

Daten sind das neue Gold. Jedes moderne Unternehmen lebt von ihnen. Ob es sich um Erkenntnisse über Kunden, Zielmärkte und Konkurrenten handelt oder um riesige Datensätze für das Training von KI-Modellen – Daten sind der Treibstoff für die digitale Wirtschaft. Es gibt hauptsächlich zwei Möglichkeiten, eine große Menge relevanter Daten zu sammeln: Entweder Sie sammeln sie von Ihren Nutzern oder Sie schöpfen sie aus dem Internet.
Data Scraping bedeutet, öffentlich verfügbare Daten auf Websites zu sammeln und sie zu verfeinern, um nützliche Informationen zu finden. Diese Informationen können dann zum Trainieren von KI-Modellen, zur Erforschung von Verbraucherverhalten, Markttrends und vielem mehr verwendet werden. In diesem Blog werden die besten Webdienste für Web Scraping im Jahr 2026 vorgestellt, die Ihnen ein sicheres und einfaches Data Scraping ermöglichen. Jeder Service enthält meine persönlichen Erfahrungen, Kundenrezensionen von vertrauenswürdigen Plattformen und eine zusammenfassende Liste der Vor- und Nachteile sowie der Preise.
Warum werden automatisierte Web Scraping Dienste benötigt?
Stellen Sie sich vor, Sie möchten prüfen, wie viel Ihre Konkurrenten für ein Produkt verlangen. Sie möchten bei Ebay und Amazon nach Produktpreisen, Titeln und Beschreibungen usw. suchen und analysieren, wie Sie Ihr Produkt positionieren wollen. Ein Web Scraping Service hilft Ihnen dabei, dies zu automatisieren, indem er Ihre Zieldomäne automatisch durchsucht und Daten in dem von Ihnen gewünschten Format sammelt.
Web Scraping ist nicht so einfach wie das obige Beispiel. Plattformen wie Amazon, Ebay und Meta setzen starke Anti-Scraping-Systeme ein, um Web-Scraper zu blockieren. Der Grund dafür ist einfach: Sie wollen nicht, dass automatisierte Bots Kundendaten auslesen und ihre Server unnötig belasten. Hier kommen die Web Scraping Services ins Spiel. Sie helfen Ihnen, Daten schneller zu scrapen, ohne sich um die Verwaltung von Proxys und Verboten kümmern zu müssen.
Web-Scraping-Dienste umgehen die Erkennungssysteme von Websites, um Webseiten in großen Mengen zu scrapen. Websites erkennen Bots anhand verschiedener Signale wie Surfverhalten, Mausbewegungen, Scrollmuster, CAPTCHA-Auslöser und Häufigkeit der Anfragen. Wenn das Erkennungssystem eines dieser Signale feststellt, können Sie gesperrt werden. Web-Scraping-Dienste wurden entwickelt, um die Erkennungssysteme zu umgehen, indem sie echtes menschliches Verhalten imitieren.
Wie beurteilen Sie, welchen Web Scraping Service Sie verwenden sollten?
Ich spreche aus persönlicher Erfahrung: Nehmen Sie niemals einen Scraping-Dienst, der auf dem Papier mehr Funktionen bietet. Lesen Sie immer zuerst die Kundenrezensionen und probieren Sie den Dienst aus, wenn er kostenlos ist, um zu sehen, ob er auf Dauer funktioniert. Wenn Ihr Unternehmen von der Datenauslese lebt, brauchen Sie einen Dienst, der:
- Sollte in der Produktion nicht kaputt gehen
- Ihre Konten sind nicht dem Risiko ausgesetzt, gesperrt zu werden
- Hat ein Kundenerlebnis
- Konzentriert sich auf den Datenschutz
- Aktualisiert regelmäßig seine Tools, um den sich entwickelnden Anforderungen des Internets gerecht zu werden
Im Idealfall möchten Sie ein Tool, das Daten auslesen kann, ohne dass Sie es beaufsichtigen müssen. Hier sind also die grundlegenden Kriterien, nach denen wir die besten Scraping-Anbieter bewertet haben:
- Unblocker Tools: Wie es CAPTCHAs, WAFs, 403/409 und JS-lastige Seiten behandelt
- Automatisierung: Grad der Automatisierung, wie Batching, Wiederholungen, Rendering und API-Unterstützung
- Klarheit der Preisgestaltung: Die Preisgestaltung sollte klar genug sein, um langfristige Budget- und Ergebnisziele festzulegen
- Einsteigerfreundlichkeit: Wie gut die Dokumentation ist und wie einfach die Benutzeroberfläche ist, um schnell loszulegen.
- Marktbewertungen: Was Kunden auf TrustPilot, G2 und Capterra über den Service denken.
Top 10 Web Scraping Unternehmen für Data Scraping Automatisierungen
1. Floppydata: Bester API-basierter Web-Scraping-Dienst

Wenn Sie sich für eine unkomplizierte Option entscheiden möchten, wählen Sie Floppydata. Es bietet Ihnen zwei Dinge: Einen riesigen Pool von sauberen IPs mit Targeting auf Stadtebene in 195 Ländern und eine hervorragende Scraping-API, die CAPTCHAs löst, JS-lastige Seiten scannt und sehr geringe Kosten verursacht.
Ich mochte Floppydata wegen seiner Einfachheit. Sie können jede beliebige Website-URL testen, indem Sie sie in das Testfeld einfügen, und Sie erhalten sofort die gescrapten Daten zurück. Dieser extrahierte Inhalt hilft Ihnen bei der Analyse dessen, was Sie aus diesem rohen HTML extrahieren möchten. Floppydata generiert auch Beispielcode in cURL, Python, JavaScript und R, den Sie in Ihrem Scraping-Automatisierungsworkflow verwenden können.
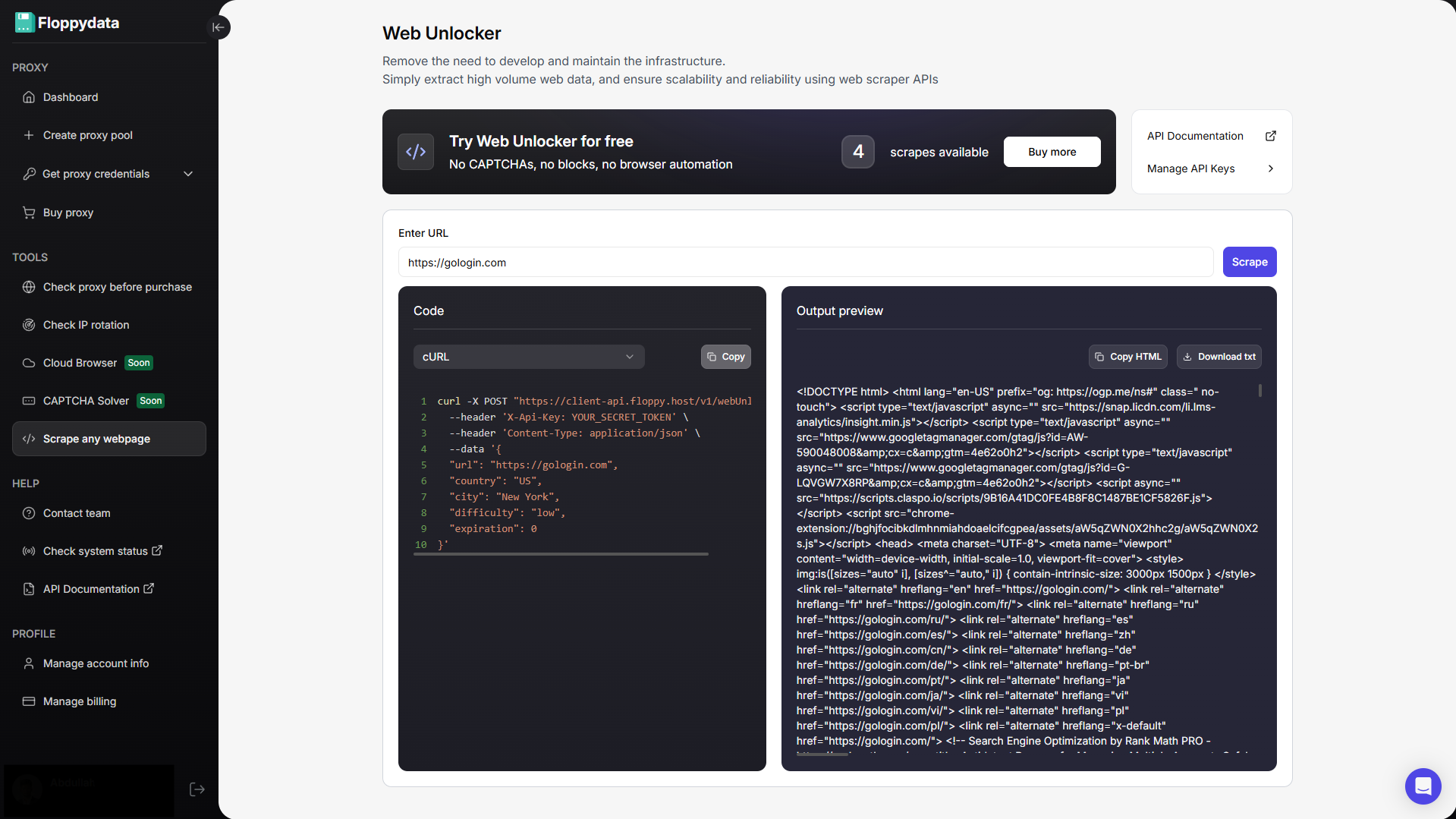
Wenn Sie getestet haben, dass die Domain funktioniert, können Sie jetzt einen API-Schlüssel einrichten und loslegen. Sie können ihn nach Belieben zu Ihrem Scraping-Workflow hinzufügen. Das war’s!
Preisgestaltung:
Floppydata bietet ein hervorragendes Preis-Leistungs-Verhältnis, da ich keine Proxys separat kaufen und einrichten muss. Sie wählen automatisch Proxys aus ihrem eigenen Pool für meine Webautomatisierungsaufgaben aus. Ich bezahle nur für erfolgreiche Extraktionen (nicht für fehlgeschlagene oder wenn eine Webseite von 10 verschiedenen Proxys erneut versucht wurde).
- Testversion: 5 Anfragen kostenlos
- Basispaket: $9 / 10K erfolgreiche Scraps
- Erweitertes Paket: $89 / 100K erfolgreiche Scans
- Maßgeschneiderter Plan: maßgeschneiderte Lösung auf der Grundlage der Kundenbedürfnisse
| Pros | Cons |
| Starke Einstiegspreise, UI-freundlich | Bietet keine Weboberfläche zum Einrichten oder Ausführen von Automatisierungen wie einige andere Wettbewerber |
| Web Unblocker für den Umgang mit 403/429-Blöcken, CAPTCHAs, usw. | |
| Scraping funktioniert in der Cloud, nicht auf Ihrem Gerät | Für die Nutzung der API benötigen Sie Programmierkenntnisse |
2. Gologin: Bester Antidetect Browser für Web Scraping Automation
Obwohl Gologin kein dedizierter Proxy-Anbieter ist, habe ich Gologin aufgrund seiner Antidetektiv-Funktionen, mit denen Sie sichere Web-Automatisierungen durchführen können, als zweitbeste Wahl eingestuft.
Sie können Automatisierungen über die Cloud Browsing API von Gologin ausführen. Gologin hilft Ihnen, durch seine Antidetektionsfunktionalität eine zusätzliche Sicherheitsebene zu unserer Automatisierung hinzuzufügen. Anstatt Ihre Netzwerk-IP und Ihren Geräte-Fingerabdruck zu riskieren, stellt Gologin Ihnen für jedes Browserprofil einen eindeutigen Geräte-Fingerabdruck und eine IP-Adresse zur Verfügung. Dadurch sieht jedes Gologin-Browserprofil wie ein eigenes Gerät aus. Dies trägt dazu bei, Ihr Gerät und Ihre Netzwerkadresse vor Sperren zu schützen, während Sie durch Automatisierung parallel in Tausenden von Gologin-Profilen auf einmal arbeiten.
Warum ich Gologin geliebt habe:
Gologin bietet nicht nur API-Unterstützung, um das Scraping über Hunderte von gleichzeitigen Browserprofilen zu automatisieren, sondern verfügt auch über einen MCP-Server. Wenn Sie nicht wissen, was ein MCP ist, sollten Sie sich das folgendermaßen merken: Sie nehmen den MCP-Schlüssel Ihres Gologins und verbinden ihn mit KI-Tools wie Claude, und nun kann dieses KI-Tool direkt auf Gologin zugreifen. Sie können nun Claude bitten, einige Aufgaben in Gologin auszuführen. Für mich war dies eine großartige Funktion, um grundlegende Webfunktionen auszuführen, wie z.B. das Durchsuchen einiger Websites, um Preise zu überprüfen, und Claude zu beauftragen, mir eine Produktbeschreibung aus den analysierten Webseiten zu schreiben.

Preisgestaltung:
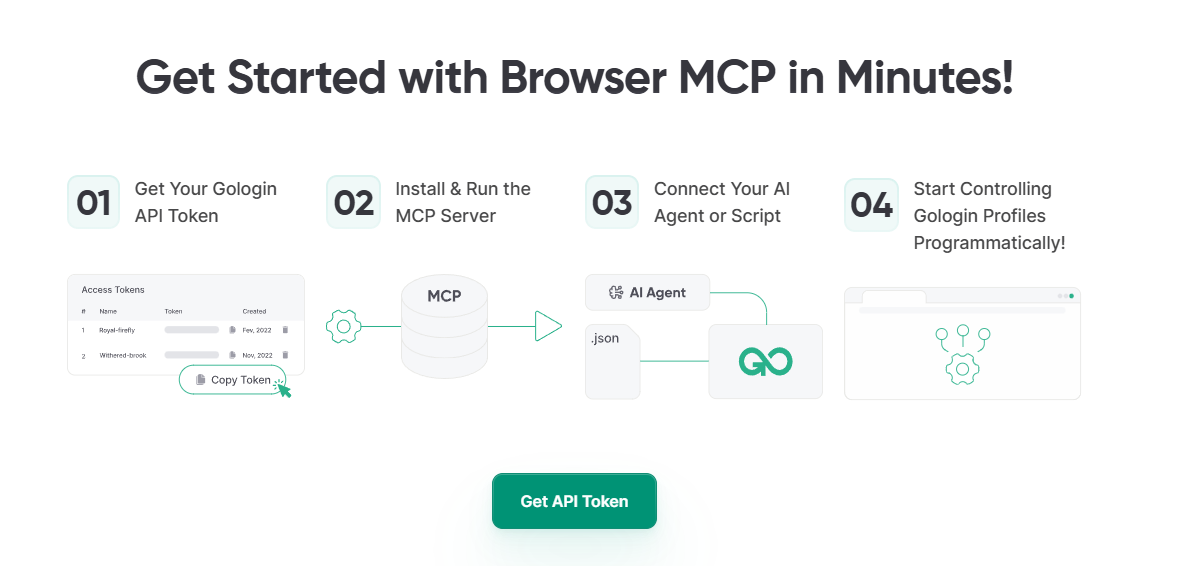
- Professional: $4/mo, 100 Profile, 10 Profilfreigaben, 1 Cloud-Start, REST API (300 RPM)
- Standortdaten, 2GB residenter Proxy
- Business: $59/mo, 300 Profile, 100 Profilfreigaben, 2 Cloud-Starts, REST API (500 RPM)
- Enterprise: $149/mo, 1000 Profile, 1000 Profilfreigaben, 3 Cloud-Starts, REST API (800 RPM)
Individuelle Pläne sind verfügbar. Die genannten Preise sind Jahrespreise.
| Pros | Cons |
| Ausgezeichneter Anti-Detect-Browser für Scraping-Workflows | Erfordert die Kopplung mit integrierten Proxys |
| Starke Isolierung der Fingerabdrücke pro Profil | Programmiererfahrung für die Verwendung der API erforderlich |
| Erschwinglich im Vergleich zu Anti-Detect-Tools für Unternehmen |
3. Zyte: Scraping-Infrastruktur für Unternehmen
Zyte (ehemals Scrapinghub) ist seit über 16 Jahren einer der ältesten Namen in der Web-Scraping-Branche. Wenn Sie auf der Suche nach einem Tool für Unternehmen sind, ist Zyte eine großartige Option mit einem Preismodell, das Sie nach Bedarf bezahlen.
Was mir an Zyte gefallen hat, ist die unkomplizierte Preisgestaltung für drei Arten von Web Scraping Tools. Es gibt eine Zyte API für Web Scraping, die Zyte Copilot VScode-Erweiterung für Entwickler zum Schreiben von Scraping-Automatisierungen und Zyte Cloud zum Ausführen von Automatisierungen in der Cloud und zum Speichern von Daten in AWS-Speicher-Buckets.
Die meisten APIs arbeiten in der Cloud, speichern die Daten aber auf Ihrem Gerät in dem von Ihnen gewünschten Format. Sie müssen jedoch das Format definieren, in dem die Daten extrahiert und in einem CSV- oder Excel-Format gespeichert werden sollen. Zyte bietet über seine Erweiterungen Zyte Cloud und Copilot vordefinierte Formate für die Datenextraktion.
Eine weitere hervorragende Funktion, die Zyte bietet, ist die automatische Proxy-Verwaltung. Sie entscheiden, welche Art von Proxy (Rechenzentrum, private Daten, mobile Daten) für jede Website geeignet ist und verwenden diese Proxys zum Scrapen von Daten. Die Abrechnung erfolgt auf der Grundlage des von Zyte gewählten Proxys.
Preisgestaltung:
Zyte hat unterschiedliche Preise, je nachdem, welches Tool Sie für das Scraping verwenden möchten.
- Zyte API: HTTP-Antwort: $0,13-$1,27 / 1K Antworten / Browser Rendered: $1,01-$16,08 / 1K Antworten. Die Kosten sinken auf $0,06-$0,10 mit monatlicher Verpflichtung
- Scrapy Cloud: Kostenlos für immer mit 1 Cloud-Einheit. 1 Stunde Crawl-Zeit und 7 Tage Aufbewahrung, $9 pro Einheit/Monat mit unbegrenzten gleichzeitigen Crawls, unbegrenzte Crawl-Laufzeit, 120 Tage Datenspeicherung
- Zyte Data: $500/Monat für standardisierte Schemata, vordefinierte Crawl-Frequenz, JSON/CSV/XML-Lieferung ODER $1.000/Monat für benutzerdefinierte Schemata, flexiblen Crawl-Zeitplan, benutzerdefinierte Lieferformate, erweiterte Nachbearbeitung
| Pro | Nachteile |
| Langjähriger Ruf der Branche | Höhere Kosten für fortgeschrittene Pläne |
| Starker Fokus auf Compliance | Weniger anfängerfreundlich |
| KI-unterstützte intelligente Proxy-Verwaltung | Kann technisches Onboarding erfordern |
4. Apify: Vorgefertigte Web Scraping-Vorlagen
Apify ist nicht nur eine Scraping-API, sondern auch ein Marktplatz, auf dem Sie vorgefertigte ‚Akteure‘ (Scraper) und Workflows erstellen oder verwenden können. Anstatt eine komplette Shopify-Automatisierung einzurichten, können Sie einen vorgefertigten Shopify-Actor verwenden, der Ihnen beim Scrapen der benötigten Daten hilft. Diese Akteure werden von der Community entwickelt und können zusätzlich Geld kosten.
Apify lebt von seinem Akteurs-Ökosystem. Wenn Sie Apify nutzen möchten, müssen Sie entweder einen eigenen Akteur erstellen oder einen vorgefertigten verwenden, was Sie Geld kostet. Einige der sehr beliebten Akteure können pro 1k Ergebnisse sehr teuer sein, verglichen mit der Verwendung einer API und dem Schreiben eigener Automatisierungsskripte.
Apify bietet Proxy-Rotation, MCP-Server, beliebte Plattform-Integrationen zur Erstellung Ihres Akteurs und Anti-Blocking-Mechanismen für einen sicheren und automatisierten Scraping-Workflow. Wenn Sie keinen Code schreiben wollen, ist Apify ein guter Ausgangspunkt.
Preisgestaltung:
Apify hat ein verwirrendes Preismodell. Sie erhalten einen Basisplan, der Ihnen Rechenleistung zur Verfügung stellt. Sie können zusätzlichen Cloud-Ram für Ihren Akteur kaufen, wenn Sie umfangreichere Websites scannen. IPs kosten zusätzliches Geld und wenn Sie einen Akteur vom Marktplatz verwenden, fallen die Kosten pro 1k Ergebnisse unterschiedlich aus. Abgesehen davon sehen die eigenen Pläne von Apify wie folgt aus:
- Starter: $29/Monat, $0,3 pro Recheneinheit, $5 Ladenguthaben
- Skala: $199/Monat, $0,3 pro Recheneinheit, Chat-Support, $29 Ladenguthaben
- Business: $999/Monat, $0,25 pro Recheneinheit, vorrangiger Chat-Support, $999 Shop-Guthaben
Hinweis: Store-Guthaben können Sie für die Erstellung Ihrer eigenen Schauspieler verwenden. Jeder Kontotyp bietet größere Rabatte beim Kauf, wenn Sie von der Community vorgefertigte Darsteller verwenden möchten.
| Pro | Nachteile |
| Großer Markt für fertige Scraping-Akteure | Die Preisgestaltung hängt von der Computernutzung ab und kann unvorhersehbar skalieren |
| Integrierte Arbeitsabläufe zur Planung, Speicherung und Automatisierung | Lernkurve für Anfänger |
| Vollständige Scraping-Infrastruktur in einer Plattform | Kann bei großem Umfang teuer werden |
| Unterstützt Headless Browser Automation | Overkill, wenn Sie nur eine einfache Scraping-API benötigen |
5. Octoparse: API-Scraping für Einsteiger
Octoparse ist für Benutzer gedacht, die keine Automatisierungsskripte schreiben möchten. Wie Apify verfügt Octoparse über zahlreiche vorgefertigte Vorlagen, die Sie verwenden können, um mit dem Scrapen von Daten zu beginnen. Sie reichen von Youtube-Beschreibungsscrapern bis zu Shopify-Produktpreisextraktoren. Es gibt eine Vorlage für fast jeden Anwendungsfall.
Was mir an Octoparse gefallen hat, ist sein visueller Workflow-Builder. Sie klicken auf Elemente auf einer Webseite, legen fest, was extrahiert werden soll, und Octoparse erstellt die Scraping-Logik für Sie. Ich kann anpassen, was ich scrapen möchte, und Tools wie Slack, Google Drive usw. zum Speichern von Daten verbinden. Ich kann Web-Scraping-Automatisierungen sowohl lokal als auch in der Cloud ausführen.
Proxy-Preis
- Kostenloser Plan: 10 Aufgaben, nur lokale Geräteläufe, 50K Zeilen/Monat Exportlimit, keine Cloud-Automatisierung
- Standard Plan: Ab $83/mo, 100 Aufgaben, 3 gleichzeitige Cloud-Prozesse, IP-Rotation, CAPTCHA-Auflösung, unbegrenzte Exporte
- Professional Plan: $299/mo, 250 Aufgaben, 20 gleichzeitige Cloud-Prozesse, Erweiterte API, Cloud-Überwachung, Prioritäts-Support
- Enterprise Plan: Individuelle Preisgestaltung, 750+ Aufgaben, 40+ gleichzeitige Cloud-Prozesse, Hochleistungsserver, engagierter Support
6. ScrapingAnt: Erschwinglichste Scraping-API
ScrapingAnt positioniert sich selbst als die preisgünstigste Scraping-API, die 100k API-Credits für $19 anbietet. Als ich jedoch anfing, es zu benutzen, stellte ich fest, dass ich Proxys separat verwalten musste, was bedeutete, dass ich Proxy-Bandbreite kaufen und sie dann mit Ihrer API verbinden musste. Bei anderen Optionen wie Floppydata und Gologin sind Proxys im Preis für die API enthalten.
ScrapingAnt ist ein API-basiertes Scraping-Tool mit positiven Bewertungen auf Capterra. Sie führen ein einfaches Automatisierungsskript mit API-Schlüssel und Ziel-URLs aus und es liefert das gerenderte HTML zurück. Im Vergleich zu BrightData oder Zyte bietet dieses Tool jedoch nichts Besonderes, außer seinem Preis.
Proxy-Preis
- Kostenloser Plan: Kostenlos, 10.000 API-Credits pro Monat, geeignet für das Testen kleiner Projekte
- Enthusiast Plan: $19 pro Monat, 100.000 API-Credits, gut für Freiberufler und kleine Scraping-Aufgaben
- Startup Plan: $49 pro Monat, 500.000 API-Credits, entwickelt für kleine Teams und wachsende Automatisierungsanforderungen
- Business Plan: $249 pro Monat, 3.000.000 API-Credits, entwickelt für größere Scraping-Workflows
- Business Pro Plan: $599 pro Monat, 8.000.000 API-Credits, höheres Volumen mit vorrangigem Support
- Benutzerdefinierter Plan: Benutzerdefinierte Preise ab ca. $ 699 pro Monat, 10M plus API-Guthaben für Unternehmen
| Pros | Cons |
| Einfache REST-API, die leicht zu integrieren ist | Begrenzte fortschrittliche Unternehmenstools |
| Integriertes JS-Rendering, Proxy-Rotation und CAPTCHA-Verarbeitung | Kleineres Ökosystem im Vergleich zu Apify oder Zyte |
| Gute Dokumentation und entwicklerorientierter Aufbau | Weniger Flexibilität im Vergleich zu vollständigen Browser-Automatisierungstools |
7. BrightData:Scraping-Plattform auf Unternehmensebene

BrightData ist einer der bekanntesten und ältesten Proxy-Anbieter auf dem Markt. Sie bieten zwei Möglichkeiten zum Scrapen von Daten: Einen Scraping-Browser und eine Scraping-API. Ein Scraping-Browser funktioniert wie Gologin und bietet Ihnen eine Cloud-Infrastruktur für Ihre Selenium- und Puppeteer-Skripte. Die Web Scraping API ist jedoch leistungsfähiger.
Was ich liebe:
Was ich an der Web Scraping API von BrightData so liebe, ist, dass sie sowohl den API-Schlüssel als auch eine codefreie Version desselben Scrapers anbietet. Wenn Sie sich also nicht mit der Verwaltung von API-Schlüsseln und Scraping-Skripten auskennen, können Sie den auf dem Control Panel basierenden „Plug-and-Play“-Scraper verwenden, der die Ergebnisse sammelt und sie direkt in Ihrem Dashboard zum Download bereitstellt.
Proxy-Preis
- Abrechnungsmodell: $1.5/1k Ergebnisse
- 510k Datensätze: $499/mo bei $0.98/1k Datensätze
- 1M Datensätze: $999/mo bei $0.83/1k Ergebnisse
- 2.5M Datensätze: $1999/mo bei $0.75/1k Datensätze
| Pros | Cons |
| Branchenführende Proxy-Infrastruktur | Teuer im Vergleich zu den meisten Wettbewerbern |
| Sehr hohe Erfolgsquote bei schwierigen Zielen | Komplexe Einrichtung für Anfänger |
| All-in-one Scraping-Ökosystem | Preise können bei hohem Volumen schnell skaliert werden |
8. ScrapingBee: Einfache API für Entwickler

Die API von ScrapingBee ist leistungsstark, effektiv und unkompliziert. Wie Floppydata bietet auch ScrapingBee rotierende Proxys für Hunderte von Headless-Browser-Sitzungen. Die API rendert JavaScript-, HTML- und CSS-Formate und kann sie in einfache JSON- oder Markdown-Dateien umwandeln.
Beim Web Scraping gibt es zwei große Herausforderungen. Die erste besteht darin, die HTML-Struktur der Ziel-URL zu analysieren, um zu erkennen, was Sie aus den Rohdaten extrahieren müssen, und die zweite darin, wie Sie diese massenhaft gescrapten Daten in ein verwertbares und verständliches Format umwandeln können.
Was mir an ScrapingBee wirklich gefällt, ist, dass Sie die API mit Ihrer n8n- oder Zapier-Automatisierung verbinden können, was eine weitere Dimension von Möglichkeiten mit Scraping und den gescrapten Daten eröffnet.
Preisgestaltung:
Die Preisgestaltung von ScrapingBee ist nicht transparent. Es wird nicht pro gescraptem Ergebnis berechnet. Sie werden danach berechnet, wie viele Credits für JS-Rendering und Proxys verbraucht wurden. Sie können also nicht abschätzen, wie lange Ihr Guthaben reichen wird.
- Freiberuflich: $49/mo, 250.000 API-Credits
- Startup: $99/mo, 1.000.000 API-Guthaben
- Business: $249/mo, 3.000.000 API-Gutschriften
- Business+: $599/mo, 8.000.000 API-Guthaben
| Pros | Cons |
| Sehr einfach zu verwendende API | Begrenzte Skalierbarkeit für Unternehmen |
| Gute Dokumentation und Einarbeitung | Das Kreditsystem kann verwirrend sein |
| Integrierte Proxy-Rotation und JS-Rendering | Weniger Kontrolle über die erweiterte Scraping-Logik |
9. ScraperAPI: Einsteigerfreundliches Scraping-API

ScraperAPI ist eine weitere API in dieser langen Liste. Wie viele andere Optionen bietet auch ScraperAPI Scraping-Vorlagen, die sie „strukturierte Endpunkte“ für bekannte Websites nennen. Wenn Sie Reddit scrapen möchten, können Sie deren vorstrukturierten Endpunkt verwenden, anstatt das ganze Skript selbst zu schreiben.
Wie Floppydata verfügt auch ScraperAPI über eine CAPTCHA-Auflösung und eine automatische Proxy-Rotation. Sie brauchen keine zusätzlichen Proxys einzurichten. Sie können Tausende von asynchronen Anfragen senden, die über das Headless Cloud Browsing verarbeitet werden.
Preisgestaltung:
Im Gegensatz zu Floppydata, das Ihnen nur erfolgreiche Extraktionen in Rechnung stellt, berechnet Ihnen ScraperAPI jede einzelne API-Anfrage.
- Hobby: $49/mo, 100.000 API-Aufrufe, 20 gleichzeitige Threads
- Startup: $149/mo, 1.000.000 API-Aufrufe, 50 gleichzeitige Threads
- Business: $299/mo, 3.000.000 API-Aufrufe, 100 gleichzeitige Threads
- Skalierung: $475/Monat, 5.000.000 API-Aufrufe, 200 gleichzeitige Threads
| Pros | Cons |
| Sehr anfängerfreundlich | Begrenzte Anpassungsmöglichkeiten im Vergleich zu fortgeschrittenen Tools |
| Keine Proxy-Einrichtung erforderlich | Die Kosten steigen bei JS-lastigem Scraping |
| Einfache Integration mit einfacher API | Weniger effizient für komplexe Arbeitsabläufe |
10. Oxylabs: Premium-Infrastruktur für Unternehmensteams

Oxylabs ist ein weiterer Anbieter von Scraping-APIs für Unternehmen wie BrightData. Als Premium-Proxy-Anbieter mit einem Pool von zehn Millionen Proxys aus über 195 Ländern verwaltet die Web Scraper API von Oxylabs die Cookie-Verwaltung, Proxy-Rotation, CAPTCHAs, Anti-Bot-Systeme und passt den Parser sogar an die Struktur der HTML-Seite an, wenn sich diese ändert.
Oxylabs bietet auch eine riesige Bibliothek mit strukturierten Endpunkten für alle bekannten Websites. Die Bibliothek mit strukturierten Endpunkten ist größer und günstiger als die von ScraperAPI. Oxylabs ist eine gute Wahl für freiberufliche Teams und Unternehmenssoftware, die Scraping-Funktionen nutzen, da es eine ausführliche Dokumentation zur Einrichtung und einen ausgezeichneten Kundensupport bietet.
Preisgestaltung:
- Kostenlose Testversion: 2000 Ergebnisse
- Micro: $49/mo bei $.50/1k Ergebnisse
- Starter: $99/mo bei $0,45/1k Ergebnisse
- Fortgeschrittene: $249/mo bei $0,40/1k Ergebnisse
Abschließende Schlussfolgerungen
Wenn Sie komplexe Automatisierungsworkflows erstellen möchten, sollten Sie sich für einen API-gestützten Dienst wie Floppydata, Gologin oder Zyte entscheiden. Apify ist großartig, wenn die Kosten für Sie keine Rolle spielen, aber beim Scraping von Daten türmen sich die Kosten schneller auf, als Sie reagieren können, da Tausende von Links innerhalb einer Stunde gescraped werden können. Wenn Sie mit rotierenden Proxys arbeiten, steigen die Kosten sogar noch weiter an.
Ich empfehle Floppydata oder Gologin, da Sie die Kosten leicht vorhersagen können, sie die Proxy-Verwaltung und die automatische Rotation für Sie übernehmen und Sie keine zusätzlichen Proxys einrichten müssen.





