

Java es ideal para construir pipelines de scraping rápidos y escalables gracias a su rendimiento, ecosistema y multi-threading. Herramientas como jsoup funcionan bien para HTML estático, pero los sitios web modernos se basan en sistemas anti-bot, CAPTCHAs, proxies y renderización de JavaScript, lo que hace que el scraping independiente de Java sea poco fiable. En 2026, lo mejor es utilizar Java como capa de control (solicitudes, análisis sintáctico, lógica) y confiar en una API de scraping como Floppydata para gestionar la infraestructura, desbloquear las solicitudes y escalar de forma fiable.
Por qué el Web Scraping en Java es una opción poderosa
Java es una opción sólida para el web scraping debido a su velocidad, escalabilidad e infraestructura de apoyo. He probado Python, Go y NodeJS para el scraping, pero Java siempre ha demostrado ser mucho mejor en el manejo de trabajos de scraping a nivel de producción. Python es ideal para el análisis sintáctico y la manipulación de datos debido a sus amplias bibliotecas de manejo de datos, pero Java se destaca por su raspado HTML estático.
Prefiero Java para trabajos de scraping a escala de producción por:
- La velocidad: Java es más rápido que los lenguajes interpretados como Python.
- Ecosistema: Puedes conectar herramientas profesionales como Apache HttpClient y bases de datos.
- Multiproceso: El ExecutorService de Java simplifica el scraping multi-threading.
Para los backends Java que deseen implantar un sistema de scraping maduro, la biblioteca jsoup de Java es una gran opción. Puede extraer contenido HTML y XML de páginas web y refinarlo utilizando las bibliotecas de manipulación de datos de Java sin necesidad de herramientas adicionales para el análisis de datos.
Muchas herramientas famosas de raspado de datos de comercio electrónico utilizan jsoup para rastrear productos y palabras clave de la competencia mediante el despliegue de trabajos de automatización a gran escala a través de Java y jsoup.
Infraestructura Java esencial para Web Scraping
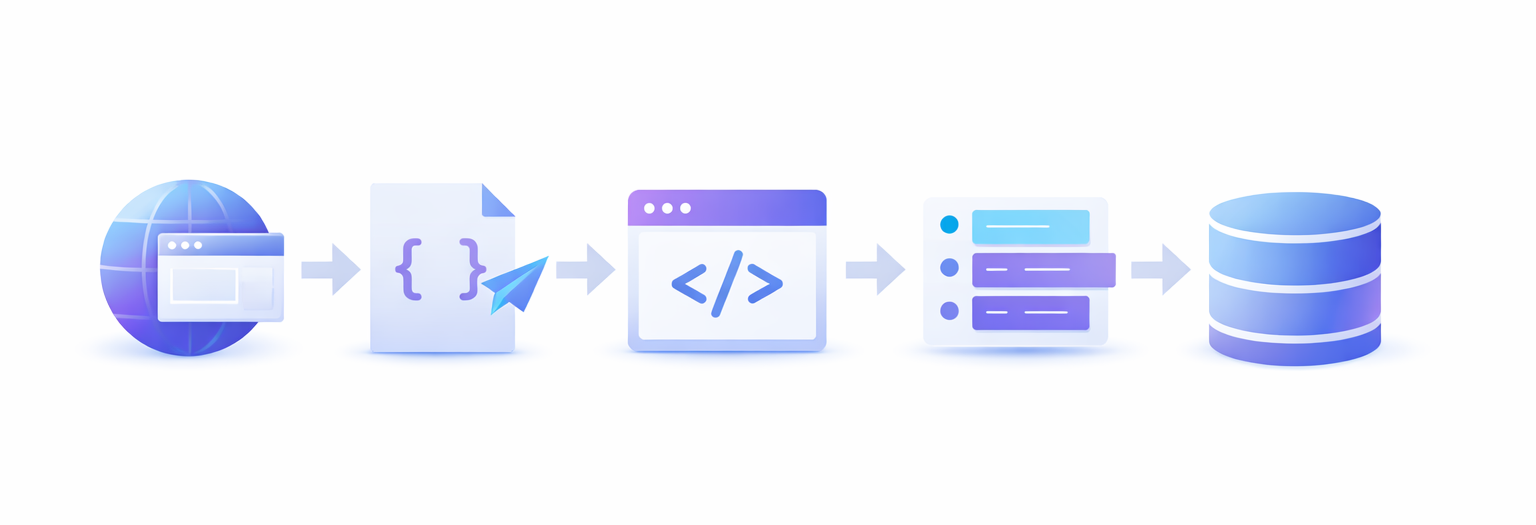
Java cuenta con un ecosistema maduro y admite miles de bibliotecas e integraciones. Las bibliotecas clave que soportan el web scraping son jsoup, Apache, Jackson, Gson y otras bibliotecas de manipulación de datos. Java también admite consultas a bases de datos dentro del código a través de JDBC.
Jsoup: Biblioteca Java de Web Scraping
Jsoup es la columna vertebral del web scraping con Java (para páginas web HTML). Jsoup le proporciona una sintaxis de selector similar a la de CSS que le ayuda a extraer todo tipo de contenido HTML del documento extraído.
Jsoup es rápido, tiene una sintaxis sencilla y gestiona por sí mismo los enlaces rotos.
Código de ejemplo:
Document doc = Jsoup.parse(html);
String title = doc.select("title").text();
String price = doc.select(".price").text();Si desea analizar una página web, primero debe obtenerla. Java no puede simplemente navegar por una página. Se necesita un servidor HTTP para hacer una solicitud de una página web específica, y luego el servidor web responde con el contenido de la página web. Esto es lo que alimentas a jsoup para empezar a extraer datos.
También puede usar los métodos HTTP propios de Java en lugar de Apache HttpClient, pero no es tan escalable. Apache maneja los tiempos de espera de sesión, los reintentos y los agentes de usuario y las cookies.
Jackson y Gson
Jackson y Gson son dos bibliotecas Java distintas. Estas bibliotecas le ayudan a convertir el texto extraído en bruto en datos limpios y procesables, como precios de productos con títulos o precios de productos en determinadas categorías de un sitio web de comercio electrónico. Jackson maneja mejor las grandes automatizaciones de scraping que Gson, que está diseñada para tareas pequeñas y ligeras.
¿Cuáles son las desventajas de utilizar Java para el Web Scraping?
Ahora que ya conoces un poco las capacidades de scraping de Java, vamos a discutir dónde te decepcionará. En 2026, no podrás confiar únicamente en librerías como jsoup y Apache HttpClient para trabajos de scraping escalables.
Hay dos problemas fundamentales a los que se enfrenta cuando realiza el scraping únicamente con Java:
- Los sitios web te bloquean: Los sitios web están ahora más a la defensiva. Se preocupan de si el visitante de su sitio web es una persona real o un bot que carga innecesariamente el servidor y extrae datos del cliente sin permiso. A los sitios web ya no les gustan los scrapers.
- Las páginas JS-Heavy no se pueden extraer: Jsoup y otros marcos de extracción funcionan muy bien para páginas HTML. Esto puede incluir páginas de productos y otras páginas web de comercio electrónico / blogs, pero muchos sitios web han comenzado a poner fragmentos de código JavaScript para añadir animaciones y efectos visuales interesantes para el sitio web. Jsoup no está diseñado para extraer páginas con mucho código JS, por lo que la extracción falla o devuelve resultados irrelevantes.
Ambos problemas tienen solución. Los raspadores web tienen diferentes estrategias y marcos de trabajo para evitar ser bloqueados por cualquier sitio web, y raspar fácilmente páginas con mucho JS. Sin embargo, el proceso no es tan sencillo como ejecutar unas pocas líneas de código jsoup y Apache.
La forma moderna de hacer web scraping en Java
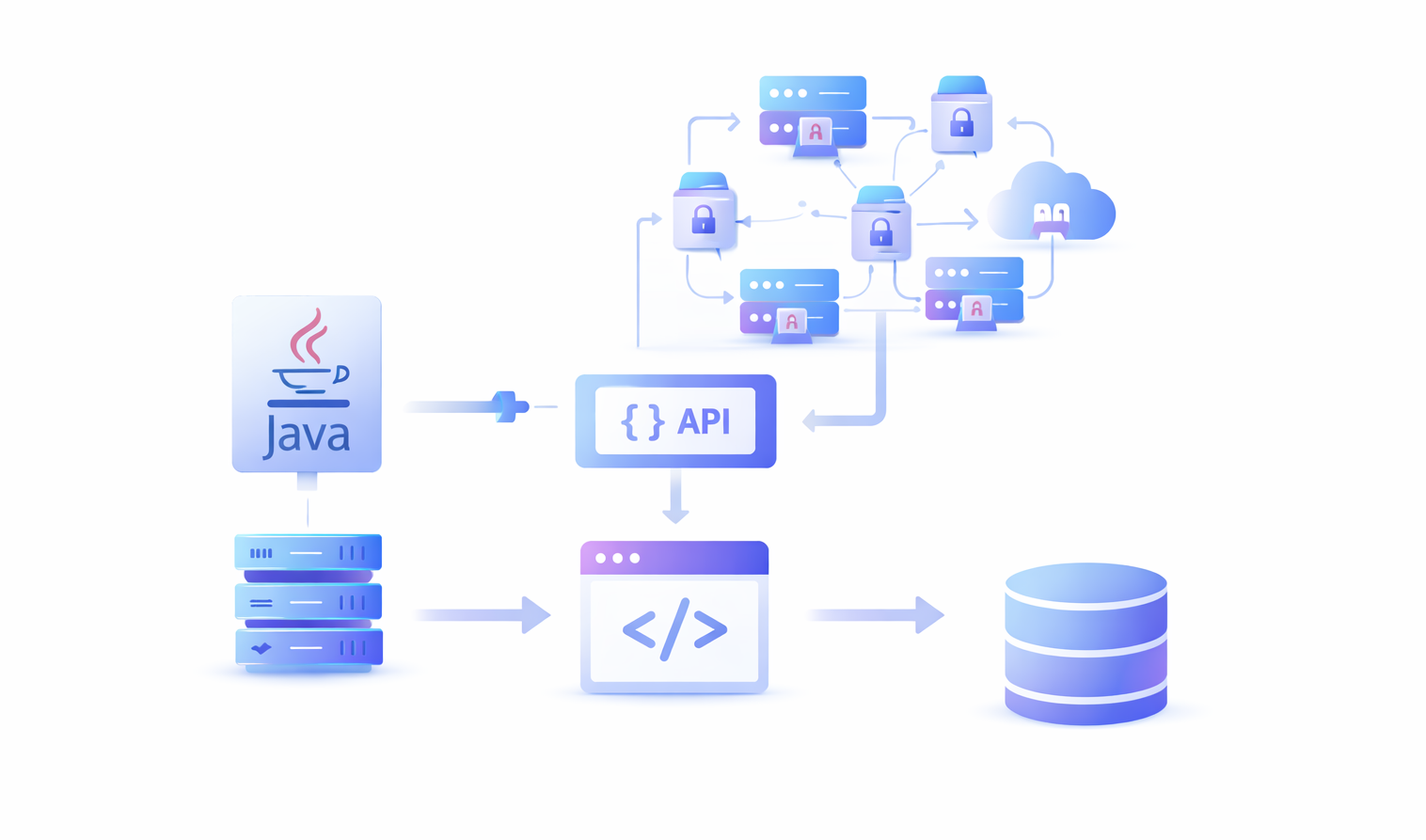
Las bibliotecas Java independientes no son suficientes para el web scraping en 2026. Ya no se trata de páginas HTML estáticas. Estamos tratando con sistemas anti-bot, CAPTCHAs, redirecciones, cookies, animaciones de diseño y diseños de texto con Java Script y mucho más.
Para crear una automatización de raspado exitosa y escalable, necesita combinar Java con otras tecnologías de raspado de última generación. Aquí hay una lista de cosas clave que necesita junto con el código Java para ejecutar una automatización de raspado web exitosa:
- Un grupo de proxies: Los sitios web rastrean a cada visitante por su dirección IP. Cuando un muro de red como Cloudflare descubre que un usuario está haciendo scraping de datos, lo primero que hace es bloquear la dirección IP para que no pueda acceder al sitio web. Esta es la razón por la que necesitas un grupo de proxies seguros y lógica Java para cambiar de proxy cada pocas peticiones para evitar ser baneado.
- Solucionador CAPTCHA: Los CAPTCHAs existen para expulsar a los bots de la plataforma. Los scrapers tradicionales no pueden resolver CAPTCHAs. Codificar un solucionador CAPTCHA en Java o cualquier otro lenguaje es casi imposible. Por eso necesita un solucionador CAPTCHA de terceros.
- Perfiles de huellas dactilares de dispositivos: Plataformas como Facebook y LinkedIn despliegan sistemas de detección aún más avanzados. Estos sistemas no solo se basan en las direcciones IP para detectar posibles señales de scraping, sino que rastrean la huella digital del dispositivo, el comportamiento del usuario, los saltos de proxy y la vinculación de cuentas. Por eso es necesario cambiar la huella digital del navegador junto con los proxies para evitar que se prohíba el acceso del dispositivo a la plataforma.
- Herramientas para extracciones pesadas de JS: Incluso si te saltas todos los sistemas de detección, muchas páginas web modernas están desarrolladas utilizando frameworks Javascript pesados como ReactJS y NextJS. Herramientas como jsoup y otros scrapers tradicionales no pueden extraer contenido de estas páginas. Usted necesita una herramienta adicional de esta parte para ayudar con la conversión de JS a HTML.
El scraping en Java no está muerto. Sigue siendo muy útil si añades tu propia infraestructura como proxies, solucionadores CAPTCHA y convertidores de páginas JS. O, la forma más ideal de saltarse todas estas integraciones es utilizar una API de raspado web como Floppydata.
Guía: Cómo hacer Web Scraping con Java en 2026
En 2026, Java debería utilizarse para respaldar la infraestructura de scraping mediante la recepción de solicitudes, la organización de datos sin procesar, el análisis sintáctico de datos sin procesar para convertirlos en datos estructurados y procesables, y la gestión de otros casos extremos y lógicas como la rotación de proxy, los reintentos, los mensajes de impresión, las advertencias, etc.
Si estás intentando scrapear páginas web modernas con jsoup, puede que falles entre un 40% y un 50% de las veces. Sin embargo, Java debería usarse por su velocidad, integraciones y multi-threading, no por la librería jsoup.
Así pues, una vez que esté preparado para utilizar Java como capa de control de su raspador, vamos a sumergirnos en el método de raspado web más sencillo y eficaz en 2026.
Paso 1: Obtener una API Web Scraper
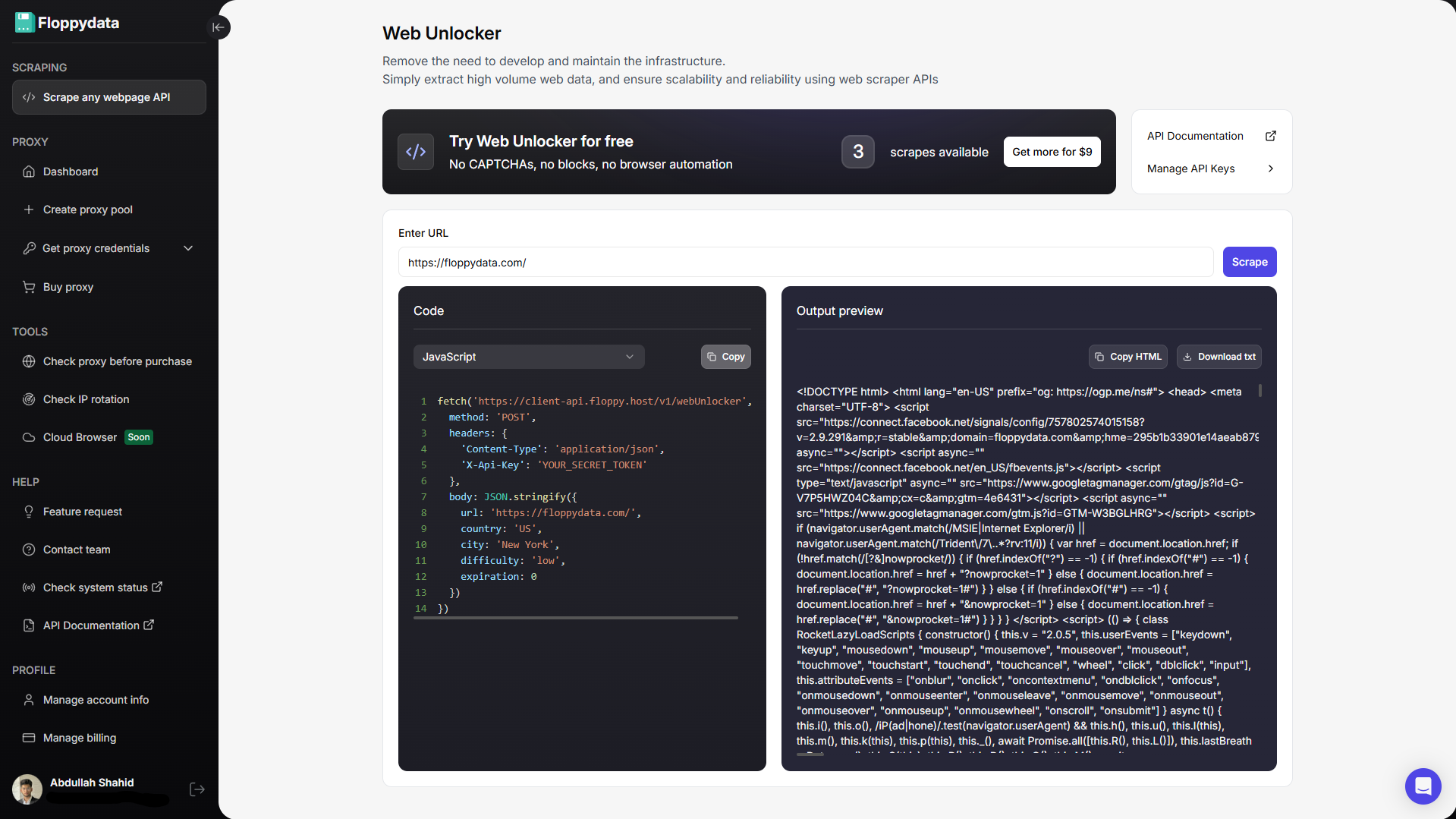
En lugar de intentar utilizar el raspador de Java, utilice una API de raspador web de confianza. Una API web scraper recibe la URL de su página web, le envía una solicitud, gestiona los CAPTCHA, convierte la página web en datos sin procesar y la devuelve. La API del raspador web se encarga del trabajo pesado del servidor HTTP, los reintentos, los CAPTCHA, los errores, la carga útil incorrecta, los proxies rotatorios y la huella digital del dispositivo.
En Java, se escribe el resto de la infraestructura de canalización, como la creación de colas multihilo de enlaces para explorar, la extracción de etiquetas útiles del contenido HTML y su almacenamiento de forma estructurada, o la realización de otras funciones sobre los datos extraídos.
Puede leer nuestra reseña sobre los mejores servicios de scraping para encontrar el más adecuado para su caso de uso.
Paso 2: Añadir API Key en Java Code Snippet
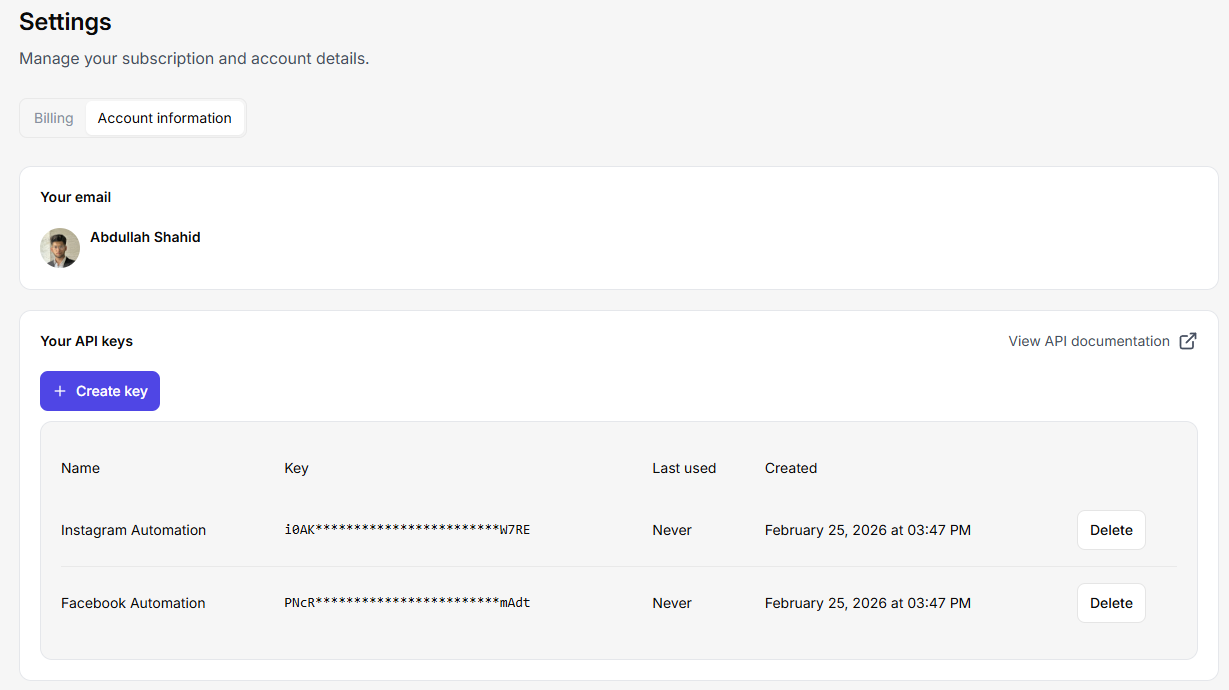
Obtenga la clave API de su servicio de raspado web. Vamos a integrarla en Java. Puedes crear múltiples claves API en Floppydata yendo a tu configuración > cuenta > botón ‘crear clave’. Puedes enviar cientos de peticiones concurrentes en esta API y crear un trabajo de scraping multi-threading que maneje miles de páginas web a la vez.
Dado que Floppydata ejecuta sus trabajos de raspado web en la nube, también se quita de encima toda la carga de abrir un navegador web y ejecutar bibliotecas de raspado en su dispositivo. Si tuvieras que gestionar toda la infraestructura de scraping, necesitarías mucha RAM y potencia de procesamiento.
La API de cliente de Floppydata utiliza una cabecera X-Api-Key, y el punto final documentado Web Unlocker acepta una url y parámetros adicionales como el país, la ciudad, la dificultad y la caducidad de la caché. La respuesta incluye contenido HTML que puedes analizar en Java.
He aquí un ejemplo de fragmento de código que me gusta utilizar:
public class Floppydatascraper {
public static void main(String[] args) throws Exception {
String apiKey = System.getenv("FLOPPY_API_KEY");
String payload = """
{
"url": "https://example.com",
"country": "US",
"difficulty": "medium",
"expiration": 0
}
""";
HttpClient client = HttpClient.newBuilder()
.connectTimeout(Duration.ofSeconds(20))
.build();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://client-api.floppy.host/v1/webUnlocker"))
.header("X-Api-Key", apiKey)
.header("Content-Type", "application/json")
.POST(HttpRequest.BodyPublishers.ofString(payload))
.build();
HttpResponse<String> response =
client.send(request, HttpResponse.BodyHandlers.ofString());
System.out.println(response.body());
}
}Paso 3: Mejore su proceso de raspado de Java
Ahora que ya tienes la clave API integrada, construye tu canal de scraping en torno a ella. Por ejemplo, si tienes una herramienta de comercio electrónico que explora Amazon en busca de productos relevantes en torno a la palabra clave objetivo, extrae su título, etiquetas, descripción, etc. y muéstraselo al usuario. Scraper API es el mejor enfoque y el más escalable. Incluso si tienes miles de clientes enviando solicitudes simultáneas a tu aplicación, la API de Floppydata puede gestionarlas fácilmente.
Puede añadir más funciones en torno a los datos extraídos, como utilizar una clave de API de IA para escribir una descripción y un título similares, o analizar palabras clave similares de todos los resultados extraídos, etc. Toda esta infraestructura debe construirse en Java.
Navegación Headless en Java sin Selenium o Puppeteer
Tradicionalmente, los scrapers utilizaban Selenium y Puppeteer para ejecutar sesiones de navegador sin cabeza, gestionar proxies y la lógica de scraping. Sin embargo, este proceso es más pesado, más lento y se rompe en la producción bajo carga pesada porque se requiere una infraestructura escalable en la nube para manejar la creciente demanda de solicitudes. Se acaba perdiendo tiempo en la construcción de la infraestructura que se puede obtener de estas API de raspado extremadamente baratas como Floppydata. Además, estas herramientas de scraping han sido probadas para garantizar su fiabilidad y escalabilidad, y evolucionan constantemente con el mercado para que no tenga que cambiar su canal de scraping cada 4 meses.
Con la API de Floppydata, necesitas:
- sin gestión local del navegador
- sin flota de navegadores headless
- sin mantenimiento de selenio
- sin configuración de Puppeteer
- sólo lógica de petición Java más análisis sintáctico HTML
Todo ello por entre 0,45 y 0,9 dólares por cada 1.000 resultados obtenidos. Es más barato que mantener sus propias máquinas en la nube. Ver precios detallados.
Reflexiones finales
Si alguien me pidiera hoy que construyera un pipeline de web scraping en Java, tardaría entre 20 y 30 minutos. Obtendría la clave de la API de Floppydata y redactaría los requisitos de mi canalización, incluyendo lo que quiero hacer con los datos raspados y cómo quiero almacenarlos. A continuación, utilizaría Claude Code para crear una sólida canalización de raspado. Dado que no estoy configurando ninguna infraestructura de scraping, puedo probar rápidamente mediante la ejecución de este script si mi pipeline está funcionando o no.
Java es una opción excelente para crear sistemas de web scraping escalables y multihilo, incluso con sus limitaciones. Pero en 2026, las librerías básicas de web scraping no tendrán ninguna oportunidad contra los sistemas anti-bot potenciados por IA que las plataformas despliegan para mantener alejados a los scraper. Necesitas una herramienta de scraping igualmente moderna y potente para desplegar una automatización de scraping exitosa.






