


Веб-скраппинг Reddit — это процесс сбора общедоступных данных на платформе. Собранные данные могут включать посты, профили, комментарии и многое другое. Ручной сбор данных Reddit может отнимать много времени, приводить к ошибкам и быть неэффективным. Поэтому исследователи, маркетологи и SEO-специалисты часто автоматизируют сбор данных с Reddit с помощью ботов или скриптов. Для управления несколькими аккаунтами Reddit может потребоваться использование прокси. Чтобы облегчить извлечение данных, Reddit имеет публичный API. Однако ваши возможности очень ограничены, когда вы парсите Reddit с помощью API по нескольким причинам. Во-первых, API имеет ограничения по скорости, что ограничивает количество запросов, которые вы можете отправить за определенный промежуток времени. Кроме того, часто требуется аутентификация, что может замедлить весь процесс.
Как работает скрапер Reddit?
Чтобы собрать данные с Reddit, скрепер отправляет HTTP-запросы на платформу. На следующем этапе происходит разбор HTML или JSON-ответов. Затем извлекаются необходимые элементы, такие как идентификатор пользователя или комментарии. Наконец, извлеченные данные очищаются и сохраняются в заранее заданном формате. К общедоступным данным, которые можно собирать на Reddit, относятся:
- Названия постов
- Имена пользователей
- Комментарии (темы и ответы)
- Баллы (upvotes и downvotes)
- Метаданные субреддита
- Временные метки и история правок
Некоторые из проблем, связанных с использованием скраппера Reddit, включают CAPTCHA, блокировку IP-адресов, вложенные секции комментариев и ограничения скорости. Именно здесь оптимизированные инструменты играют решающую роль, выводя вашу деятельность по скраппингу на новый уровень.
Где купить Reddit Scraper
Скреперы можно разделить на 2 (две) группы — кодовые и бескодовые скреперы. Кодовые скреперы используют язык программирования, такой как Python, CSS, Java и т. д., для создания скрипта, который автоматизирует извлечение данных. Этот вариант требует определенных навыков кодирования и технических знаний для написания кода, который может обойти CAPTCHA и ограничения скорости для эффективного извлечения данных. Вы также можете написать скрипт для скрапера изображений Reddit, если цель состоит только в извлечении изображений на странице.
С другой стороны, вариант без кода — это решение, которое не требует кодирования или широкого понимания языков программирования. Для тех, кто ищет простой вариант, как собрать данные Reddit, пригодятся инструменты без кода. Они оснащены различными функциями, которые позволяют извлекать данные с таких платформ, как Reddit, за несколько шагов. Одним из самых надежных мест, где можно получить это решение без кода, является Floppydata. Этот инструмент оптимизирует процесс получения данных с Reddit благодаря функциям, позволяющим обходить CAPTCHA и IP-запреты. Инструмент Web Unblocker от Floppydata отлично подходит для масштабирования больших объемов данных без использования таких браузеров автоматизации, как Selenium, Puppeteer или Playwright.
Floppydata’s Web Unblocker — это инструмент, который упрощает веб-скраппинг, автоматически обходя блоки и CAPTCHA, позволяя вам собирать данные без необходимости автоматизации браузера или ручной настройки прокси. Некоторые из его функций включают:
- Автоматизированное решение проблемы CAPTCHA
- Обход механизмов защиты от ботов с помощью усовершенствованной системы «отпечатков пальцев» браузера
- Эффективное извлечение данных из динамических веб-сайтов
- Встроенная автоматическая ротация прокси-серверов и логика повторных попыток позволяют сохранять анонимность.
Еще один момент, который следует учитывать при покупке скрепера, — это цена. Floppydata стремится предоставлять высококачественные решения по доступным ценам. Поэтому Floppydata предлагает свой Web Unblocker по очень выгодным ценам. Хотя есть бесплатная пробная версия, она ограничена 5 (пятью) скрепами. Существует четыре ценовых уровня, которые включают в себя:
- План роста — от $0,98 за 1 тыс. результатов
- Профессиональный план — от $0,75 за 1 тыс. результатов
- Бизнес-план — от $0,60 за 1 тыс. результатов
- Премиум-план — от $0,45 за 1 тыс. результатов
- Индивидуальный план — обратитесь в службу поддержки для получения индивидуального плана.
Плюсы бескодового скрепера Floppydata
- Нетехнические пользователи могут с легкостью использовать его
- Поставляется со встроенными функциями, которые обрабатывают ротацию IP-адресов, CAPTCHA и динамическое содержимое.
- Передача данных в форматах CSV или JSON для удобства обработки
- Экономически эффективные варианты для частных лиц и малых и средних предприятий
- Быстрая доставка данных
Минусы
- Ограниченная гибкость в настройке
Другие альтернативы скраппингу данных Reddit
Давайте кратко проанализируем другие методы, которые можно использовать для поиска данных Reddit:
Официальный API Reddit
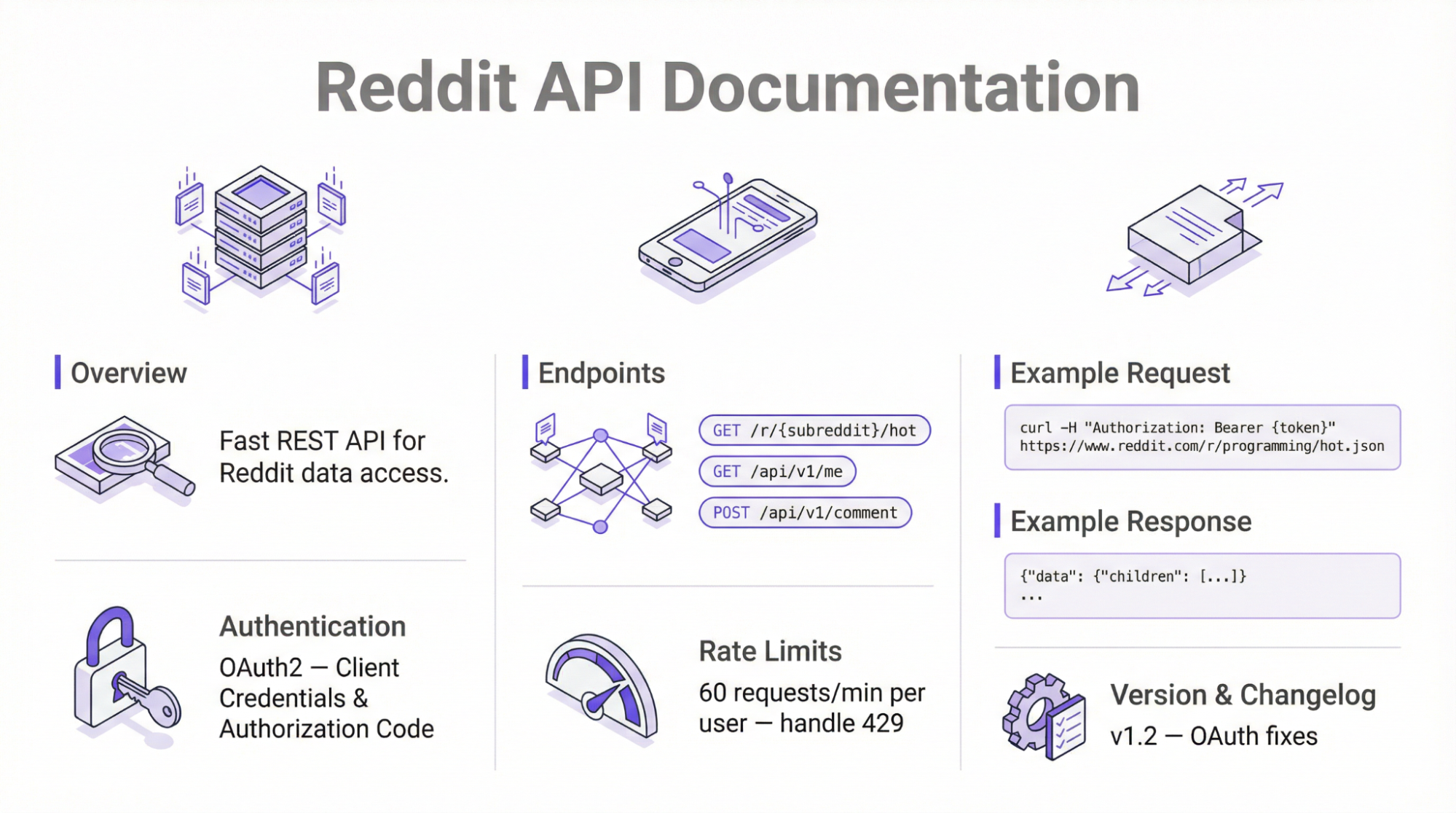
Если вы хотите скреативить платформу без сторонних инструментов, то вам следует рассмотреть возможность использования официального API. Этот подход использует конечные точки JSON API Reddit для сбора общедоступной информации с помощью простых HTTP-запросов.
Использование официального API требует аутентификации OAuth2 и вводит ограничения по скорости — 100 QPM для бесплатного уровня. Согласно обновлениям политики, выпущенным в 2025 году, API требует ручного одобрения со стороны платформы перед получением данных.
Чтобы использовать официальный API Reddit для сбора данных, выполните следующие действия:
- Зарегистрируйтесь, чтобы получить доступ к API
Первым делом войдите в свою учетную запись Reddit или создайте ее, если вы новый пользователь. Перейдите на страницу Reddit Apps, нажмите на кнопку «Создать приложение» и следуйте инструкциям на экране. После этого появится новое окно с идентификатором клиента, секретом клиента и строкой агента пользователя.
- Аутентификация
Используйте OAuth для получения маркера доступа. Для этого шага вы можете использовать библиотеку программирования, например библиотеку PRAW в Python, и пройти аутентификацию в API. В качестве альтернативы можно использовать библиотеку запросов , что предполагает ручную работу с маркерами доступа.
- Выполнение HTTP-запросов
Следующий шаг — использование фреймворка, например библиотеки запросов Python, для отправки GET-запросов к различным конечным точкам.
- Разбор и сохранение данных
Исходные данные извлекаются и обрабатываются в формате JSON для удобства чтения.
N.B.: Описанный выше процесс эффективен только для простых задач скрапинга. Кроме того, он требует хорошего знания языков программирования и кодирования.
Плюсы официального API Reddit
- Он обеспечивает официальный и надежный доступ к серверам Reddit для сбора данных
- Это жалоба на условия использования платформы
- Минимальный риск запретов при условии, что вы не превысите лимит тарифов.
- Поддерживает извлечение общедоступных данных без ограничений, препятствующих скрапингу.
Минусы официального API Reddit
- Данные очень ограничены
- Не подходит для тех, кто практически не умеет кодировать.
- Ограничения по тарифам затрудняют масштабирование процесса скрапбукинга
- Извлечение данных в больших объемах может быть весьма дорогостоящим
Использование Python

Python — это язык программирования с обширной библиотекой, поддерживающей веб-скраппинг. Для скраппинга Reddit большинство разработчиков используют PRAW (Python Reddit API Wrapper), чтобы взаимодействовать с сервером для извлечения данных.
Однако для извлечения данных, выходящих за рамки API, используются фреймворки вроде BeautifulSoup. Они также играют важную роль в разборе HTML-данных и предоставлении их в формате XML или JSON.
Структура Reddit часто меняется, что может повлиять на работу скрепера. Поэтому скрепер необходимо регулярно обновлять, чтобы адаптировать его к изменениям на платформе.
Лучшие практики использования Python Reddit scraper
Поворот IP-адреса
Одной из основных целей ротации IP-адресов является обеспечение анонимности. Кроме того, платформа может обнаружить, когда повторные запросы поступают с одного и того же IP-адреса. Это может привести к запрету IP-адреса, что затрудняет сбор данных.
Обработка CAPTCHA
Скрепер Python Reddit не приспособлен для работы с CAPTCHA, которые могут появляться в качестве способа, позволяющего платформе отличать действия человека от действий бота. Чтобы обойти CAPTCHA, используйте безголовые браузеры, такие как Selenium, Playwright и Puppeteer, чтобы имитировать человеческую модель просмотра. Впоследствии это усложняет обнаружение автоматических действий.
Используйте безголовые браузеры для работы с динамическим контентом
Как и современные сайты, Reddit использует JavaScript для загрузки динамического содержимого. Обычные скреперы обычно анализируют только HTML-контент и могут быть не в состоянии загрузить динамическое содержимое. Одним из способов решения этой проблемы является интеграция безголовых браузеров, таких как Selenium
Плюсы использования Python
- Поскольку это библиотека с открытым исходным кодом, она бесплатна.
- Высокая настраиваемость
- Надежный
Минусы использования Python-скреперов
- Требуется знание программирования на языке Python
- Ограничено публичными данными
- Ограничено лимитами API Reddit
Примеры использования данных Reddit
Веб-скреппинг Reddit обеспечивает доступ к данным, которые можно использовать в различных целях. К наиболее распространенным вариантам использования относятся:
Исследование рынка
Многие специалисты собирают данные Reddit для проведения маркетинговых исследований. Собранная информация может быть отсортирована и проанализирована, чтобы понять настроения на рынке, текущие тенденции и репутацию различных брендов. Таким образом, данные могут быть интерпретированы в решения, влияющие на рекламу, упаковку и ценообразование продукта, которые соответствуют целевому рынку.
Финансовый анализ
Большинство людей даже не подозревают, что на Reddit существует целое сообщество финансовых экспертов. На Reddit собрано огромное количество информации по финансовым темам, касающимся акций, долей, криптовалюты и международных рынков. Финансовый анализ необходим перед осуществлением значительных инвестиций, чтобы минимизировать риск потерь. Эти данные можно извлечь, проанализировать и интерпретировать, чтобы понять прогноз рынка и принять обоснованные финансовые решения.
ИИ и машинное обучение
Данные с Reddit можно использовать для обучения LLM (Large Language Models), чтобы улучшить результаты поиска, управляемого ИИ. ИИ-боты могут работать только в том объеме, в котором они получают данные. Поэтому ежедневное большое количество посетителей Reddit делает его идеальным источником данных. В качестве примера можно привести собственный ИИ Reddit — LLM, который получает данные с платформы, чтобы создавать персонализированные страницы для каждого посетителя.
Социальные исследования
Еще один вариант использования данных Reddit — социальные исследования. Сбор данных о сабреддитах можно использовать для изучения моделей взаимодействия между людьми. Социальные исследования могут быть использованы для сбора данных о тенденциях и мнениях по таким темам, как конфиденциальность и согласие в Интернете. Кроме того, эти данные можно использовать для обучения чат-ботов круглосуточной поддержке, которая может быть невозможна при использовании человеческих агентов поддержки.
Как собрать данные с Reddit с помощью Web Unblocker от Floppydata
Использовать Web Unblocker от Floppydata для сбора данных с Reddit очень просто, и сделать это можно всего за несколько шагов. Вот пошаговое руководство о том, как собрать данные Reddit с помощью Floppydata.
Давайте начнем!
Шаг 1: Посетите страницу Web Unblocker и войдите в систему, чтобы начать работу
Шаг 2: Войдите в свою учетную запись Reddit. Откройте страницу результатов поиска с определенными фильтрами, соответствующими вашему сценарию использования.
Шаг 3: Перейдите на панель управления Floppydata’s Web Unblocker и вставьте URL-адрес
Шаг 4: Ваши результаты будут готовы через несколько минут.
Заключение
Изучение того, как собирать данные с Reddit, может стать мощным подспорьем для исследователей, частных лиц и компаний. Это способ собрать информацию из одного из крупнейших глобальных сообществ в Интернете. Чтобы собрать эти данные, вы можете написать скрипт на языке программирования или использовать решение без кода.
Floppydata предлагает комплексное решение для скраппинга без кода — Web Unblocker, которое эффективно извлекает данные с Reddit и предоставляет их в удобном для вас формате. Новые пользователи получают до 5 бесплатных сессий для сбора данных с любой платформы.
Если вы хотите легко и без проблем работать с данными Reddit, воспользуйтесь программой Floppydata’s Web Unblocker уже сегодня!





