

Introducción
Al ser una de las principales plataformas inmobiliarias de EE.UU., Zillow se convierte en una plataforma a la que muchas empresas quieren recurrir para obtener datos sobre propiedades. La plataforma recibe actualmente alrededor de 243 millones de visitas al mes, por lo que, naturalmente, alberga una enorme cantidad de datos inmobiliarios útiles.
Sin embargo, los desarrolladores a menudo comparten en Reddit cómo les resulta difícil eludir el cortafuegos de Zillow o se bloquean permanentemente mientras intentan hacer scraping. Si acabas de experimentar esto y estás buscando una guía estable que funcione, sigue leyendo.
En esta guía, te mostraré cómo extraer datos clave de listados de Zillow utilizando Python y una API web sencilla.
¿Qué es Zillow Scraping?
El scraping de Zillow es el proceso de recopilar datos inmobiliarios disponibles públicamente de las páginas de Zillow y convertirlos en un formato estructurado, como CSV o JSON, que puedas utilizar con fines comerciales o personales.
En lugar de abrir los listados uno por uno, puede utilizar un scraper para extraer los detalles clave de las páginas de búsqueda y de las páginas de detalles de los listados de propiedades.
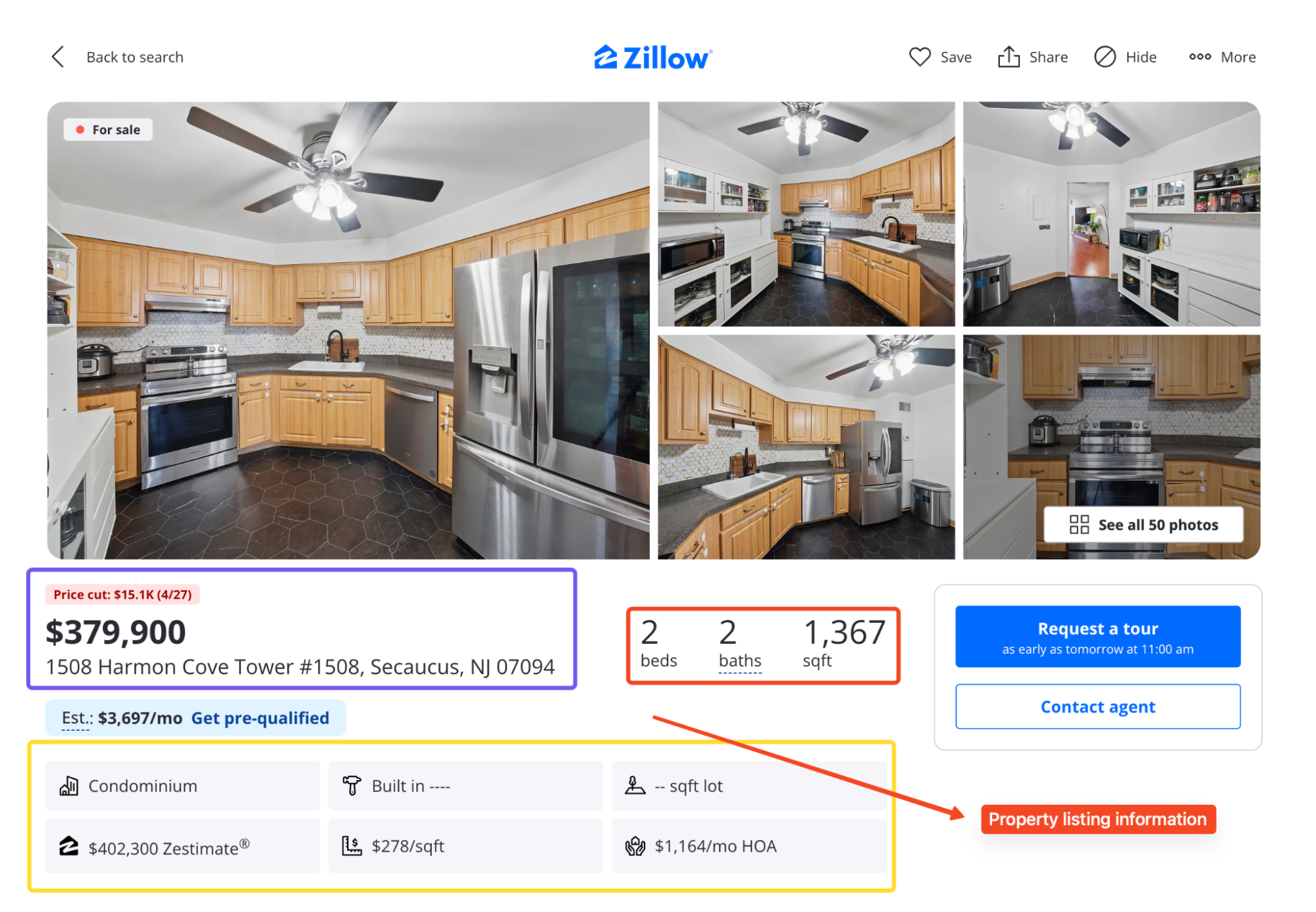
Entre ambas páginas se puede sacar:
- Precio, dirección, camas, baños, metros cuadrados, estado y días en el mercado
- Zestimate y Rent Zestimate
- Fotos del anuncio y nombre del agente
- Historial de precios e impuestos
¿Por qué raspar datos de Zillow?
Imagine poder acceder a listados de propiedades actualizados al minuto, detalles de precios y análisis de mercado sin tener que abrir manualmente cientos de páginas de Zillow.
Ese es el verdadero valor de raspar Zillow.
Si trabajas en el sector inmobiliario, la inversión en propiedades, la investigación de mercado, la generación de clientes potenciales o el análisis de precios, Zillow tiene datos públicos útiles que pueden ayudarte a detectar tendencias más rápidamente.
¿Qué hace que Zillow sea tan difícil de raspar?
Zillow no va tan lejos como otras plataformas cuando se trata de bloquear bots, pero aún así está construida para cerrar el tráfico que no parece humano.
La mayoría de los desguaces fracasan por dos razones. Veamos ambas:
Protección PerimeterX
Zillow utiliza PerimeterX para detectar y bloquear el tráfico bot en tiempo real. Si tu scraper tiene cabeceras erróneas, proviene de una IP de baja confianza o envía demasiadas solicitudes demasiado rápido, puede ser marcado.
La mayoría de las veces, esa bandera conduce a un rompecabezas CAPTCHA, que rompería la mayoría de los raspadores. PerimeterX también comprueba muchas señales, como cabeceras, comportamiento del navegador, huellas TLS, velocidad de solicitud y reputación IP.
Si el tráfico parece automatizado, es posible que el scraper nunca llegue a los datos reales del listado.
Por lo tanto, incluso si renderiza la página en un navegador sin cabeza, eso no garantiza el éxito. Sigues necesitando proxies de alta calidad, sesiones limpias y un comportamiento realista de las peticiones.
Por eso prefiero utilizar Floppydata’s Web Unlocker para el scraping de Zillow.
HTML no estructurado y sin selectores estables
Analizar Zillow también puede ser tan frustrante como superar sus defensas. Casi no hay nombres de clase, IDs o atributos de datos consistentes en la fuente de la página.
Los elementos que parecen sencillos, como el precio o la dirección, están envueltos en etiquetas genéricas <div> o no tienen ningún identificador.
Peor aún, los nombres de las clases cambian a menudo y no siguen ningún patrón. Así que hay que usar concordancias flexibles (como find() basado en palabras clave o incluso regex) para extraer datos de nodos de texto sin procesar.
Esto hace que Zillow sea uno de los sitios más inestables para scrapear si confías en selectores estáticos.
Extraer información de listados de Zillow con Python
Para esta guía, me centraré en la página de resultados de búsqueda de Zillow en Boston, que contiene varios listados de propiedades. A partir de ahí, podemos extraer campos como el precio, la dirección, las camas, los baños, los metros cuadrados, el estado y los enlaces de los listados.
Nota: Las páginas de Zillow cambian a menudo. Si la página de Boston parece diferente para cuando leas esto, ve a Zillow, busca cualquier ciudad o barrio, copia la URL de los resultados y sustitúyela en el código.
Empecemos por la configuración:
Requisitos previos
Necesitarás tres cosas antes de empezar:
- Python 3.10 o superior instalado en su máquina
- Una cuenta de Floppydata con una clave API para el Web Unlocker
- Dos bibliotecas Python: requests para las llamadas HTTP y beautifulsoup4 para el análisis sintáctico de HTML
Si aún no tienes una cuenta de Floppydata, regístrate en floppydata.com y obtén tu clave API desde el panel de control de Web Unlocker.
Las cuentas nuevas vienen con cinco raspados gratuitos, así que puedes seguir todo este tutorial sin pagar nada.
La biblioteca de peticiones suele venir preinstalada, pero puedes ejecutar este comando para asegurarte de que está correctamente instalada:
pip install requests beautifulsoup4Una vez hecho esto, cree una nueva carpeta y un nuevo archivo de proyecto:
mkdir zillow-scraper
cd zillow-scraper
touch zillow_scraper.pyAhora, ya está listo.
Envío de la primera solicitud
Lo primero que intenta la mayoría de la gente es una petición Python normal. Que por lo general se parece a esto:
import requests
url = "https://www.zillow.com/boston-ma/"
response = requests.get(url)
print(response.status_code)
print(response.text)Pero cuando lo probé, no tardó ni dos intentos, ya que mi primera petición volvió bloqueada. Recibí una respuesta 403 con una página de bloqueo de PerimeterX:
403
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<meta name="description" content="px-captcha">
<title>Access to this page has been denied</title>
</head>Ahora, este es el problema con el scraping de Zillow directamente. Una petición Python normal no se comporta como una sesión de navegación real. Tampoco tiene la huella digital correcta del navegador, la calidad de IP o el renderizado de JavaScript que permite a Zillow detectarlo inmediatamente y bloquear la solicitud.
Esta es la razón por la que no construyo el raspador principal alrededor de llamadas directas requests() a Zillow. En su lugar, envío mis peticiones a través de Floppydata’s Web Unlocker y dejo que se encargue de las partes difíciles.
Scraping Zillow con Floppydata Web Unlocker
Enviemos una petición a la página de búsqueda utilizando el Desbloqueador Web. Zillow no es el objetivo más difícil de escrapear, pero sí se preocupa por la reputación IP y el comportamiento del navegador.
Aquí es donde entra en juego Web Unlocker. Enruta su solicitud a través de una IP residencial de confianza, aplica una huella digital real del navegador y devuelve el HTML completamente renderizado.
Una cosa que me gusta mucho de Floppydata es que sólo pagas por las solicitudes que tienen éxito. Si un scrape falla, no cuenta para tu consumo.
El panel de control también muestra análisis de las solicitudes en tiempo real, para que pueda realizar un seguimiento de su uso, las tasas de éxito y los créditos restantes sin salir de la página.
Antes de escribir cualquier código, me gusta probar primero la URL de destino en el Web Unlocker sin código. Esto me permite ver la respuesta HTML antes de construir un analizador, así que sé exactamente qué selectores y datos esperar.
Utilizar la herramienta Web Unlocker es literalmente tan fácil como el abecedario. Simplemente abre el Desbloqueador Web desde tu panel de Floppydata. A continuación, pegue esta URL«https://www.zillow.com/boston-ma/», haga clic en el botón Scrape y espere unos segundos
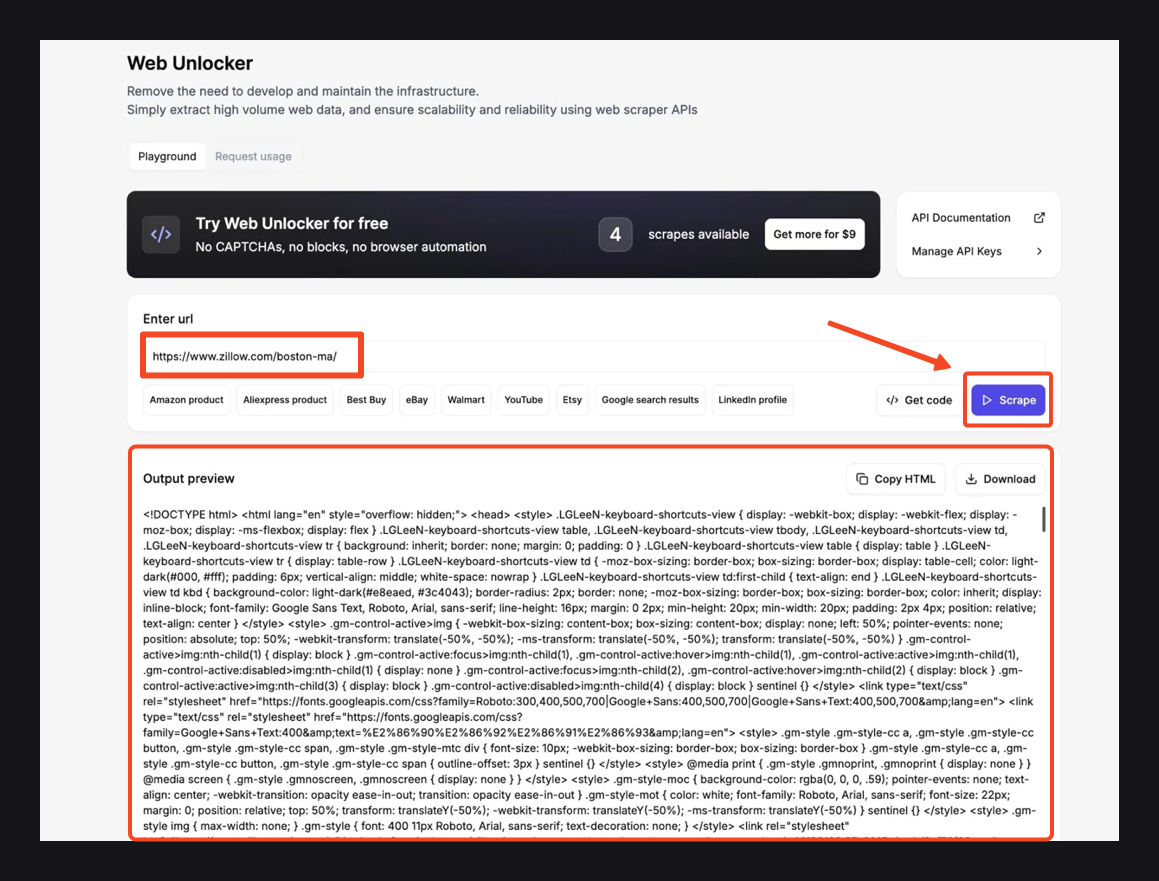
Una vez finalizado el scrape, compruebe el panel de vista previa de salida que aparece a continuación. Debería ver la página HTML completa que contiene los resultados de nuestra búsqueda en Zillow.
Si los datos tienen buena pinta, utilice Copiar HTML para obtenerlos o Descargar para guardar el archivo localmente.
Comprender la estructura de paginación de Zillow
La vista previa de la salida devuelve HTML sin formato, lo que es útil porque puedo inspeccionar la estructura exacta antes de escribir el código.
Esto es similar a abrir las herramientas de desarrollo del navegador pulsando F12 e inspeccionar la página directamente. Dentro del HTML descargado, encontré una cosa importante que facilita mucho el análisis sintáctico.
La mayoría de los tutoriales te dirán que cojas las tarjetas de listado con selectores CSS, pero Zillow sólo muestra 9 tarjetas en el marcado de la página. Las otras 32 se cargan a medida que te desplazas por la página, por lo que el scraping con selectores CSS pierde la mayor parte de los datos.
Más bien, los resultados de la búsqueda están dentro de un gran objeto JSON en la página HTML. Ese JSON se encuentra dentro de esta etiqueta script:
<script id="__NEXT_DATA__" type="application/json">La página utiliza ese JSON para cargar los datos en el frontend, y nosotros también podemos leerlo. Dentro de ese JSON, los listados se encuentran en esta ruta exacta:
data["props"]["pageProps"]["searchPageState"]["cat1"]["searchResults"]["listResults"]Así que nuestro plan de análisis es simple.
Encontraremos el script __NEXT_DATA__ con BeautifulSoup, parsearemos el JSON, nos moveremos al array listResults, y sacaremos los campos que necesitemos.
Zillow web scraping con Python y Web Unlocker
Ahora podemos pasar del salpicadero al código.
El snippet del dashboard usa httpx, pero usaré requests aquí porque es más familiar para la mayoría de los lectores de Python.
Paso 1: Preparar la solicitud
Empecemos con la configuración básica. Necesitamos el endpoint de Web Unlocker, nuestra clave API y la URL de Zillow de destino:
import requests
import json
from bs4 import BeautifulSoup
API_URL = "https://client-api.floppy.host/v1/webUnlocker"
API_KEY = "YOUR_API_KEY"
SEARCH_URL = "https://www.zillow.com/boston-ma/"
SEARCH_URL = "live_zillow_boston.json"Sustituya YOUR_API_KEY con la clave de su panel de Floppydata.
Aquí estoy utilizando Boston como mercado objetivo, pero si quieres hacer scraping de otra ciudad, sólo tienes que sustituir la URL de búsqueda.
Paso 2: Obtener la página a través de Web Unlocker
Web Unlocker recibe una carga JSON con la URL de destino y algunas opciones. Devuelve una respuesta JSON que contiene el HTML renderizado en un campo html:
Ahora creo una función fetch_html()para enviar la URL de Zillow a Web Unlocker y devolver el HTML renderizado
def fetch_html(url):
response = requests.post(
API_URL,
headers={
"Content-Type": "application/json",
"X-Api-Key": API_KEY,
},
json={
"url": url,
"country": "US",
"city": "Boston",
"difficulty": "medium",
"expiration": 0,
},
timeout=120,
)
response.raise_for_status()
data = response.json()
html = data.get("html")
if not html:
raise ValueError("Unlocker response did not include an 'html' field.")
return htmlAquí ocurren varias cosas. Los campos de país y ciudad ayudan a que la solicitud coincida mejor con la ubicación de destino. He utilizado dificultad «media» porque Zillow no es una simple página estática, por lo que necesita un proceso de desbloqueo más fuerte.
El campo de caducidad se establece en 0, por lo que obtengo una respuesta nueva. Después de que la solicitud tiene éxito, Web Unlocker devuelve una respuesta JSON, y el HTML renderizado está dentro del campo html.
Paso 3: Extraer los listados
Ahora podemos aplicar el plan de análisis de antes. Crearé una función extract_listings(). Esta función toma el HTML, encuentra los datos JSON de Zillow y extrae los listados:
def extract_listings(html):
soup = BeautifulSoup(html, "html.parser")
next_data = soup.find("script", id="__NEXT_DATA__")
if not next_data or not next_data.string:
raise ValueError("Could not find Zillow's __NEXT_DATA__ script.")
data = json.loads(next_data.string)
search_state = data.get("props", {}).get("pageProps", {}).get("searchPageState", {})
list_results = (
search_state.get("cat1", {})
.get("searchResults", {})
.get("listResults", [])
)
listings = []
for item in list_results:
listings.append(
{
"zpid": item.get("zpid"),
"address": item.get("address"),
"price": item.get("price"),
"beds": item.get("beds"),
"baths": item.get("baths"),
"sqft": item.get("area"),
"status": item.get("statusType"),
"url": item.get("detailUrl"),
}
)
return listingsUsando BeautifulSoup, puedo fácilmente ir directamente al JSON estructurado dentro de la página. Luego analicé el contenido del script como JSON y obtuve la matriz listResults.
Cada elemento en listResults es un listado de propiedades, y de cada listado, podemos recoger datos valiosos como:
- dirección
- precio
- camas
- baños
- zona
- statusType
- detailUrl
He cambiado el nombre del área a pies cuadrados en el resultado final porque es más fácil de entender.
Paso 4: Guardar los resultados en un archivo JSON
Por último, podemos añadir una función main() para ejecutar el scraper y guardar la salida en un archivo JSON:
def main():
print(f"Fetching data from: {SEARCH_URL}")
html = fetch_html(SEARCH_URL)
listings = extract_listings(html)
if not listings:
raise SystemExit("No listings found in Zillow's JSON data.")
with open(OUTPUT_FILE, "w", encoding="utf-8") as file:
json.dump(listings, file, indent=2)
print(f"Found {len(listings)} listings")
print(f"Saved results to {OUTPUT_FILE}")Esta función obtiene la página, extrae los listados, comprueba que la lista no está vacía y lo guarda todo en un archivo JSON. Una vez que los datos se ven bien, podemos convertirlos a CSV más tarde o utilizar los datos directamente en nuestras aplicaciones.
El guión completo
Aquí está todo el código que utilicé para extraer con éxito mis listados de Zillow:
from bs4 import BeautifulSoup
import requests
import json
API_URL = "https://client-api.floppy.host/v1/webUnlocker"
API_KEY = "Your_API_KEY"
SEARCH_URL = "https://www.zillow.com/boston-ma/"
OUTPUT_FILE = "live_zillow_boston.json"
def fetch_html(url):
response = requests.post(
API_URL,
headers={
"Content-Type": "application/json",
"X-Api-Key": API_KEY,
},
json={
"url": url,
"country": "US",
"city": "Boston",
"difficulty": "medium",
"expiration": 0,
},
timeout=120,
)
response.raise_for_status()
data = response.json()
html = data.get("html")
if not html:
raise ValueError("Unlocker response did not include an 'html' field.")
return html
def extract_listings(html):
soup = BeautifulSoup(html, "html.parser")
next_data = soup.find("script", id="__NEXT_DATA__")
if not next_data or not next_data.string:
raise ValueError("Could not find Zillow's __NEXT_DATA__ script.")
data = json.loads(next_data.string)
search_state = data.get("props", {}).get("pageProps", {}).get("searchPageState", {})
list_results = (
search_state.get("cat1", {})
.get("searchResults", {})
.get("listResults", [])
)
listings = []
for item in list_results:
listings.append(
{
"zpid": item.get("zpid"),
"address": item.get("address"),
"price": item.get("price"),
"beds": item.get("beds"),
"baths": item.get("baths"),
"sqft": item.get("area"),
"status": item.get("statusType"),
"url": item.get("detailUrl"),
}
)
return listings
def main():
print(f"Fetching data from: {SEARCH_URL}")
html = fetch_html(SEARCH_URL)
listings = extract_listings(html)
if not listings:
raise SystemExit("No listings found in Zillow's JSON data.")
with open(OUTPUT_FILE, "w", encoding="utf-8") as file:
json.dump(listings, file, indent=2)
print(f"Found {len(listings)} listings")
print(f"Saved results to {OUTPUT_FILE}")
if __name__ == "__main__":
main()Si todo está configurado correctamente, debería ver una salida como ésta:
[
{
"zpid": "59174136",
"address": "45 Garden St APT 3, Boston, MA 02114",
"price": "$685,000",
"beds": 2,
"baths": 1,
"sqft": 525,
"status": "FOR_SALE",
"url": "https://www.zillow.com/homedetails/45-Garden-St-APT-3-Boston-MA-02114/59174136_zpid/"
}
]En este punto, tu scraper está funcionando, lo que significa que ahora eres capaz de raspar información clave de cualquier listado de Zillow.
Resolución de problemas comunes
Si rastreas los datos inmobiliarios de Zillow con frecuencia, seguro que en algún momento te topas con algún muro. Yo mismo me he enfrentado a un par de ellos. Por lo tanto, te puedo decir qué esperar, incluyendo:
- Errores403: Significa que Zillow ha bloqueado tu bot. Prueba a cambiar tus cabeceras o a utilizar un proxy para seguir obteniendo datos de Zillow.
- Respuestasvacías: Eso podría deberse a la renderización de JavaScript. Prueba a utilizar una herramienta que renderice completamente la página antes de devolver el HTML, como Web Unlocker.
- Faltan datos: No todos los listados tienen la misma información. Utiliza siempre .get() cuando extraigas datos de Zillow para que tu scraper no se bloquee al faltar una clave.
Como Zillow no ofrece una API gratuita, tendrás que encontrar una forma de evitarlo. Si necesitas una forma fiable de acceder a los datos de los listados de Zillow, la mejor opción es Web Unlocker de Floppydata.
Conclusión
Zillow no parece un sitio de alta seguridad, pero está protegido por PerimeterX y un sistema de detección por capas que vigila tu IP, cabeceras, huella digital TLS y señales de comportamiento. Si actúas de forma sospechosa, serás marcado y bloqueado indefinidamente.
Por lo tanto, es necesario tener cuidado al rasparlo. Aquí es donde entra Floppydata Web Unlocker. Lo:
- Rota los proxies residenciales premium
- Rotación de cabeceras y huella digital real del navegador
- Se carga siempre limpio y con HTML completo
- Sólo se facturan las respuestas positivas
Con esta configuración, no tienes que luchar contra el sistema anti-bot de Zillow por ti mismo; deja que Floppy Data Web Unlocker te ayude. Comience a raspar Zillow ahora con 5 raspados gratis.





