

Благодаря своей производительности, экосистеме и многопоточности Java идеально подходит для создания быстрых и масштабируемых конвейеров скраппинга. Такие инструменты, как jsoup, хорошо работают со статическим HTML, но современные веб-сайты полагаются на системы защиты от ботов, CAPTCHA, прокси и рендеринг JavaScript, что делает автономный Java-скрепинг ненадежным. В 2026 году лучший подход — использовать Java в качестве управляющего слоя (запросы, парсинг, логика) и полагаться на API для скраппинга, например Floppydata, для обработки инфраструктуры, разблокировки запросов и надежного масштабирования.
Почему веб-скраппинг на Java — это мощный выбор
Java — надежный выбор для веб-скраппинга благодаря своей скорости, масштабируемости и поддерживающей инфраструктуре. Я пробовал использовать для скраппинга Python, Go и NodeJS, но Java всегда оказывалась намного лучше при выполнении заданий по скраппингу на уровне производства. Python отлично подходит для парсинга и манипулирования данными благодаря своим обширным библиотекам для работы с данными, но Java хорошо подходит для обработки статического HTML.
Я предпочитаю Java для выполнения работ по веб-скрейпингу в производственных масштабах, потому что:
- Скорость: Java быстрее интерпретируемых языков, таких как Python.
- Экосистема: Вы можете подключать профессиональные инструменты, такие как Apache HttpClient и базы данных.
- Многопоточность: Java ExecutorService упрощает многопоточную обработку данных.
Для Java-бэкендов, которые хотят построить полноценную систему скраппинга, библиотека jsoup от Java — отличный вариант. Вы можете извлекать HTML и XML-контент с веб-страниц и дорабатывать его с помощью библиотек Java для работы с данными, не прибегая к дополнительным инструментам для анализа данных.
Многие известные инструменты для сбора данных электронной коммерции используют jsoup для отслеживания продуктов и ключевых слов конкурентов путем развертывания крупномасштабных заданий автоматизации с помощью Java и jsoup.
Необходимая инфраструктура Java для веб-скрапинга
Java имеет развитую экосистему и поддерживает тысячи библиотек и интеграций. Ключевыми библиотеками, поддерживающими веб-скраппинг, являются jsoup, Apache, Jackson, Gson и другие библиотеки для работы с данными. Java также поддерживает запросы к базам данных внутри кода через JDBC.
Jsoup: Библиотека для веб-скрапинга на Java
Jsoup — это основа веб-скраппинга с помощью Java (для веб-страниц HTML). Jsoup предоставляет вам CSS-подобный синтаксис селектора, который помогает вам извлекать все виды HTML-контента из извлеченного документа.
Jsoup работает быстро, имеет простой синтаксис и самостоятельно обрабатывает битые ссылки.
Пример кода:
Document doc = Jsoup.parse(html);
String title = doc.select("title").text();
String price = doc.select(".price").text();Если вы хотите распарсить страницу, вам нужно сначала получить ее. Java сама по себе не загружает веб-страницы. Вам нужен HTTP-сервер, чтобы сделать запрос на определенную веб-страницу, а затем веб-сервер отвечает содержимым веб-страницы. Это то, что вы передаете jsoup, чтобы начать извлекать данные.
Вы также можете использовать собственные HTTP-методы Java вместо Apache HttpClient, но это не так масштабируемо. Apache обрабатывает тайм-ауты сессий, повторные попытки, а также агенты пользователя и cookies.
Jackson and Gson
Jackson и Gson — это две разные Java-библиотеки. Эти библиотеки помогают преобразовать необработанный извлеченный текст в чистые данные, такие как цены на товары с названиями или цены на товары в определенных категориях с сайта электронной коммерции. Jackson лучше справляется с большими автоматическими операциями по скраппингу, чем Gson, который предназначен для небольших и легких задач.
Каковы недостатки использования Java для веб-скрапинга?
Теперь, когда вы немного поняли возможности Java в области скраппинга, давайте обсудим, где она вас подведет. В 2026 году вы не сможете полагаться только на такие библиотеки, как jsoup и Apache HttpClient, для выполнения масштабируемых заданий по скраппингу.
Есть две фундаментальные проблемы, с которыми вы столкнетесь, если будете заниматься скраппингом исключительно на Java:
- Сайты блокируют вас: Сайты теперь более оборонительны. Им небезразлично, является ли посетитель их сайта настоящим человеком или просто ботом, создающим лишнюю нагрузку на сервер и извлекающим данные о клиенте без разрешения. Сайты больше не любят скреперов.
- JS-тяжелые страницы не могут быть извлечены: Jsoup и другие фреймворки для извлечения отлично работают с HTML-страницами. Сюда можно отнести страницы товаров и другие веб-страницы электронной коммерции/блогов, но многие сайты начали размещать фрагменты кода JavaScript, чтобы добавить анимацию и сложные визуальные элементы на сайт. Jsoup не предназначен для извлечения страниц, содержащих JS, поэтому извлечение не удается или возвращает нерелевантные результаты.
Обе эти проблемы решаемы. Веб-скреперы используют различные стратегии и фреймворки, чтобы избежать блокировки со стороны веб-сайтов и легко собирать данные страницы с большим количеством JS. Однако этот процесс не так прост, как выполнение нескольких строк кода jsoup и Apache.
Современный способ веб-скрапинга на Java
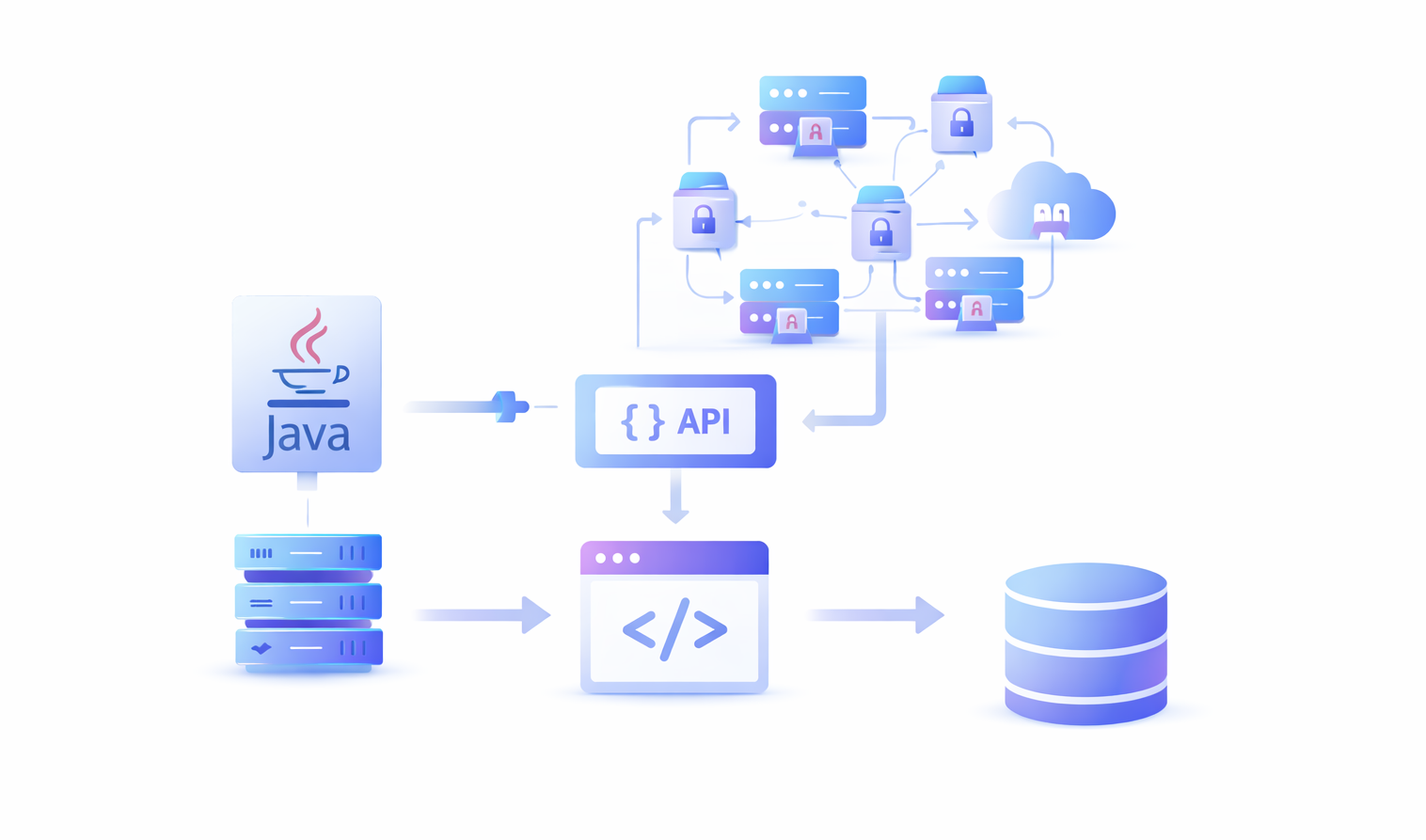
Автономных библиотек Java будет недостаточно для веб-скрапинга в 2026 году. Мы больше не имеем дело со статичными HTML-страницами. Мы имеем дело с системами защиты от ботов, CAPTCHA, редиректами, cookies, анимацией дизайна на основе JavaScript, макетами текста и многим другим.
Чтобы создать успешную и масштабируемую автоматизацию скраппинга, необходимо сочетать Java с другими новейшими технологиями скраппинга. Вот список ключевых вещей, необходимых наряду с Java-кодом для успешной автоматизации веб-скрепинга:
- Пул прокси-серверов: Веб-сайты отслеживают каждого посетителя по IP-адресу. Когда сетевая стена, такая как Cloudflare, обнаруживает, что пользователь извлекает данные, первое, что она делает, — блокирует IP-адрес от доступа к сайту. Вот почему вам нужен пул безопасных прокси-серверов и Java-логика для переключения прокси-серверов каждые несколько запросов, чтобы избежать запрета.
- CAPTCHA Solver: CAPTCHA существуют для того, чтобы вытеснить ботов с платформы. Традиционные скреперы не могут решить CAPTCHA. Хардкодить решатель CAPTCHA на Java или любом другом языке практически невозможно. Вот почему вам нужен сторонний решатель CAPTCHA.
- Профили отпечатков пальцев устройств: Такие платформы, как Facebook и LinkedIn, используют еще более совершенные системы обнаружения. Эти системы не просто используют IP-адреса для выявления потенциальных сигналов о краже, они отслеживают отпечатки пальцев устройств, поведение пользователей, переходы через прокси-серверы и привязку аккаунтов. Вот почему вам необходимо менять отпечатки пальцев браузера вместе с прокси-серверами, чтобы избежать блокировки вашего устройства на платформе.
- Инструменты для извлечения тяжелых JS-файлов: Даже если вы обойдете все системы обнаружения, многие современные веб-страницы разработаны с использованием тяжелых JavaScript-фреймворков, таких как ReactJS и NextJS. Такие инструменты, как jsoup и другие традиционные скреперы, не могут извлечь контент с таких страниц. Вам понадобится дополнительный инструмент для преобразования JS в HTML.
Скрапинг на Java не умер. Он по-прежнему очень полезен, если вы добавите собственную инфраструктуру, например прокси-серверы, решатели CAPTCHA и конвертеры JS-страниц. Или же самый идеальный способ избежать всех этих интеграций — использовать API веб-скрапера, например Floppydata.
Руководство: Как делать веб-скраппинг с помощью Java в 2026 году
В 2026 году Java должна использоваться для поддержки инфраструктуры веб-скрейпинга путем обработки запросов, организации исходных данных, разбора исходных данных на структурированные и пригодные для использования данные, а также для обработки других побочных ситуаций и логики, таких как ротация прокси, повторные попытки, печать сообщений, предупреждения и многое другое.
Если вы пытаетесь скреативить современные веб-страницы с помощью jsoup, то в 40%-50% случаев у вас ничего не получится. Однако Java следует использовать для скорости, интеграции и многопоточности, а не для библиотеки jsoup.
Итак, когда вы будете готовы использовать Java в качестве управляющего слоя для вашего скрепера, давайте погрузимся в самый простой и самый эффективный метод веб-скрепинга в 2026 году.
Шаг 1: Получите Web Scraper API
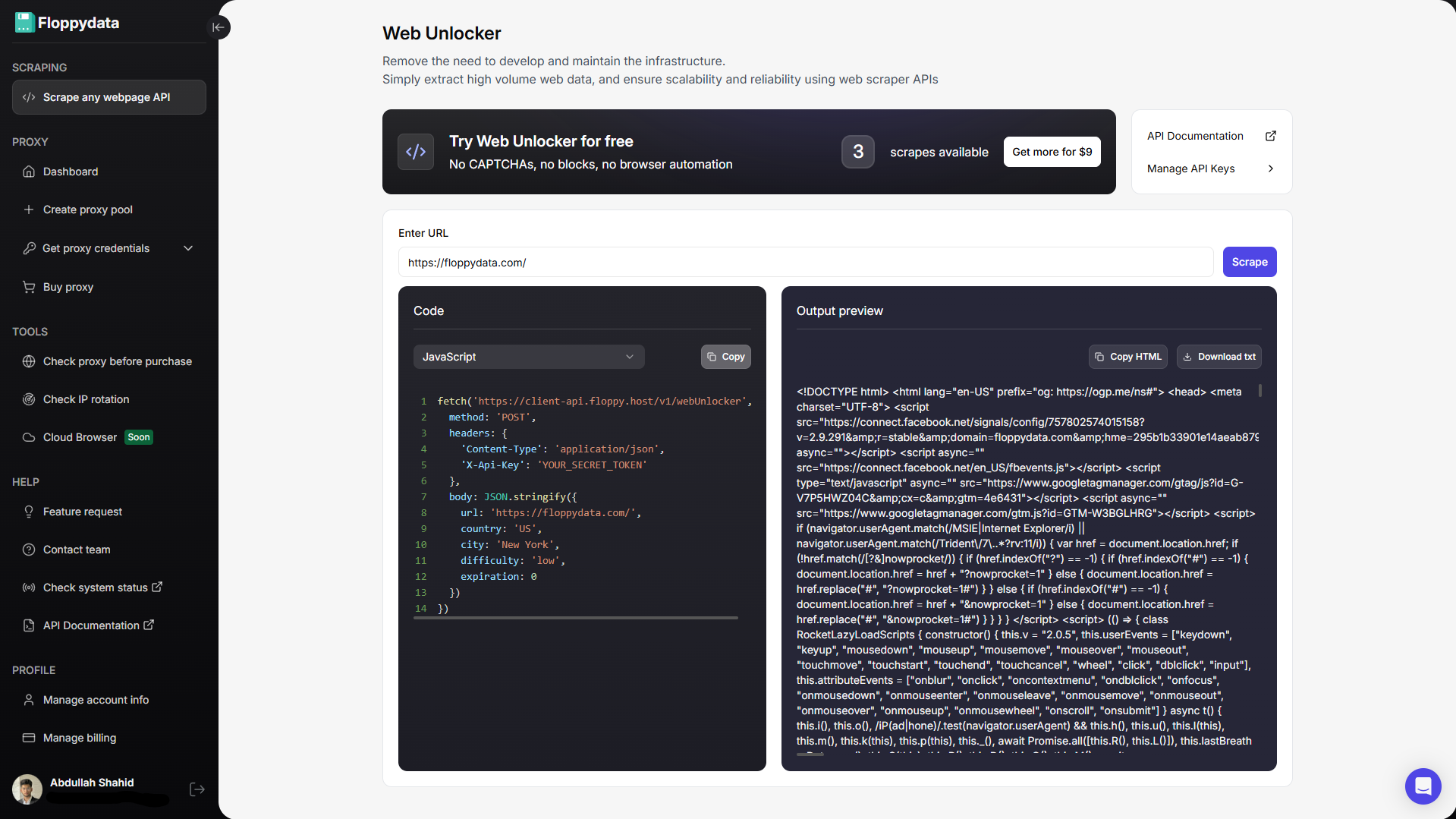
Вместо того чтобы пытаться использовать Java-скрейпер, воспользуйтесь надежным веб-скребком API. API веб-скрапера получает URL вашей веб-страницы, отправляет на нее запрос, обрабатывает CAPTCHA, преобразует веб-страницу в сырые данные и возвращает их обратно. API веб-скрапера берет на себя всю тяжесть работы с HTTP-сервером, повторными попытками, CAPTCHA, ошибками, плохой полезной нагрузкой, вращающимися прокси и отпечатком устройства.
На Java вы пишете остальную инфраструктуру конвейера, например, создаете многопоточные очереди ссылок для изучения, извлекаете полезные теги из HTML-контента и сохраняете их в структурированном виде, или выполняете другие функции поверх извлеченных данных.
Вы можете прочитать наш обзор лучших сервисов для скраппинга, чтобы выбрать наиболее подходящий для вашего случая.
Шаг 2: Добавление ключа API в сниппет кода Java
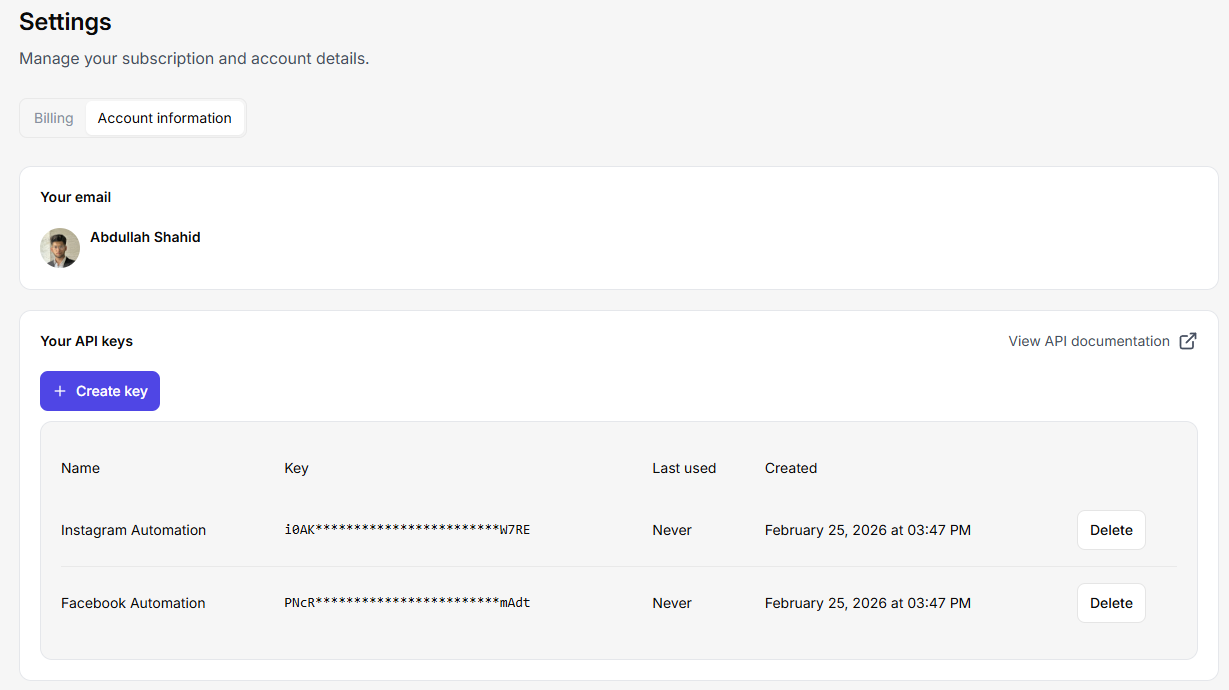
Получите API-ключ от вашего сервиса веб-скраппера. Давайте интегрируем его в Java. Вы можете создать несколько API-ключей во Floppydata, перейдя в настройки > аккаунта > кнопки «Создать ключ». Вы можете отправлять сотни одновременных запросов к этому API и создать многопоточную работу по скраппингу, которая обрабатывает тысячи веб-страниц одновременно.
Поскольку Floppydata выполняет задания по скраппингу в облаке, вы также снимаете с себя всю нагрузку по открытию веб-браузера и запуску библиотек скраппинга с вашего устройства. Если бы вы сами управляли всей инфраструктурой скрапбукинга, вам бы потребовалось много оперативной памяти и вычислительной мощности.
Клиентский API Floppydata использует заголовок X-Api-Key, а документированная конечная точка Web Unlocker принимает url и дополнительные параметры, такие как страна, город, сложность и срок действия кэша. Ответ содержит HTML-содержимое, которое можно разобрать на Java.
Вот пример фрагмента кода, который я предпочитаю использовать:
public class Floppydatascraper {
public static void main(String[] args) throws Exception {
String apiKey = System.getenv("FLOPPY_API_KEY");
String payload = """
{
"url": "https://example.com",
"country": "US",
"difficulty": "medium",
"expiration": 0
}
""";
HttpClient client = HttpClient.newBuilder()
.connectTimeout(Duration.ofSeconds(20))
.build();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://client-api.floppy.host/v1/webUnlocker"))
.header("X-Api-Key", apiKey)
.header("Content-Type", "application/json")
.POST(HttpRequest.BodyPublishers.ofString(payload))
.build();
HttpResponse<String> response =
client.send(request, HttpResponse.BodyHandlers.ofString());
System.out.println(response.body());
}
}Шаг 3: Усовершенствуйте конвейер Java-скрапинга
Теперь, когда у вас есть интегрированный API-ключ, постройте на его основе системы сбора данных. Например, если у вас есть инструмент для электронной коммерции, который исследует Amazon на предмет релевантных товаров по целевому ключевому слову, извлеките их название, теги, описание и т. д. и покажите их пользователю. Scraper API — это лучший и наиболее масштабируемый подход. Даже если у вас тысячи клиентов, посылающих одновременные запросы к вашему приложению, Floppydata API легко справится с ними.
Вы можете добавить дополнительные функции к полученным данным, например, использовать ключ AI API для написания похожего описания и заголовка, или проанализировать похожие ключевые слова из всех извлеченных результатов и т. д. Вся эта инфраструктура должна быть построена на Java.
Headless-браузинг в Java без использования Selenium и Puppeteer
Обычно скрейперы используют Selenium и Puppeteer для работы с headless-браузерами, управления прокси и реализации логики сбора данных. Однако этот процесс тяжелее, медленнее и ломается в производстве под большой нагрузкой, поскольку требуется масштабируемая облачная инфраструктура для обработки растущих запросов. В итоге вы тратите время на создание инфраструктуры, которую можно получить от этих чрезвычайно дешевых API для скраппинга, таких как Floppydata. Более того, эти инструменты проверены на надежность и масштабируемость и постоянно развиваются вместе с рынком, так что вам не придется менять свой конвейер каждые 4 месяца.
Для работы с Floppydata API вам понадобятся:
- не нужно управлять локальным браузером
- не нужен пул headless-браузеров
- не требуется поддержка Selenium
- не нужна настройка Puppeteer
- достаточно Java для запросов и парсинга HTML
И все это за $0,45-$0,9/1 тыс. успешно отсканированных результатов. Это дешевле, чем содержать собственные облачные машины. Смотрите подробную информацию о ценах.
Заключительные мысли
Если бы сегодня меня попросили построить систему сбора данных для веб-скреппинга на Java, это заняло бы от 20 до 30 минут. Я бы получил API-ключ Floppydata и составил требования к конвейеру, включая то, что я хочу делать с полученными данными и как их хранить. Затем я использую Claude Code для создания надежного трубопровода. Поскольку я не создаю никакой инфраструктуры для скраппинга, я могу быстро проверить, работает ли мой конвейер, запустив этот сценарий.
Java — отличный выбор для создания масштабируемых, многопоточных систем веб-скрейпинга, даже несмотря на свои ограничения. Но в 2026 году у базовых библиотек для веб-скрейпинга не будет шансов против систем защиты от ботов на основе искусственного интеллекта, которые платформы развертывают, чтобы не допустить проникновения скреперов. Для успешной автоматизации скраппинга вам нужен такой же современный и мощный инструмент.






