


Reddit Web Scraping ist der Prozess des Sammelns öffentlich verfügbarer Daten auf der Plattform. Zu den gesammelten Daten können Beiträge, Profile, Kommentare und mehr gehören. Das manuelle Sammeln von Reddit-Daten kann zeitaufwendig, fehleranfällig und ineffizient sein. Daher automatisieren Forscher, Vermarkter und SEO-Experten das Reddit-Scraping häufig mit Bots oder Skripten. Die Verwaltung mehrerer Reddit-Konten für das Scraping kann die Verwendung eines Proxys erfordern. Um die Datenextraktion zu erleichtern, verfügt Reddit über eine öffentliche API. Allerdings sind Ihre Möglichkeiten sehr begrenzt, wenn Sie Reddit mit der API scrapen, und zwar aus mehreren Gründen. Erstens setzt die API Ratenbeschränkungen ein, die die Anzahl der Anfragen, die Sie innerhalb eines bestimmten Zeitraums senden können, begrenzen. Außerdem sind häufig Authentifizierungsdaten erforderlich, was den gesamten Prozess verlangsamen kann.
Wie funktioniert ein Reddit Scraper?
Um Reddit-Daten zu scrapen, sendet der Scraper HTTP-Anfragen an die Plattform. In der nächsten Phase werden die HTML- oder JSON-Antworten geparst. Dann werden die erforderlichen Elemente wie Benutzer-ID oder Kommentare extrahiert. Schließlich werden die extrahierten Daten bereinigt und in einem vordefinierten Format gespeichert. Zu den öffentlich verfügbaren Daten, die Sie auf Reddit scrapen können, gehören:
- Posttitel
- Benutzernamen
- Kommentare (Themen und Antworten)
- Bewertungen ( Upvotes und Downvotes)
- Metadaten des Subreddits
- Zeitstempel und Bearbeitungshistorie
Zu den Herausforderungen bei der Verwendung eines Reddit-Scrapers gehören CAPTCHAs, blockierte IPs, verschachtelte Kommentarbereiche und Ratenbeschränkungen. Hier spielen optimierte Tools eine entscheidende Rolle, um Ihre Scraping-Aktivitäten auf die nächste Stufe zu heben.
Wo erhalten Sie Reddit Scraper?
Scraper können grob in 2 (zwei) Gruppen eingeteilt werden – Code Scraper und No-Code Scraper. Die Code-Scraper verwenden eine Programmiersprache wie Python, CSS, Java usw., um ein Skript zu erstellen, das die Datenextraktion automatisiert. Diese Option erfordert einige Programmierkenntnisse und technisches Know-how, um einen Code zu schreiben, mit dem CAPTCHA und Ratenbeschränkungen für eine effektive Datenextraktion umgangen werden können. Sie können auch ein Skript für einen Reddit Image Scraper schreiben, wenn das Ziel nur darin besteht, Bilder auf der Seite zu extrahieren.
Andererseits ist die No-Code-Option eine Lösung, die keine Codierung oder ein umfassendes Verständnis von Programmiersprachen erfordert. Für diejenigen, die eine einfache Möglichkeit suchen, Reddit zu scrapen, sind die No-Code-Tools sehr nützlich. Sie verfügen über verschiedene Funktionen, mit denen Sie in wenigen Schritten Daten von Plattformen wie Reddit extrahieren können. Einer der zuverlässigsten Anbieter für diese No-Code Scraping-Lösung ist Floppydata. Dieses Tool optimiert den Prozess der Datenbeschaffung von Reddit mit Funktionen, die CAPTCHA und IP-Sperren umgehen und so für ein reibungsloses Erlebnis sorgen. Das Tool Web Unblocker von Floppydata eignet sich hervorragend für die Skalierung großer Datenmengen, ohne dass Sie Automatisierungsbrowser wie Selenium, Puppeteer oder Playwright benötigen.
Der Web Unblocker von Floppydata ist ein Tool, das Web Scraping vereinfacht, indem es Sperren und CAPTCHAs automatisch umgeht. So können Sie Daten sammeln, ohne dass eine Browser-Automatisierung oder die manuelle Einrichtung eines Proxys erforderlich ist. Einige seiner Funktionen sind:
- Automatisiertes CAPTCHA lösen
- Umgehen Sie Anti-Bot-Mechanismen mit seinem fortschrittlichen Browser-Fingerprinting
- Extrahiert effizient Daten aus dynamischen Websites
- Eingebaute automatische Proxy-Rotation und Wiederholungslogik zur Wahrung der Anonymität.
Ein weiterer Punkt, den Sie bei der Anschaffung eines Scrapers berücksichtigen sollten, ist der Preis. Floppydata ist bestrebt, hochwertige Lösungen zu erschwinglichen Preisen anzubieten. Daher bietet Floppydata seinen Web Unblocker zu äußerst wettbewerbsfähigen Preisen an. Es gibt zwar eine kostenlose Testversion, diese ist jedoch auf 5 (fünf) Scraps begrenzt. Es gibt vier Preisstufen und sie umfassen:
- Wachstumsplan – Ab $0,98 pro 1k Ergebnisse
- Professional Plan – Ab $0,75 pro 1k Ergebnisse
- Geschäftsplan – Ab $0,60 pro 1k Ergebnisse
- Premium Plan – Ab $0.45 pro 1k Ergebnisse
- Benutzerdefinierter Plan – Wenden Sie sich an den Kundendienst, um einen individuellen Plan zu erhalten.
Vorteile des No-Code Scrapers von Floppydata
- Auch nicht-technische Benutzer können es problemlos benutzen
- Enthält integrierte Funktionen für IP-Rotation, CAPTCHAs und dynamische Inhalte
- Liefert Daten in Formaten wie CSV oder JSON zur einfachen Verarbeitung
- Kostengünstige Optionen für Einzelpersonen und KMU
- Schnelle Datenlieferung
Nachteile
- Begrenzte Flexibilität bei der Anpassung
Andere Alternativen zum Scraping von Reddit-Daten
Lassen Sie uns kurz andere Methoden analysieren, die zum Scrapen von Reddit-Daten verwendet werden können:
Die offizielle API von Reddit
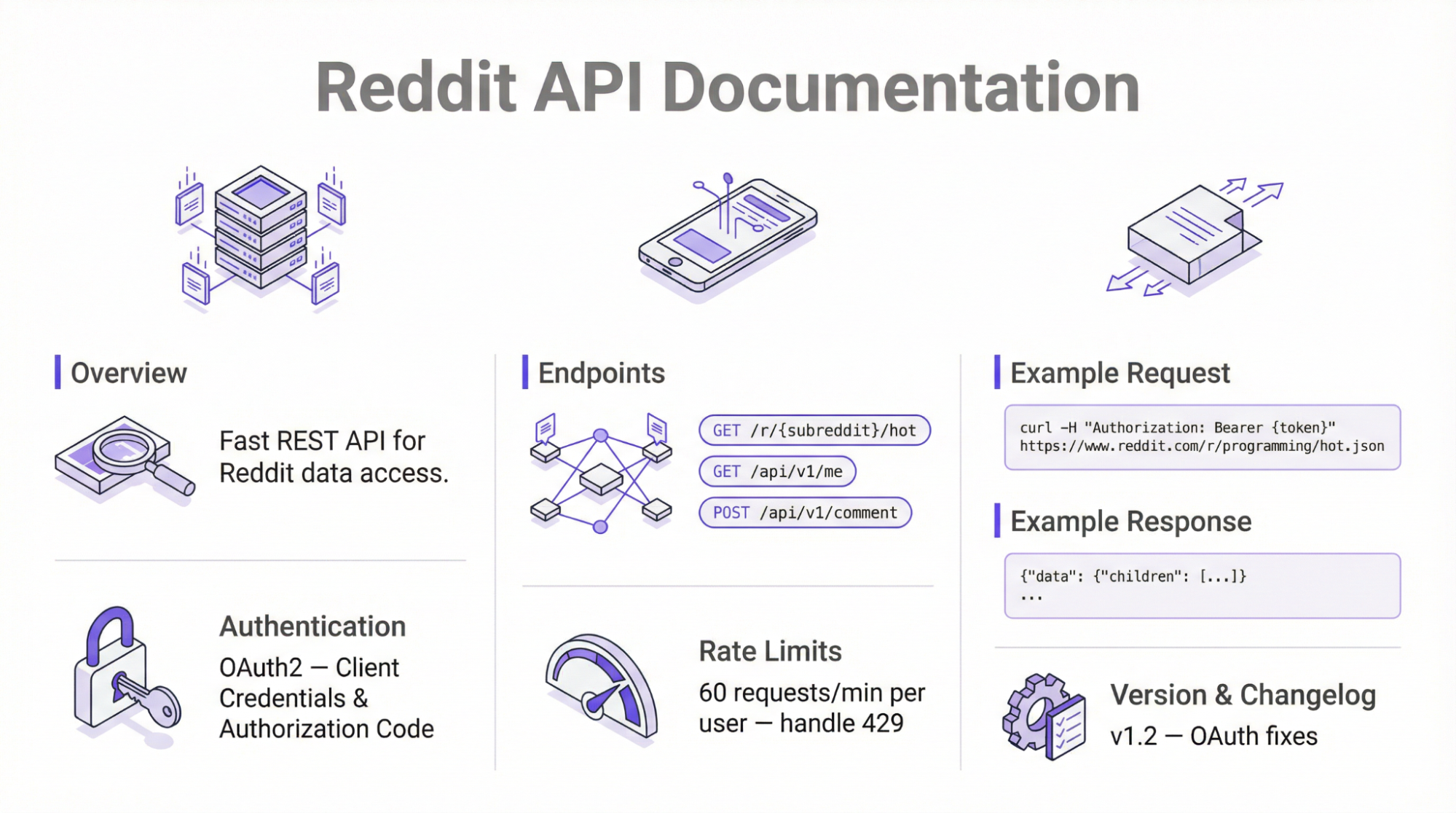
Wenn Sie die Plattform ohne Tools von Drittanbietern scrapen möchten, sollten Sie die offizielle API verwenden. Bei diesem Ansatz werden die JSON-API-Endpunkte von Reddit verwendet, um öffentlich verfügbare Informationen über einfache HTTP-Anfragen abzurufen.
Die Nutzung der offiziellen API erfordert eine OAuth2-Authentifizierung und erzwingt die Tarifbeschränkungen – 100 QPM für die kostenlose Stufe. Gemäß den 2025 eingeführten Richtlinien-Updates erfordert die API vor dem Abruf von Daten eine manuelle Genehmigung durch die Plattform.
Folgen Sie den nachstehenden Schritten, um die offizielle API von Reddit für die Datenerfassung zu verwenden:
- Registrieren, um API-Zugang zu erhalten
Der erste Schritt besteht darin, sich bei Ihrem Reddit-Konto anzumelden oder eines zu erstellen, wenn Sie ein neuer Benutzer sind. Besuchen Sie die Seite Reddit Apps, klicken Sie auf „Eine App erstellen“ und folgen Sie den Anweisungen auf dem Bildschirm. Sobald dies erfolgreich war, öffnet sich ein neues Fenster mit Ihrer Client-ID, Ihrem Client-Geheimnis und dem User-Agent-String.
- Authentifizierung
Verwenden Sie OAuth, um ein Zugriffstoken zu erhalten. Für diesen Schritt können Sie entweder eine Programmierbibliothek verwenden, z. B. die PRAW-Bibliothek von Python, und sich bei der API authentifizieren. Alternativ können Sie auch die Anfragebibliothek verwenden, was eine manuelle Handhabung der Zugriffstoken erfordert.
- HTTP-Anfragen stellen
Der nächste Schritt ist die Verwendung eines Frameworks wie der Python Request Library, um GET-Anfragen an verschiedene Endpunkte zu senden.
- Daten parsen und speichern
Die Rohdaten werden extrahiert und im JSON-Format verarbeitet, damit sie leicht lesbar sind.
N.B.: Das oben beschriebene Verfahren ist nur für einfache Scraping-Aufgaben effizient. Außerdem erfordert es gute Kenntnisse von Programmiersprachen und Kodierung.
Vorteile der offiziellen API von Reddit
- Es bietet offiziellen und zuverlässigen Zugang zu Reddit-Servern, um Daten zu sammeln
- Es handelt sich um eine Beschwerde gegen die Nutzungsbedingungen der Plattform
- Geringes Risiko von Sperren, vorausgesetzt, Sie überschreiten nicht das Tariflimit
- Unterstützt die Extraktion von öffentlich zugänglichen Daten ohne Anti-Scraping-Beschränkungen.
Nachteile der offiziellen API von Reddit
- Die Daten sind sehr begrenzt
- Nicht geeignet für Personen mit geringen oder keinen Programmierkenntnissen
- Ratenbeschränkungen machen es schwierig, den Scraping-Prozess zu skalieren
- Die Extraktion größerer Datenmengen kann recht teuer sein
Python verwenden

Python ist eine Programmiersprache mit einer umfangreichen Bibliothek, die Web Scraping unterstützt. Für Reddit Scraping verwenden die meisten Entwickler PRAW (Python Reddit API Wrapper), um mit dem Server zu interagieren und Daten zu extrahieren.
Um jedoch Daten zu extrahieren, die über die Grenzen der API hinausgehen, werden Frameworks wie BeautifulSoup verwendet. Sie spielen auch eine wichtige Rolle beim Parsen von HTML-Daten und deren Bereitstellung im XML- oder JSON-Format.
Die Struktur von Reddit ändert sich häufig, was die Leistung des Scrapers beeinträchtigen kann. Daher muss der Scraper regelmäßig aktualisiert werden, um sich an die Änderungen auf der Plattform anzupassen.
Beste Praktiken für die Verwendung eines Python Reddit Scrapers
IP-Adresse rotieren
Einer der Hauptzwecke der rotierenden IP-Adressen ist die Anonymität. Außerdem kann die Plattform erkennen, wenn wiederholte Anfragen von der gleichen IP-Adresse ausgehen. Dies kann eine IP-Sperre auslösen, was eine vollständige Datenerfassung erschwert.
CAPTCHA Handhabung
Ein Python Reddit Scraper ist nicht in der Lage, CAPTCHAs zu verarbeiten, die auftauchen können, damit die Plattform zwischen menschlichen und Bot-Aktivitäten unterscheiden kann. Um CAPTCHAs zu umgehen, verwenden Sie Headless-Browser wie Selenium, Playwright und Puppeteer, um das menschliche Surfverhalten zu imitieren. Dadurch wird es schwieriger, automatisierte Aktivitäten zu erkennen.
Verwendung von Headless Browsern für dynamische Inhalte
Ähnlich wie moderne Websites verwendet Reddit JavaScript, um dynamische Inhalte zu laden. Normale Scraper analysieren in der Regel nur HTML-Inhalte und sind möglicherweise nicht in der Lage, dynamische Inhalte zu laden. Eine Möglichkeit, damit umzugehen, ist die Integration von Headless Browsern wie Selenium
Vorteile der Verwendung von Python
- Da es sich um eine Open-Source-Bibliothek handelt, ist sie kostenlos
- Hochgradig anpassbar
- Zuverlässig
Nachteile der Verwendung von Python Scrapers
- Erfordert Python-Programmierkenntnisse
- Beschränkt auf öffentliche Daten
- Eingeschränkt auf Reddit’s API Grenzen
Anwendungsfälle von Reddit-Daten
Reddit Web Scraping bietet Zugang zu Daten, die für verschiedene Zwecke verwendet werden können. Einige der häufigsten Anwendungsfälle sind:
Marktforschung
Viele Fachleute sammeln Reddit-Daten für die Marktforschung. Die gesammelten Informationen können sortiert und analysiert werden, um die Marktstimmung, aktuelle Trends und den Ruf verschiedener Marken zu verstehen. Daher können die Daten in Entscheidungen interpretiert werden, die die Produktwerbung, die Verpackung und die Preisgestaltung für den Zielmarkt beeinflussen.
Finanzielle Analyse
Die meisten Menschen sind sich nicht bewusst, dass es auf Reddit eine ganze Gemeinschaft von Finanzexperten gibt. Von Finanzthemen, die Aktien, Kryptowährungen und internationale Märkte betreffen, hält Reddit eine große Menge an Daten bereit. Eine Finanzanalyse ist notwendig, bevor Sie eine größere Investition tätigen, um das Risiko von Verlusten zu minimieren. Diese Daten können extrahiert, analysiert und interpretiert werden, um die Marktprognosen zu verstehen und fundierte Finanzentscheidungen zu treffen.
KI und maschinelles Lernen
Daten von Reddit können zum Trainieren von LLMs (Large Language Models) verwendet werden, um KI-gesteuerte Suchergebnisse zu verbessern. KI-Bots können nur so viel leisten wie die Daten, die sie erhalten. Daher ist Reddit mit seinen täglich hohen Besucherzahlen eine ideale Datenquelle. Ein Beispiel ist die Reddit-eigene KI, ein LLM, das mit Daten von der Plattform gefüttert wird, um personalisierte Seiten für jeden Besucher bereitzustellen.
Sozialforschung
Ein weiterer Anwendungsfall von Reddit-Daten ist die Sozialforschung. Das Sammeln von Subreddit-Daten kann für Studien über das Muster menschlicher Interaktion verwendet werden. Die Sozialforschung kann genutzt werden, um Daten über Trends und Meinungen zu Themen wie Online-Datenschutz und Einwilligung zu sammeln. Darüber hinaus können die Daten verwendet werden, um Chatbots zu trainieren, die einen 24/7-Support anbieten können, der mit menschlichen Support-Mitarbeitern nicht möglich wäre.
Wie man Reddit-Daten mit Floppydata Web Unblocker scrappt
Die Verwendung von Floppydatas Web Unblocker als Reddit Scraper ist einfach und kann in wenigen Schritten durchgeführt werden. Hier finden Sie eine Schritt-für-Schritt-Anleitung, wie Sie Reddit-Daten mit Floppydata scrapen können.
Legen Sie los!
Schritt 1: Besuchen Sie die Seite Web Unblocker und melden Sie sich an, um loszulegen.
Schritt 2: Melden Sie sich bei Ihrem Reddit-Konto an. Öffnen Sie eine Suchergebnisseite mit spezifischen Filtern, die auf Ihren Anwendungsfall abgestimmt sind.
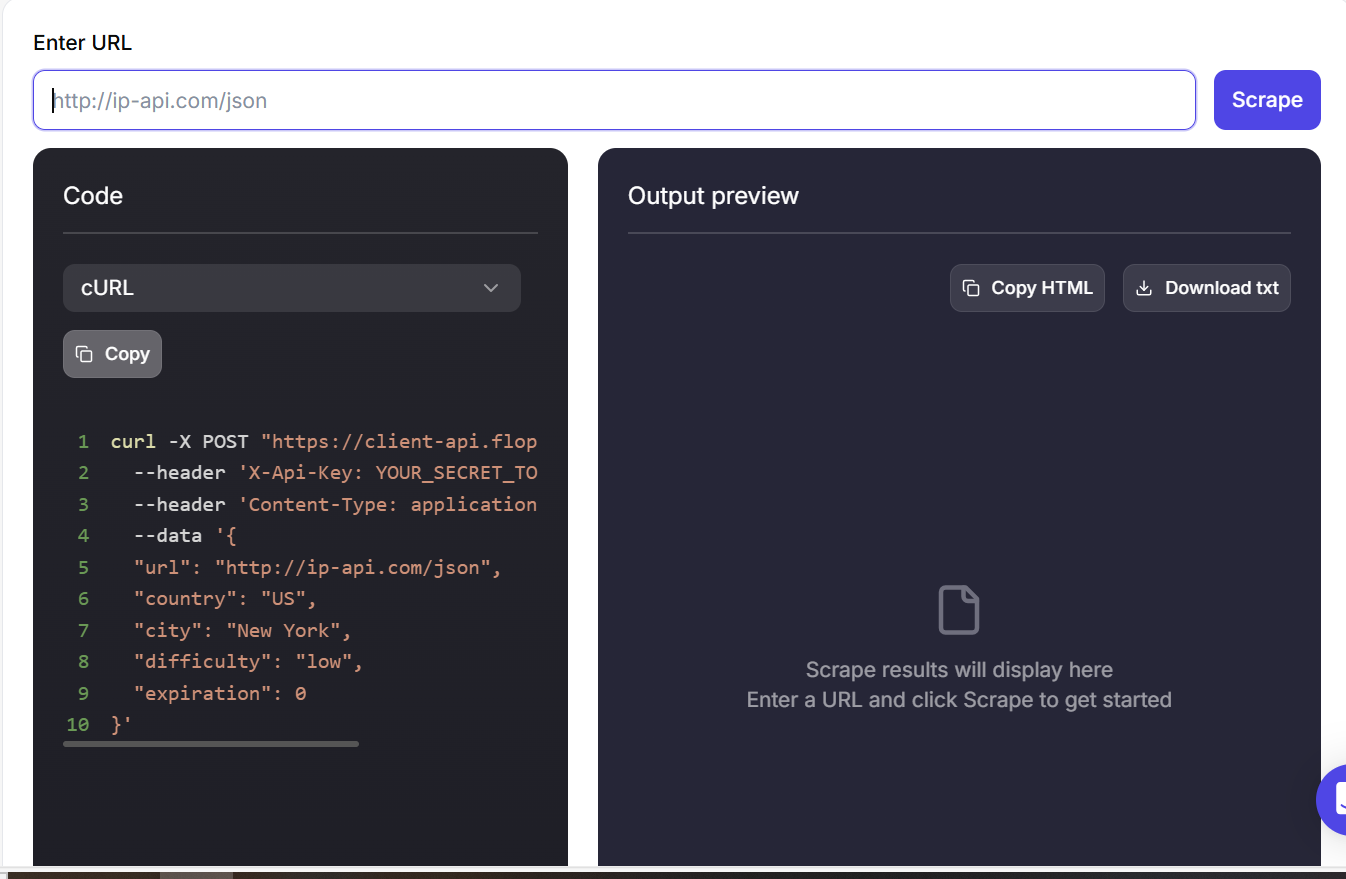
Schritt 3: Gehen Sie zum Floppydata’s Web Unblocker Dashboard und fügen Sie die URL ein
Schritt 4: Ihre Ergebnisse sind innerhalb weniger Minuten fertig.
Fazit
Wenn Sie lernen, wie man Reddit-Daten scrappt, kann dies für Forscher, Einzelpersonen und Unternehmen von großem Nutzen sein. Auf diese Weise können Sie Erkenntnisse aus einer der größten globalen Communities im Internet gewinnen. Um diese Daten zu sammeln, können Sie entweder ein Skript mit einer Programmiersprache schreiben oder eine no-code Lösung verwenden.
Floppydata bietet eine umfassende, codefreie Scraping-Lösung – Web Unblocker, die effektiv Daten von Reddit extrahiert und in Ihrem bevorzugten Format liefert. Neue Benutzer erhalten bis zu 5 kostenlose Sitzungen zum Sammeln von Daten von jeder Plattform.
Wenn Sie ein einfaches und nahtloses Erlebnis beim Scrapen von Reddit-Daten wünschen, probieren Sie noch heute den Web Unblocker von Floppydata aus!





