

Введение
Являясь одной из ведущих платформ недвижимости в США, Zillow становится платформой, данные о недвижимости которой многие компании хотят скрейпить. В настоящее время платформа получает около 243 миллионов посещений в месяц, поэтому, естественно, она содержит огромное количество полезных данных о недвижимости.
Однако разработчики часто делятся на Reddit, как им сложно обойти файервол Zillow или получить постоянную блокировку при попытке скрейпинга. Если вы только что столкнулись с этим и ищете стабильное рабочее руководство, читайте дальше.
В этом руководстве я покажу вам, как извлекать ключевые данные объявлений из Zillow, используя Python и простой веб-API.
Что такое скрейпинг Zillow?
Скрейпинг Zillow — это процесс сбора общедоступных данных о недвижимости со страниц Zillow и преобразования их в структурированный формат, такой как CSV или JSON, который вы можете реально использовать в бизнесе или личных целях.
Вместо того чтобы открывать объявления одно за другим, вы можете использовать скрейпер для извлечения ключевых деталей со страниц поиска и страниц с подробностями объявлений о недвижимости.
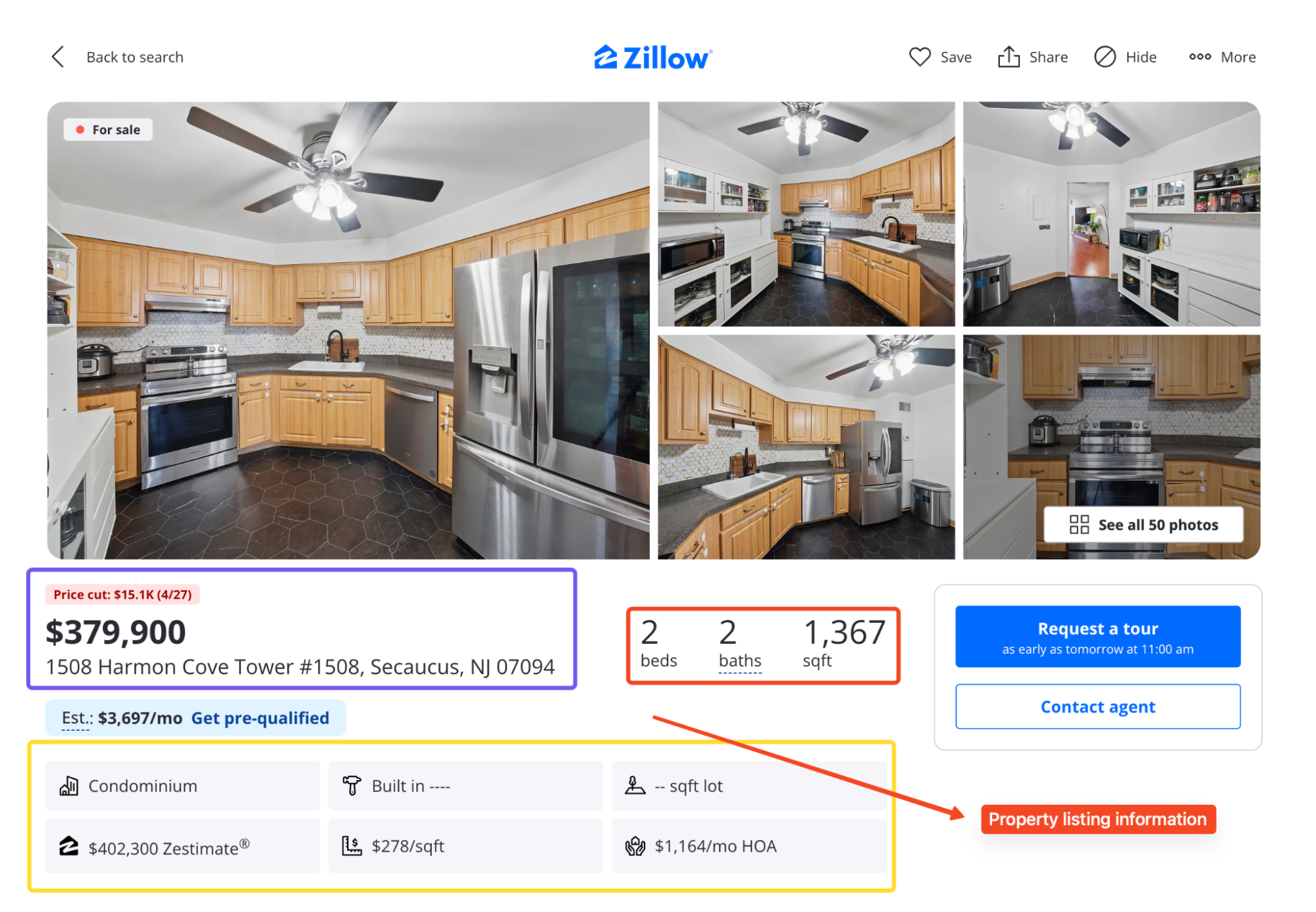
Между обеими страницами вы можете извлечь:
- Цену, адрес, количество спален, ванных комнат, площадь, статус и дни на рынке
- Zestimate и Rent Zestimate
- Фотографии объявлений и имя брокера
- Историю цен и налоговую историю
Зачем скрейпить данные Zillow?
Представьте, что вы можете получить доступ к актуальным объявлениям о недвижимости, ценовым деталям и рыночной аналитике, не открывая вручную сотни страниц Zillow.
В этом и заключается реальная ценность скрейпинга Zillow.
Если вы работаете в сфере недвижимости, инвестиций в недвижимость, маркетинговых исследований, генерации лидов или анализа цен, Zillow имеет полезные публичные данные, которые могут помочь вам быстрее выявлять тенденции.
Что делает Zillow таким сложным для скрейпинга?
Zillow не заходит так далеко, как некоторые платформы, когда речь идет о блокировке ботов, но он все равно создан для блокировки трафика, который не выглядит человеческим.
Большинство скрейперов терпят неудачу по двум причинам. Давайте рассмотрим обе:
Защита PerimeterX
Zillow использует PerimeterX для обнаружения и блокировки ботов в реальном времени. Если ваш скрейпер имеет неправильные заголовки, приходит с IP-адреса с низким доверием или отправляет слишком много запросов слишком быстро, он может быть помечен.
В большинстве случаев эта пометка приводит к головоломке CAPTCHA, которая сломает большинство скрейперов. PerimeterX также проверяет множество сигналов, включая заголовки, поведение браузера, отпечатки TLS, скорость запросов и репутацию IP.
Если трафик ощущается автоматизированным, скрейпер может никогда не достичь фактических данных об объявлениях.
Так что, даже если вы рендерите страницу в headless-браузере, это не гарантирует успех. Вам все равно нужны высококачественные прокси, чистые сессии и реалистичное поведение запросов.
Вот почему я предпочитаю использовать Floppydata Web Unlocker для скрейпинга Zillow.
Неструктурированный HTML и отсутствие стабильных селекторов
Парсинг Zillow также может быть таким же разочаровывающим, как и преодоление его защиты. В исходном коде страницы почти нет согласованных имен классов, идентификаторов или атрибутов данных.
Элементы, которые выглядят простыми, например цена или адрес, обернуты в универсальные теги <div> или вообще не имеют идентификаторов.
Еще хуже то, что имена классов часто меняются и не следуют никакому шаблону. Поэтому вам приходится использовать гибкое сопоставление (например, find() на основе ключевых слов или даже regex) для извлечения данных из необработанных текстовых узлов.
Это делает Zillow одним из самых нестабильных сайтов для скрейпинга, если вы полагаетесь на статические селекторы.
Извлечение информации об объявлениях из Zillow с помощью Python
Для этого руководства я нацелюсь на страницу результатов поиска Бостона в Zillow, которая содержит несколько объявлений о недвижимости. Оттуда мы можем извлечь такие поля, как цена, адрес, количество спален, ванных комнат, площадь, статус и ссылки на объявления.
Примечание: Страницы Zillow часто меняются. Если страница Бостона выглядит иначе к тому времени, когда вы это читаете, перейдите на Zillow, найдите любой город или район, скопируйте URL результатов и замените его в коде.
Давайте начнем с настройки:
Предварительные требования
Перед началом вам понадобятся три вещи:
- Python 3.10 или выше, установленный на вашей машине
- Аккаунт Floppydata с API-ключом для Web Unlocker
- Две библиотеки Python: requests для HTTP-вызовов и beautifulsoup4 для парсинга HTML
Если у вас еще нет аккаунта Floppydata, зарегистрируйтесь на floppydata.com и получите свой API-ключ из панели управления Web Unlocker.
Новые аккаунты поставляются с пятью бесплатными скрейпами, поэтому вы можете следовать всему этому руководству, ничего не платя.
Библиотека requests обычно предустановлена, но вы можете просто выполнить эту команду, чтобы убедиться, что она правильно установлена:
pip install requests beautifulsoup4Как только это будет сделано, создайте новую папку проекта и файл:
mkdir zillow-scraper
cd zillow-scraper
touch zillow_scraper.pyТеперь вы готовы к работе.
Отправка первого запроса
Первое, что пытаются сделать большинство людей, — это обычный Python-запрос. Обычно это выглядит так:
import requests
url = "https://www.zillow.com/boston-ma/"
response = requests.get(url)
print(response.status_code)
print(response.text)Но когда я это протестировал, не потребовалось даже двух попыток, так как мой самый первый запрос вернулся заблокированным. Я получил ответ 403 со страницей блокировки PerimeterX:
403
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<meta name="description" content="px-captcha">
<title>Access to this page has been denied</title>
</head>Вот в чем проблема прямого скрейпинга Zillow. Обычный Python-запрос не ведет себя как реальная сессия просмотра. У него также нет правильного отпечатка браузера, качества IP или рендеринга JavaScript, что позволяет Zillow немедленно его обнаружить и заблокировать запрос.
Вот почему я не строю основной скрейпер вокруг прямых вызовов requests() к Zillow. Вместо этого я отправляю свои запросы через Floppydata Web Unlocker и позволяю ему справляться со сложными частями.
Скрейпинг Zillow с помощью Floppydata Web Unlocker
Давайте отправим запрос на страницу поиска, используя Web Unlocker. Zillow не является самой сложной целью для скрейпинга, но он заботится о репутации IP и поведении браузера.
Вот где появляется Web Unlocker. Он направляет ваш запрос через доверенный резидентный IP, применяет реальный отпечаток браузера и возвращает полностью отрендеренный HTML.
Одна вещь, которая мне действительно нравится в Floppydata, — это то, что вы платите только за успешные запросы. Если скрейп не удается, он не засчитывается в ваше использование.
Панель управления также показывает аналитику запросов в реальном времени, поэтому вы можете отслеживать свое использование, процент успеха и оставшиеся кредиты, не покидая страницу.
Перед написанием любого кода мне нравится сначала протестировать целевой URL в Web Unlocker без кода. Это позволяет мне увидеть HTML ответа перед созданием парсера, чтобы я точно знал, какие селекторы и данные ожидать.
Использование инструмента Web Unlocker буквально так же просто, как ABC. Просто откройте Web Unlocker из вашей панели управления Floppydata. Затем вставьте этот URL «https://www.zillow.com/boston-ma/«, нажмите кнопку Scrape и подождите несколько секунд
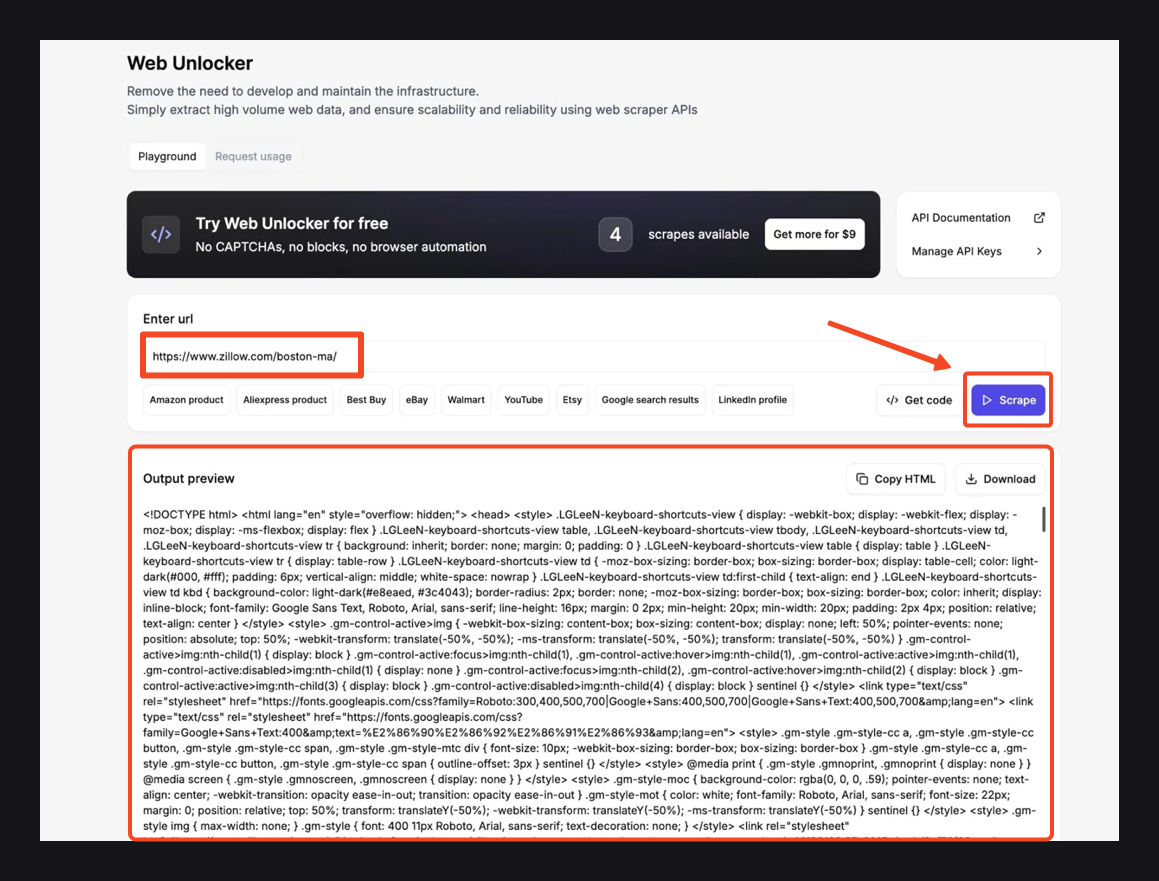
Как только скрейп завершится, проверьте панель Output preview ниже. Вы должны увидеть полный HTML страницы, содержащий наши результаты поиска Zillow.
Если данные выглядят хорошо, используйте Copy HTML, чтобы скопировать их, или Download, чтобы сохранить файл локально.
Понимание структуры пагинации Zillow
Предварительный просмотр вывода вернул необработанный HTML, что полезно, потому что я могу проверить точную структуру перед написанием кода.
Это похоже на открытие инструментов разработчика браузера нажатием F12 и проверку страницы напрямую. В загруженном HTML я обнаружил одну важную вещь, которая значительно упрощает парсер.
Большинство руководств скажут вам захватывать карточки объявлений с помощью CSS-селекторов, но Zillow рендерит только 9 карточек в разметке страницы. Остальные 32 загружаются по мере прокрутки, поэтому скрейпинг с помощью CSS-селекторов пропускает большую часть данных.
Скорее, результаты поиска находятся внутри большого JSON-объекта в HTML страницы. Этот JSON находится внутри этого тега скрипта:
<script id="__NEXT_DATA__" type="application/json">Страница использует этот JSON для загрузки данных на фронтенде, и мы тоже можем его прочитать. Внутри этого JSON объявления находятся по этому точному пути:
data["props"]["pageProps"]["searchPageState"]["cat1"]["searchResults"]["listResults"]Итак, наш план парсинга прост.
Мы найдем скрипт __NEXT_DATA__ с помощью BeautifulSoup, распарсим JSON, перейдем в массив listResults и извлечем нужные нам поля.
Веб-скрейпинг Zillow с Python и Web Unlocker
Теперь мы можем перейти от панели управления к коду.
Фрагмент панели управления использует httpx, но я буду использовать requests здесь, потому что он более знаком большинству читателей Python.
Шаг 1: Настройка запроса
Давайте начнем с базовой конфигурации. Нам нужна конечная точка Web Unlocker, наш API-ключ и целевой URL Zillow:
import requests
import json
from bs4 import BeautifulSoup
API_URL = "https://client-api.floppy.host/v1/webUnlocker"
API_KEY = "YOUR_API_KEY"
SEARCH_URL = "https://www.zillow.com/boston-ma/"
OUTPUT_FILE = "live_zillow_boston.json"Замените YOUR_API_KEY ключом из вашей панели управления Floppydata.
Я использую Бостон в качестве целевого рынка здесь, но если вы хотите скрейпить другой город, просто замените URL поиска.
Шаг 2: Получение страницы через Web Unlocker
Web Unlocker принимает JSON-пакет с целевым URL и несколькими опциями. Он возвращает JSON-ответ, который содержит отрендеренный HTML в поле html:
Теперь я создаю функцию fetch_html() для отправки URL Zillow в Web Unlocker и возврата отрендеренного HTML
def fetch_html(url):
response = requests.post(
API_URL,
headers={
"Content-Type": "application/json",
"X-Api-Key": API_KEY,
},
json={
"url": url,
"country": "US",
"city": "Boston",
"difficulty": "medium",
"expiration": 0,
},
timeout=120,
)
response.raise_for_status()
data = response.json()
html = data.get("html")
if not html:
raise ValueError("Unlocker response did not include an 'html' field.")
return htmlЗдесь происходит несколько вещей. Поля country и city помогают запросу лучше соответствовать целевому местоположению. Я использовал difficulty: «medium», потому что Zillow не является простой статической страницей, поэтому ему нужен более сильный процесс разблокировки.
Поле expiration установлено в 0, поэтому я получаю свежий ответ. После успешного выполнения запроса Web Unlocker возвращает JSON-ответ, и отрендеренный HTML находится в поле html.
Шаг 3: Извлечение объявлений
Теперь мы можем применить план парсинга с ранее. Я создам функцию extract_listings(). Эта функция принимает HTML, находит JSON-данные Zillow и извлекает объявления:
def extract_listings(html):
soup = BeautifulSoup(html, "html.parser")
next_data = soup.find("script", id="__NEXT_DATA__")
if not next_data or not next_data.string:
raise ValueError("Не удалось найти скрипт __NEXT_DATA__ Zillow.")
data = json.loads(next_data.string)
search_state = data.get("props", {}).get("pageProps", {}).get("searchPageState", {})
list_results = (
search_state.get("cat1", {})
.get("searchResults", {})
.get("listResults", [])
)
listings = []
for item in list_results:
listings.append(
{
"zpid": item.get("zpid"),
"address": item.get("address"),
"price": item.get("price"),
"beds": item.get("beds"),
"baths": item.get("baths"),
"sqft": item.get("area"),
"status": item.get("statusType"),
"url": item.get("detailUrl"),
}
)
return listingsИспользуя BeautifulSoup, я могу легко перейти прямо к структурированному JSON внутри страницы. Затем я распарсил содержимое скрипта как JSON и получил массив listResults.
Каждый элемент в listResults — это одно объявление о недвижимости, и из каждого объявления мы можем собрать ценные данные, такие как:
- address (адрес)
- price (цена)
- beds (спальни)
- baths (ванные)
- area (площадь)
- statusType (тип статуса)
- detailUrl (URL деталей)
Я переименовал area в sqft в финальном выводе, потому что так легче понять.
Шаг 4: Сохранение результатов в JSON-файл
Наконец, мы можем добавить функцию main() для запуска скрейпера и сохранения вывода в JSON-файл:
def main():
print(f"Fetching data from: : {SEARCH_URL}")
html = fetch_html(SEARCH_URL)
listings = extract_listings(html)
if not listings:
raise SystemExit("No listings found in Zillow's JSON data.")
with open(OUTPUT_FILE, "w", encoding="utf-8") as file:
json.dump(listings, file, indent=2)
print(f"Found {len(listings)} listings")
print(f"Saved results to {OUTPUT_FILE}")Эта функция получает страницу, извлекает объявления, проверяет, что список не пуст, и сохраняет все в JSON-файл. Как только данные выглядят хорошо, мы можем преобразовать их в CSV позже или использовать данные напрямую в наших приложениях.
Полный скрипт
Вот весь код, который я использовал для успешного извлечения моих объявлений Zillow:
from bs4 import BeautifulSoup
import requests
import json
API_URL = "https://client-api.floppy.host/v1/webUnlocker"
API_KEY = "Your_API_KEY"
SEARCH_URL = "https://www.zillow.com/boston-ma/"
OUTPUT_FILE = "live_zillow_boston.json"
def fetch_html(url):
response = requests.post(
API_URL,
headers={
"Content-Type": "application/json",
"X-Api-Key": API_KEY,
},
json={
"url": url,
"country": "US",
"city": "Boston",
"difficulty": "medium",
"expiration": 0,
},
timeout=120,
)
response.raise_for_status()
data = response.json()
html = data.get("html")
if not html:
raise ValueError("Unlocker response did not include an 'html' field.")
return html
def extract_listings(html):
soup = BeautifulSoup(html, "html.parser")
next_data = soup.find("script", id="__NEXT_DATA__")
if not next_data or not next_data.string:
raise ValueError("Could not find Zillow's __NEXT_DATA__ script.")
data = json.loads(next_data.string)
search_state = data.get("props", {}).get("pageProps", {}).get("searchPageState", {})
list_results = (
search_state.get("cat1", {})
.get("searchResults", {})
.get("listResults", [])
)
listings = []
for item in list_results:
listings.append(
{
"zpid": item.get("zpid"),
"address": item.get("address"),
"price": item.get("price"),
"beds": item.get("beds"),
"baths": item.get("baths"),
"sqft": item.get("area"),
"status": item.get("statusType"),
"url": item.get("detailUrl"),
}
)
return listings
def main():
print(f"Fetching data from: {SEARCH_URL}")
html = fetch_html(SEARCH_URL)
listings = extract_listings(html)
if not listings:
raise SystemExit("No listings found in Zillow's JSON data.")
with open(OUTPUT_FILE, "w", encoding="utf-8") as file:
json.dump(listings, file, indent=2)
print(f"Found {len(listings)} listings")
print(f"Saved results to {OUTPUT_FILE}")
if __name__ == "__main__":
main()Если все настроено правильно, вы должны увидеть вывод, подобный этому:
[
{
"zpid": "59174136",
"address": "45 Garden St APT 3, Boston, MA 02114",
"price": "$685,000",
"beds": 2,
"baths": 1,
"sqft": 525,
"status": "FOR_SALE",
"url": "https://www.zillow.com/homedetails/45-Garden-St-APT-3-Boston-MA-02114/59174136_zpid/"
}
]На этом этапе ваш скрейпер работает, что означает, что теперь вы можете скрейпить ключевую информацию из любого объявления Zillow.
Устранение распространенных проблем
Если вы часто скрейпите данные о недвижимости Zillow, вы обязательно столкнетесь с некоторыми препятствиями. Я сам столкнулся с парой из них. Поэтому я могу сказать вам, чего ожидать, включая:
- Ошибки 403: Это означает, что Zillow заблокировал вашего бота. Попробуйте изменить заголовки или использовать прокси для продолжения скрейпинга данных Zillow.
- Пустые ответы: Это может быть связано с рендерингом JavaScript. Попробуйте использовать инструмент, который полностью рендерит страницу перед возвратом HTML, например Web Unlocker.
- Отсутствующие данные: Не все объявления имеют одинаковую информацию. Всегда используйте .get() при извлечении данных Zillow, чтобы ваш скрейпер не ломался на отсутствующем ключе.
Поскольку Zillow не предлагает бесплатный API, вам придется найти способ обойти это. Если вам нужен надежный способ доступа к данным объявлений Zillow, Floppydata Web Unlocker — ваш лучший выбор.
Заключение
Zillow не выглядит как сайт с высокой безопасностью, но он защищен PerimeterX и многоуровневой системой обнаружения, которая отслеживает ваш IP, заголовки, отпечаток TLS и поведенческие сигналы. Подозрительное поведение приведет к пометке и бессрочному бану.
Следовательно, вам нужно быть осторожным при скрейпинге. Вот где появляется Floppydata Web Unlocker. Он:
- Ротирует премиальные резидентные прокси
- Ротирует заголовки и реальные отпечатки браузера
- Загружает чистый и полный HTML каждый раз
- Выставляет счета только за успешные ответы
С этой настройкой вам не нужно бороться с анти-ботовой системой Zillow самостоятельно; пусть Floppydata Web Unlocker поможет вам. Начните скрейпить Zillow прямо сейчас с 5 бесплатными скрейпами.





