

En 2026, il n’est pas facile d’exécuter des automatismes de grattage de sites web. Étant donné qu’un grand nombre d’entreprises spécialisées dans l’IA essaient de récupérer autant de données que possible sur Internet pour l’entraînement des modèles, des plateformes comme Reddit, Meta, X et d’autres déploient des systèmes de détection alimentés par l’IA pour empêcher les racleurs de sites Web de mettre la main sur des données d’utilisateurs publiques. Ce guide explore donc la manière de mettre à l’échelle et d’automatiser le web scraping en 2026.
Pourquoi le Web Scraping devient-il plus difficile ?

Voici quelques raisons pour lesquelles les entreprises détectent et bloquent activement les automatismes de « web scraping ».
- Les scrappeurs de sites web sollicitent inutilement les serveurs puisqu’ils envoient des centaines, voire des milliers de requêtes automatisées simultanées.
- Les annonceurs n’aiment pas les robots parce que les publicités sont montrées à un robot qui récupère les données d’une page et que les dépenses publicitaires sont gaspillées.
- La plupart des entreprises préfèrent vendre leurs données à d’autres entreprises d’IA ou former leurs propres modèles. C’est pourquoi elles ne souhaitent pas que des « scrapers » extraient gratuitement des données de leur plateforme.
Néanmoins, il existe encore en 2026 des méthodes de scraping de données efficaces qui sont non seulement sûres à utiliser, mais aussi évolutives, faciles à automatiser et qui fonctionnent pour tous les sites web. Étant donné que les systèmes anti-bots deviennent plus intelligents grâce à l’IA, les scrappeurs web rattrapent également leur retard en proposant la résolution automatique des CAPTCHA, la randomisation des mouvements et des clics de souris, la rotation des IP, la randomisation des empreintes digitales des navigateurs et bien plus encore.
Comment faire évoluer le Web Scraping ?

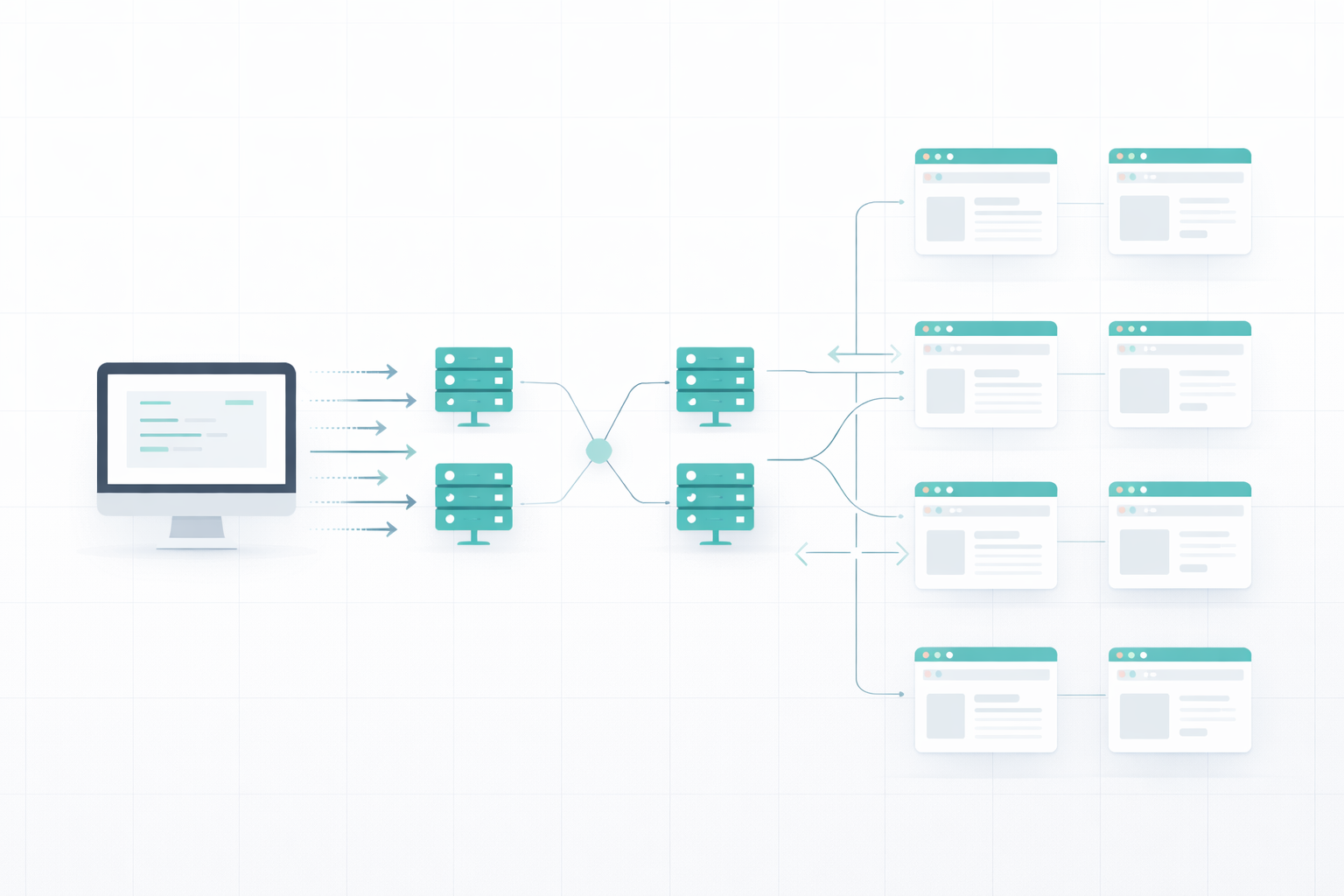
Le problème n’est pas de récupérer une ou deux pages web, mais comment récupérer des milliers de pages web en quelques heures ou quelques jours ? Nous ne pouvons pas ouvrir autant d’onglets sur notre appareil en raison de la limitation de la mémoire vive et de la vitesse de traitement, et si notre IP est bannie dans les premières minutes, nous devrons changer d’appareil.
La mise à l’échelle du web scraping nécessite de la compréhension et de la planification. Commençons par comprendre les défis que pose le web scraping.
Les défis de l’extraction de données sur le Web
Les sites web ne sont plus de simples pages HTML statiques. Les systèmes anti-bots suivent en permanence l’activité des utilisateurs et la qualité du trafic pour s’assurer que seuls les vrais utilisateurs accèdent aux sites web et que les scrappeurs sont instantanément bloqués. Voici les défis auxquels j’ai été confronté lorsque j’ai commencé à faire du web scraping :
- Limitation du taux d’IP : Les plateformes enregistrent le nombre de requêtes par adresse IP toutes les minutes et toutes les heures. Si une adresse IP tente de dépasser la limite, le compte est suspendu ou temporairement désactivé pour cause de spam.
- Rendu Javascript : De nombreux sites web chargent désormais leur contenu de manière dynamique. Lorsqu’un scraper tente d’obtenir du contenu HTML, il obtient des champs manquants parce que certaines parties de la page n’ont pas été chargées.
- CAPTCHAs : Mes scripts de scraping web avaient du mal à résoudre les CAPTCHAs et continuaient à me bloquer. Facebook a même banni mon IP et je n’ai plus pu y accéder avec la même IP.
- Détection du comportement : Les sites web suivent votre comportement, comme l’activité de défilement, les mouvements de la souris, le caractère aléatoire des clics, etc. pour déterminer si vous êtes un robot ou une personne réelle.
- Suivi des empreintes digitales : Les plateformes enregistrent et suivent l’empreinte digitale de votre navigateur pour identifier les appareils qui utilisent ce compte. En cas de violation des conditions d’utilisation, elles peuvent interdire l’empreinte digitale et empêcher votre navigateur d’accéder à la plateforme.
- Gestion des cookies : J’ai essayé d’utiliser des proxys et plusieurs profils de navigateur, mais je me heurtais constamment à des problèmes de contamination croisée des cookies. Comme tous les profils enregistrent les cookies de mes sessions de connexion, les plateformes ont pu identifier que j’avais d’autres comptes connectés à partir du même appareil et que je faisais du web scraping.
Construire une stratégie de scraping web évolutive
Il existe d’excellents services de web scraping qui vous aident à construire un système de web scraping évolutif sans avoir à vous soucier de tous les problèmes décrits ci-dessus. Ces outils de web scraping utilisent un pool de proxies et des empreintes de navigateur aléatoires, exécutent toutes vos sessions de scraping dans le nuage pour ne pas alourdir votre machine, résolvent automatiquement les CAPTCHA, isolent les cookies et gèrent le rendu Javascript.
Les services de scraping web tels que Floppydata résolvent le problème de l’extensibilité :
- Exécution de sessions de navigation parallèles dans le nuage
- Utilisation d’adresses IP tournantes à partir de son pool de 90 millions de proxies
- Gestion automatique des CAPTCHAs et du rendu JS
- Évolution à la demande sans avoir à mettre en place une infrastructure supplémentaire
Comment automatiser le Web Scraping ?
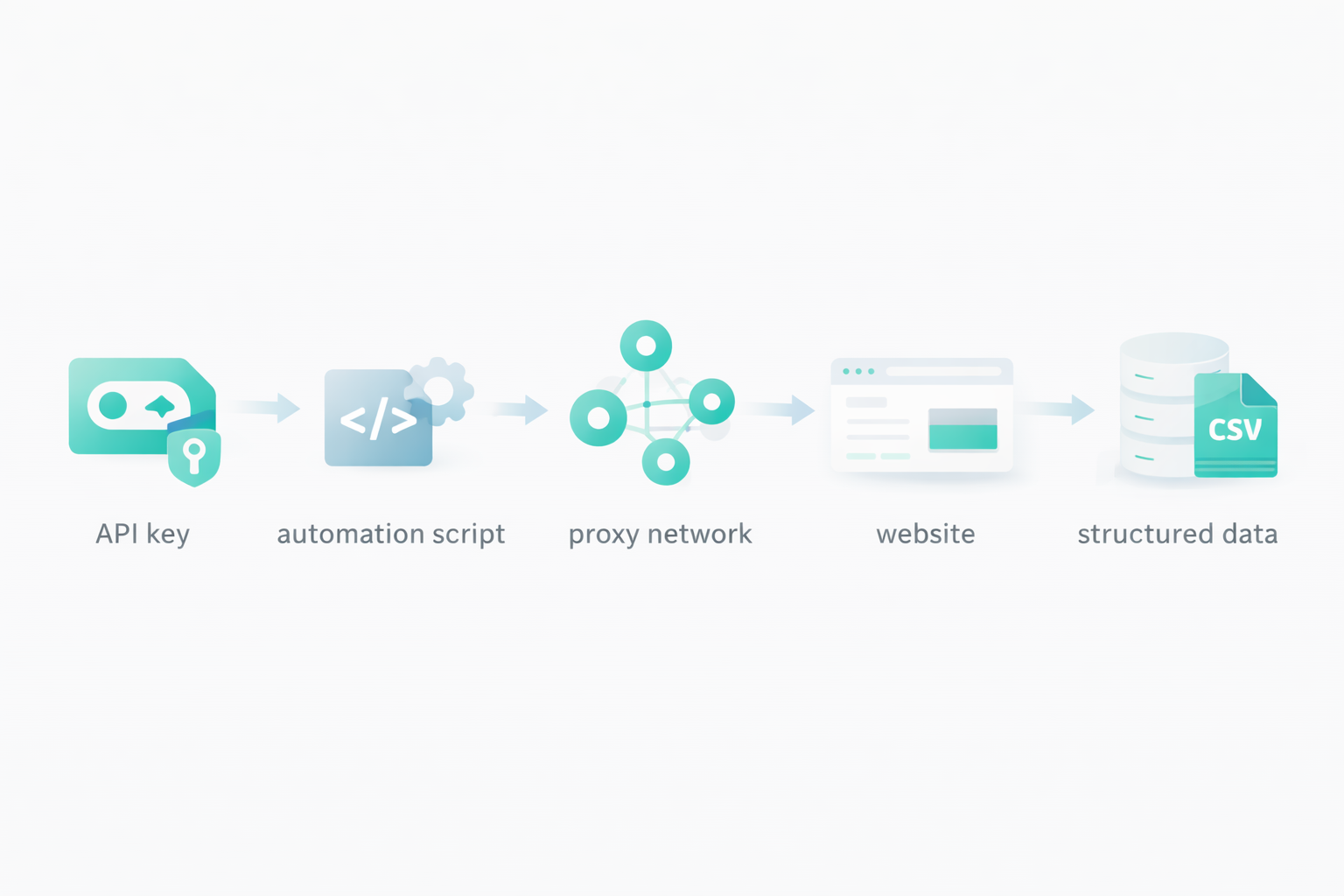
Lorsque vous disposez d’une infrastructure évolutive, vous devez créer un système automatisé pour gérer les proxies, les extractions, les liens, le formatage des données, etc. Même si les services de scraping vous fournissent une infrastructure évolutive pour gérer des milliers de requêtes par heure, vous ne pouvez pas le faire manuellement. C’est là qu’interviennent les scripts d’automatisation pour le scraping.
Certains services de scraping web proposent des modèles configurés pour des plateformes célèbres telles que Reddit, Meta, Instagram, X., etc. Vous pouvez choisir un modèle, le configurer en fonction de votre cas d’utilisation et commencer le scraping.
Une autre méthode d’automatisation du web scraping, plus populaire, est celle des clés API. Des services de web scraping comme Floppydata proposent des clés API qui vous permettent d’envoyer des requêtes de web scraping à leur serveur cloud et de recevoir le contenu extrait en retour. Lorsque vous utilisez une API, les possibilités sont infinies. Vous définissez votre propre format d’extraction de données, vos règles de rotation de proxy, les pages à extraire, les champs à extraire, la manière de les stocker, le délai à ajouter entre chaque requête, le nombre de requêtes simultanées à envoyer, et bien d’autres choses encore.
Vous pouvez utiliser cette clé API pour créer des outils de scraping ou l’intégrer dans votre système d’entreprise existant. Tout ce dont vous avez besoin, c’est d’une clé API, et des services comme Floppydata se chargeront du reste et vous fourniront les résultats finaux.
Guide étape par étape pour la mise à l’échelle et l’automatisation du Web Scraping
Voici un guide étape par étape sur la création d’une automatisation de scraping web avec l’API Floppydata.
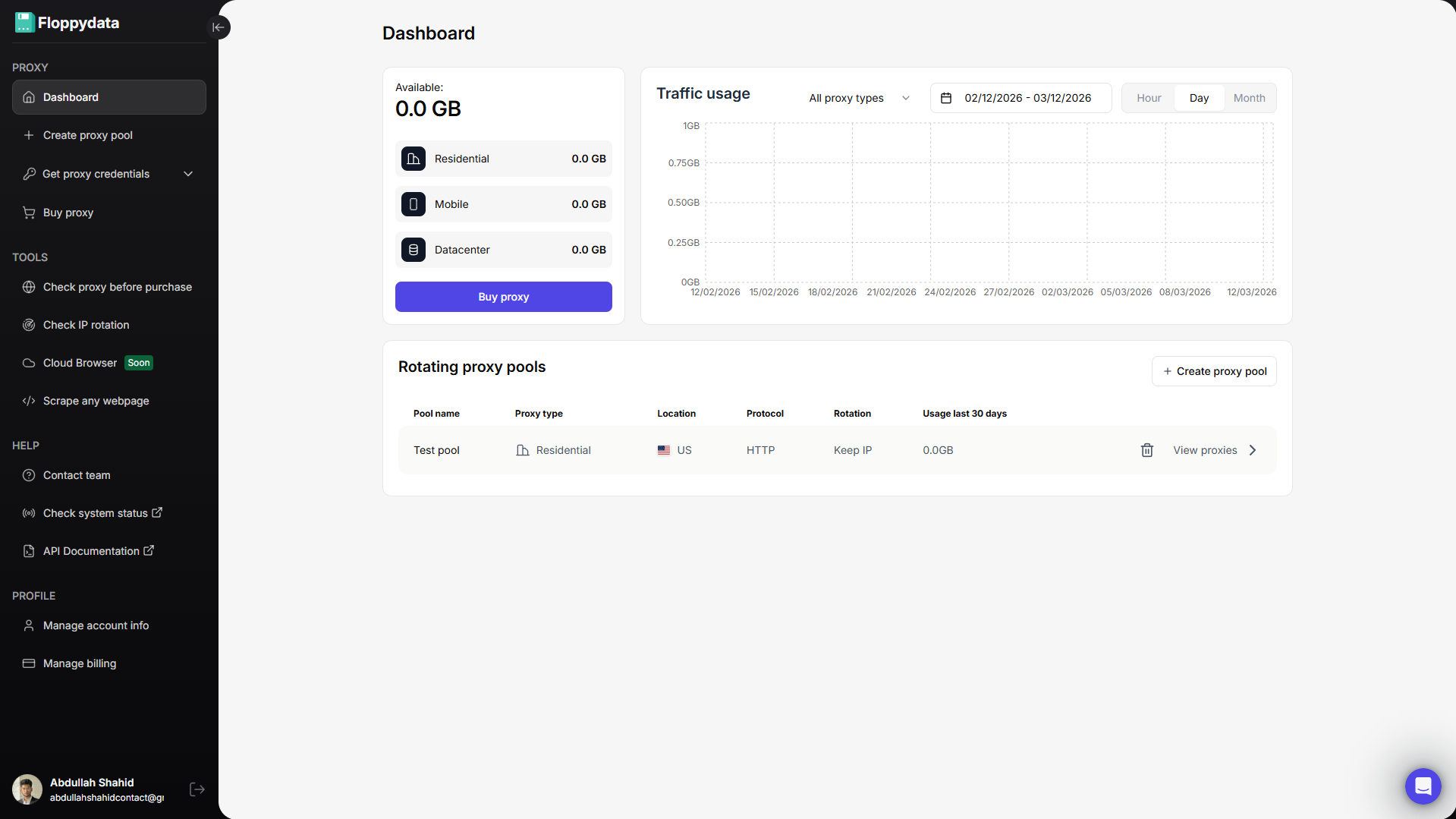
Étape 1 : Créer un compte Floppydata
Inscrivez-vous sur Floppydata et ouvrez le tableau de bord. C’est là que vous pouvez gérer vos proxies et des outils comme le débloqueur de sites web.
Étape 2 : Analyser l’URL cible

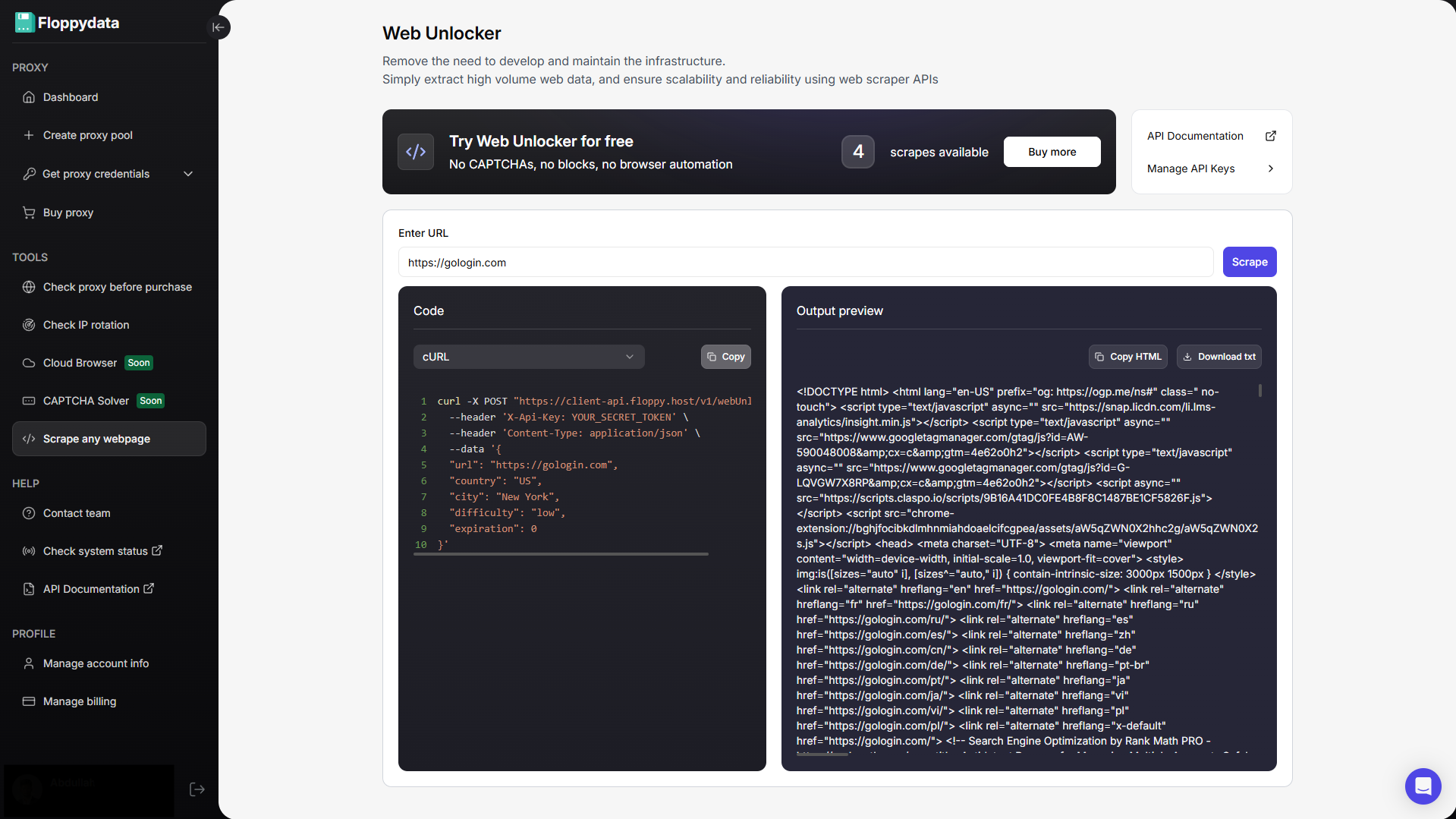
Collez votre URL dans le champ affiché et cliquez sur scrape. Vous obtiendrez le contenu HTML de cette page ainsi qu’un extrait de code à ajouter à l’automatisation de votre navigateur. Si vous créez un automatisme pour récupérer les prix d’un produit sur un site web, vous pouvez utiliser cette fonction d’analyse pour identifier la balise HTML qui contient le prix. Vous pouvez ensuite écrire votre script d’automatisation pour extraire spécifiquement les balises suivantes et les stocker dans votre fichier excel/csv.
Étape 3 : Créer des clés API pour l’automatisation
Vous pouvez créer des clés API à partir des paramètres de votre compte. Ces clés API seront utilisées dans votre script d’automatisation du navigateur pour faire pivoter les proxies, déverrouiller les sites web et récupérer des données. Floppydata Web Unlocker récupère des données et les envoie à votre script via cette API.
Étape 4 : Rédiger et exécuter l’automatisation de la recherche sur le Web
Maintenant que vous disposez de la clé API et des proxies, vous pouvez créer un script de web scraping en Python, Javascript, C# ou GO. Placez votre clé API dans l’extrait de code indiqué sur la page de déverrouillage du web avec les URL. Voici un exemple rapide de script Python que je peux exécuter dans un interpréteur Python pour extraire des données d’un forum de discussion Reddit:
httpx.post(
« https://client-api.floppy.host/v1/webUnlocker »,
headers={
« Content-Type » : « application/json »,
« X-Api-Key » : « YOUR_SECRET_TOKEN »
},
json={
« url » :
« https://www.reddit.com/r/automation/comments/1ntu327/top_5_antidetect_browsers_comparison_2025/ »,
« country » : « US »,
« city » : « New York »,
« difficulty » : « low »,
« expiration » : 0
}
)
Vous pouvez modifier le pays, la ville et l’URL pour changer le proxy et les liens cibles. Ceci n’est qu’un extrait de code fictif. Vous pouvez créer des automatismes complexes à l’aide de Claude Code ou de ChatGPT qui exploreront dynamiquement toute votre liste d’URL cibles et en extrairont le contenu utile dans le format de votre choix.
Meilleures pratiques et conseils pour l’automatisation du Web Scraping
Lorsque vous créez des flux de travail automatisés pour le web scraping, il est important de donner la priorité à la résilience et à la performance plutôt qu’à la vitesse. Votre flux de travail doit avoir une bonne précision. Si 40 % de vos demandes d’extraction échouent, vous perdez 40 % de votre budget sans aucun résultat. Bien que Floppydata ne vous facture que les extractions de pages réussies, d’autres services facturent pour 1 000 requêtes, même si elles échouent toutes.
Pour créer une automatisation qui fera partie de votre flux de travail pendant des semaines ou des mois, vous devez vous assurer de quelques points essentiels :
- Rotation des IP par travailleur ou par session
- Faites évoluer le scraping grâce à des sessions parallèles, et non en augmentant la vitesse ou en réduisant les temps d’attente.
- Utilisez les Web Unlockers pour les sites à forte densité de blocs
- Privilégiez les API lorsqu’elles sont disponibles
- Isoler les empreintes digitales du navigateur
- Enregistrer les erreurs et réessayer intelligemment
- Tester à petite échelle avant de passer à grande échelle
- Achetez des proxies propres auprès d’un vendeur de confiance
Vous n’avez pas à vous soucier des proxys si vous utilisez un outil de déblocage de site web d’un fournisseur de proxy comme Floppydata, BrightData, Oxylabs etc. car ils peuvent inclure des IP propres pour leur outil.
Principaux enseignements
La mise à l’échelle et l’automatisation du web scraping sont toujours possibles en 2026 et peuvent être très efficaces si vous faites les choses correctement. Si vous suivez les stratégies que j’ai expliquées dans ce blog et que vous donnez la priorité à la résilience plutôt qu’à la vitesse, vous pouvez créer une automatisation reproductible qui durera des mois avant que vous n’ayez besoin de faire des changements. Avec une infrastructure appropriée, vous n’avez pas à vous soucier d’un système anti-bot.





