

Java ist dank seiner Leistung, seines Ökosystems und seines Multi-Threadings ideal für den Aufbau schneller, skalierbarer Scraping-Pipelines. Tools wie jsoup eignen sich gut für statisches HTML, aber moderne Websites verlassen sich auf Anti-Bot-Systeme, CAPTCHAs, Proxies und JavaScript-Rendering – was eigenständiges Java-Scraping unzuverlässig macht. Im Jahr 2026 ist es am besten, Java als Kontrollschicht (Anfragen, Parsing, Logik) zu verwenden und sich auf eine Scraping-API wie Floppydata zu verlassen, um die Infrastruktur zu verwalten, Anfragen freizugeben und zuverlässig zu skalieren.
Warum Web Scraping in Java eine leistungsstarke Wahl ist
Java ist aufgrund seiner Geschwindigkeit, Skalierbarkeit und unterstützenden Infrastruktur eine solide Wahl für Web Scraping. Ich habe Python, Go und NodeJS für Scraping ausprobiert, aber Java hat sich bei der Bewältigung von Scraping-Aufgaben auf Produktionsebene immer als viel besser erwiesen. Python eignet sich aufgrund seiner umfangreichen Datenverarbeitungsbibliotheken hervorragend für das Parsing und die Datenmanipulation, aber Java zeichnet sich durch sein statisches HTML-Scraping aus.
Ich bevorzuge Java für Scraping-Aufgaben im Produktionsmaßstab aus folgenden Gründen:
- Geschwindigkeit: Java ist schneller als interpretierte Sprachen wie Python.
- Ökosystem: Sie können professionelle Tools wie Apache HttpClient und Datenbanken verbinden.
- Multi-threading: Java’s ExecutorService macht Multi-Threading Scraping einfach.
Für Java-Backends, die ein ausgereiftes Scraping-System einsetzen möchten, ist die Java-Bibliothek jsoup eine hervorragende Option. Sie können HTML- und XML-Inhalte aus Webseiten extrahieren und mit den Datenmanipulationsbibliotheken von Java verfeinern, ohne dass Sie zusätzliche Tools für die Datenanalyse benötigen.
Viele bekannte E-Commerce-Data-Scraping-Tools verwenden jsoup, um Produkte und Schlüsselwörter von Mitbewerbern aufzuspüren, indem sie groß angelegte Automatisierungsaufträge über Java und jsoup ausführen.
Unverzichtbare Java-Infrastruktur für Web Scraping
Java hat ein ausgereiftes Ökosystem und unterstützt Tausende von Bibliotheken und Integrationen. Die wichtigsten Bibliotheken, die Web Scraping unterstützen, sind jsoup, Apache, Jackson, Gson und andere Bibliotheken zur Datenmanipulation. Java unterstützt auch Datenbankabfragen innerhalb von Code über JDBC.
Jsoup: Java’s Web Scraping Bibliothek
Jsoup ist das Rückgrat des Web Scraping mit Java (für HTML-Webseiten). Jsoup bietet Ihnen eine CSS-ähnliche Selektorsyntax, mit der Sie alle Arten von HTML-Inhalten aus dem extrahierten Dokument extrahieren können.
Jsoup ist schnell, hat eine einfache Syntax und kümmert sich selbstständig um defekte Links.
Beispiel-Code:
Document doc = Jsoup.parse(html);
String title = doc.select("title").text();
String price = doc.select(".price").text();Wenn Sie eine Webseite parsen wollen, müssen Sie sie zuerst abrufen. Java kann eine Seite nicht einfach durchsuchen. Sie benötigen einen HTTP-Server, um eine Anfrage für eine bestimmte Webseite zu stellen, und der Webserver antwortet dann mit dem Inhalt der Webseite zurück. Das ist es, was Sie an jsoup weitergeben, um mit dem Extrahieren von Daten zu beginnen.
Sie können auch die Java-eigenen HTTP-Methoden anstelle des Apache HttpClient verwenden, aber das ist nicht so skalierbar. Apache kümmert sich um Sitzungs-Timeouts, Wiederholungsversuche, Benutzeragenten und Cookies.
Jackson und Gson
Jackson und Gson sind zwei verschiedene Java-Bibliotheken. Diese Bibliotheken helfen Ihnen bei der Umwandlung von extrahiertem Rohtext in saubere und verwertbare Daten, z. B. Produktpreise mit Titeln oder Produktpreise für bestimmte Kategorien auf einer E-Commerce-Website. Jackson eignet sich besser für größere Scraping-Automatisierungen als Gson, das für kleine und leichte Aufgaben konzipiert ist.
Was sind die Nachteile der Verwendung von Java für Web Scraping?
Nachdem Sie nun ein wenig über die Scraping-Fähigkeiten von Java wissen, lassen Sie uns besprechen, wo es Sie im Stich lassen wird. Im Jahr 2026 können Sie sich für skalierbare Scraping-Aufträge nicht mehr allein auf Bibliotheken wie jsoup und Apache HttpClient verlassen.
Es gibt zwei grundlegende Probleme, mit denen Sie konfrontiert werden, wenn Sie ausschließlich mit Java scannen:
- Websites blockieren Sie: Websites sind jetzt defensiver. Es ist ihnen wichtig, ob der Besucher ihrer Website ein echter Mensch ist oder nur ein Bot, der den Server unnötig belastet und unerlaubt Kundendaten abgreift. Websites mögen keine Scraper mehr.
- JS-lastige Seiten können nicht extrahiert werden: Jsoup und andere Extraktions-Frameworks eignen sich hervorragend für HTML-Seiten. Dazu können Produktseiten und andere E-Commerce-/Blog-Webseiten gehören, aber viele Websites haben damit begonnen, JavaScript-Codefragmente einzufügen, um Animationen und coole visuelle Effekte auf der Website hinzuzufügen. Jsoup ist nicht dafür ausgelegt, JS-lastige Seiten zu extrahieren, so dass die Extraktion fehlschlägt oder irrelevante Ergebnisse liefert.
Diese beiden Probleme sind lösbar. Web Scraper haben verschiedene Strategien und Frameworks, um zu vermeiden, dass sie von einer Website blockiert werden, und um JS-lastige Seiten problemlos zu scrapen. Allerdings ist der Prozess nicht so einfach, wie ein paar Zeilen jsoup- und Apache-Code auszuführen.
Der moderne Weg für Web Scraping in Java
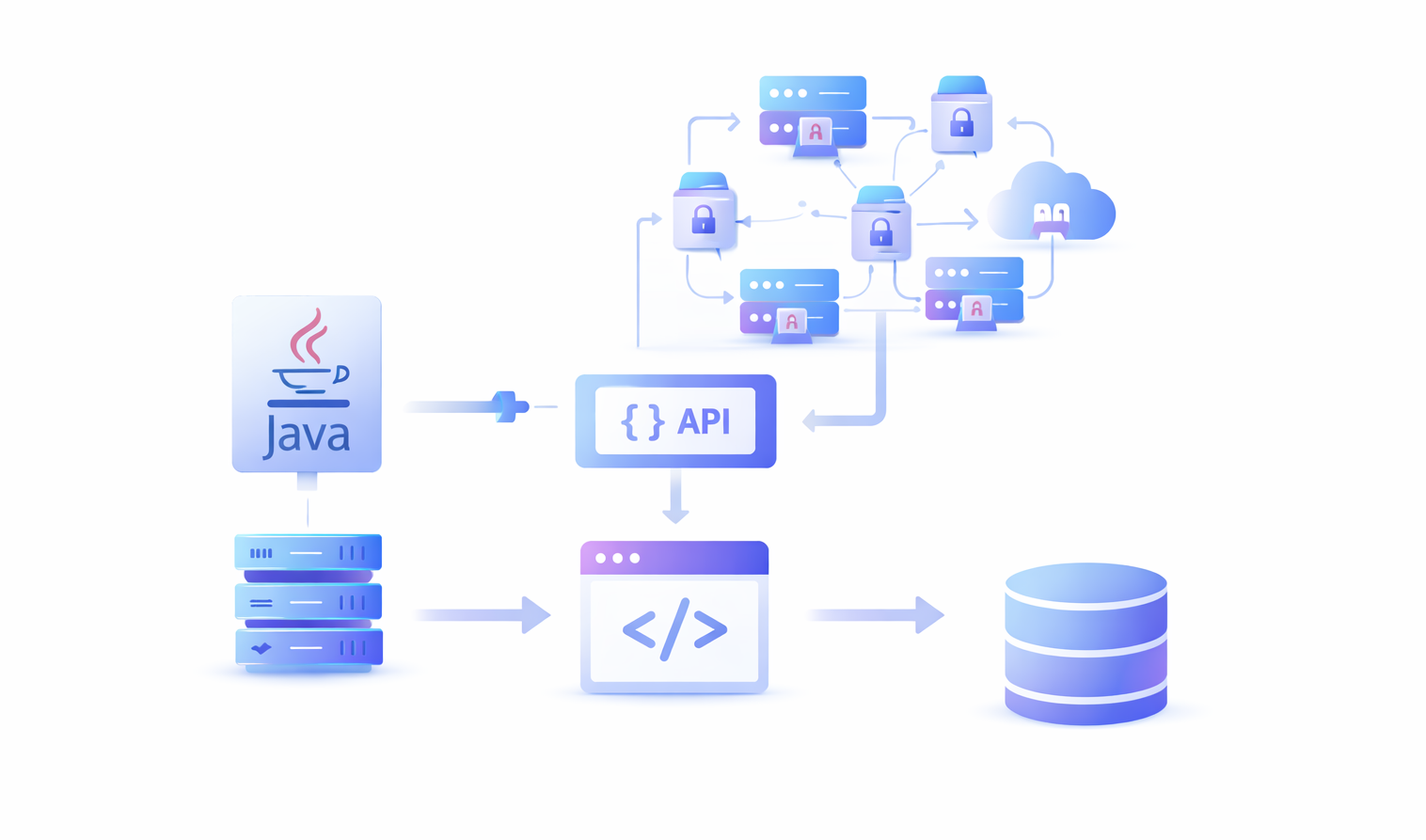
Eigenständige Java-Bibliotheken reichen für Web Scraping im Jahr 2026 nicht mehr aus. Wir haben es nicht mehr mit statischen HTML-Seiten zu tun. Wir haben es mit Anti-Bot-Systemen, CAPTCHAs, Weiterleitungen, Cookies, Java Script-gesteuerten Design-Animationen und Textlayouts und vielem mehr zu tun.
Um eine erfolgreiche und skalierbare Scraping-Automatisierung zu erstellen, müssen Sie Java mit anderen aktuellen Scraping-Technologien kombinieren. Hier ist eine Liste der wichtigsten Dinge, die Sie neben Java-Code benötigen, um eine erfolgreiche Web-Scraping-Automatisierung durchzuführen:
- Ein Pool von Proxys: Websites verfolgen jeden Besucher anhand seiner IP-Adresse. Wenn eine Netzwerkwand wie Cloudflare herausfindet, dass ein Benutzer Daten abgreift, wird als Erstes der Zugriff auf die Website für die IP-Adresse gesperrt. Deshalb brauchen Sie einen Pool von sicheren Proxys und eine Java-Logik, um die Proxys alle paar Anfragen zu wechseln, damit Sie nicht gesperrt werden.
- CAPTCHA-Löser: CAPTCHAs existieren, um Bots von der Plattform zu vertreiben. Herkömmliche Scraper können CAPTCHAs nicht lösen. Die Hardcodierung eines CAPTCHA-Lösers in Java oder einer anderen Sprache ist nahezu unmöglich. Deshalb brauchen Sie einen CAPTCHA-Löser eines Drittanbieters.
- Geräte-Fingerabdruck-Profile: Plattformen wie Facebook und LinkedIn setzen sogar noch fortschrittlichere Erkennungssysteme ein. Diese Systeme stützen sich nicht nur auf IP-Adressen für potenzielle Scraping-Signale, sondern verfolgen auch den Fingerabdruck des Geräts, das Benutzerverhalten, Proxy-Sprünge und Kontoverknüpfungen. Deshalb müssen Sie Ihren Browser-Fingerabdruck zusammen mit Ihren Proxys wechseln, um zu vermeiden, dass Ihr Gerät von der Plattform gesperrt wird.
- Tools für JS-lastige Extraktionen: Selbst wenn Sie alle Erkennungssysteme umgehen, werden viele moderne Webseiten mit schweren Javascript-Frameworks wie ReactJS und NextJS entwickelt. Tools wie jsoup und andere herkömmliche Scraper können keine Inhalte von diesen Seiten extrahieren. Sie benötigen ein zusätzliches Tool, das Ihnen bei der Umwandlung von JS in HTML hilft.
Scraping in Java ist nicht tot. Es ist immer noch sehr nützlich, wenn Sie Ihre eigene Infrastruktur wie Proxys, CAPTCHA-Löser und JS-Seiten-Konverter hinzufügen. Der idealste Weg, all diese Integrationen zu überspringen, ist die Verwendung einer Web Scraper API wie Floppydata.
Leitfaden: Web Scraping mit Java im Jahr 2026
Im Jahr 2026 sollte Java zur Unterstützung der Scraping-Infrastruktur verwendet werden, indem es Anfragen verarbeitet, Rohdaten organisiert, Rohdaten in strukturierte und verwertbare Daten parst und andere Randfälle und Logiken wie Proxy-Rotation, Wiederholungen, Druckmeldungen, Warnungen und mehr verarbeitet.
Wenn Sie versuchen, moderne Webseiten mit jsoup zu scrapen, werden Sie in 40%-50% der Fälle scheitern. Java sollte jedoch wegen seiner Geschwindigkeit, Integrationen und Multithreading verwendet werden, nicht wegen der jsoup-Bibliothek.
Wenn Sie also bereit sind, Java als Steuerungsebene für Ihren Scraper zu verwenden, lassen Sie uns in die einfachste und effektivste Methode des Web Scraping im Jahr 2026 eintauchen.
Schritt 1: Besorgen Sie sich eine Web Scraper API
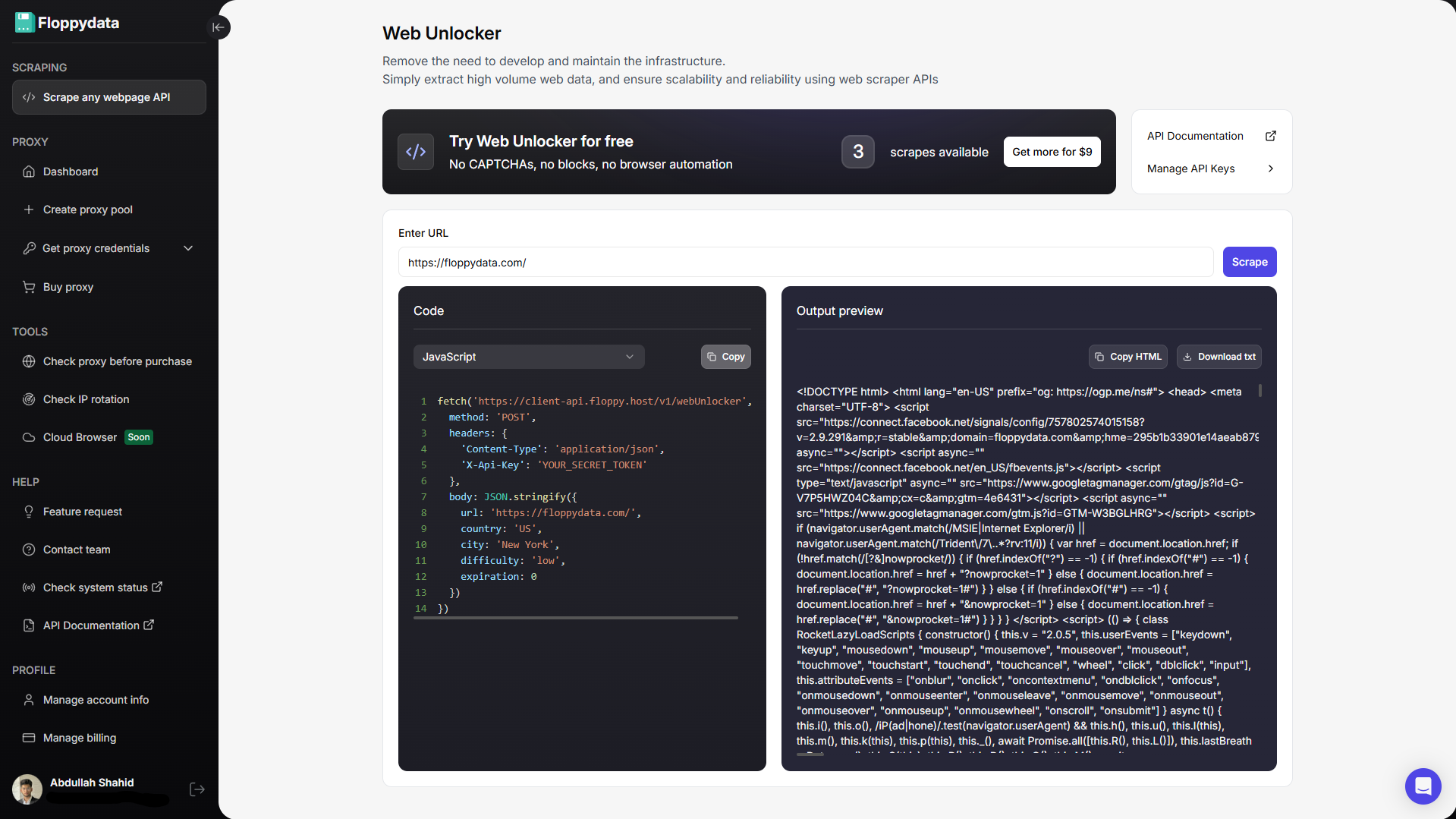
Versuchen Sie nicht, den Java Scraper zu verwenden, sondern nutzen Sie eine vertrauenswürdige Web Scraper API. Eine Web Scraper API empfängt die URL Ihrer Webseite, sendet eine Anfrage an sie, bearbeitet CAPTCHAs, konvertiert die Webseite in Rohdaten und gibt sie zurück. Die Web Scraper API kümmert sich um HTTP-Server, Wiederholungsversuche, CAPTCHAs, Fehler, schlechte Nutzdaten, rotierende Proxys und Geräte-Fingerabdrücke.
In Java schreiben Sie den Rest der Pipeline-Infrastruktur, wie z.B. das Erstellen von Multi-Thread-Warteschlangen von Links, die untersucht werden sollen, das Extrahieren nützlicher Tags aus dem HTML-Inhalt und deren strukturierte Speicherung oder das Ausführen anderer Funktionen auf den extrahierten Daten.
Lesen Sie unsere Übersicht über die besten Scraping-Dienste, um den für Ihren Anwendungsfall am besten geeigneten zu finden.
Schritt 2: API-Schlüssel in Java Code Snippet hinzufügen
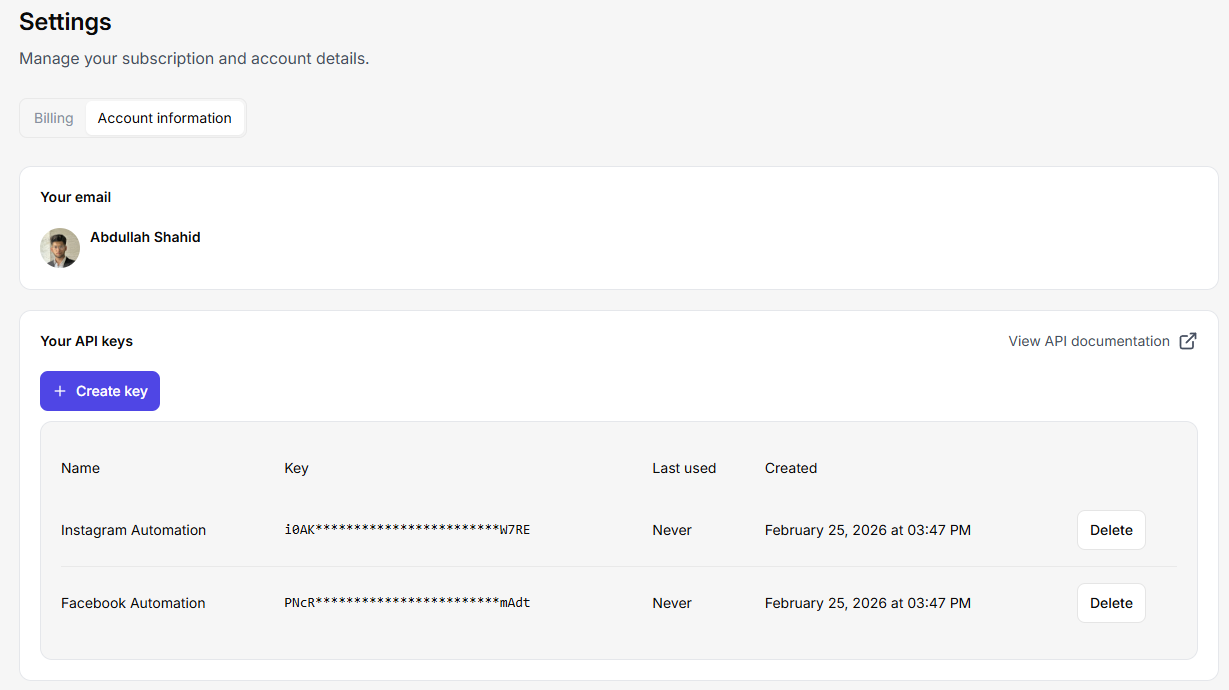
Holen Sie sich den API-Schlüssel von Ihrem Web Scraper-Dienst. Lassen Sie ihn uns in Java integrieren. Sie können mehrere API-Schlüssel in Floppydata erstellen, indem Sie zu Ihren Einstellungen gehen > Konto > Schaltfläche ‚Schlüssel erstellen‘. Sie können Hunderte von gleichzeitigen Anfragen an diese API senden und einen Multi-Threading-Scraping-Auftrag erstellen, der Tausende von Webseiten auf einmal verarbeitet.
Da Floppydata Ihre Web-Scraping-Aufträge in der Cloud ausführt, entlasten Sie sich auch von der Last, einen Webbrowser zu öffnen und Scraping-Bibliotheken auf Ihrem Gerät auszuführen. Wenn Sie die gesamte Scraping-Infrastruktur verwalten würden, bräuchten Sie viel Arbeitsspeicher und Rechenleistung.
Die Client-API von Floppydata verwendet einen X-Api-Key-Header, und der dokumentierte Web Unlocker-Endpunkt akzeptiert eine URL und zusätzliche Parameter wie Land, Stadt, Schwierigkeit und Cache-Ablauf. Die Antwort enthält HTML-Inhalte, die Sie in Java parsen können.
Hier ist ein Beispiel für einen Code-Schnipsel, den ich gerne verwende:
public class Floppydatascraper {
public static void main(String[] args) throws Exception {
String apiKey = System.getenv("FLOPPY_API_KEY");
String payload = """
{
"url": "https://example.com",
"country": "US",
"difficulty": "medium",
"expiration": 0
}
""";
HttpClient client = HttpClient.newBuilder()
.connectTimeout(Duration.ofSeconds(20))
.build();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://client-api.floppy.host/v1/webUnlocker"))
.header("X-Api-Key", apiKey)
.header("Content-Type", "application/json")
.POST(HttpRequest.BodyPublishers.ofString(payload))
.build();
HttpResponse<String> response =
client.send(request, HttpResponse.BodyHandlers.ofString());
System.out.println(response.body());
}
}Schritt 3: Verbessern Sie Ihre Java Scraping Pipeline
Jetzt, da Sie den API-Schlüssel integriert haben, bauen Sie Ihre Scraping-Pipeline um ihn herum auf. Wenn Sie z.B. ein E-Commerce-Tool haben, das Amazon nach relevanten Produkten rund um das Ziel-Keyword durchsucht, extrahieren Sie deren Titel, Tags, Beschreibung usw. und zeigen Sie sie dem Benutzer an. Die Scraper-API ist der beste und am besten skalierbare Ansatz. Selbst wenn Sie Tausende von Kunden haben, die gleichzeitig Anfragen an Ihre App senden, kann die Floppydata API diese problemlos verarbeiten.
Sie können weitere Funktionen um die gescrapten Daten herum hinzufügen, z. B. die Verwendung eines KI-API-Schlüssels, um eine ähnliche Beschreibung und einen ähnlichen Titel zu schreiben oder um ähnliche Schlüsselwörter aus allen extrahierten Ergebnissen zu analysieren usw. Diese ganze Infrastruktur muss auf Ihrer Seite in Java erstellt werden.
Headless Browsing in Java ohne Selenium oder Puppeteer
Traditionell verwendeten Scraper Selenium und Puppeteer für die Ausführung von Browser-Sitzungen ohne Kopf, die Verwaltung von Proxys und die Scraping-Logik. Dieser Prozess ist jedoch schwerfälliger, langsamer und bricht in der Produktion unter hoher Last zusammen, da Sie eine skalierbare Cloud-Infrastruktur benötigen, um die wachsenden Anfragen zu bewältigen. Sie verbringen viel Zeit damit, eine Infrastruktur aufzubauen, die Sie von diesen extrem günstigen Scraping-APIs wie Floppydata erhalten können. Außerdem sind diese Scraping-Tools auf Zuverlässigkeit und Skalierbarkeit getestet und werden ständig mit dem Markt weiterentwickelt, so dass Sie Ihre Scraping-Pipeline nicht alle 4 Monate ändern müssen.
Mit Floppydata API benötigen Sie:
- keine lokale Browserverwaltung
- keine Headless-Browser-Flotte
- keine Wartung von Selen
- keine Puppeteer-Einrichtung
- nur Java-Anfragelogik plus HTML-Parsing
Und das alles für $0,45-$0,9/1k erfolgreich ausgewertete Ergebnisse. Das ist billiger als die Wartung Ihrer eigenen Cloud-Maschinen. Siehe detaillierte Preise.
Letzte Überlegungen
Wenn mich heute jemand bitten würde, eine Web-Scraping-Pipeline in Java zu erstellen, würde das 20-30 Minuten dauern. Ich würde mir den Floppydata-API-Schlüssel besorgen und meine Anforderungen an die Pipeline formulieren, einschließlich der Frage, was ich mit den gescrapten Daten tun möchte und wie ich sie speichern möchte. Dann würde ich Claude Code verwenden, um eine robuste Scraping-Pipeline zu erstellen. Da ich keine Scraping-Infrastruktur einrichten muss, kann ich mit diesem Skript schnell testen, ob meine Pipeline funktioniert oder nicht.
Java ist eine hervorragende Wahl für den Aufbau skalierbarer Multi-Thread-Web-Scraping-Systeme, auch wenn es seine Grenzen hat. Aber im Jahr 2026 haben einfache Web Scraping-Bibliotheken keine Chance gegen KI-gestützte Anti-Bot-Systeme, die Plattformen einsetzen, um Scraper fernzuhalten. Sie benötigen ein ebenso modernes und leistungsstarkes Scraping-Tool, um eine erfolgreiche Scraping-Automatisierung einzusetzen.






