


Веб-скрепінг Reddit – це процес збору загальнодоступних даних на платформі. Зібрані дані можуть включати дописи, профілі, коментарі тощо. Ручний збір даних Reddit може зайняти багато часу, призвести до помилок і бути неефективним. Тому дослідники, маркетологи та SEO-фахівці часто автоматизують збір даних Reddit за допомогою ботів або скриптів. Керування кількома акаунтами Reddit для скрапінгу може вимагати використання проксі-сервера. Для полегшення вилучення даних Reddit має публічний API. Однак ваші можливості дуже обмежені, коли ви скрапуєте Reddit за допомогою API з кількох причин. По-перше, API реалізує ліміти швидкості, що обмежує кількість запитів, які ви можете відправити протягом певного періоду часу. Крім того, він часто вимагає дані для автентифікації, що може сповільнити весь процес.
Як працює скрепер Reddit?
Щоб вилучити дані Reddit, скрейпер надсилає HTTP-запити до платформи. На наступному етапі відбувається синтаксичний аналіз відповідей у форматі HTML або JSON. Потім витягуються необхідні елементи, такі як ідентифікатор користувача або коментарі. Нарешті, витягнуті дані очищаються і зберігаються в заздалегідь визначеному форматі. Загальнодоступні дані, які ви можете отримати на Reddit, включають
- Назви постів
- Імена користувачів
- Коментарі (теми та відповіді)
- Оцінки (голоси “за” і “проти”)
- Метадані підредактиву
- Мітки часу та історія редагувань
Деякі з проблем, пов’язаних з використанням скрейпера Reddit, включають CAPTCHA, заблоковані IP-адреси, вкладені розділи коментарів і обмеження швидкості. Саме тут оптимізовані інструменти відіграють вирішальну роль у виведенні вашої скрап-активності на новий рівень.
Де взяти Reddit скрейпер чи парсер
Скрепери можна умовно розділити на 2 (дві) групи – скрепери з кодом і без коду. Скрепери з кодом використовують мову програмування, таку як Python, CSS, Java тощо, для створення скрипта, який автоматизує вилучення даних. Цей варіант вимагає певних навичок кодування та технічних знань для написання коду, який може обійти CAPTCHA та обмеження швидкості для ефективного вилучення даних. Ви також можете написати скрипт для скрепера зображень Reddit, якщо метою є лише вилучення зображень на сторінці.
З іншого боку, варіант без коду – це рішення, яке не вимагає кодування або широкого розуміння мов програмування. Для тих, хто шукає простий варіант, як витягти дані з Reddit, стануть у нагоді інструменти без коду. Вони мають різні функції, які дозволяють витягувати дані з таких платформ, як Reddit, за кілька кроків. Одне з найнадійніших місць, де можна отримати таке рішення для вилучення даних без коду, – Floppydata. Цей інструмент оптимізує процес отримання даних з Reddit завдяки функціям, які обходять CAPTCHA та IP-заборони для безперешкодної роботи. Інструмент Web Unblocker від Floppydata чудово підходить для масштабування великих обсягів даних без необхідності використання автоматизованих браузерів, таких як Selenium, Puppeteer або Playwright.
Floppydata Web Unblocker – це інструмент, який спрощує веб-скрепінг, автоматично обходячи блоки і CAPTCHA, дозволяючи вам збирати дані без необхідності автоматизації браузера або ручного налаштування проксі. Деякі з його функцій включають:
- Автоматичне розгадування CAPTCHA
- Обходьте механізми захисту від ботів за допомогою розширеного розпізнавання відбитків пальців у браузері
- Ефективно витягує дані з динамічних веб-сайтів
- Вбудована автоматична ротація проксі та логіка повторних спроб для збереження анонімності.
Ще одна річ, яку слід врахувати, купуючи скрепер, – це ціна. Floppydata прагне надавати високоякісні рішення за доступними цінами. Тому Floppydata пропонує свій Web Unblocker за дуже конкурентоспроможними цінами. Хоча існує безкоштовна пробна версія, вона обмежена 5 (п’ятьма) утилітами. Існує чотири цінові рівні, і вони включають:
- План зростання – від $0,98 за 1 тис. результатів
- Професійний план – від $0,75 за 1 тис. результатів
- Бізнес-план – від $0,60 за 1 тис. результатів
- Преміум-план – від $0,45 за 1 тис. результатів
- Індивідуальний план – зверніться до служби підтримки, щоб отримати індивідуальний план
Переваги скрепера No-code від Floppydata
- Нетехнічні користувачі можуть легко ним користуватися
- Поставляється з вбудованими функціями, які обробляють ротацію IP-адрес, CAPTCHA та динамічний вміст
- Доставляє дані у форматах CSV або JSON для легкої обробки
- Економічно ефективні варіанти для приватних осіб та МСП
- Швидка доставка даних
Мінуси
- Обмежена гнучкість у налаштуванні
Інші альтернативи вилученню даних Reddit
Давайте коротко проаналізуємо інші методи, які можна використовувати для вилучення даних з Reddit:
Офіційний API Reddit
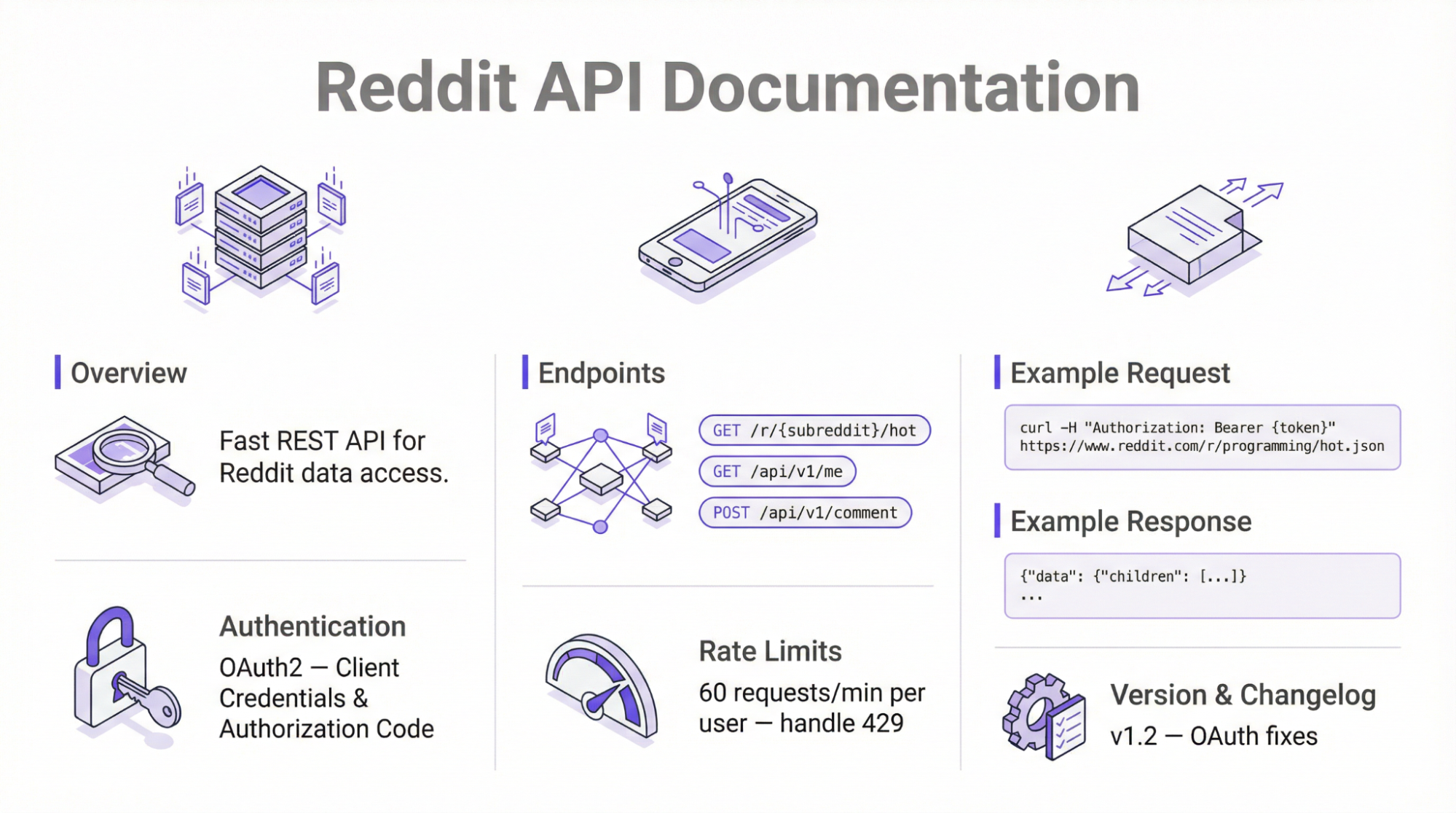
Якщо ви хочете сканувати платформу без сторонніх інструментів, вам варто розглянути можливість використання офіційного API. Цей підхід використовує кінцеві точки JSON API Reddit для вилучення загальнодоступної інформації за допомогою простих HTTP-запитів.
Використання офіційного API вимагає автентифікації OAuth2 та обмежує швидкість – 100 QPM для безкоштовного рівня. Згідно з оновленнями політики, випущеними в 2025 році, API вимагає ручного схвалення від платформи перед отриманням даних.
Щоб використовувати офіційний API Reddit для збору даних, виконайте наведені нижче кроки:
- Зареєструйтеся, щоб отримати доступ до API
Перший крок – увійти до свого облікового запису Reddit або створити його, якщо ви новий користувач. Відвідайте сторінку “Додатки Reddit”, натисніть на “Створити додаток” і дотримуйтесь інструкцій на екрані. Після цього з’явиться нове вікно з вашим ідентифікатором клієнта, секретом клієнта та рядком агента користувача.
- Аутентифікація
Використовуйте OAuth, щоб отримати токен доступу. Для цього кроку ви можете скористатися бібліотекою програмування, наприклад, бібліотекою PRAW у Python, і автентифікуватися за допомогою API. Крім того, ви можете скористатися бібліотекою запитів , яка передбачає ручну обробку токенів доступу.
- Створення HTTP-запитів
Наступним кроком буде використання фреймворку, такого як бібліотека запитів Python, для надсилання GET-запитів до різних кінцевих точок.
- Аналіз і збереження даних
Сирі дані витягуються та обробляються у форматі JSON для зручності читання.
N.B.: Описаний вище процес ефективний лише для простих завдань скрепінгу. Крім того, він вимагає хорошого знання мов програмування та кодування.
Переваги офіційного API Reddit
- Надає офіційний та надійний доступ до серверів Reddit для збору даних
- Це скарга на умови використання платформи
- Мінімальний ризик банів за умови, що ви не перевищуєте ліміт ставки
- Підтримує вилучення загальнодоступних даних без обмежень проти скрепінгу.
Недоліки офіційного API Reddit
- Дані дуже обмежені
- Не підходить для тих, у кого мало або зовсім немає навичок кодування
- Обмеження швидкості ускладнюють масштабування процесу скребкування
- Вилучення великих обсягів даних може бути досить дорогим
Використання Python

Python – це мова програмування з великою бібліотекою, яка підтримує веб-скрепінг. Для скрапінгу Reddit більшість розробників використовують PRAW (Python Reddit API Wrapper) для взаємодії з сервером для вилучення даних.
Однак для вилучення даних за межами API використовуються фреймворки на кшталт BeautifulSoup. Вони також відіграють важливу роль у розборі HTML-даних і передачі їх у форматі XML або JSON.
Структура Reddit часто змінюється, що може вплинути на роботу скрепера. Тому скрепер потрібно регулярно оновлювати, щоб адаптуватися до змін на платформі.
Найкращі практики використання скрепера Reddit на Python
Змінити IP-адресу
Однією з основних цілей ротації IP-адрес є забезпечення анонімності. Крім того, платформа може виявити, коли повторні запити надходять з однієї і тієї ж IP-адреси. Це може спричинити заборону IP-адреси, що ускладнює завершення збору даних
Обробка CAPTCHA
Скрейпер Reddit на Python не призначений для роботи з CAPTCHA, які можуть з’являтися як спосіб для платформи розрізняти дії людини і бота. Щоб обійти CAPTCHA, використовуйте безголові браузери, такі як Selenium, Playwright і Puppeteer, які імітують людську модель перегляду. Згодом це ускладнює виявлення автоматизованих дій.
Використання headless браузерів для роботи з динамічним контентом
Як і сучасні веб-сайти, Reddit використовує JavaScript для завантаження динамічного контенту. Звичайні скрепери зазвичай обробляють лише HTML-вміст і не можуть завантажувати динамічний вміст. Одним із способів вирішити цю проблему є інтеграція безголових браузерів, таких як Selenium
Переваги використання Python
- Оскільки це бібліотека з відкритим вихідним кодом, вона безкоштовна
- Легко налаштовується
- Надійний.
Недоліки використання скребків Python
- Потрібні знання програмування на Python
- Обмежено публічними даними
- Обмежено лімітами API Reddit
Приклади використання даних Reddit
Веб-скрепінг Reddit надає доступ до даних, які можна використовувати для різних цілей. Ось деякі з найпоширеніших випадків використання:
Дослідження ринку
Багато професіоналів збирають дані з Reddit для маркетингових досліджень. Зібрану інформацію можна сортувати та аналізувати, щоб зрозуміти ринкові настрої, поточні тенденції та репутацію різних брендів. Таким чином, дані можуть бути інтерпретовані у рішення, які впливають на рекламу, упаковку та ціноутворення, що відповідають цільовому ринку.
Фінансовий аналіз
Більшість людей не знають, що на Reddit існує ціла спільнота фінансових експертів. На Reddit міститься великий обсяг даних на фінансові теми, пов’язані з акціями, паями, криптовалютою та міжнародними ринками. Фінансовий аналіз необхідний перед тим, як зробити будь-яку значну інвестицію, щоб мінімізувати ризик втрат. Ці дані можна витягти, проаналізувати та інтерпретувати, щоб зрозуміти ринковий прогноз і прийняти обґрунтовані фінансові рішення.
ШІ та машинне навчання
Дані з Reddit можна використовувати для навчання LLM (великих мовних моделей), щоб покращити результати пошуку, керованого ШІ. ШІ-боти можуть працювати лише на основі даних, які вони отримують. Тому щоденна велика кількість відвідувачів Reddit робить його ідеальним джерелом даних. Прикладом є власний ШІ Reddit, LLM, який отримує дані з платформи, щоб надавати персоналізовані сторінки для кожного відвідувача.
Соціальні дослідження
Ще одна сфера використання даних Reddit – соціальні дослідження. Збір даних на субредіті можна використовувати для вивчення моделей людської взаємодії. Соціальні дослідження можна використовувати для збору даних щодо тенденцій та думок на такі теми, як конфіденційність та згода в Інтернеті. Крім того, дані можуть бути використані для навчання чат-ботів надавати цілодобову підтримку, що може бути нездійсненним у випадку з агентами підтримки, які працюють з людьми.
Як скрейпити дані Reddit за допомогою Floppydata Web Unblocker
Використовувати Floppydata Web Unblocker як скрепер для Reddit дуже просто, і це можна зробити за кілька кроків. Ось покрокова інструкція про те, як вилучити дані Reddit за допомогою Floppydata.
Давайте почнемо!
Крок 1: Відвідайте сторінку Web Unblocker і зареєструйтеся, щоб розпочати роботу
Крок 2: Увійдіть до свого облікового запису Reddit. Відкрийте сторінку результатів пошуку з певними фільтрами, які відповідають вашому сценарію використання.
Крок 3: Перейдіть на інформаційну панель Floppydata’s Web Unblocker і вставте URL-адресу
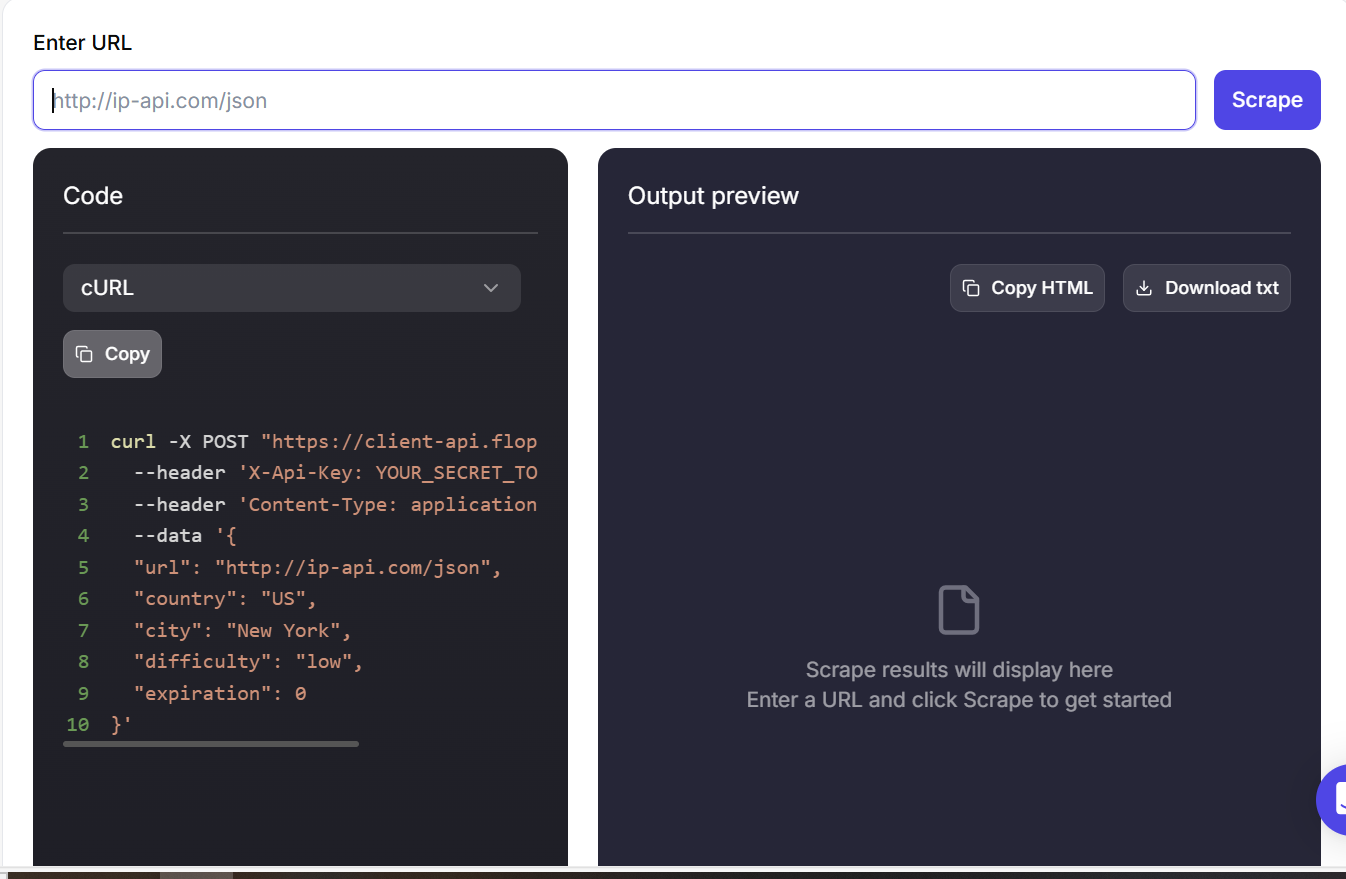
Крок 4: Ваші результати будуть готові за кілька хвилин.
Висновок
Навчитися вилучати дані з Reddit може стати потужним ресурсом для дослідників, приватних осіб та компаній. Це спосіб зібрати інформацію з однієї з найбільших глобальних спільнот в Інтернеті. Щоб зібрати ці дані, ви можете написати скрипт мовою програмування або скористатися рішенням без коду.
Floppydata пропонує комплексне рішення для вилучення даних без коду – Web Unblocker, яке ефективно витягує дані з Reddit і надає їх у зручному для вас форматі. Нові користувачі отримують до 5 безкоштовних сесій для збору даних з будь-якої платформи.
Якщо ви хочете легко і безперешкодно видаляти дані з Reddit, спробуйте Web Unblocker від Floppydata вже сьогодні!





