme mit der Kreuzkontamination von Cookies. Da alle Profile Cookies meiner Anmeldesitzungen speichern, konnten die Plattformen erkennen, dass ich von demselben Gerät aus andere Konten angemeldet habe und Web Scraping betreibe.
Aufbau einer skalierbaren Web Scraping Strategie
Es gibt einige hervorragende Web-Scraping-Dienste, mit denen Sie ein skalierbares Web-Scraping-System aufbauen können, ohne sich um all die oben beschriebenen Probleme kümmern zu müssen. Diese Web-Scraping-Tools verwenden einen Pool von Proxies und zufällige Browser-Fingerabdrücke, lassen alle Scraping-Sitzungen in der Cloud laufen, um Ihren Rechner nicht zu belasten, lösen CAPTCHAs automatisch, isolieren Cookies und übernehmen das Rendering von Javascript.
Web-Scraping-Dienste wie Floppydata lösen das Problem der Skalierbarkeit durch:
- Parallele Browser-Sitzungen in der Cloud ausführen
- Mit rotierenden IPs aus seinem Pool von 90 Millionen Proxys
- Automatischer Umgang mit CAPTCHAs und JS-Rendering
- Skalierung nach Bedarf, ohne dass eine zusätzliche Infrastruktur eingerichtet werden muss
Wie automatisiert man Web Scraping?
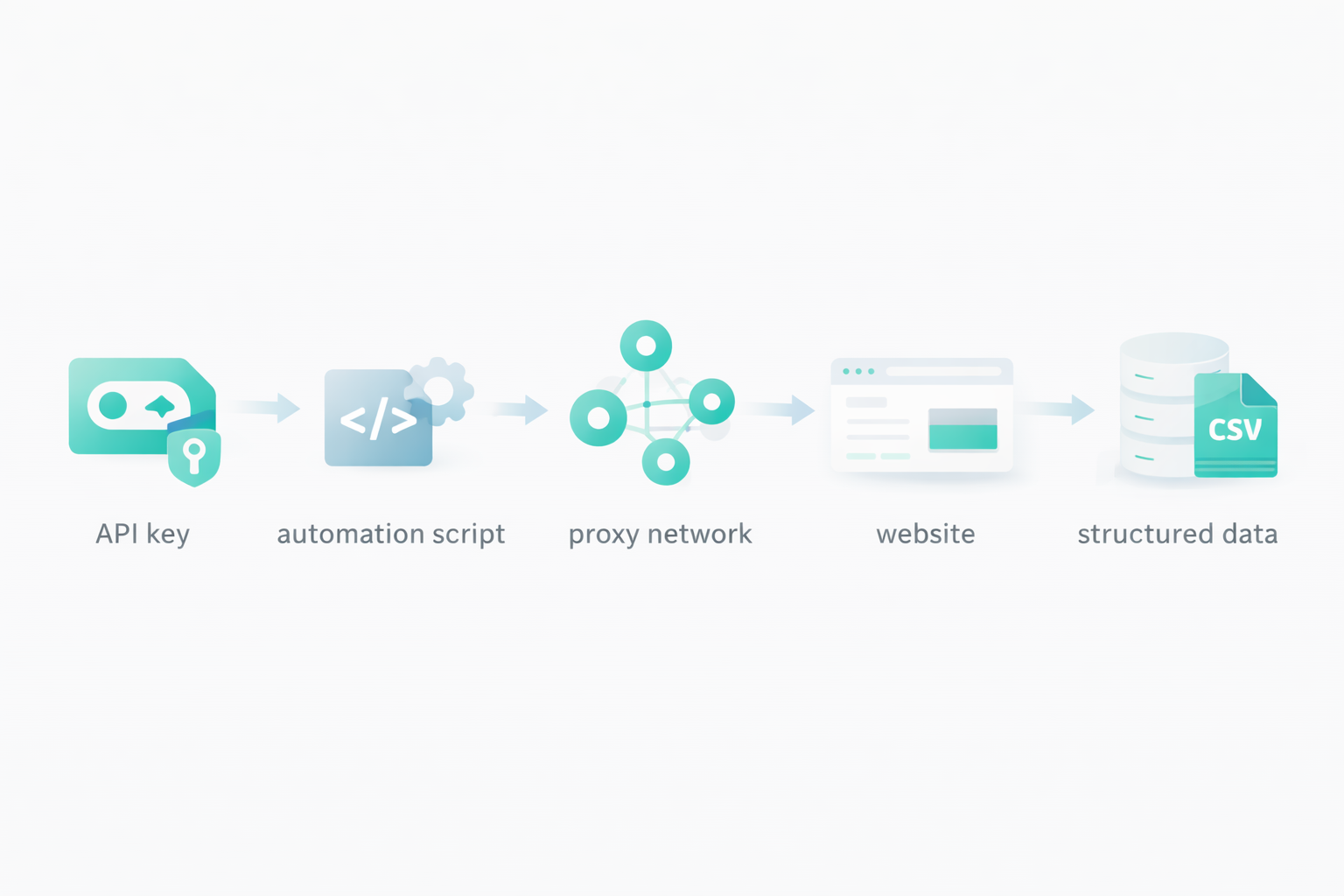
Wenn Sie eine skalierbare Infrastruktur haben, müssen Sie ein automatisiertes System zur Verwaltung von Proxys, Extraktionen, Links, Datenformatierung usw. einrichten. Auch wenn Scraping-Dienste Ihnen eine skalierbare Infrastruktur zur Verfügung stellen, mit der Sie Tausende von Anfragen pro Stunde bearbeiten können, können Sie dies nicht manuell tun. Hier kommen Automatisierungsskripte für Scraping ins Spiel.
Einige Web-Scraping-Dienste bieten vorkonfigurierte Vorlagen für bekannte Plattformen wie Reddit, Meta, Instagram, X. usw. Sie können eine Vorlage auswählen, sie für Ihren Anwendungsfall konfigurieren und mit dem Scraping beginnen.
Eine andere Methode zur Automatisierung von Web Scraping, die auch sehr beliebt ist, sind API-Schlüssel. Web-Scraping-Dienste wie Floppydata bieten ihre API-Schlüssel an, mit denen Sie Web-Scraping-Anfragen an ihren Cloud-Server senden und im Gegenzug die extrahierten Inhalte erhalten. Wenn Sie eine API verwenden, sind die Möglichkeiten endlos. Sie definieren Ihr eigenes Format für die Datenextraktion, Ihre Regeln für die Proxy-Rotation, welche Seiten extrahiert werden sollen, welche Felder extrahiert werden sollen, wie sie gespeichert werden sollen, wie viel Verzögerung zwischen den einzelnen Anfragen eingefügt werden soll, wie viele gleichzeitige Anfragen gesendet werden sollen und vieles mehr.
Sie können diesen API-Schlüssel verwenden, um Scraping-Tools zu erstellen oder ihn in Ihr bestehendes Unternehmenssystem zu integrieren. Alles, was Sie brauchen, ist ein API-Schlüssel, und Dienste wie Floppydata kümmern sich um den Rest und liefern Ihnen die endgültigen Ergebnisse.
Schritt-für-Schritt-Anleitung für skaliertes und automatisiertes Web Scraping
Hier finden Sie eine Schritt-für-Schritt-Anleitung zur Erstellung einer Web-Scraping-Automatisierung mit Floppydata API.
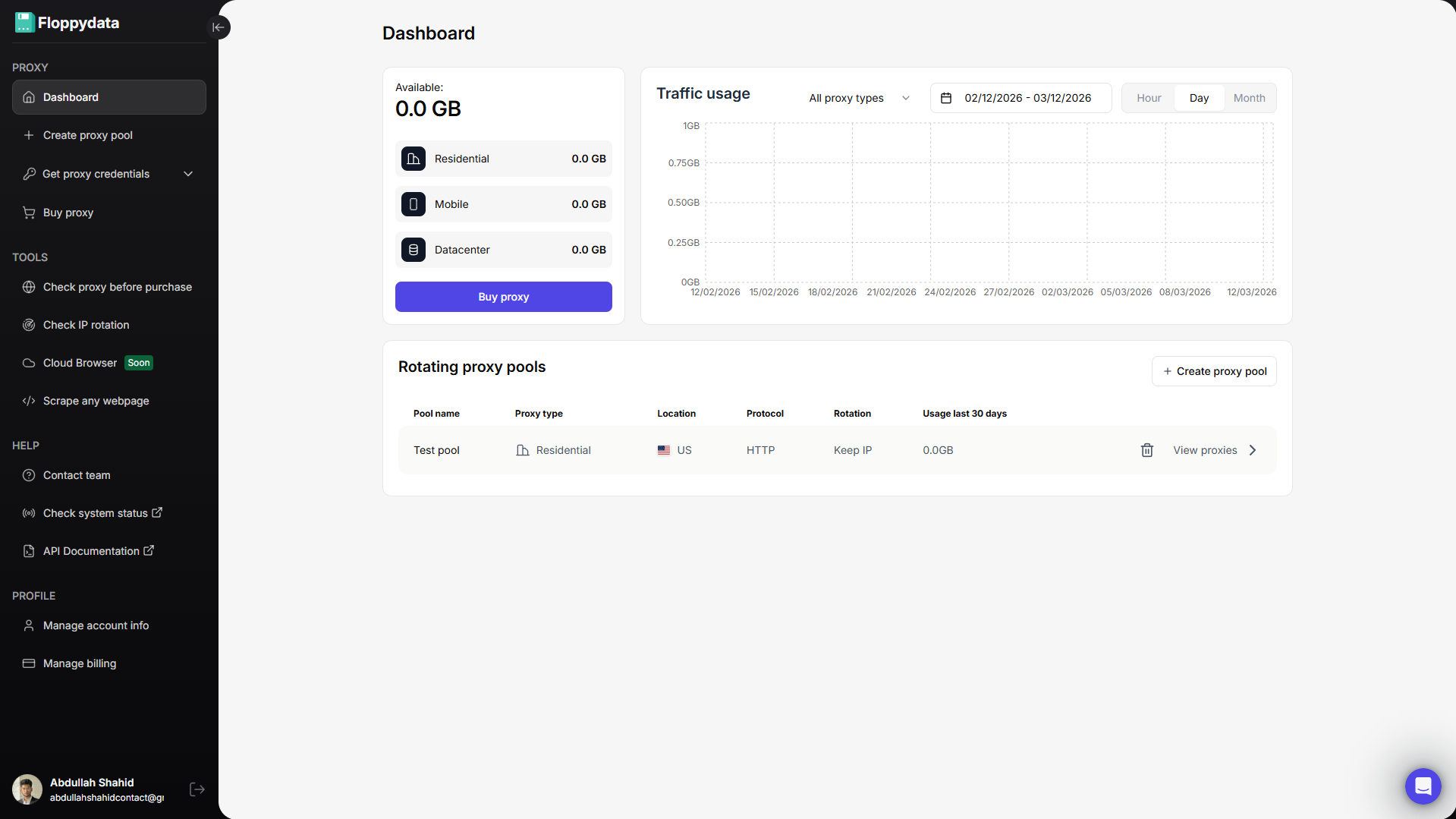
Schritt #1: Erstellen Sie ein Floppydata-Konto
Melden Sie sich bei Floppydata an und öffnen Sie das Dashboard. Hier können Sie Ihre Proxys und Tools wie den Web Unlocker verwalten.
Schritt #2: Analysieren Sie die Ziel-URL

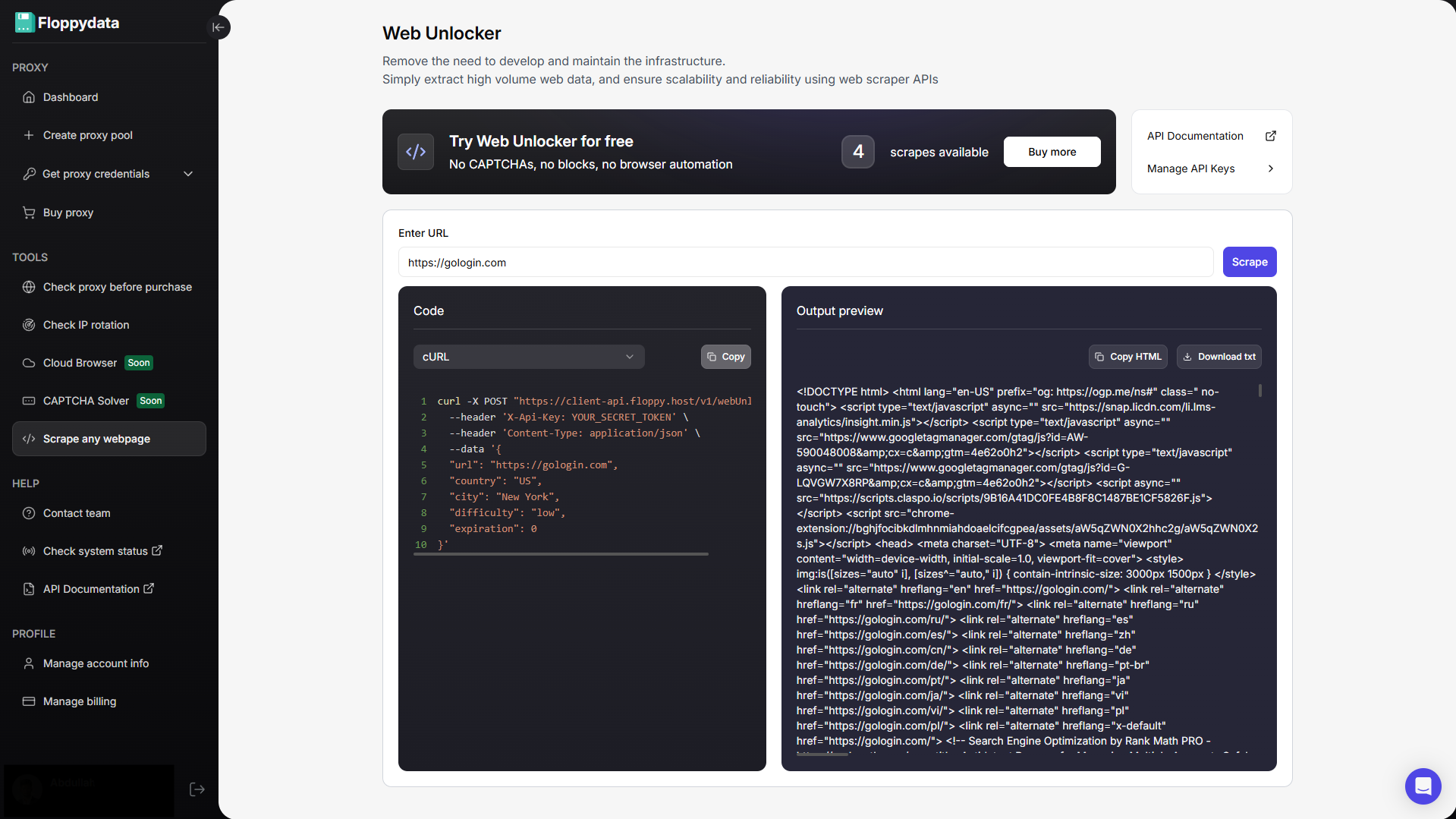
Fügen Sie Ihre URL in das angezeigte Feld ein und klicken Sie auf scrapen. Sie erhalten den HTML-Inhalt dieser Seite zusammen mit einem Codeschnipsel, den Sie zu Ihrer Browser-Automatisierung hinzufügen können. Wenn Sie eine Automatisierung zum Abrufen von Produktpreisen von einer Website erstellen, können Sie diese Analysefunktion verwenden, um zu ermitteln, welches HTML-Tag Preise enthält. Sie können dann Ihr Automatisierungsskript so schreiben, dass es speziell die folgenden Tags extrahiert und sie in Ihrer Excel/csv-Datei speichert.
Schritt #3: API-Schlüssel für die Automatisierung erstellen
Sie können über Ihre Kontoeinstellungen API-Schlüssel erstellen. Diese API-Schlüssel werden in Ihrem Skript zur Browser-Automatisierung verwendet, um Proxys zu drehen, Websites freizuschalten und Daten zu scrapen. Floppydata Web Unlocker schöpft Daten ab und sendet sie über diese API an Ihr Skript.
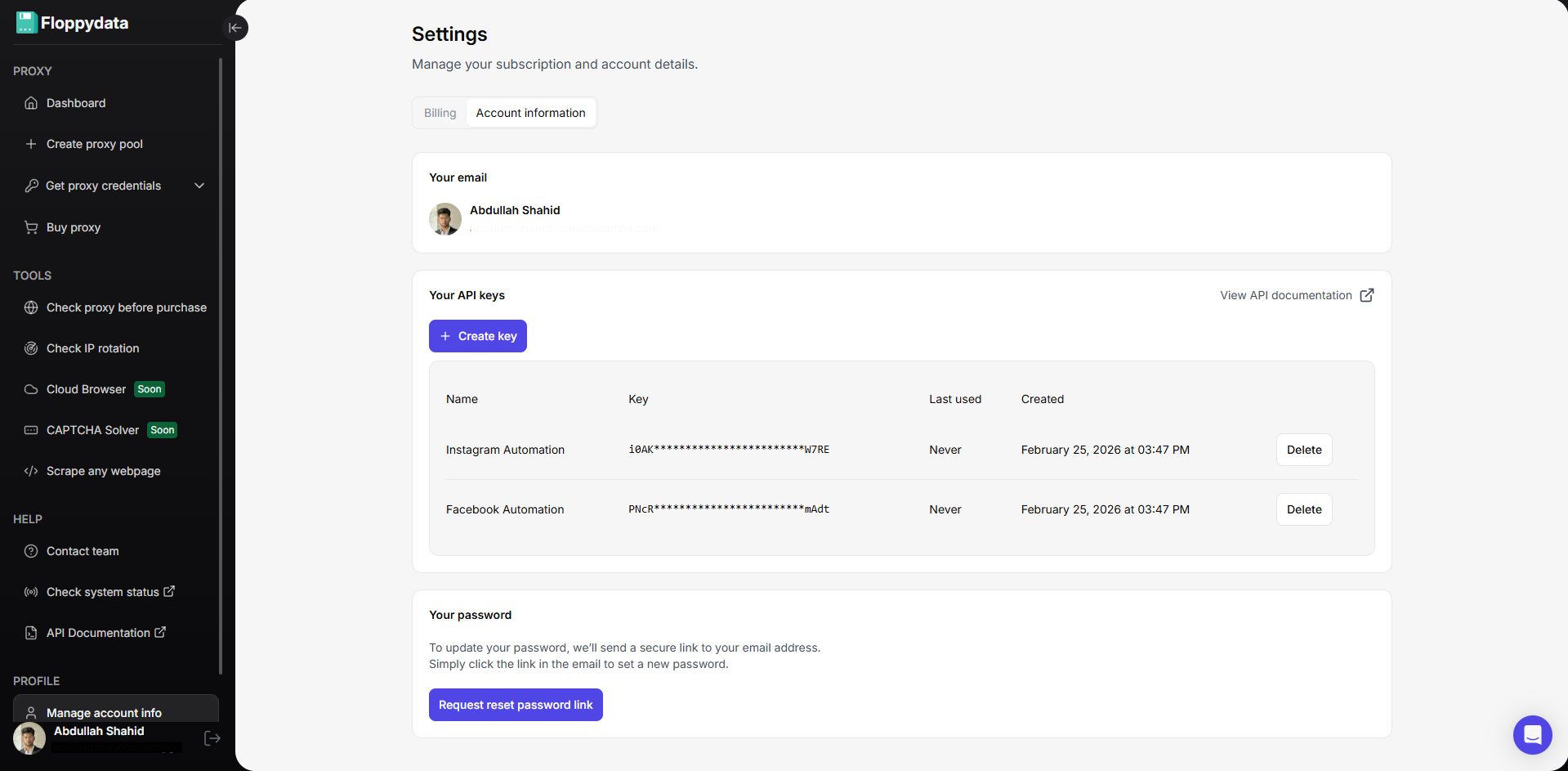
Schritt #4: Web Scraping Automation schreiben und ausführen
Jetzt, da Sie den API-Schlüssel und die Proxys haben, können Sie ein Web-Scraping-Skript in Python, Javascript, C# oder GO erstellen. Fügen Sie Ihren API-Schlüssel zusammen mit den URLs in den Codeausschnitt ein, der auf der Webfreigabeseite angezeigt wird. Hier ist ein kurzes Beispiel für ein Python-Skript, das ich in einem Python-Interpreter ausführen kann, um Daten aus einem Reddit-Diskussionsforum zu extrahieren:
httpx.post(
„https://client-api.floppy.host/v1/webUnlocker“,
headers={
„Content-Type“: „application/json“,
„X-Api-Key“: „YOUR_SECRET_TOKEN“
},
json={
„url“:
„https://www.reddit.com/r/automation/comments/1ntu327/top_5_antidetect_browsers_comparison_2025/“,
„country“: „US“,
„city“: „New York“,
„difficulty“: „low“,
„expiration“: 0
}
)
Sie können das Land, die Stadt und die URL ändern, um Proxy- und Ziellinks zu ändern. Dies ist nur ein Dummy-Codefragment. Mit Claude Code oder ChatGPT können Sie komplexe Automatisierungen erstellen, die dynamisch Ihre gesamte Liste der Ziel-URLs untersuchen und nützliche Inhalte in dem Format Ihrer Wahl extrahieren.
Bewährte Praktiken und Tipps für die Automatisierung von Web Scraping
Bei der Erstellung automatisierter Web-Scraping-Workflows ist es wichtig, die Ausfallsicherheit und die Leistung über die Geschwindigkeit zu stellen. Ihr Workflow muss eine hohe Genauigkeit aufweisen. Wenn 40 % Ihrer Scraping-Anfragen fehlschlagen, verlieren Sie 40 % Ihres Budgets und können keine Ergebnisse vorweisen. Während Floppydata Ihnen nur erfolgreiche Seitenextraktionen in Rechnung stellt, berechnen andere Dienste pro 1.000 Anfragen, selbst wenn diese alle fehlschlagen.
Um eine Automatisierung zu erstellen, die wochen- oder monatelang Teil Ihres Arbeitsablaufs sein wird, müssen Sie ein paar wichtige Dinge beachten:
- IPs pro Arbeiter oder Sitzung rotieren
- Skalieren Sie Scraping mit parallelen Sitzungen, nicht durch Erhöhung der Geschwindigkeit oder Reduzierung der Wartezeiten
- Verwenden Sie Web Unlockers für blocklastige Websites
- Bevorzugen Sie APIs, wenn verfügbar
- Browser-Fingerabdrücke isolieren
- Fehler protokollieren und intelligent neu versuchen
- Testen Sie klein, bevor Sie groß skalieren
- Kaufen Sie saubere Proxys von einem vertrauenswürdigen Anbieter
Sie müssen sich keine Gedanken über Proxies machen, wenn Sie ein Web Unlocker Tool von einem Proxy-Anbieter wie Floppydata, BrightData, Oxylabs usw. verwenden, da diese saubere IPs für ihr Tool bereitstellen können.
Wichtigste Erkenntnisse
Die Skalierung und Automatisierung von Web Scraping ist auch im Jahr 2026 noch möglich und kann sehr effektiv sein, wenn Sie alles richtig machen. Wenn Sie die Strategien befolgen, die ich in diesem Blog erläutert habe, und der Ausfallsicherheit Vorrang vor der Geschwindigkeit einräumen, können Sie eine wiederholbare Automatisierung erstellen, die monatelang funktioniert, bevor Sie irgendwelche Änderungen vornehmen müssen. Mit der richtigen Infrastruktur müssen Sie sich keine Gedanken über ein Anti-Bot-System machen.





