

Introducción
PHP fue uno de mis primeros lenguajes como desarrollador web en su día, y todavía me gusta usarlo para scraping.
Este tutorial cubre lo que realmente uso en producción. Te guiaré a través de un flujo de trabajo completo de raspado web PHP usando Floppydata Web Unlocker como la capa de raspado.
¿Por qué Floppydata?
Porque proporciona una API de scraping que elimina la necesidad de gestionar proxies, cabeceras o lógica anti-bot. Al final de este artículo, usted tendrá un buen conocimiento de cómo realizar web scraping con PHP.
¿Qué es el web scraping PHP?
PHP web scraping es el proceso de utilizar código PHP para extraer datos de sitios web. No todos los sitios ofrecen una API, como Twitter por ejemplo, así que en muchos casos la única forma de obtener la información que necesitas es buscar la página y analizar el HTML tú mismo.
PHP tiene mucho sentido para esto si ya lo utiliza todos los días. Puede colocar los datos raspados directamente en un backend existente, almacenarlos en MySQL o ejecutar el raspador en una tarea cron sin introducir otro lenguaje en la pila.
La cuestión principal no es si PHP puede raspar. Por supuesto que puede. La verdadera pregunta es qué tan bien maneja su scraper las solicitudes bloqueadas, las restricciones basadas en la ubicación y los CAPTCHA agresivos.
Esa es exactamente la razón por la que emparejo PHP con Floppydata Web Unlocker para ayudar a cerrar la brecha.
Bibliotecas PHP de web scraping que merece la pena conocer (2026)
PHP tiene muchas librerías de scraping, pero honestamente, me he decidido por unas pocas que realmente uso. He aquí un rápido vistazo a ellos.
- Guzzle: Un cliente HTTP sólido que maneja peticiones POST, cargas útiles JSON, redirecciones y cabeceras de forma limpia. Lo usaremos a lo largo de este tutorial para hablar con la API de Web Unlocker.
- Symfony DomCrawler: Te permite navegar por HTML y XML usando selectores CSS o XPath. Cuando se combina con el componente symfony/css-selector, proporciona un filtrado de estilo jQuery que funciona de forma fiable en HTML desordenado. Es independiente, por lo que no necesitas el resto de Symfony.
- Symfony HttpBrowser: Es el sustituto moderno de la ya obsoleta librería Goutte. Está construida sobre BrowserKit y DomCrawler, y te permite simular clics, envíos de formularios y cadenas de redireccionamiento. Ideal cuando su lógica de raspado abarca varias páginas.
- DiDOM: DiDOM es un analizador rápido de dependencia cero con una API similar a jQuery. Perfecto para scripts más pequeños en los que quieras evitar tirar de componentes de Symfony.
- Symfony Panther: Controla un navegador Chrome o Chromium real a través de WebDriver. Se utiliza cuando un sitio renderiza todo en JavaScript (React, Vue, SPAs pesadas) y una petición HTTP simple devuelve un shell vacío. Es más pesado, así que sólo lo uso cuando nada más funciona.
Goutte solía ser una recomendación común, pero ahora está obsoleta, por lo que no recomendaría construir un nuevo proyecto en torno a ella.
Para esta guía, Guzzle más Symfony DomCrawler es suficiente. Dado que Web Unlocker ya ejecuta JavaScript y devuelve el HTML renderizado final, no necesitamos ejecutar un navegador headless en nuestro extremo.
Requisitos previos
Antes de escribir cualquier código, asegúrate de tener las siguientes cuatro cosas en su lugar. Si nunca has configurado un proyecto PHP desde cero, no te preocupes, te guiaré a través de cada paso.
1. PHP 8.2 o posterior
PHP viene preinstalado en muchos sistemas Mac y Linux, pero nunca está de más comprobarlo. Abre tu terminal y comprueba tu versión de PHP:
php -vSi PHP ya está instalado, debería ver un número de versión. Para este tutorial, utilice PHP 8.2 o más reciente. Ese es el punto de partida más seguro con las versiones de dependencia que vamos a instalar.
Si falta PHP, siga las instrucciones para instalarlo:
# Windows (Chocolatey, run PowerShell as Administrator)
choco install php
# macOS (Homebrew)
brew install phpDespués de la instalación, ejecute php -v de nuevo para confirmar la versión. En Homebrew, no necesita paquetes separados php-curl o php-xml para este tutorial. Esas extensiones ya están incluidas con la instalación principal de PHP.
2. Compositor
Composer es el gestor de paquetes estándar para PHP. Es básicamente el equivalente de npm o pip para proyectos PHP. Lo usaremos para instalar Guzzle y los paquetes del parser de Symfony.
En primer lugar, compruebe si ya está disponible:
composer --versionSi Composer aún no está instalado, utilícelo:
# Windows (Chocolatey, as Administrator)
choco install composer
# macOS (Homebrew)
brew install composerUna vez hecho esto, composer --version debería imprimir un número de versión, y ya está listo para crear el proyecto.
3. Una cuenta Floppydata
Crea una cuenta en Floppydata y copia tu clave API desde el panel de control. Cada nueva cuenta obtiene 5 scrapes gratuitos para el Web Unlocker.
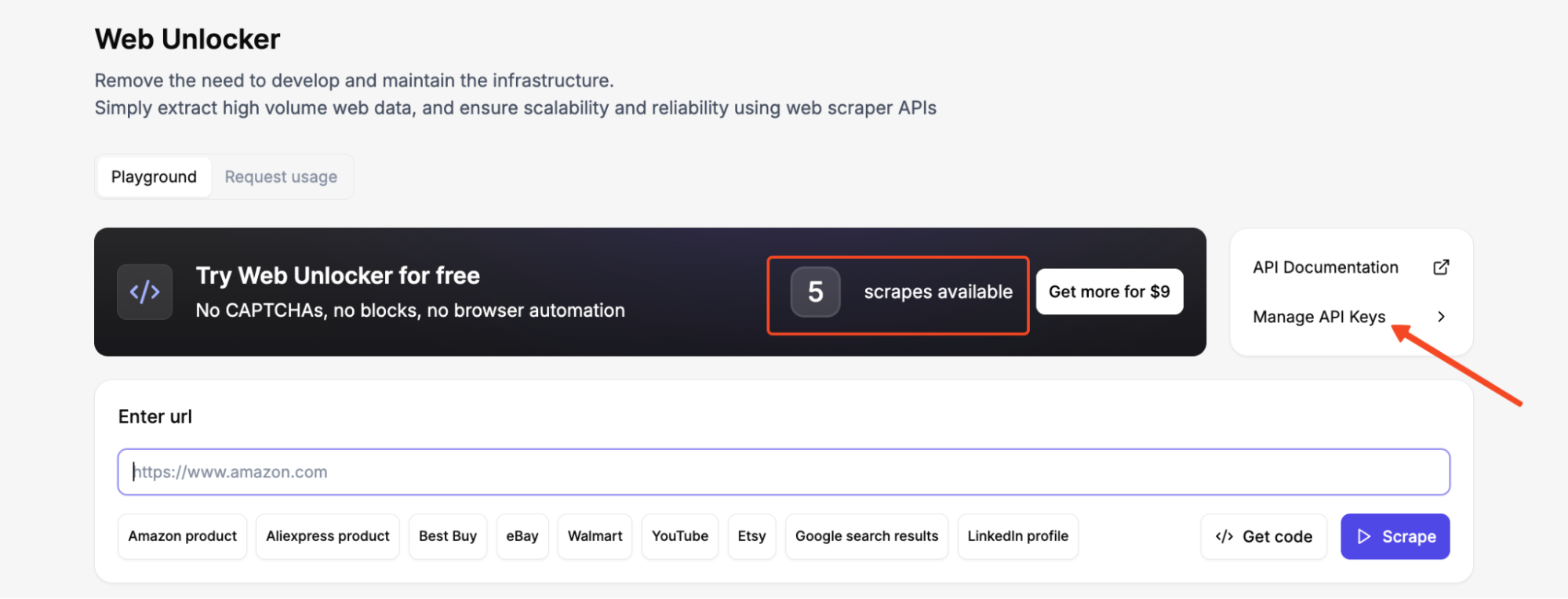
Después de iniciar sesión en su panel de control, vaya a Administrar claves de API en el Desbloqueador Web y genere una clave de API. Cópiala inmediatamente y guárdala en un lugar seguro.
Utilizarás esta clave en la cabecera X-Api-Key de cada petición de Web Unlocker. La añadiremos a nuestro código en unos minutos.
4. Directorio del proyecto y dependencias
Ahora vamos a crear la carpeta donde vivirá nuestro scraper e instalar las librerías PHP que necesitamos. En tu terminal:
mkdir php-scrape-countries
cd php-scrape-countriesInicialice un nuevo proyecto de Composer:
composer init --name="myname/country-scraper" --require="php:^8.2" --no-interactionAhora instala los paquetes que necesitamos:
composer require guzzlehttp/guzzle symfony/dom-crawler:^7.4 symfony/css-selector:^7.4Composer descargará las tres librerías más sus dependencias en una carpeta vendor/ y creará un archivo composer.json que rastrea exactamente qué versiones estás utilizando.
A partir de ahora, cada archivo PHP en el proyecto puede cargar las dependencias con:
require_once __DIR__ . '/vendor/autoload.php';En este punto, la configuración se ha completado, y podemos pasar a la rasqueta en sí.
Cómo scrapear datos con PHP usando Floppydata Web Unlocker
Paso nº 1: Pon a prueba tu objetivo
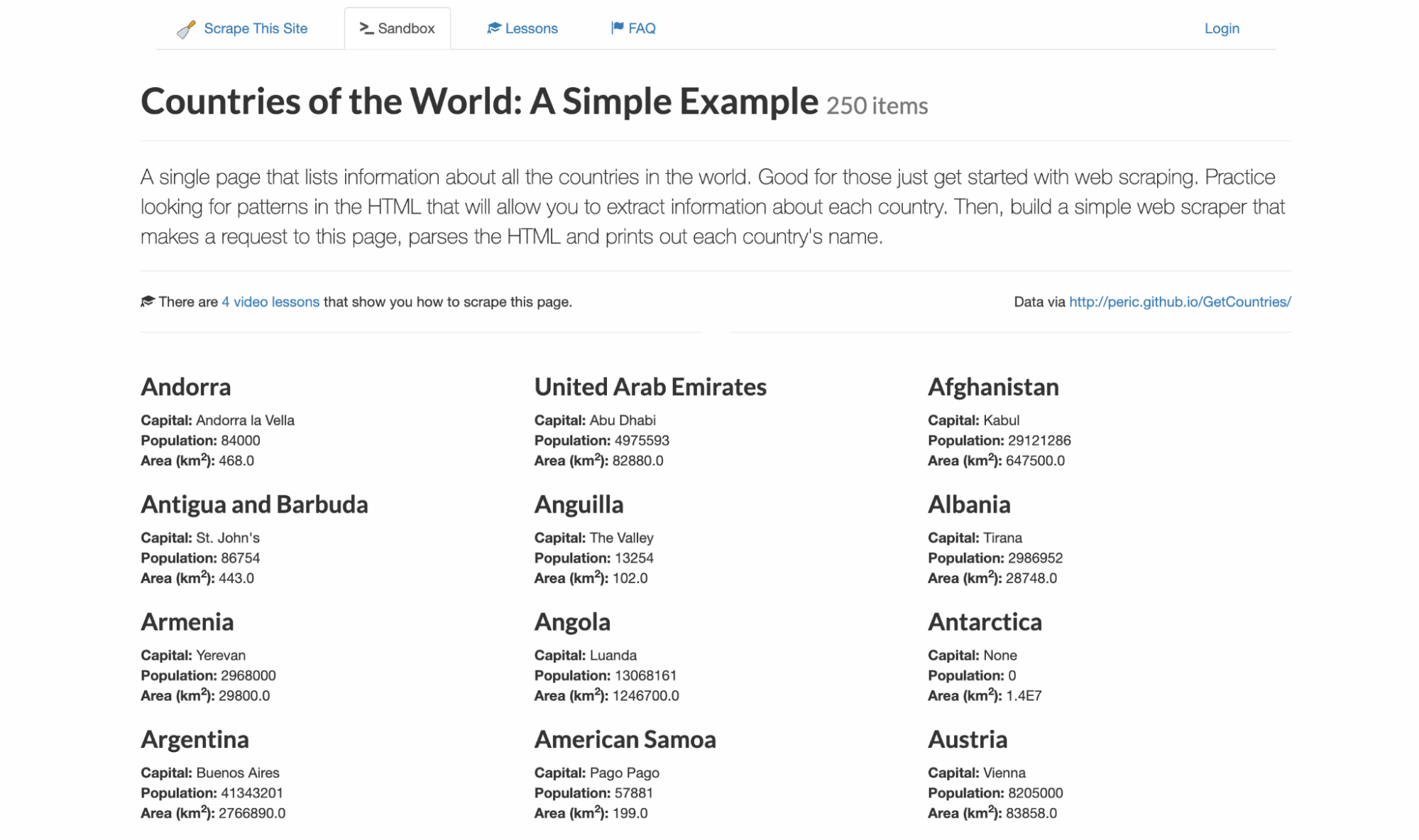
Nunca me gusta escribir código a ciegas para saber exactamente qué selectores y estructura de datos esperar. Para este ejemplo, me centraré en scrapethissite, un sitio de demostración para el scraping de datos. Contiene un listado de los 250 países con su capital, población y superficie.
Para seguir el proceso, visita Floppydata Web Unlocker Playground. Esta herramienta sin código está disponible directamente desde tu panel de control y te permite ver el HTML exacto que devolverá la API sin necesidad de configurar un proyecto.
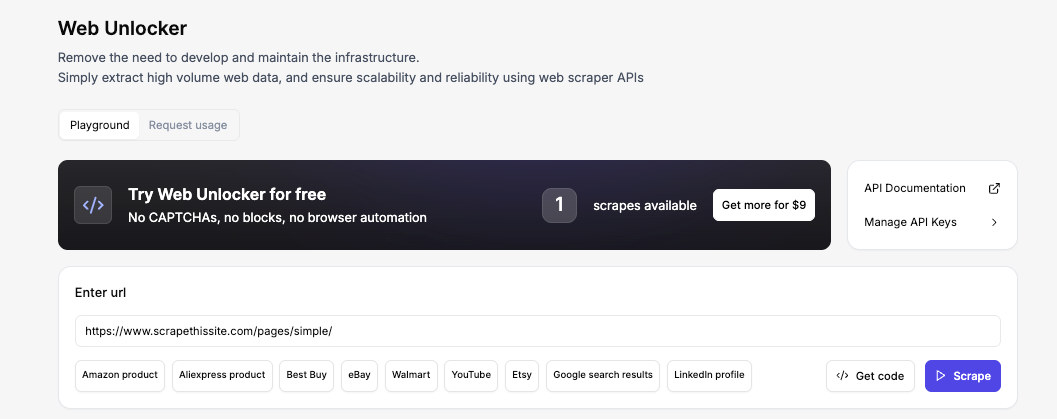
Ahora, introduce la URL y haz clic en Scrape. En unos segundos, verás el HTML completo en la vista previa de salida. Ese es exactamente el mismo HTML que tu script PHP recibirá dentro de unos pasos.
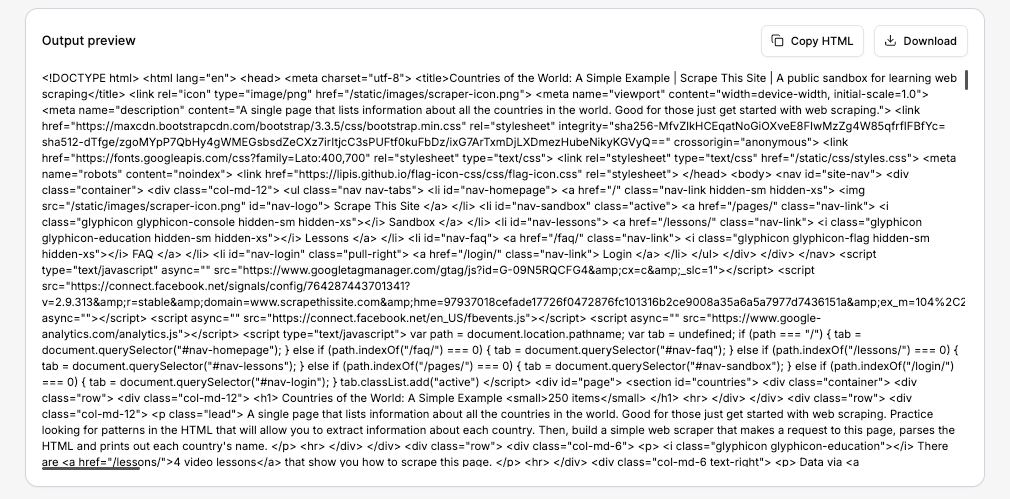
Si los datos parecen correctos, puedes copiar el HTML o descargar la respuesta. Pero en nuestro caso, dejaremos que el script PHP lo haga automáticamente.
Paso 2: Envío de la primera solicitud de desbloqueo web con Guzzle
El núcleo de todo el flujo de trabajo es una solicitud POST al punto final de Floppydata:
https://client-api.floppy.host/v1/webUnlockerPara ello, primero creamos un cliente Guzzle y preparamos la configuración de la petición. Después enviamos la petición y gestionamos la respuesta.
Cree un archivo llamado scrape.php y comience con el esqueleto básico:
<?php
// scrape.php
require_once __DIR__ . '/vendor/autoload.php';
use GuzzleHttp\Client;
$apiKey = 'YOUR_API_KEY'; // Replace with your real key
$targetUrl = 'https://www.scrapethissite.com/pages/simple/';
$client = new Client([
'base_uri' => 'https://client-api.floppy.host',
'timeout' => 60,
]);Sustituya YOUR_API_KEY por su clave real. Ahora construimos la llamada POST real. Enviamos JSON al punto final de la API, incluimos la clave de API en las cabeceras y pasamos la URL de destino más algunos argumentos en el cuerpo:
$response = $client->post('/v1/webUnlocker', [
'headers' => [
'Content-Type' => 'application/json',
'X-Api-Key' => $apiKey,
],
'json' => [
'url' => $targetUrl,
'country' => 'US',
'city' => 'New York',
'difficulty' => 'low',
'expiration' => 0,
],
]);
$payload = json_decode((string) $response->getBody(), true);
$html = $payload['html'] ?? '';
echo "HTML received! Length: " . strlen($html) . " characters\n";Los campos de país y ciudad indican al Desbloqueador Web a través de qué ubicación geográfica debe enrutar la petición. El campo de dificultad controla la agresividad con la que el desbloqueador maneja las protecciones anti-bot. Aquí utilizo el valor bajo porque nuestro objetivo sandbox no tiene ninguna protección.
Para objetivos protegidos detrás de Cloudflare o DataDome, configúrelo como medio para que el desbloqueador aplique una lógica de huella digital y resolución de CAPTCHA más fuerte.
Ahora, tenga en cuenta que el Web Unlocker devuelve el HTML sin procesar dentro de un objeto JSON, lo que significa que necesita decodificar el JSON y extraer el marcado real de la página del campo html.
Si olvidas esto y tratas todo el cuerpo de la respuesta como HTML, tu analizador se romperá. Con esto, el lado de la solicitud se hace, y podemos pasar a analizar.
Paso nº 3: Inspeccionar la estructura de la página
Una vez realizada la solicitud, el siguiente paso es inspeccionar la estructura de la página y seleccionar los elementos repetidos que contienen los datos que deseamos. Cada país de la página sigue exactamente este patrón HTML:
<div class="col-md-4 country">
<h3 class="country-name">
<i class="flag-icon flag-icon-ad"></i>
Andorra
</h3>
<div class="country-info">
<strong>Capital:</strong> <span class="country-capital">Andorra la Vella</span><br>
<strong>Population:</strong> <span class="country-population">84000</span><br>
<strong>Area (km<sup>2</sup>):</strong> <span class="country-area">468.0</span><br>
</div>
</div>Esa estructura repetida es lo que hace que esta página sea maravillosamente predecible. Cada ficha de país utiliza los mismos nombres de clase: .country para la envoltura, .country-name para el encabezamiento y.country-capital, .country-population y .country-area para los campos de datos dentro de .country-info.
Paso 4: Análisis de datos con Symfony DomCrawler
Como las clases son coherentes en las 250 entradas, podemos recorrer cada elemento .country y extraer los valores de los selectores hijos. Pero antes, vamos a añadir una pequeña función de ayuda para limpiar el texto que extraigamos:
use Symfony\Component\DomCrawler\Crawler;
function normalizeText(string $text): string
{
return preg_replace('/\s+/', ' ', trim($text)) ?? trim($text);
}Si observa el código HTML sin formato, verá que los nombres de los países tienen espacios en blanco y nuevas líneas a su alrededor debido a las etiquetas <i> icono de bandera dentro de <h3>.
La función normalizeText( ) ayuda a eliminar los espacios en blanco iniciales y finales y, a continuación, utiliza una regex para contraer los espacios o nuevas líneas restantes, de modo que nombres como Andorra o St. John’s aparezcan de forma limpia en lugar de arrastrar los espacios en blanco sobrantes del HTML.
Con el helper listo, creamos una instancia de Crawler y hacemos un bucle sobre cada tarjeta de país:
$crawler = new Crawler($html);
$countries = [];
$crawler->filter('.country')->each(function (Crawler $node) use (&$countries): void {
$countries[] = [
'name' => normalizeText($node->filter('.country-name')->text()),
'capital' => normalizeText($node->filter('.country-capital')->text()),
'population' => normalizeText($node->filter('.country-population')->text()),
'area' => normalizeText($node->filter('.country-area')->text()),
];
});
echo 'Parsed ' . count($countries) . " countries\n";DomCrawler nos ofrece una forma limpia de movernos por el HTML utilizando selectores CSS. Empezamos envolviendo el HTML en un objeto Crawler y luego filtramos hasta cada bloque .country de la página. Dentro de cada bloque, obtenemos el nombre, la capital, la población y el área.
En este punto, si ejecutas el script, deberías ver «Parsed 250 countries» impreso en el terminal.
Paso nº 5: Exportar los resultados a CSV y JSON
Una vez que el analizador sintáctico le proporciona una matriz $countries, exportar los datos resulta muy sencillo.
$csvHandle = fopen('countries.csv', 'w');
fputcsv($csvHandle, ['Country', 'Capital', 'Population', 'Area (km2)'], ',', '"', '');
foreach ($countries as $country) {
fputcsv($csvHandle, [
$country['name'],
$country['capital'],
$country['population'],
$country['area'],
], ',', '"', '');
}
fclose($csvHandle);
file_put_contents('countries.json', json_encode($countries, JSON_PRETTY_PRINT | JSON_UNESCAPED_SLASHES));La exportación CSV es útil porque proporciona a los lectores un archivo que pueden abrir inmediatamente en Excel, Google Sheets o cualquier otra herramienta de hoja de cálculo. La exportación JSON es igual de útil si quieren introducir los datos raspados en otro script PHP o en una API más adelante.
Una pequeña actualización aquí es el argumento escape explícito en fputcsv(). En las nuevas versiones de PHP, esto evita las advertencias de depreciación y mantiene el ejemplo limpio cuando los lectores lo ejecutan desde el terminal.
Paso nº 6: Juntarlo todo en un guión
Ahora que cada parte funciona por sí sola, aquí está el script completo:
<?php
declare(strict_types=1);
require_once __DIR__ . '/vendor/autoload.php';
use GuzzleHttp\Client;
use Symfony\Component\DomCrawler\Crawler;
function normalizeText(string $text): string
{
return preg_replace('/\s+/', ' ', trim($text)) ?? trim($text);
}
$apiKey = 'YOUR_API_KEY';
$targetUrl = 'https://www.scrapethissite.com/pages/simple/';
if ($apiKey === 'YOUR_API_KEY') {
fwrite(STDERR, "Replace YOUR_API_KEY before running the script.\n");
exit(1);
}
$client = new Client([
'base_uri' => 'https://client-api.floppy.host',
'timeout' => 60,
]);
try {
$response = $client->post('/v1/webUnlocker', [
'headers' => [
'Content-Type' => 'application/json',
'X-Api-Key' => $apiKey,
],
'json' => [
'url' => $targetUrl,
'country' => 'US',
'city' => 'New York',
'difficulty' => 'low',
'expiration' => 0,
],
]);
} catch (Throwable $e) {
fwrite(STDERR, "Request failed: {$e->getMessage()}\n");
exit(1);
}
$payload = json_decode((string) $response->getBody(), true);
if (!is_array($payload) || !isset($payload['html']) || !is_string($payload['html'])) {
fwrite(STDERR, "Unexpected API response. Expected JSON with an html field.\n");
exit(1);
}
$crawler = new Crawler($payload['html']);
$countries = [];
$crawler->filter('.country')->each(function (Crawler $node) use (&$countries): void {
$countries[] = [
'name' => normalizeText($node->filter('.country-name')->text()),
'capital' => normalizeText($node->filter('.country-capital')->text()),
'population' => normalizeText($node->filter('.country-population')->text()),
'area' => normalizeText($node->filter('.country-area')->text()),
];
});
if ($countries === []) {
fwrite(STDERR, "No countries were parsed.\n");
exit(1);
}
$csvHandle = fopen(__DIR__ . '/countries.csv', 'w');
if ($csvHandle === false) {
fwrite(STDERR, "Could not create countries.csv.\n");
exit(1);
}
fputcsv($csvHandle, ['Country', 'Capital', 'Population', 'Area (km2)'], ',', '"', '');
foreach ($countries as $country) {
fputcsv($csvHandle, [
$country['name'],
$country['capital'],
$country['population'],
$country['area'],
], ',', '"', '');
}
fclose($csvHandle);
file_put_contents(__DIR__ . '/countries.json', json_encode($countries, JSON_PRETTY_PRINT | JSON_UNESCAPED_SLASHES));
echo 'Done! Parsed ' . count($countries) . " countries.\n";
echo "Saved countries.csv and countries.json\n";Sustituye ‘YOUR_API_KEY’ y ejecútalo así:
php scrape.phpCuando todo esté configurado correctamente, el script obtendrá la página a través de Web Unlocker, analizará los 250 países y escribirá countries.csv y countries.json en la carpeta del proyecto.
Ver los resultados
Una vez finalizado el script, puede abrir countries.csv inmediatamente. Las primeras filas tendrán el siguiente aspecto:
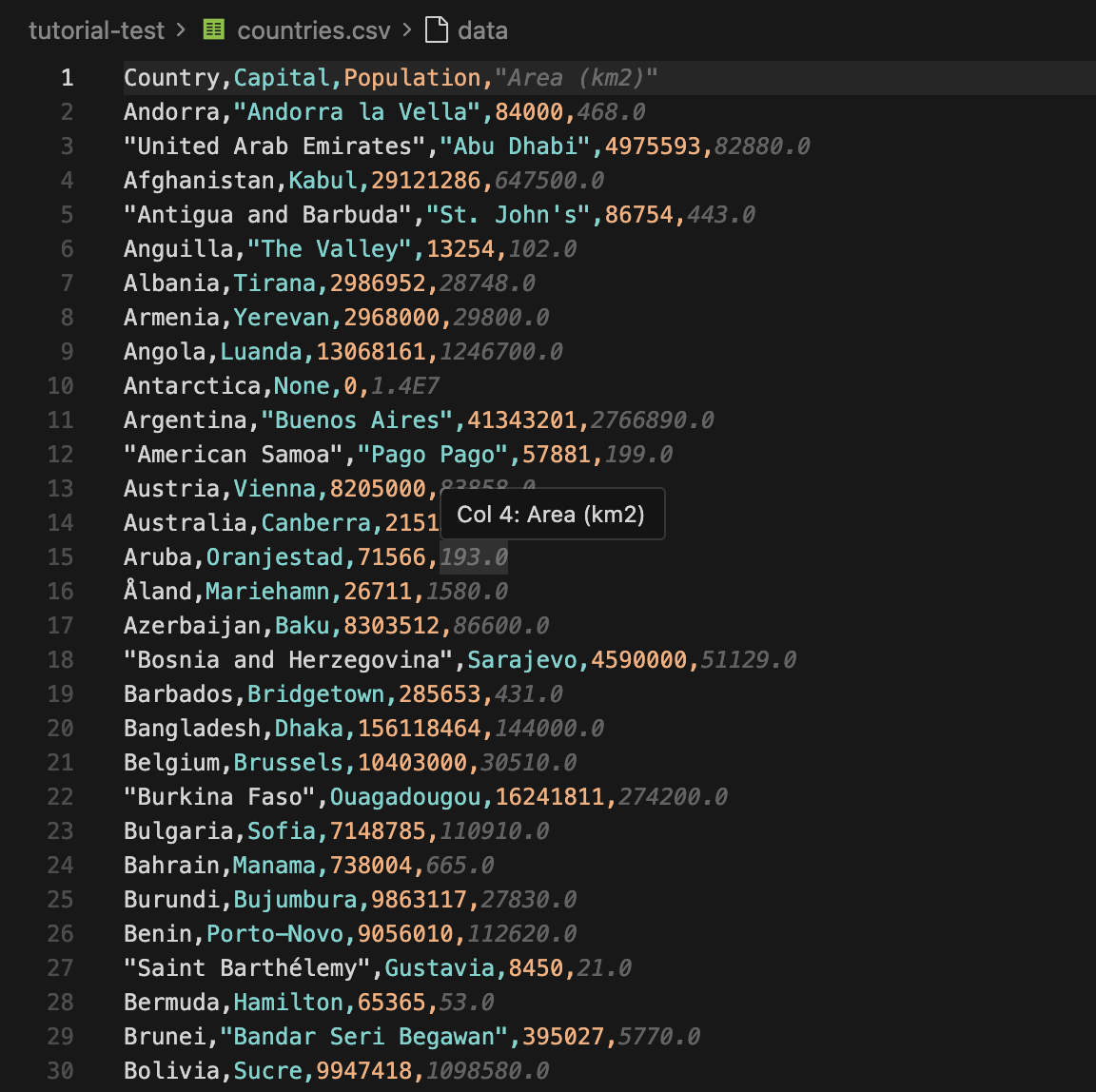
Ahora puede importar el CSV a una hoja de cálculo o enviar el JSON a otra aplicación. Si quieres utilizar este flujo de trabajo para el seguimiento de precios, puedes emparejarlo con los proxies de seguimiento de precios de Floppydata, así que haz bien en comprobarlo.
Medidas contra el chantaje
Una página simple y estática no es difícil de analizar, como acabamos de ver. Pero los sitios protegidos pueden ser un quebradero de cabeza.
Podrías encontrarte con bloqueos, datos que faltan, CAPTCHAs, renderizado de JavaScript o límites de velocidad. Ahí es donde un scraper PHP normal empieza a tener problemas.
Estos son los problemas más comunes a los que puede enfrentarse:
- Bloqueo de IP: Los sitios web pueden bloquear tu dirección IP si detectan varias solicitudes procedentes de la misma IP en un breve periodo de tiempo.
- CAPTCHAs: Los sistemas CAPTCHA se utilizan para diferenciar entre bots y humanos presentando retos difíciles de resolver para los bots.
- Limitación de la tasa: Los sitios web suelen limitar el número de solicitudes que se pueden realizar en un periodo de tiempo determinado para evitar un scraping excesivo.
- Detección de agentes de usuario: Los agentes de usuario ajenos al navegador se bloquean porque no se parecen a los visitantes reales.
- Desafíos de JavaScript: El contenido sólo se carga tras la ejecución de JavaScript, algo que una petición HTTP simple puede pasar por alto.
Puede intentar resolver estos problemas manualmente, pero no es conveniente ni escalable.
Ahí es donde entra Floppydata Web Unlocker. En lugar de resolver cada desafío usted mismo, puede descargar toda la capa anti-bot y centrarse en extraer y almacenar los datos.
Floppydata Web Unlocker se encarga:
- Rotación de IP con un gran grupo de proxies residenciales y de centros de datos
- Huella digital del navegador y navegadores sin cabeza
- Procesamiento de JavaScript para páginas dinámicas
- Reintentos automáticos y resolución de CAPTCHA
- Segmentación geográfica por ciudades
Si necesita más control, Floppydata también ofrece proxies residenciales estáticos para el scraping de sesiones largas y proxies de centros de datos para el trabajo de volumen a alta velocidad.
Pero para la mayoría de las páginas protegidas, Web Unlocker es la forma más rápida de pasar de una petición bloqueada a HTML analizable.
Reflexiones finales
PHP es un lenguaje muy capaz para el web scraping, y por ahora, usted debe tener una base sólida en web scraping con PHP.
Detendré este tutorial en este punto ya que es una introducción al web scraping con PHP. En futuros tutoriales, vamos a ampliar nuestro scraper para que pueda seguir enlaces, manejar la paginación, y raspar objetivos más complejos.
Si mientras tanto quieres saber más sobre el web scraping, consulta estos recursos:
¿Listo para probar Web Unlocker? Empiece hoy mismo con 5 raspados gratuitos y raspe cualquier cosa sin quebraderos de cabeza.






