

Executar automações de raspagem da Web em 2026 não é fácil. Como muitas empresas de IA estão tentando extrair o máximo possível de dados da Internet para o treinamento de modelos, plataformas como Reddit, Meta, X e outras implantam sistemas de detecção com tecnologia de IA para impedir que os raspadores da Web coloquem as mãos em dados públicos de usuários. Portanto, este guia explora como dimensionar e automatizar a raspagem da Web em 2026.
Por que a raspagem da Web está ficando mais difícil?

Aqui estão alguns motivos pelos quais as empresas detectam e bloqueiam ativamente as automações de raspagem da Web.
- Os raspadores da Web colocam uma carga desnecessária nos servidores, pois enviam centenas ou até milhares de solicitações automatizadas simultâneas.
- Os anunciantes não gostam de bots porque os anúncios são exibidos para um bot que extrai dados de uma página e o gasto com anúncios é desperdiçado.
- A maioria das empresas prefere vender seus dados para outras empresas de IA ou treinar seus próprios modelos. É por isso que elas não querem que scrapers extraiam dados de sua plataforma gratuitamente.
No entanto, ainda existem alguns métodos eficazes de raspagem de dados em 2026 que não são apenas seguros de usar, mas são dimensionáveis, fáceis de automatizar e funcionam para todos os sites. Como os sistemas antibot estão se tornando mais inteligentes com a IA, os raspadores da Web também estão se atualizando, fornecendo resolução automática de CAPTCHA, movimentos e cliques aleatórios do mouse, IPs rotativos, impressões digitais aleatórias do navegador e muito mais.
Como dimensionar o Web Scraping?

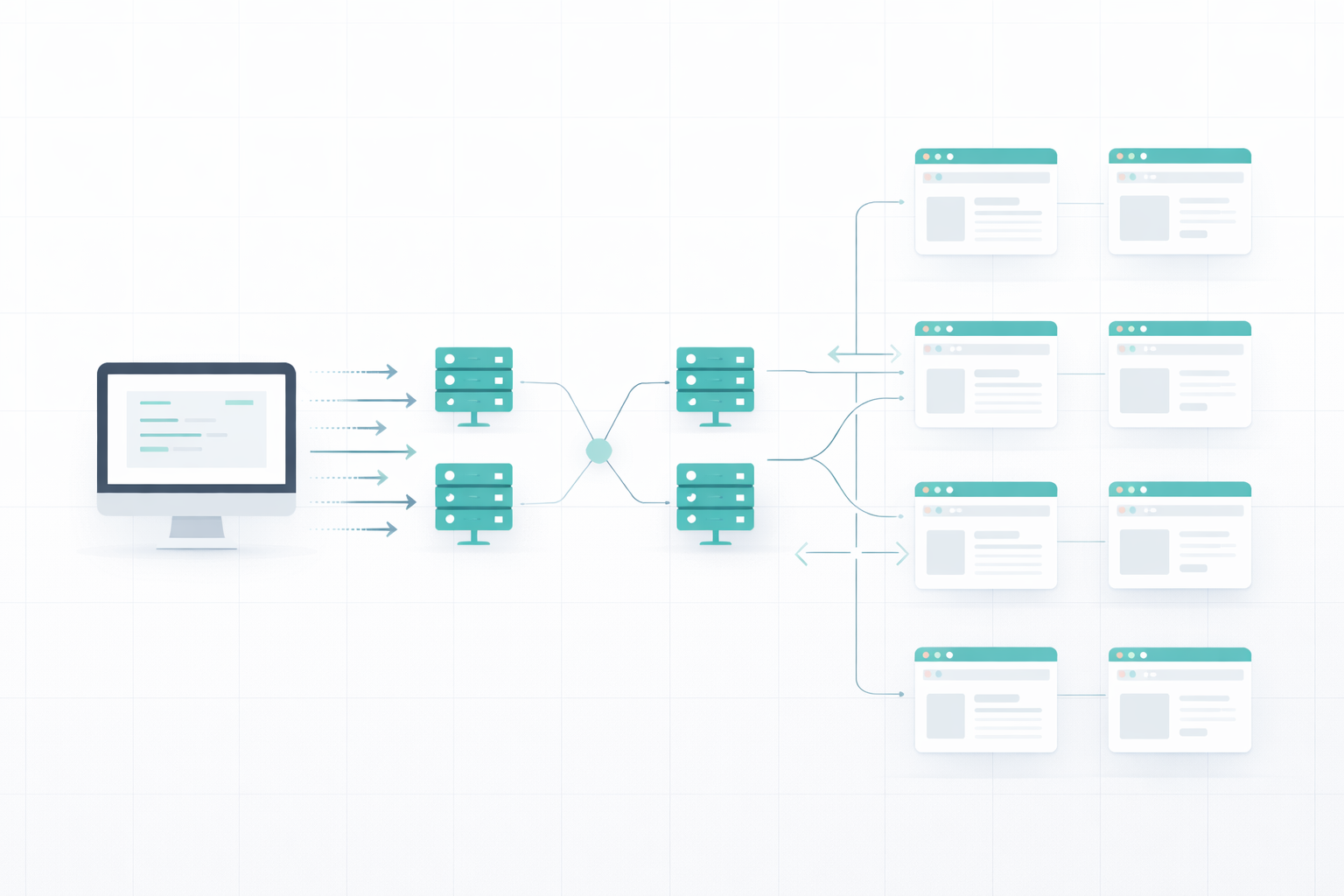
Extrair uma ou duas páginas da Web não é o problema, mas como extrair milhares de páginas da Web em algumas horas ou dias? Não podemos abrir tantas guias em nosso dispositivo devido à limitação da RAM e da velocidade de processamento e, se nosso IP for banido nos primeiros minutos, teremos que mudar para outro dispositivo.
O dimensionamento da raspagem da Web requer compreensão e planejamento. Primeiro, vamos entender os desafios da raspagem da Web.
Desafios na raspagem da Web
Os sites não são mais apenas páginas HTML estáticas. Os sistemas anti-bot rastreiam continuamente a atividade do usuário e a qualidade do tráfego para garantir que somente usuários reais acessem os sites e que os scrapers sejam bloqueados instantaneamente. Aqui estão os desafios que enfrentei quando comecei a fazer scraping na Web:
- Limitação da taxa de IP: As plataformas rastreiam o número de solicitações por IP a cada minuto e hora. Se um endereço IP tentar exceder o limite, a conta será suspensa ou temporariamente desativada por atividade de spam.
- Renderização em Javascript: Muitos sites agora carregam conteúdo dinamicamente. Quando um scraper tenta obter conteúdo HTML, ele obtém campos ausentes porque algumas partes da página não foram carregadas.
- CAPTCHAs: Meus scripts de raspagem da Web tiveram dificuldade em resolver CAPTCHAs e continuaram me bloqueando. O Facebook até baniu meu IP e não consegui acessá-lo novamente com o mesmo IP.
- Detecção de comportamento: Os sites rastreiam seu comportamento, como atividade de rolagem, movimentos do mouse, aleatoriedade de cliques etc., para ver se você é um bot ou uma pessoa real.
- Rastreamento de impressões digitais: As plataformas salvam e rastreiam a impressão digital do seu navegador para identificar quais dispositivos estão usando essa conta. Se você for flagrado violando os termos e serviços, elas podem banir a impressão digital e impedir que seu navegador acesse a plataforma.
- Gerenciamento de cookies: Tentei usar proxies e vários perfis de navegador, mas continuei tendo problemas de contaminação cruzada de cookies. Como todos os perfis salvam cookies das minhas sessões de login, as plataformas conseguiram identificar que eu tinha outras contas conectadas no mesmo dispositivo e que estava fazendo raspagem da Web.
Criação de uma estratégia escalável de raspagem da Web
Existem alguns excelentes serviços de raspagem da Web que ajudam você a criar um sistema de raspagem da Web dimensionável sem se preocupar com todos os problemas descritos acima. Essas ferramentas de raspagem da Web usam um pool de proxies e impressões digitais de navegador aleatórias, executam todas as suas sessões de raspagem na nuvem para evitar sobrecarregar seu computador, resolvem automaticamente CAPTCHAs, isolam cookies e lidam com a renderização de Javascript.
Os serviços de raspagem da Web, como o Floppydata, resolvem o problema da escalabilidade:
- Execução de sessões paralelas do navegador na nuvem
- Usando IPs rotativos de seu pool de 90 milhões de proxies
- Manipulação automática de CAPTCHAs e renderização de JS
- Dimensionamento sob demanda sem a necessidade de configurar infraestrutura adicional
Como automatizar o Web Scraping?
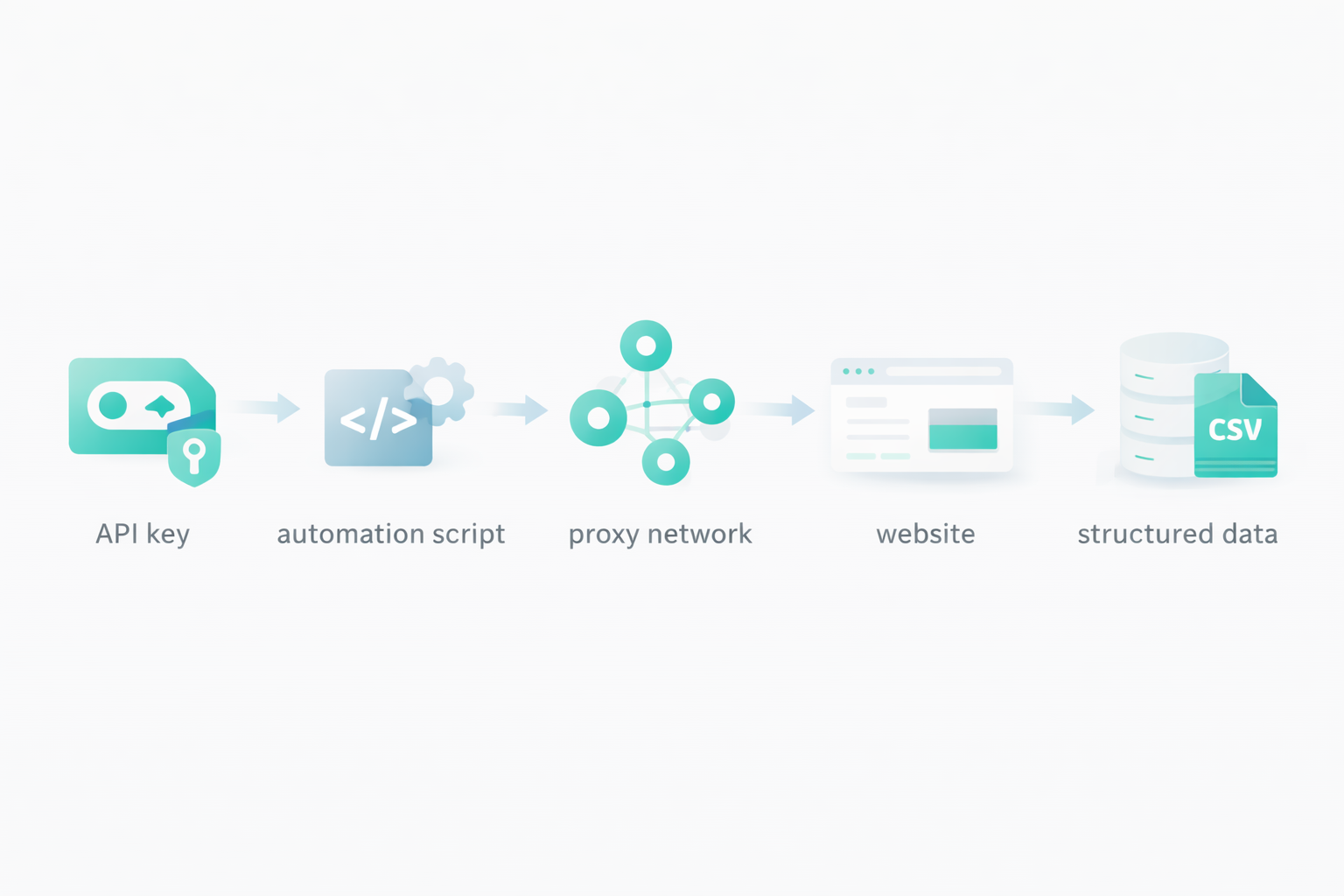
Quando você tem uma infraestrutura dimensionável, precisa criar um sistema automatizado para gerenciar proxies, extrações, links, formatação de dados etc. Mesmo que os serviços de raspagem forneçam uma infraestrutura dimensionável para lidar com milhares de solicitações por hora, você não pode fazer isso manualmente. É aqui que entram os scripts de automação para raspagem.
Alguns serviços de raspagem da Web oferecem modelos configurados por você para plataformas famosas como Reddit, Meta, Instagram, X. etc. Você pode escolher um modelo, configurá-lo de acordo com seu caso de uso e começar a raspagem.
Outro método de automação de raspagem da Web, e um dos mais populares, são as chaves de API. Os serviços de raspagem da Web, como o Floppydata, oferecem chaves de API que ajudam você a enviar solicitações de raspagem da Web para o servidor em nuvem deles e receber o conteúdo extraído em troca. Quando você está usando uma API, as possibilidades são infinitas. Você define seu próprio formato de extração de dados, suas regras de rotação de proxy, quais páginas extrair, quais campos extrair, como armazená-los, quanto atraso adicionar entre cada solicitação, quantas solicitações simultâneas enviar e muito mais.
Você pode usar essa chave de API para criar ferramentas de raspagem ou integrá-las ao sistema existente da sua empresa. Tudo o que você precisa é de uma chave de API, e serviços como o Floppydata cuidarão do resto e trarão a você os resultados finais.
Guia passo a passo para dimensionar e automatizar a raspagem da Web
Aqui você encontra um guia passo a passo sobre como criar uma automação de raspagem da Web com a API Floppydata.
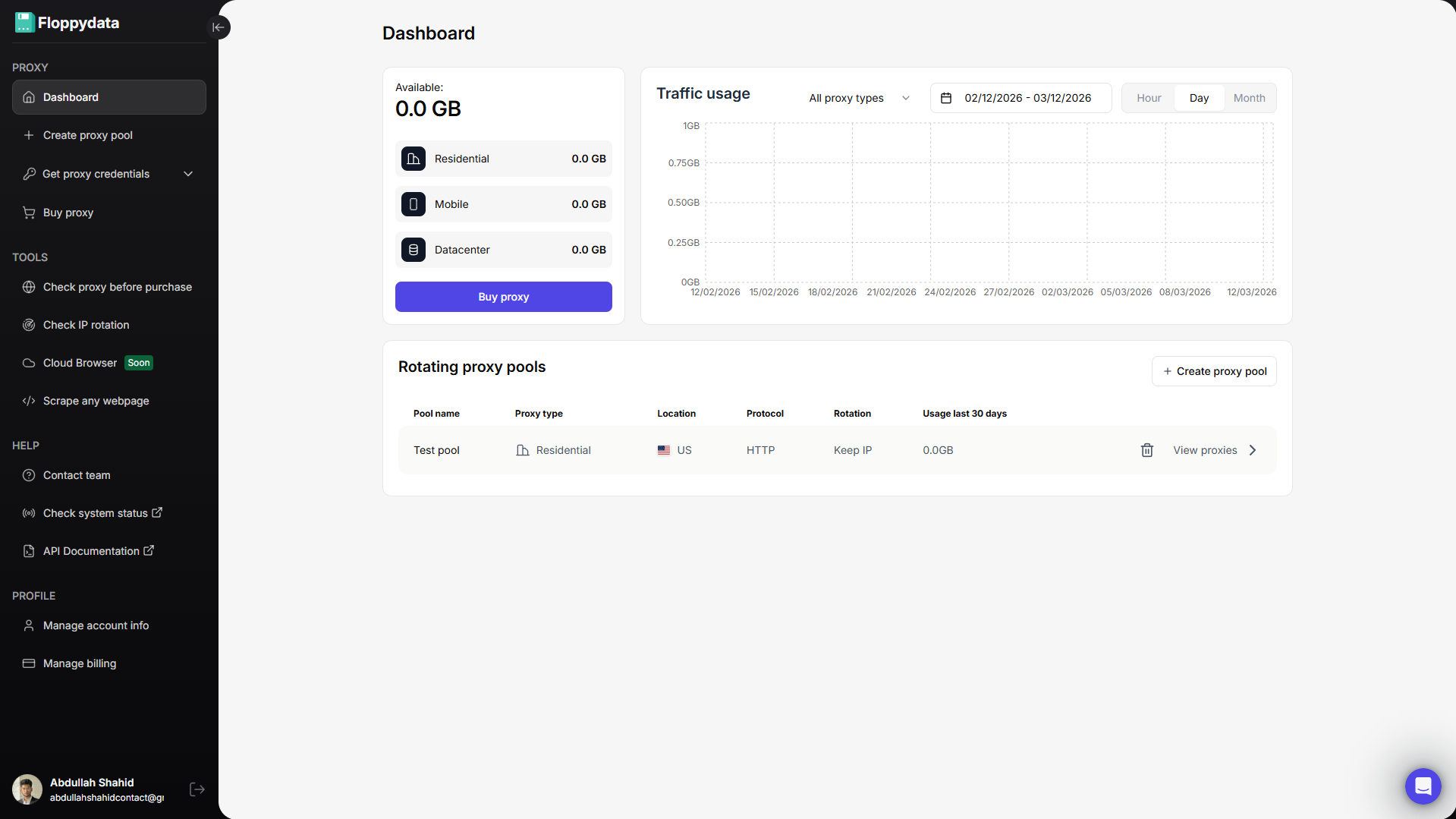
Etapa 1: Criar uma conta Floppydata
Registre-se na Floppydata e abra o painel de controle. É aqui que você pode gerenciar seus proxies e ferramentas como o desbloqueador da Web.
Etapa 2: Analisar o URL de destino

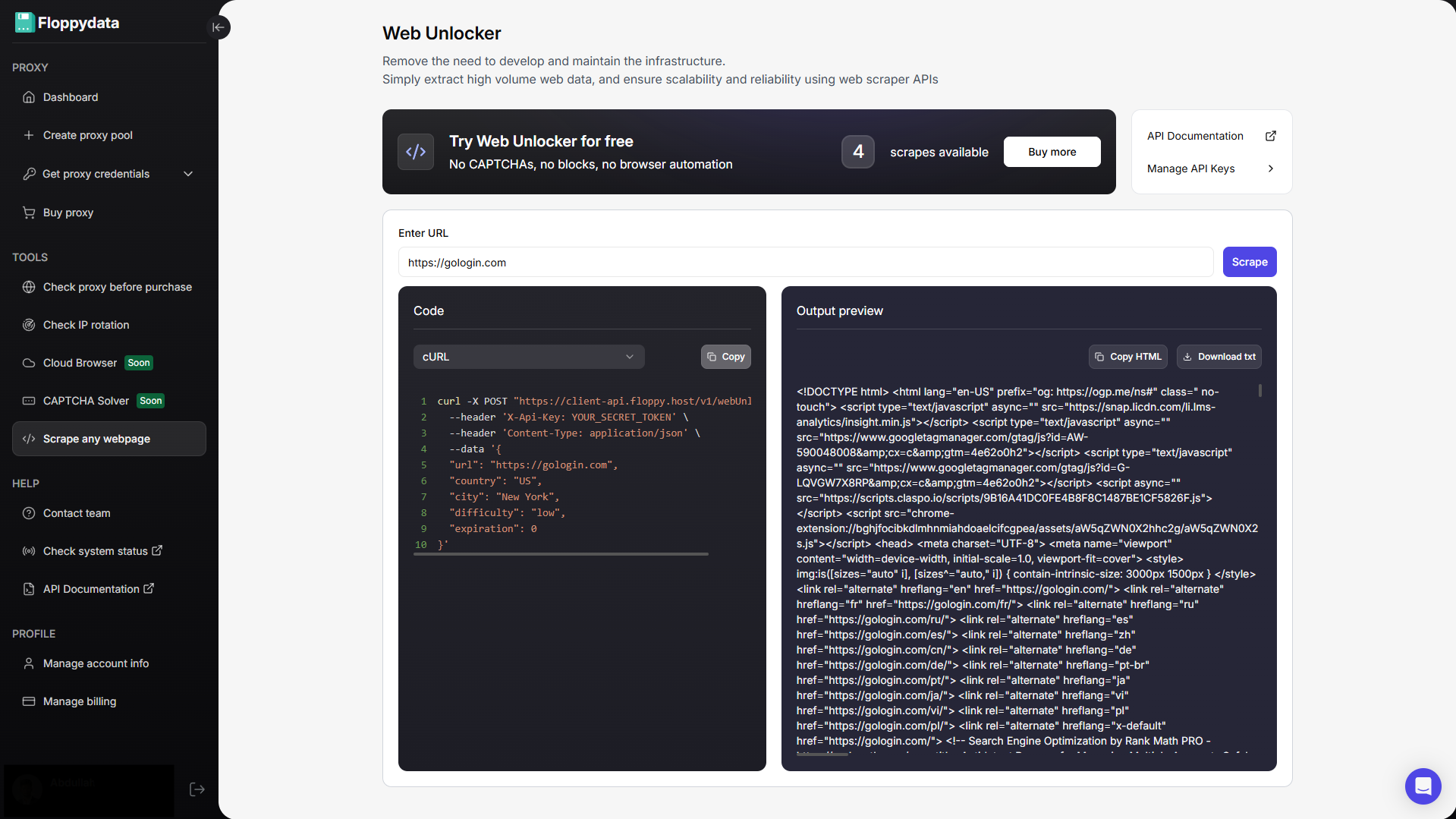
Cole o URL no campo mostrado e clique em scrape. Você obterá o conteúdo HTML dessa página juntamente com um trecho de código para adicionar à automação do navegador. Se você estiver criando uma automação para obter preços de produtos de um site, poderá usar esse recurso de análise para identificar qual tag HTML contém preços. Em seguida, você pode escrever seu script de automação para extrair especificamente as seguintes tags e armazená-las em seu arquivo excel/csv.
Etapa 3: Criar chaves de API para automação
Você pode criar chaves de API nas configurações de sua conta. Essas chaves de API serão usadas em seu script de automação do navegador para girar proxies, desbloquear sites e coletar dados. O Floppydata Web Unlocker coleta dados e os envia ao seu script por meio dessa API.
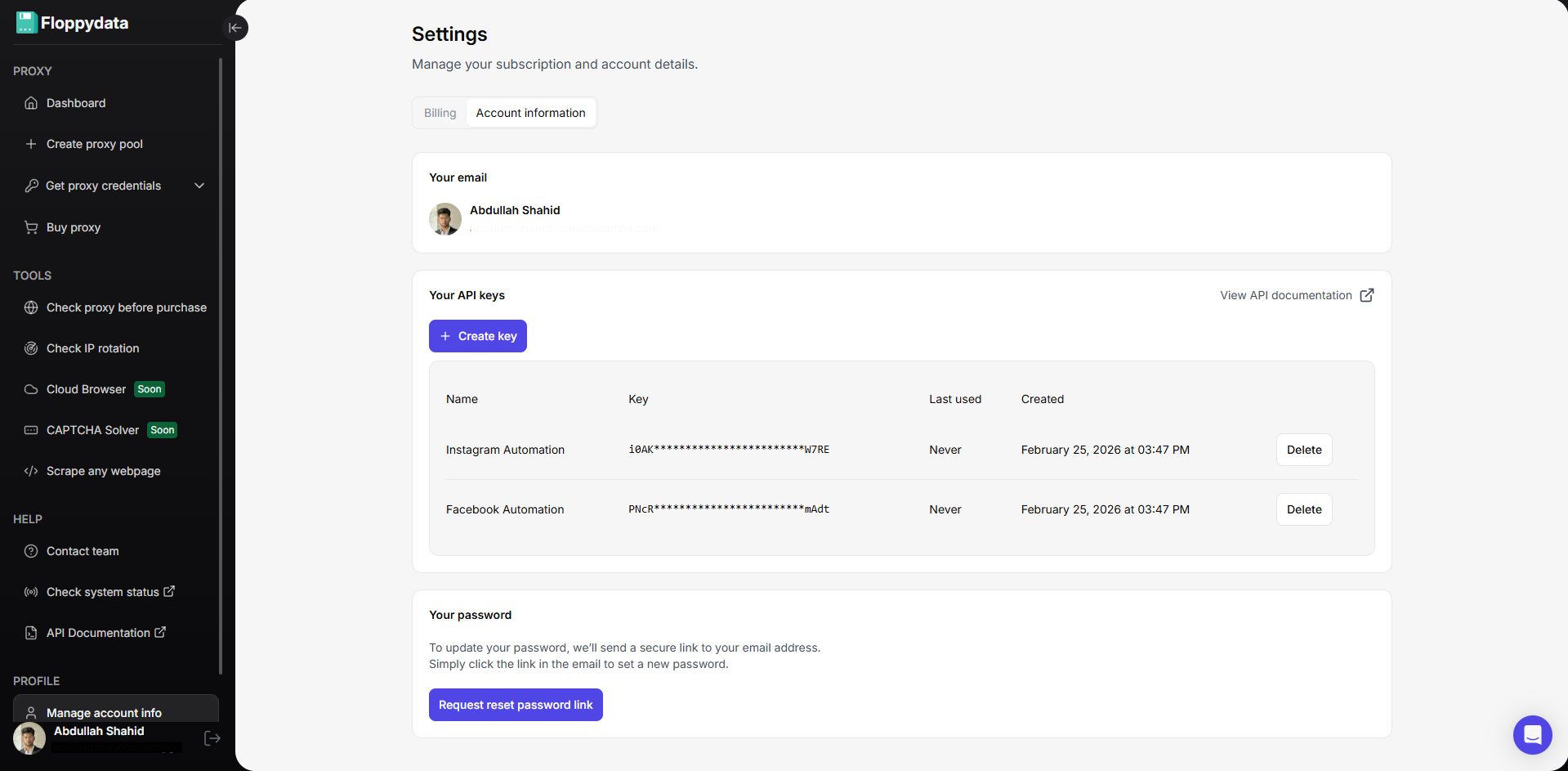
Etapa 4: escrever e executar a automação de raspagem da Web
Agora que você tem a chave de API e os proxies, pode criar um script de raspagem da Web em Python, Javascript, C# ou GO. Coloque sua chave de API no trecho de código mostrado na página do desbloqueador da Web junto com os URLs. Aqui está um exemplo rápido de um script Python que posso executar em um interpretador Python para extrair dados de um fórum de discussão do Reddit:
httpx.post(
“https://client-api.floppy.host/v1/webUnlocker”,
headers={
“Content-Type”: “application/json”,
“X-Api-Key”: “YOUR_SECRET_TOKEN”
},
json={
“url”:
“https://www.reddit.com/r/automation/comments/1ntu327/top_5_antidetect_browsers_comparison_2025/”,
“country”: “US”,
“city”: “New York”,
“difficulty” (dificuldade): “low” (baixa),
“expiration” (expiração): 0
}
)
Você pode alterar o país, a cidade e o URL para alterar o proxy e os links de destino. Este é apenas um trecho de código fictício. Você pode criar automações complexas usando o Claude Code ou o ChatGPT que explorará dinamicamente toda a sua lista de URLs de destino e extrairá conteúdo útil no formato de sua escolha.
Práticas recomendadas e dicas para automação de raspagem da Web
Ao criar fluxos de trabalho automatizados de raspagem da Web, é importante que você priorize a resiliência e o desempenho em relação à velocidade. Seu fluxo de trabalho deve ter uma boa precisão. Se 40% das suas solicitações de raspagem falharem, você perderá 40% do seu orçamento sem resultados para mostrar. Embora a Floppydata cobre de você apenas as extrações de páginas bem-sucedidas, outros serviços cobram por 1.000 solicitações, mesmo que todas elas falhem.
Para criar uma automação que fará parte do seu fluxo de trabalho por semanas ou meses, você precisa garantir alguns aspectos importantes:
- Rotacionar IPs por trabalhador ou sessão
- Dimensione a raspagem com sessões paralelas, não aumentando a velocidade ou reduzindo os tempos de espera
- Use Web Unlockers para sites com muitos blocos
- Prefira APIs quando disponíveis
- Isolar as impressões digitais do navegador
- Registre os erros e tente novamente de forma inteligente
- Faça testes pequenos antes de aumentar a escala
- Compre proxies limpos de um fornecedor confiável
Você não precisa se preocupar com proxies se estiver usando uma ferramenta de desbloqueio da Web de um provedor de proxy como Floppydata, BrightData, Oxylabs etc., pois eles podem incluir IPs limpos para a ferramenta.
Principais conclusões
O dimensionamento e a automação da raspagem da Web ainda são possíveis em 2026 e podem ser muito eficazes se você fizer as coisas corretamente. Se você seguir as estratégias que expliquei neste blog e priorizar a resiliência em relação à velocidade, poderá criar uma automação repetível que durará meses antes de precisar fazer qualquer alteração. Com uma infraestrutura adequada, você não precisa se preocupar com nenhum sistema antibot.





