


Daten sind heute für viele Organisationen in verschiedenen Sektoren ein wichtiges Gut. Dennoch gibt es viele Unternehmen, die Daten schneller sammeln, als sie sie verarbeiten können. Die Techniken der Datenerfassung und -verarbeitung beeinflussen die Entscheidungen im Geschäftsbetrieb.
Da sich die Qualität der Eingabe auf die Ausgabe auswirkt, müssen Sie sicherstellen, dass Ihr System Daten von guter Qualität erhält. Aus diesem Grund benötigen Sie eine gute Dateneingabe-Pipeline-Architektur , um verwertbare Erkenntnisse zu gewinnen.
In diesem Leitfaden werden wir die Pipelines für die Datenaufnahme, die Arten der Datenaufnahme und gängige Anwendungsfälle näher beleuchten.
Was ist Data Ingestion?
Eine der häufigsten Fragen, die man sich stellt, wenn man versucht, die Ingestion-Pipeline zu verstehen, lautet: „Was ist Datenerfassung?“
Der Begriff Data Ingestion beschreibt den Prozess des Sammelns, Sortierens und Organisierens von Daten aus verschiedenen Quellen in einem zentralen Speicher – wie einem Datahub oder Warehouse. Dieser Prozess ist der erste Schritt bei der Vorbereitung von „Rohdaten“ für die weitere Verarbeitung und Interpretation. Die Datenaufnahme ist ein sehr wichtiger Schritt in der Pipeline, da in diesem Stadium Daten aus verschiedenen Quellen gesammelt werden, die sich darauf auswirken, wie Unternehmen Produkteinblicke und Wettbewerbsvorteile gewinnen.
Einige der üblichen Datenquellen für die Pipeline sind:
- Datenbanken
- Internet der Dinge
- Datenzentren
- Plattformen für soziale Medien
- API
- Daten von Drittanbietern
- SaaS-Anwendungen
Vorteile von Data Ingestion
Jedes Unternehmen, unabhängig von seiner Größe, kann von der Datenerfassung profitieren, da sie Einblicke in Markttrends, Verbraucherstimmungen, innovative Strategien und vieles mehr bietet. Hier finden Sie einige der häufigsten Vorteile der Datenübernahme:
Verfügbarkeit von Daten
Einer der Vorteile der Datenaufnahme besteht darin, dass die Notwendigkeit von Datensilos entfällt. Dies fördert die Datenverfügbarkeit für Analysen, indem Daten aus verschiedenen Quellen in einer einzigen zentralen Quelle zusammengeführt werden.
Skalierbarkeit
Mit dem Wachstum von Unternehmen wächst auch ihr Bedarf an qualitativ hochwertigen Daten. Daher spielen Dateneingabe-Pipelines eine zentrale Rolle bei der Verarbeitung großer Datenmengen und gewährleisten gleichzeitig deren Gültigkeit, Genauigkeit und Zuverlässigkeit.
Analytik in Echtzeit
Ein weiterer Vorteil der Dateneingabe-Pipeline ist, dass die Daten sofort oder in Stapeln verarbeitet werden, was den Zugang zu aktuellen Erkenntnissen ermöglicht. So können Unternehmen schnell auf Trends reagieren und rechtzeitig Entscheidungen treffen, die sich auf die Gesamtgewinnspanne auswirken können.
Effizienz
Da die Dateneingabe-Pipelines automatisiert sind, entfällt die Notwendigkeit der manuellen Datenverarbeitung. Dies spart Zeit und Ressourcen, da der Prozess des Datenimports und der Datenspeicherung rationalisiert wird, während sich das Team auf andere vorrangige Aufgaben konzentrieren kann.
Arten der Dateneingabe
Das Sammeln von Daten aus verschiedenen Quellen in einem zentralen Speicher klingt recht einfach. Es kann jedoch etwas komplizierter sein, insbesondere für die Datenpipeline. Im Folgenden finden Sie die gängigsten Arten der Datenübernahme:
Batch-Ingestion
Dies ist der Prozess, bei dem eine große Menge an Daten in bestimmten Intervallen erfasst wird. Diese Intervalle können stündlich, täglich oder sogar wöchentlich sein, je nachdem, was Sie für die Datenerfassung benötigen. Batch Data Ingestion eignet sich daher für Unternehmen, die keine Echtzeitdaten für die Entscheidungsfindung benötigen.
Dies sind die Art von Unternehmen, die bequem arbeiten und Entscheidungen auf der Grundlage regelmäßiger Datenaktualisierungen treffen können.
Ingestion in Echtzeit
Diese Technik erfordert, dass die Daten genau zu dem Zeitpunkt empfangen werden, zu dem sie erstellt werden. Diese Technik ermöglicht daher den Erhalt frischer Dateneinblicke, die für die Entscheidungsfindung sehr wichtig sind. Real-Time Ingestion hilft, die Verzögerung zwischen dem Empfang und der Verarbeitung der Daten zu verringern. Einige der Anwendungsfälle für Echtzeitdaten sind die Erkennung von Betrug, die Datenverarbeitung von Sensoren und die Aktualisierung von Dashboards in Echtzeit. Die Pipeline für die Datenaufnahme in Echtzeit kann Daten in Echtzeit oder in Stücken verarbeiten, während sie extrahiert werden. Obwohl diese Technik frische Daten liefert, ist die Handhabung von Fehlern und die Skalierbarkeit ein komplexes Thema.
Lambda Architektur
Die Lambda-Architektur kombiniert Batch- und Echtzeit-Ingestion und bietet so ein ausgewogenes Verhältnis zwischen Geschwindigkeit und Genauigkeit. Die Batch-Daten liefern umfassende historische Trends, während die Echtzeitdaten Einblicke in aktuelle Aktivitäten bieten.
Der Lambda-Ansatz wird häufig in Situationen verwendet, in denen große Datenmengen mit hoher Genauigkeit verarbeitet werden müssen. Er ermöglicht es Unternehmen, schnell auf aktuelle Ereignisse zu reagieren, ohne das Wissen über frühere Marktereignisse zu verlieren.
Was ist die Data Ingestion Pipeline?
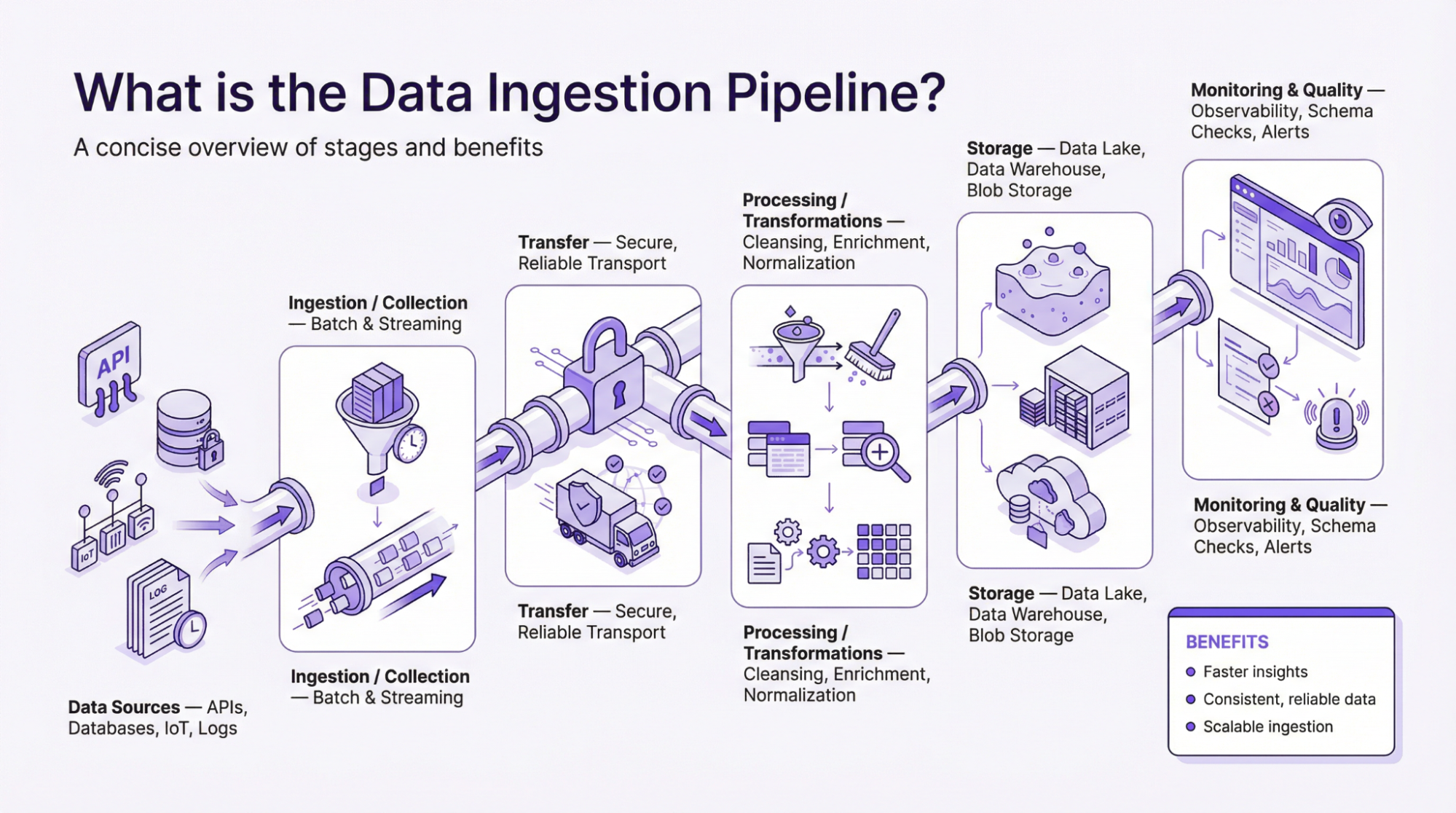
Zur Hauptfrage„Was ist eine Dateneingabe-Pipeline?“ – Die Pipeline, die oft als Rahmenwerk beschrieben wird, beschreibt den Datenfluss von der Erfassung bis zur Verarbeitung und Anwendung der Daten, um evidenzbasierte Entscheidungen zu treffen. Eine Datenpipeline ist einfach die Art und Weise, wie Informationen von einem Ende zum anderen fließen. Es handelt sich um eine Reihe von Anweisungen, die Daten aus verschiedenen Quellen sammeln, verarbeiten und an ein Ziel senden. Daher ist eine ordnungsgemäße Dateneingabe-Pipeline notwendig, damit Unternehmen Daten effektiv nutzen können, um Wachstum, Gewinn und ROI zu steigern.
Schritte zum Aufbau einer effektiven Datenverarbeitungspipeline
Hier sind einige wichtige Schritte zum Aufbau einer effektiven Datenverarbeitungspipeline:
- Bestimmen Sie die Datenquellen: Der erste Schritt beim Aufbau einer effektiven Datenverarbeitungspipeline besteht darin, die Datenquelle zu bestimmen. Bevor Sie Datenquellen definieren, müssen Sie zunächst die Art der Daten, das Volumen, die Geschwindigkeit und die Unternehmensziele festlegen. Die Wahl guter und nachhaltiger Datenquellen spielt eine Rolle für die Genauigkeit und Zuverlässigkeit des Outputs.
- Wählen Sie Datenziel: Als nächstes müssen Sie das Ziel der Daten bestimmen. Das ist der Ort, an dem Sie alle Daten, die Sie aus verschiedenen Quellen erhalten, speichern werden. Das Zielsystem kann ein Data Lake, ein Warehouse oder eine andere Art von Speicher sein, die Sie bevorzugen.
- Wählen Sie die Datenübernahme-Methode: Es gibt verschiedene Arten von Dateneingabemethoden. Daher müssen Sie diejenige auswählen, die am besten zu den individuellen Anforderungen Ihres Unternehmens passt. Je nach Ihren Geschäftszielen können Sie zwischen Batch-Ingestion, Stream-Ingestion oder einer Mischung aus beidem wählen.
- Entwerfen Sie den Ingestionsprozess: Bei dieser Methode wird festgelegt, wie die Daten gesammelt, verarbeitet und im Zielsystem gespeichert werden. In der heutigen digitalen Welt wird der Ingestionsprozess automatisiert, um die Effizienz zu steigern und menschliche Fehler zu reduzieren. Ein weiterer Grund für die Automatisierung des Prozesses ist die Konsistenz. Die Automatisierung des Datenflusses in der Pipeline stellt sicher, dass die Daten wie geplant weitergeleitet werden, um Engpässe zu vermeiden.
- Überwachung und Wartung: Sobald der Prozess der Datenübernahme implementiert ist, müssen Sie seine Leistung überwachen. Dazu gehört die Implementierung von Warnmeldungen für fehlgeschlagene Aufgaben. Eine regelmäßige Überwachung hilft dabei, Probleme zu erkennen und umgehend zu beheben, um eine konsistente Datenverfügbarkeit zu gewährleisten.
Daten-Pipeline-Architektur
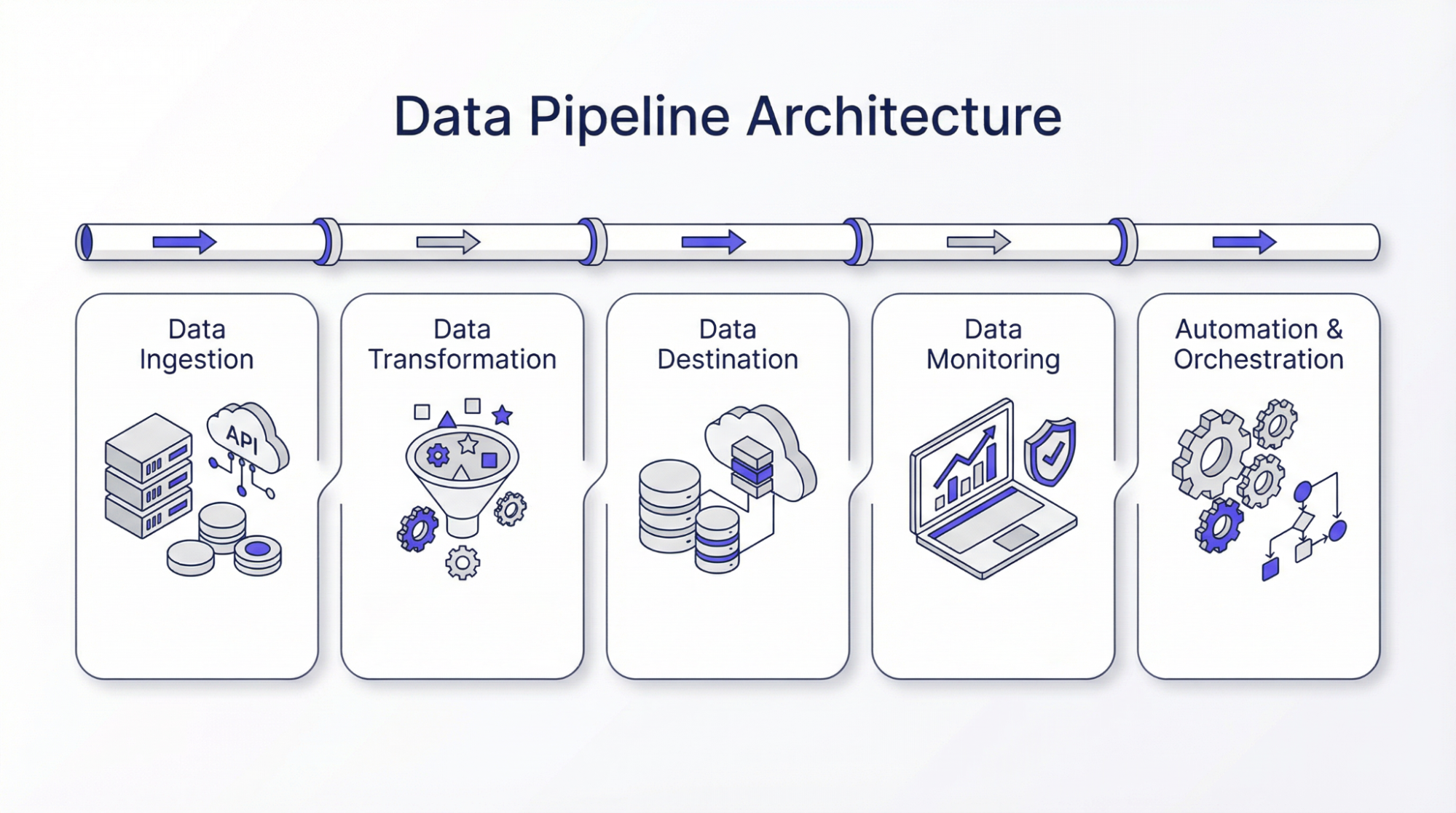
Nachfolgend finden Sie die einzelnen Schritte der Datenpipeline-Architektur:
Dateneingabe
Der erste Schritt in der Datenpipeline-Architektur ist die Sammlung von Daten aus verschiedenen Quellen. Eine gute Datenqualität hat immer Priorität, da sie die Authentizität des gesamten Prozesses beeinflusst. Die aufgenommenen oder gesammelten Daten können je nach Technologie strukturiert oder unstrukturiert sein. Es gibt Leute, die es vorziehen, Daten nur bei Bedarf zu sammeln, während es andere gibt, die Daten sammeln und sie speichern. Dies hilft ihnen, ihre historischen Daten zu aktualisieren, und sie können die Daten zum Vergleich verwenden. In diesem Stadium werden verschiedene Mechanismen eingesetzt, um die Zuverlässigkeit und Genauigkeit der Daten zu gewährleisten. Die Implementierung von Maßnahmen, die die Ausfallsicherheit und Skalierbarkeit fördern, gewährleistet eine reibungslose nachgelagerte Leistung.
Datenumwandlung
Bei der Datenumwandlung werden die Daten in die gewünschte Form gebracht. Dieser Schritt ist wichtig, da die gesammelten Daten möglicherweise nicht die gleiche Form haben. Die Daten können zum Beispiel in JSON-Form vorliegen und JSON kann verschachtelt sein. Daher besteht das Hauptziel dieses Schritts oder der Datenumwandlung darin, das JSON zu entrollen, um die Schlüsseldaten für die weitere Verarbeitung zu erhalten. Mit anderen Worten: Die Datentransformation ist notwendig, um alle Daten in die gewünschte Form oder besser gesagt in eine Standardform zu bringen. Das Ziel der Datenumwandlung ist es, die Daten zu bereinigen, zu filtern und den Wert für Geschäftsentscheidungen zu erhöhen. Es können verschiedene Algorithmen wie Berechnungsmethoden, statistische Analysen oder maschinelles Lernen eingesetzt werden, um verwertbare Erkenntnisse zu gewinnen.
Daten Ziel
Datenziele sind die Orte, an denen die verarbeiteten Daten in der Pipeline-Architektur gespeichert werden. Diese Ziele können Data Warehouses, Cloud-basierte Datenbanken oder Data Lakes sein. Die Wahl eines geeigneten Speichers ist wichtig, da sie sich auf den einfachen Zugriff auf die Daten auswirkt. Vor der Auswahl des Speicherortes werden verschiedene Faktoren wie Datentyp, Volumen und Zweck berücksichtigt.
Eine gute Datenpipeline-Architektur stellt sicher, dass Analysten problemlos auf Daten von Zielorten zugreifen können. Sie sollte auch so aufgebaut sein, dass sie große Datenmengen schnell und präzise verarbeiten kann. In dieser Phase werden Datenschutzrichtlinien für Datensicherheit und Compliance implementiert.
Datenüberwachung
Die Überwachung von Daten ist notwendig, um die Einhaltung von Richtlinien und Vorschriften zu gewährleisten. Dies ist notwendig, um Sicherheit und Integrität zu gewährleisten. Daher umfasst diese Phase die Festlegung von Rollen für die Datenverwaltung, Audits und die Implementierung von Zugriffskontrollen. Ein Kontrollrahmen ist entscheidend, um den unbefugten Zugriff auf Daten zu verhindern und Gesetze wie die Allgemeinen Datenschutzbestimmungen einzuhalten. Außerdem ist die Überwachung der Datenqualität nützlich, um Anomalien und Fehler in der Pipeline zu erkennen. Die Implementierung von Schritten zur Datenvalidierung und Fehlererkennung stellt daher die Zuverlässigkeit und Genauigkeit der Ausgabe sicher. Darüber hinaus bieten Überwachungstools einen Überblick über die Leistung der Datenpipeline und erkennen Probleme, die umgehend behoben werden können.
Automatisierung und Orchestrierung
Datenorchestrierung kann definiert werden als die Koordination der Bewegung von Daten entlang der Pipeline. Dies ist notwendig, um sicherzustellen, dass Prozesse auf die richtige Weise ausgeführt werden. Diese Tools lösen Workflows aus und verwalten Wiederherstellungsaktionen, wodurch manuelle Eingriffe minimiert werden. Eine gute Orchestrierungsstrategie berücksichtigt dynamische Skalierung, Lastausgleich und Parallelverarbeitung. Sie spielen daher eine Schlüsselrolle bei der Leistung von Datenpipelines, um einen reibungslosen Datenfluss mit minimalen Unterbrechungen zu gewährleisten.
Anwendungsfälle für die Datenübernahme
Nachfolgend finden Sie verschiedene Verwendungszwecke für die Dateneingabe
Betrugsaufdeckung im Finanzwesen
Einige Finanzunternehmen nutzen eine Architektur zur Datenintegration, um Betrug aufzudecken und zu verhindern. Die Integration eines robusten Verschlüsselungs- und Mapping-Systems im Finanzwesen ist entscheidend für die Aufdeckung von Betrug. Dies führt zu mehr Vertrauen und weniger finanziellen Verlusten.
Maschinelles Lernen
Maschinelles Lernen ist ein Zweig der KI, der Daten verwendet, um große Sprachmodelle (LLMs) zu trainieren, die in verschiedenen Branchen eingesetzt werden. Maschinelles Lernen ist auch deshalb so wichtig, weil es Daten verwendet, um nachzuahmen, wie Menschen denken, kommunizieren und Probleme lösen. Darüber hinaus kann es auch genutzt werden, um anhand von Daten aus der Vergangenheit und aktuellen Trends Vorhersagen zu treffen.
Analyse und Überwachung
Ein Datenwissenschaftler wird wahrscheinlich auch mit einer großen Menge an Daten arbeiten, um diese zu analysieren und Schlussfolgerungen zu ziehen. Datenaufnahme-Pipelines helfen in diesem Fall, da sie Daten in einem Format bereitstellen, das sich leicht kategorisieren lässt. Dies ermöglicht es einem Datenanalysten, Datenvisualisierungstools zu verwenden, um Daten zu analysieren und effizient Schlussfolgerungen zu ziehen.
Herausforderungen im Zusammenhang mit der Datenpipeline-Architektur
Trotz der Einfachheit einer Datenpipeline-Architektur ist sie nicht ohne Herausforderungen. Zum Beispiel gibt es Herausforderungen wie diese:
Inkonsistente Datenqualität
Eines der am häufigsten auftretenden Probleme bei den Dateneingabe-Pipelines ist die inkonsistente Qualität der Daten. Dies kann zu falschen Entscheidungen und folglich zur Instabilität der Abläufe führen. Daher muss die Architektur der Datenpipeline mit bestimmten Komponenten ausgestattet sein, die die Qualität der Daten effektiv messen und überwachen können. Datenqualität ist definiert als hochwertige Daten, wenn die Daten:
- Akkurat
- Konsistent
- Relevant
- Rechtzeitig
- Vollständig
- Einzigartig.
Außerdem hilft die Automatisierung des Datenbereinigungsprozesses, Fehler zu vermeiden, die während des Prozesses auftreten können. Diese Komponenten müssen also in die Dateneingabe-Pipeline aufgenommen werden, um die Relevanz des Ergebnisses zu erhöhen.
Bedenken bezüglich Datensicherheit und Datenschutz
Viele Länder haben es geschafft, Datenschutzgesetze einzuführen, um die Sicherheit der Daten im Zeitalter des automatisierten Web Scraping zu gewährleisten. Diese Gesetze schreiben auch die Verwendung der online gewonnenen Daten vor. Die Einhaltung dieser Gesetze trägt also dazu bei, Vertrauen bei den Beteiligten, Partnern und Kunden aufzubauen. Es ist wichtig, die Daten vor unbefugtem Zugriff zu schützen und sie im Einklang mit den Gesetzen zu verwenden. Daher muss die Architektur der Dateneingabe-Pipeline eine starke Verschlüsselung enthalten, um den Datenschutz zu gewährleisten.
Skalierbarkeit
Ein weiteres Problem bei der Dateneingabe ist die Skalierbarkeit, d.h. die Fähigkeit, große Datenmengen zu verarbeiten. Wenn die Nachfrage nach Daten steigt, müssen die Pipeline-Frameworks ihre Leistung entsprechend verbessern. Es gibt jedoch die Möglichkeit, Cloud-basierte Lösungen zu verwenden, um die Skalierbarkeit zu verbessern.
Engpässe bei der Leistung
Aufgrund der Komplexität der Daten kann ein wiederkehrendes Leistungsproblem auftreten. Dieses Problem kann in jeder Phase des Pipeline-Frameworks auftauchen.
Leistungsengpässe entstehen oft, wenn eine Stufe des Frameworks die Daten langsamer verarbeitet als die vorherige Stufe und dadurch ein Rückstau entsteht. Die richtige Planung und die Verwendung der richtigen Tools können helfen, dieses Problem in der Dateneingabe-Pipeline zu lindern.
Beziehung zwischen Daten-Pipeline und ETL
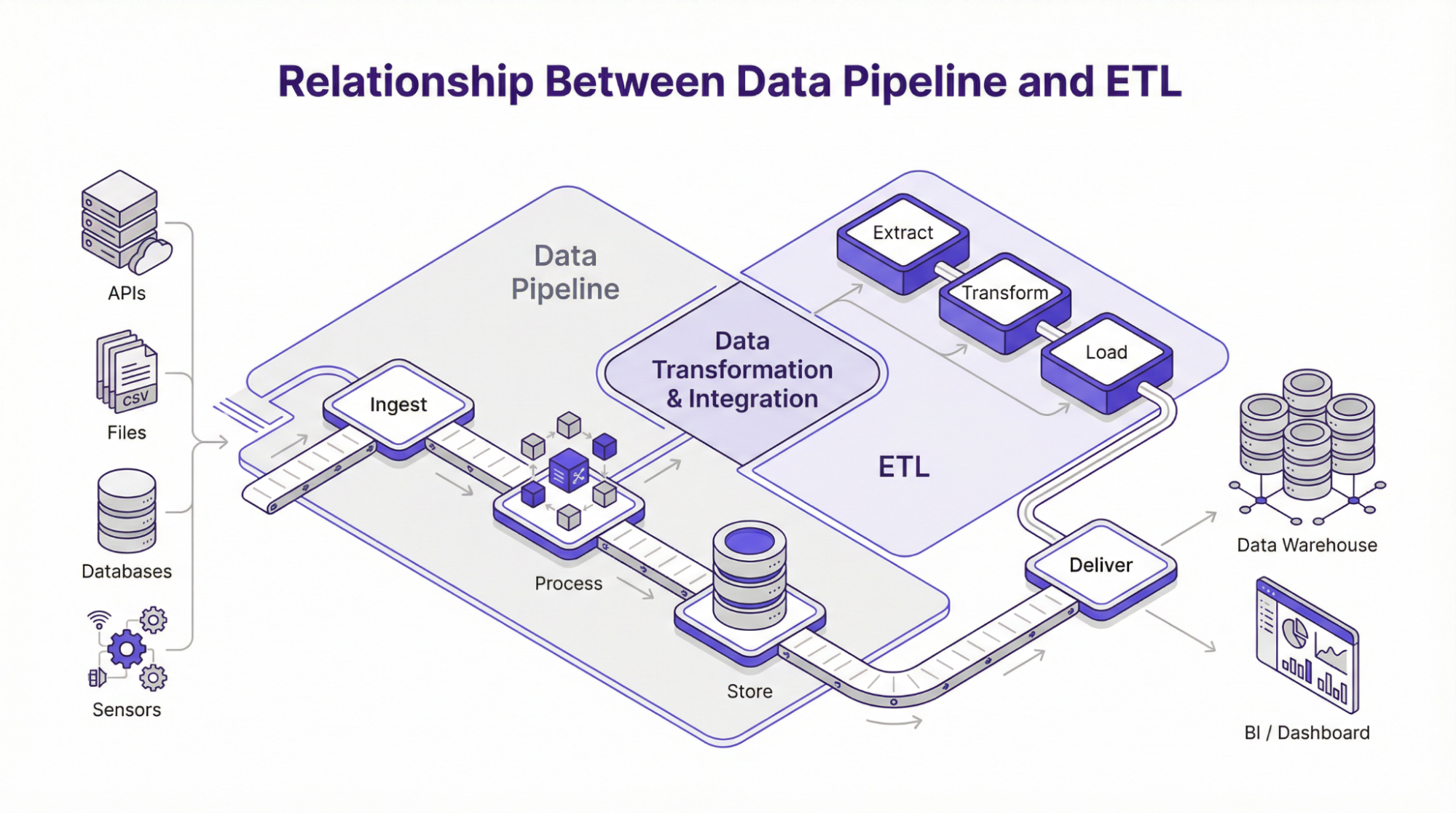
ETL, was für Extrahieren, Transformieren und Laden steht, ist eine der gängigsten Methoden zum Aufbau von Datenpipelines. Wie der Name schon sagt, wird damit ein bestimmter Weg für die Daten definiert, während sie das System durchlaufen.
In einer standardmäßigen oder traditionellen ETL-Pipeline werden Daten aus verschiedenen Quellen extrahiert. Anschließend werden sie in eine Verarbeitungsebene umgewandelt, von der aus sie in eine Zielspeichereinheit wie ein Data Warehouse geladen werden. Dieser Prozess wird häufig in Stapelverarbeitungs-Frameworks verwendet, in denen Daten in geplanten Zeiträumen gesammelt und verarbeitet werden. Darüber hinaus wird dieses Framework implementiert, wenn Daten vor der Speicherung validiert, formatiert oder in ein strukturiertes Format umgewandelt werden müssen. Die moderne Datenpipeline-Architektur unterstützt jedoch auch andere Frameworks wie z.B.:
ELT – Extrahieren, Laden, Transformieren
Beim ELT-Modell werden die Daten unmittelbar nach der Extraktion aus verschiedenen Quellen in den Zielspeicher geladen. Die Transformationen werden dann zu einem späteren Zeitpunkt mit Tools wie SQL oder DB durchgeführt. Das ELT-Framework wird jedoch in der Regel in Situationen bevorzugt, in denen Rechner und Speicher getrennte Einheiten sind, wie z.B. bei Cloud-basierten Pipelines.
ETL umkehren
In diesem Rahmen bewegen sich die Daten in die entgegengesetzte Richtung als im ETL. Mit anderen Worten, die Daten werden vom Warehouse zu externen Tools wie Kundensupportsystemen, Modellen für maschinelles Lernen oder CRM übertragen. Anschließend können Unternehmen die Analyse in den Betrieb integrieren, indem sie Warehouse-Daten mit Tools verknüpfen, die von Support-, Vertriebs- oder Marketing-Teams verwendet werden. Obwohl ETL, ELT und Reverse ETL Daten in unterschiedliche Richtungen bewegen, bleibt das Ziel dasselbe – Daten dort zu extrahieren, wo sie erzeugt werden, und sie dorthin zu schicken, wo sie benötigt werden. Das Verständnis dieser Datenflussmechanismen gibt den Teams daher Aufschluss über den besten Ansatz zum Aufbau einer Dateneingabe-Pipeline, die relevant und skalierbar ist und mit den betrieblichen Zielen übereinstimmt.
Letzte Überlegungen
Unternehmen benötigen eine große Menge an Daten, um ihre Stabilität zu erhalten. Gleichzeitig sind sie damit beschäftigt, Daten schneller zu erfassen, als sie sie verarbeiten können. Data Ingestion ist ein architektonisches System, das dabei helfen kann, all diese Daten in eine nützliche Form zu bringen. Daher ist es effizient, eine Data Ingestion Pipeline zu erstellen, um Ressourcen aus verschiedenen Quellen zu nutzen.
Einige der Probleme, die bei der Datenübernahme auftreten, sind Datenqualität, Leistung, Sicherheitsbedenken und die Handhabung großer Datenmengen. Trotz all dieser Probleme ist es möglich, den Prozess der Datenübernahme reibungslos zu gestalten, indem Sie bewährte Verfahren wie die Sicherstellung der Datenqualität, die Skalierbarkeit des Datenübernahme-Frameworks und die Überwachung der Leistung der Datenpipeline anwenden.





