

O Java é ideal para a criação de pipelines de raspagem rápidos e dimensionáveis graças ao seu desempenho, ecossistema e multi-threading. Ferramentas como jsoup funcionam bem para HTML estático, mas os sites modernos dependem de sistemas antibot, CAPTCHAs, proxies e renderização de JavaScript, o que torna a raspagem autônoma em Java pouco confiável. Em 2026, a melhor abordagem é usar o Java como sua camada de controle (solicitações, análise, lógica) e contar com uma API de raspagem como a Floppydata para lidar com a infraestrutura, desbloquear solicitações e dimensionar de forma confiável.
Por que o Web Scraping em Java é uma opção poderosa
O Java é uma opção sólida para raspagem da Web devido à sua velocidade, escalabilidade e infraestrutura de suporte. Já experimentei Python, Go e NodeJS para raspagem, mas o Java sempre se mostrou muito melhor para lidar com trabalhos de raspagem em nível de produção. O Python é excelente para análise e manipulação de dados devido às suas extensas bibliotecas de manipulação de dados, mas o Java se destaca por sua raspagem estática de HTML.
Eu prefiro Java para trabalhos de raspagem em escala de produção por causa de:
- Velocidade: Java é mais rápido do que linguagens interpretadas como Python.
- Ecossistema: Você pode conectar ferramentas profissionais como o Apache HttpClient e bancos de dados.
- Multi-threading: O ExecutorService do Java simplifica a raspagem com vários threads.
Para back-ends Java que desejam implantar um sistema de raspagem maduro, a biblioteca jsoup do Java é uma ótima opção. Você pode extrair conteúdo HTML e XML de páginas da Web e refiná-lo usando as bibliotecas de manipulação de dados do Java sem precisar de ferramentas adicionais para análise de dados.
Muitas ferramentas famosas de raspagem de dados de comércio eletrônico usam o jsoup para rastrear produtos e palavras-chave da concorrência, implantando trabalhos de automação em grande escala via Java e jsoup.
Infraestrutura Java essencial para raspagem da Web
O Java tem um ecossistema maduro e oferece suporte a milhares de bibliotecas e integrações. As principais bibliotecas que oferecem suporte à raspagem da Web são jsoup, Apache, Jackson, Gson e outras bibliotecas de manipulação de dados. O Java também oferece suporte a consultas a bancos de dados no código via JDBC.
Jsoup: A biblioteca de raspagem da Web do Java
O Jsoup é a espinha dorsal da coleta de dados da Web com Java (para páginas da Web em HTML). O Jsoup fornece uma sintaxe de seletor semelhante à do CSS que ajuda você a extrair todos os tipos de conteúdo HTML do documento extraído.
O Jsoup é rápido, tem uma sintaxe simples e lida com links quebrados por conta própria.
Exemplo de código:
Document doc = Jsoup.parse(html);
String title = doc.select("title").text();
String price = doc.select(".price").text();Se quiser analisar uma página da Web, você deve buscá-la primeiro. O Java não pode simplesmente navegar em uma página. Você precisa de um servidor HTTP para fazer uma solicitação de uma página da Web específica e, em seguida, o servidor da Web responde com o conteúdo da página da Web. Isso é o que você fornece ao jsoup para começar a extrair dados.
Você também pode usar os próprios métodos HTTP do Java em vez do Apache HttpClient, mas não é tão escalonável. O Apache lida com tempos limite de sessão, novas tentativas, agentes de usuário e cookies.
Jackson e Gson
Jackson e Gson são duas bibliotecas Java distintas. Essas bibliotecas ajudam você a converter o texto bruto extraído em dados limpos e acionáveis, como preços de produtos com títulos ou preços de produtos em determinadas categorias, de um site de comércio eletrônico. A Jackson lida melhor com automações de raspagem maiores do que a Gson, que foi projetada para tarefas pequenas e leves.
Quais são os contras de usar Java para raspagem da Web?
Agora que você entende um pouco sobre os recursos de raspagem do Java, vamos discutir onde ele o deixará na mão. Em 2026, você não poderá contar apenas com bibliotecas como jsoup e Apache HttpClient para trabalhos de raspagem dimensionáveis.
Há dois problemas fundamentais que você enfrenta ao fazer scraping somente com Java:
- Os sites bloqueiam você: Os sites estão mais defensivos agora. Eles se preocupam se o visitante do site é um ser humano real ou apenas um bot que sobrecarrega desnecessariamente o servidor e extrai dados do cliente sem permissão. Os sites não gostam mais de scrapers.
- Páginas com muitos JS não podem ser extraídas: O Jsoup e outras estruturas de extração funcionam muito bem para páginas HTML. Isso pode incluir páginas de produtos e outras páginas de comércio eletrônico/blog, mas muitos sites começaram a colocar trechos de código JavaScript para adicionar animações e recursos visuais interessantes ao site. O Jsoup não foi criado para extrair páginas com muito JS, de modo que a extração falha ou retorna resultados irrelevantes.
Esses dois problemas podem ser resolvidos. Os raspadores da Web têm estratégias e estruturas diferentes para evitar que sejam bloqueados por qualquer site e para raspar facilmente páginas com muito JS. No entanto, o processo não é tão simples quanto executar algumas linhas de código do jsoup e do Apache.
A maneira moderna de fazer raspagem da Web em Java
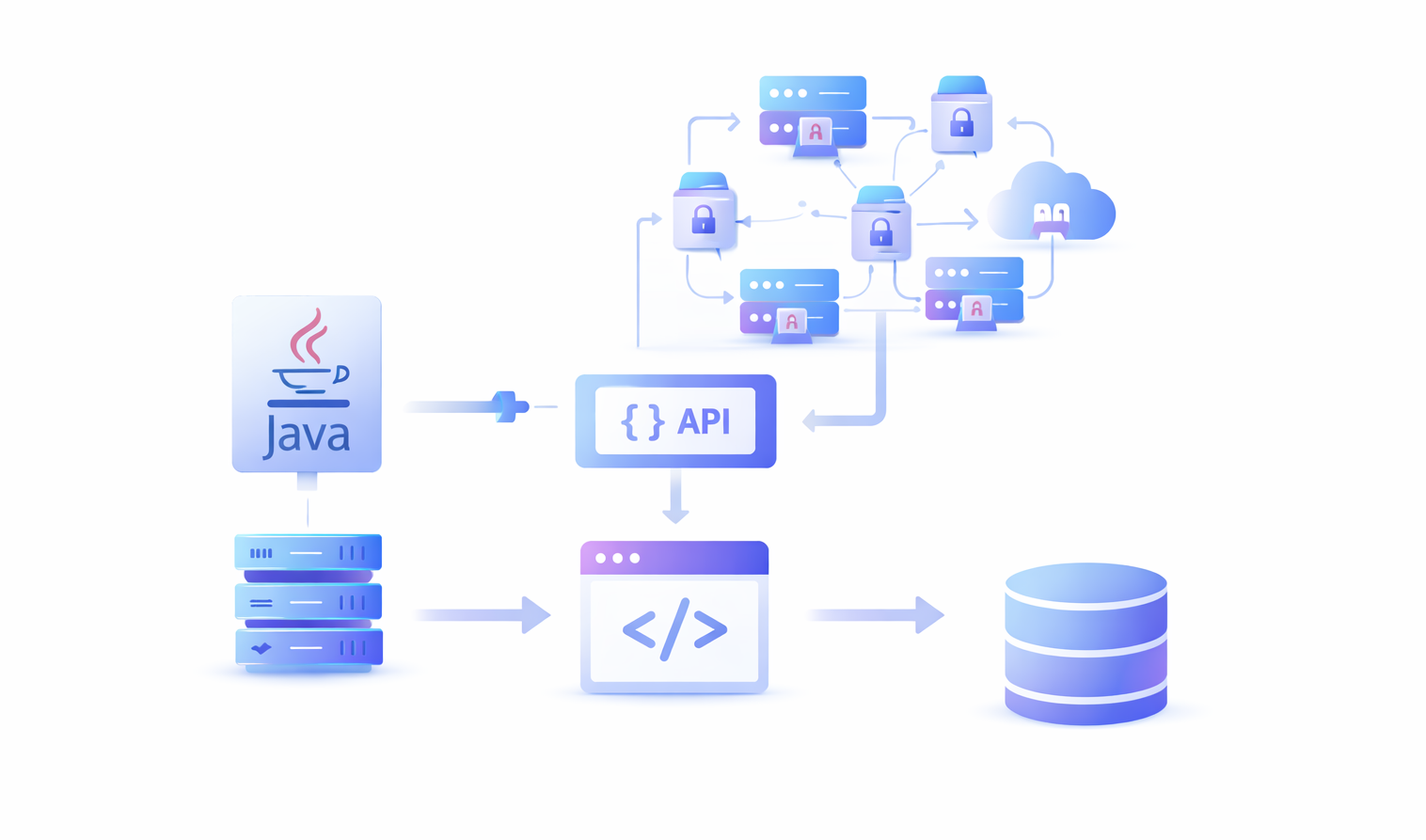
As bibliotecas Java autônomas não são suficientes para a raspagem da Web em 2026. Não estamos mais lidando com páginas HTML estáticas. Estamos lidando com sistemas anti-bot, CAPTCHAs, redirecionamentos, cookies, animações de design e layouts de texto com Java Script e muito mais.
Para criar uma automação de raspagem bem-sucedida e dimensionável, você precisa combinar o Java com outras tecnologias de raspagem mais recentes. Aqui está uma lista dos principais itens de que você precisa junto com o código Java para executar uma automação de raspagem da Web bem-sucedida:
- Um pool de proxies: Os sites rastreiam cada visitante pelo endereço IP. Quando uma parede de rede como a Cloudflare descobre que um usuário está extraindo dados, a primeira coisa que faz é bloquear o acesso do endereço IP ao site. É por isso que você precisa de um pool de proxies seguros e de lógica Java para trocar de proxies a cada poucas solicitações para evitar ser banido.
- Solucionador de CAPTCHA: Os CAPTCHAs existem para afastar os bots da plataforma. Os raspadores tradicionais não conseguem resolver CAPTCHAs. Codificar um solucionador de CAPTCHA em Java ou em qualquer outra linguagem é quase impossível. É por isso que você precisa de um solucionador de CAPTCHA de terceiros.
- Perfis de impressão digital de dispositivos: Plataformas como Facebook e LinkedIn implantam sistemas de detecção ainda mais avançados. Esses sistemas não se baseiam apenas em endereços IP para possíveis sinais de raspagem, eles rastreiam a impressão digital do dispositivo, o comportamento do usuário, saltos de proxy e vinculação de contas. É por isso que você precisa trocar a impressão digital do seu navegador junto com seus proxies para evitar que seu dispositivo seja banido da plataforma.
- Ferramentas para extrações pesadas de JS: Mesmo que você ignore todos os sistemas de detecção, muitas páginas da Web modernas são desenvolvidas usando estruturas pesadas de Javascript, como ReactJS e NextJS. Ferramentas como jsoup e outros raspadores tradicionais não podem extrair conteúdo dessas páginas. Você precisa de uma ferramenta adicional dessa parte para ajudar na conversão de JS para HTML.
A raspagem em Java não está morta. Ele ainda é muito útil se você adicionar sua própria infraestrutura, como proxies, solucionadores de CAPTCHA e conversores de páginas JS. Ou, a maneira mais ideal de ignorar todas essas integrações é usar uma API de raspagem da Web, como a Floppydata.
Guia: Como fazer raspagem da Web com Java em 2026
Em 2026, o Java deverá ser usado para dar suporte à infraestrutura de raspagem, atendendo a solicitações, organizando dados brutos, analisando dados brutos em dados estruturados e acionáveis e lidando com outros casos extremos e lógicas, como rotação de proxy, novas tentativas, mensagens de impressão, avisos e muito mais.
Se você estiver tentando extrair páginas da Web modernas com o jsoup, talvez falhe em 40% a 50% das vezes. No entanto, o Java deve ser usado por sua velocidade, integrações e multi-threading, não pela biblioteca jsoup.
Portanto, quando você estiver pronto para usar o Java como camada de controle do seu raspador, vamos nos aprofundar no método mais simples e mais eficaz de raspagem da Web em 2026.
Etapa 1: obtenha uma API do Web Scraper
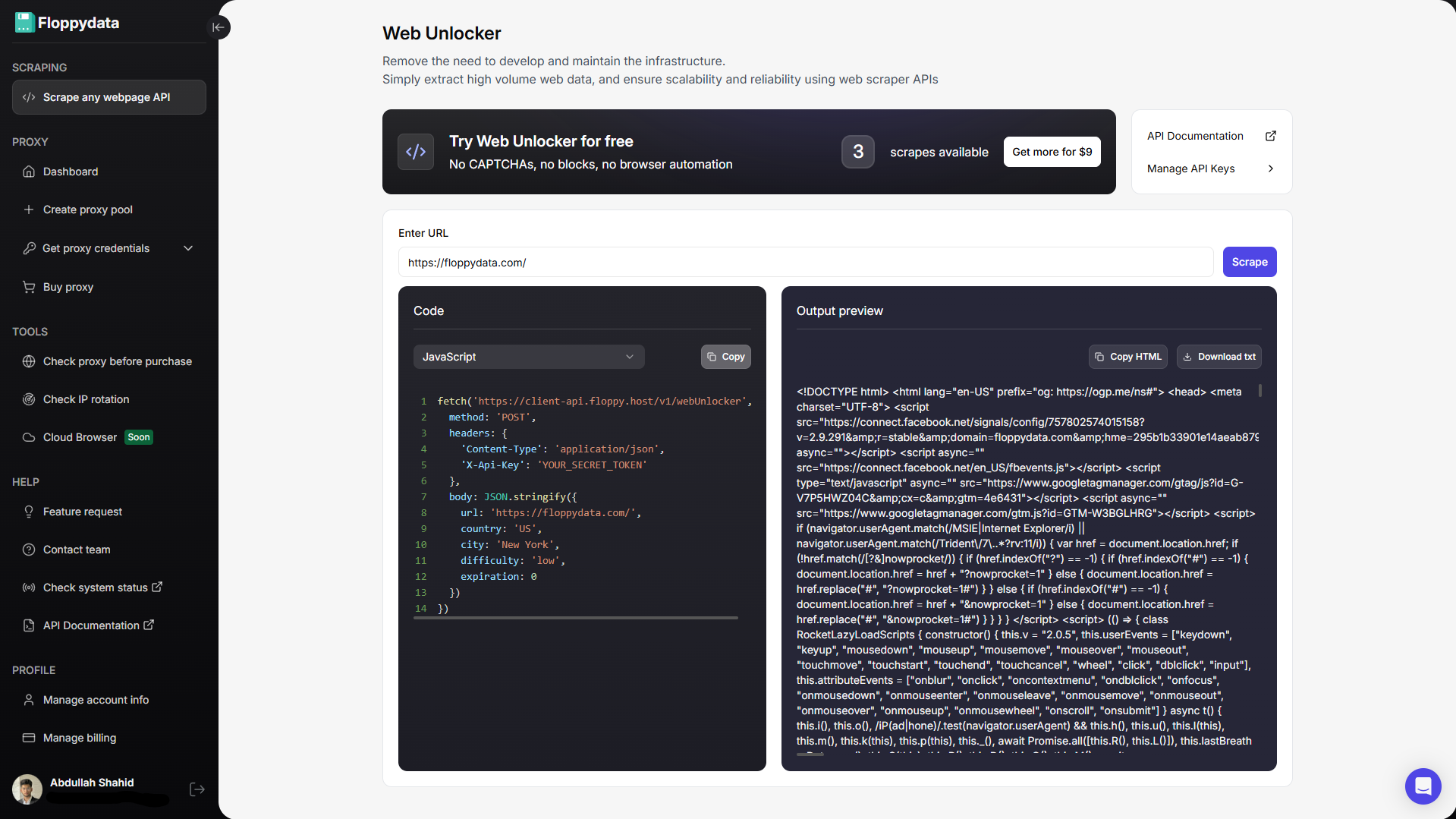
Em vez de tentar usar o raspador do Java, utilize uma API de raspador da Web confiável. Uma API de raspador da Web recebe o URL da sua página da Web, envia uma solicitação a ela, lida com CAPTCHAs, converte a página da Web em dados brutos e os devolve. A API do raspador da Web faz o trabalho pesado do servidor HTTP, tentativas, CAPTCHAs, erros, carga útil ruim, proxies rotativos e impressão digital do dispositivo.
Em Java, você escreve o restante da infraestrutura do pipeline, como a criação de filas multi-thread de links a serem explorados, extraindo tags úteis do conteúdo HTML e armazenando-as de forma estruturada, ou executando outras funções sobre os dados extraídos.
Você pode ler nossa análise sobre os melhores serviços de raspagem para encontrar o mais adequado para o seu caso de uso.
Etapa 2: Adicionar chave de API no snippet de código Java
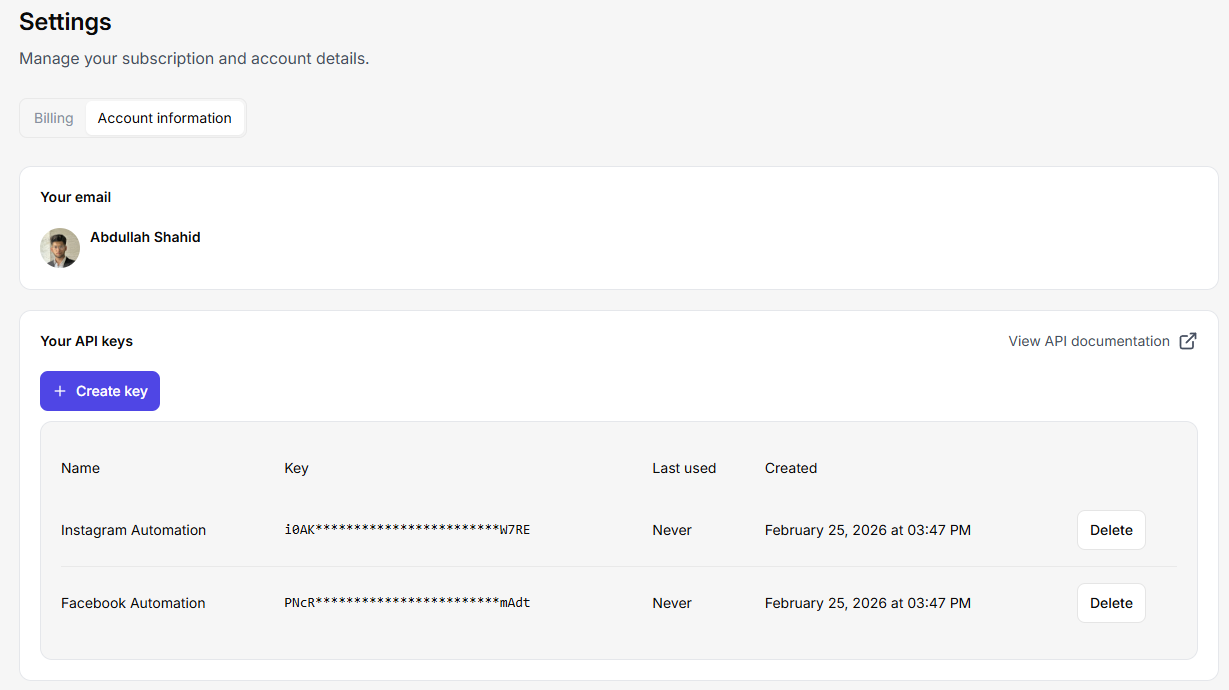
Obtenha a chave de API do serviço de raspagem da Web. Vamos integrá-la ao Java. Você pode criar várias chaves de API no Floppydata acessando suas configurações > account > botão “create key” (criar chave). Você pode enviar centenas de solicitações simultâneas nessa API e criar um trabalho de raspagem com vários threads que lida com milhares de páginas da Web de uma só vez.
Como a Floppydata executa seus trabalhos de raspagem da Web na nuvem, você também elimina toda a carga de abrir um navegador da Web e executar bibliotecas de raspagem no seu dispositivo. Se você fosse gerenciar toda a infraestrutura de raspagem, precisaria de muita memória RAM e capacidade de processamento.
A API de cliente da Floppydata usa um cabeçalho X-Api-Key e o ponto de extremidade documentado do Web Unlocker aceita uma url e parâmetros adicionais como país, cidade, dificuldade e expiração do cache. A resposta inclui conteúdo HTML que você pode analisar em Java.
Aqui está um exemplo de trecho de código que gosto de usar:
public class Floppydatascraper {
public static void main(String[] args) throws Exception {
String apiKey = System.getenv("FLOPPY_API_KEY");
String payload = """
{
"url": "https://example.com",
"country": "US",
"difficulty": "medium",
"expiration": 0
}
""";
HttpClient client = HttpClient.newBuilder()
.connectTimeout(Duration.ofSeconds(20))
.build();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://client-api.floppy.host/v1/webUnlocker"))
.header("X-Api-Key", apiKey)
.header("Content-Type", "application/json")
.POST(HttpRequest.BodyPublishers.ofString(payload))
.build();
HttpResponse<String> response =
client.send(request, HttpResponse.BodyHandlers.ofString());
System.out.println(response.body());
}
}Etapa 3: aprimore seu pipeline de raspagem de Java
Agora que você tem a chave de API integrada, crie seu pipeline de raspagem em torno dela. Por exemplo, se você tiver uma ferramenta de comércio eletrônico que explora a Amazon em busca de produtos relevantes em torno da palavra-chave alvo, extraia o título, as tags, a descrição etc. e mostre-os ao usuário. A API Scraper é a melhor abordagem e a mais escalável. Mesmo que você tenha milhares de clientes enviando solicitações simultâneas ao seu aplicativo, a API do Floppydata pode lidar facilmente com elas.
Você pode adicionar mais recursos aos dados extraídos, como o uso de uma chave de API de IA para escrever uma descrição e um título semelhantes, ou analisar palavras-chave semelhantes de todos os resultados extraídos etc. Toda essa infraestrutura precisa ser desenvolvida por você em Java.
Navegação sem cabeça em Java sem Selenium ou Puppeteer
Tradicionalmente, os raspadores usavam o Selenium e o Puppeteer para executar sessões de navegador sem cabeça, gerenciar proxies e lógica de raspagem. No entanto, esse processo é mais pesado, mais lento e quebra na produção sob carga pesada porque você precisa de uma infraestrutura de nuvem dimensionável para lidar com a demanda crescente de solicitações. Você acaba gastando tempo na construção de uma infraestrutura que pode ser obtida com essas APIs de raspagem extremamente baratas, como a Floppydata. Além disso, essas ferramentas de raspagem são testadas quanto à confiabilidade e à escala, e estão em constante evolução com o mercado para que você não precise alterar seu pipeline de raspagem a cada quatro meses.
Com a API do Floppydata, você precisa:
- nenhum gerenciamento de navegador local
- nenhuma frota de navegadores sem cabeça
- sem manutenção do selênio
- nenhuma configuração do Puppeteer
- apenas lógica de solicitação Java mais análise de HTML
Tudo isso por US$ 0,45 a US$ 0,9/1k de resultados raspados com sucesso. É mais barato do que manter suas próprias máquinas na nuvem. Veja os preços detalhados.
Considerações finais
Se alguém me pedisse para criar um pipeline de raspagem da Web em Javahoje, isso levaria de 20 a 30 minutos. Eu obteria a chave da API do Floppydata e elaboraria os requisitos do meu pipeline, incluindo o que eu quero fazer com os dados extraídos e como quero armazená-los. Em seguida, usaria o Claude Code para criar um pipeline de raspagem robusto. Como não estou configurando nenhuma infraestrutura de raspagem, posso testar rapidamente, executando esse script, se meu pipeline está funcionando ou não.
O Java é uma excelente opção para a criação de sistemas de raspagem da Web escalonáveis e multithread, mesmo com suas limitações. Mas, em 2026, as bibliotecas básicas de raspagem da Web não terão chance contra os sistemas antibot com tecnologia de IA que as plataformas implantam para manter os raspadores afastados. Você precisa de uma ferramenta de raspagem igualmente moderna e avançada para implantar uma automação de raspagem bem-sucedida.






