


Le web scraping de Reddit est le processus de collecte de données accessibles au public sur la plateforme. Les données collectées peuvent inclure des messages, des profils, des commentaires, etc. La collecte manuelle des données Reddit peut être longue, sujette à des erreurs et inefficace. C’est pourquoi les chercheurs, les spécialistes du marketing et les professionnels du référencement automatisent souvent le scraping Reddit à l’aide de bots ou de scripts. La gestion de plusieurs comptes Reddit pour le scraping peut nécessiter l’utilisation d’un proxy. Pour faciliter l’extraction des données, Reddit dispose d’une API publique. Cependant, vos options sont très limitées lorsque vous scrapez Reddit avec l’API, et ce pour plusieurs raisons. Tout d’abord, l’API met en œuvre des limites de débit, qui restreignent le nombre de requêtes que vous pouvez envoyer dans un certain laps de temps. En outre, elle requiert souvent des informations d’authentification, ce qui peut ralentir l’ensemble du processus.
Comment fonctionne un scraper Reddit ?
Pour récupérer les données de Reddit, le scrapeur envoie des requêtes HTTP à la plateforme. La phase suivante consiste à analyser les réponses HTML ou JSON. Ensuite, les éléments requis tels que l’identifiant de l’utilisateur ou les commentaires sont extraits. Enfin, les données extraites sont nettoyées et stockées dans un format prédéfini. Les données accessibles au public que vous pouvez récupérer sur Reddit sont les suivantes :
- Titres des postes
- Noms d’utilisateur
- Commentaires (fils de discussion et réponses)
- Scores (« upvotes » et « downvotes »)
- Métadonnées du subreddit
- Horodatage et historique des modifications
Les CAPTCHA, les IP bloquées, les sections de commentaires imbriquées et les limites de taux sont quelques-uns des défis associés à l’utilisation d’un scraper Reddit. C’est là que les outils optimisés jouent un rôle crucial pour faire passer vos activités de scraping au niveau supérieur.
Où se procurer Reddit Scraper
Les scrapeurs peuvent être classés en deux (2) catégories : les scrapeurs à code et les scrapeurs sans code. Les « code scrapers » utilisent un langage de programmation comme Python, CSS, Java, etc. pour créer un script qui automatise l’extraction des données. Cette option nécessite des compétences en codage et une expertise technique pour écrire un code capable de contourner les CAPTCHA et les limites de taux pour une extraction efficace des données. Vous pouvez également écrire un script pour un scraper d’images Reddit si l’objectif est uniquement d’extraire des images sur la page.
D’autre part, l’option « sans code » est une solution qui ne nécessite pas de codage ou de connaissances approfondies des langages de programmation. Pour ceux qui recherchent une solution facile pour scraper Reddit, les outils sans code sont très utiles. Ils sont dotés de différentes fonctionnalités qui vous permettent d’extraire des données de plateformes telles que Reddit en quelques étapes. L’un des sites les plus fiables pour obtenir cette solution de scraping sans code est Floppydata. Cet outil optimise le processus d’extraction de données de Reddit grâce à des fonctionnalités qui contournent les CAPTCHA et les interdictions d’IP pour une expérience fluide. L’outil Web Unblocker de Floppydata est excellent pour mettre à l’échelle de grands volumes de données sans avoir besoin de navigateurs d’automatisation comme Selenium, Puppeteer ou Playwright.
Le Web Unblocker de Floppydata est un outil qui simplifie le web scraping en contournant automatiquement les blocages et les CAPTCHAs, ce qui vous permet de collecter des données sans avoir recours à l’automatisation du navigateur ou à la configuration manuelle d’un proxy. Voici quelques-unes de ses fonctionnalités :
- Résolution automatisée des CAPTCHA
- Contourner les mécanismes anti-bots grâce à l’empreinte avancée du navigateur.
- Extraction efficace de données à partir de sites web dynamiques
- Rotation automatique du proxy et logique de réessai intégrées pour rester anonyme.
Un autre élément à prendre en compte lors de l’achat d’un scraper est le prix. Floppydata s’engage à fournir des solutions de haute qualité à des prix abordables. C’est pourquoi Floppydata propose son Web Unblocker à un prix très compétitif. Bien qu’il y ait un essai gratuit, il est limité à 5 (cinq) scraps. Il y a quatre niveaux de prix et ils incluent :
- Plan de croissance – À partir de 0,98 $ par 1 000 résultats
- Plan professionnel – À partir de 0,75 $ par 1 000 résultats
- Plan d’affaires – À partir de 0,60 $ par 1 000 résultats
- Plan Premium – À partir de 0,45 $ par 1 000 résultats
- Plan personnalisé – Contactez le service clientèle pour un plan personnalisé.
Avantages du scraper sans code de Floppydata
- Les utilisateurs non techniques peuvent l’utiliser facilement
- Il est doté de fonctions intégrées qui gèrent la rotation des adresses IP, les CAPTCHA et les contenus dynamiques.
- Fournit des données dans des formats tels que CSV ou JSON pour faciliter le traitement.
- Des options rentables pour les particuliers et les PME
- Livraison rapide des données
Cons
- Flexibilité limitée pour la personnalisation
Autres alternatives à la récupération des données de Reddit
Analysons brièvement d’autres méthodes qui peuvent être utilisées pour récupérer des données Reddit :
API officielle de Reddit
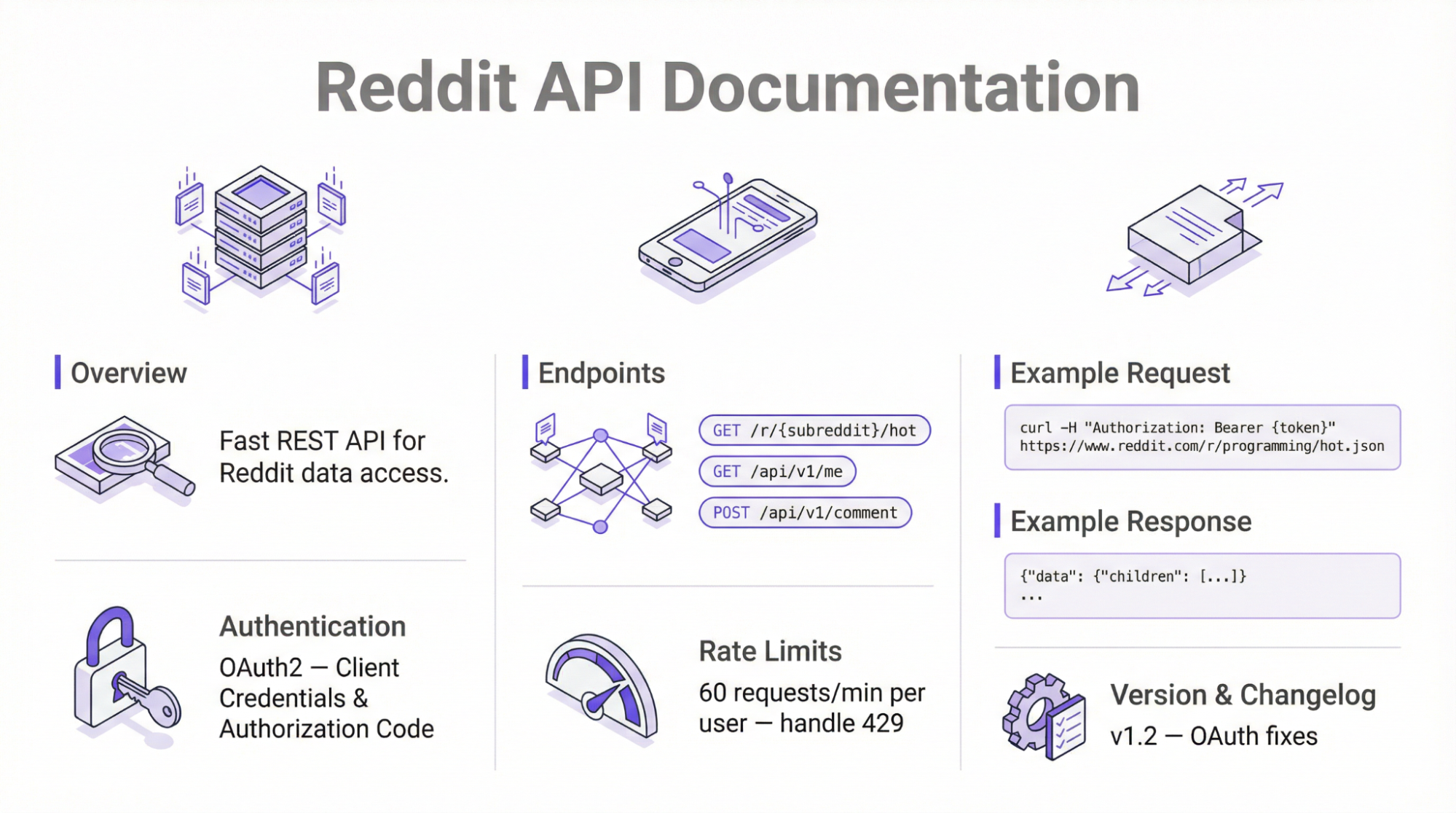
Si vous souhaitez explorer la plateforme sans outils tiers, vous devez envisager d’utiliser l’API officielle. Cette approche utilise les points d’extrémité de l’API JSON de Reddit pour récupérer des informations accessibles au public à l’aide de simples requêtes HTTP.
L’utilisation de l’API officielle nécessite une authentification OAuth2 et applique les limites de taux – 100 QPM pour le niveau gratuit. Selon les mises à jour de la politique déployées en 2025, l’API nécessite une approbation manuelle de la plateforme avant la récupération des données.
Suivez les étapes ci-dessous pour utiliser l’API officielle de Reddit pour la collecte de données :
- Enregistrez-vous pour obtenir l’accès à l’API
La première étape consiste à vous connecter à votre compte Reddit ou à en créer un si vous êtes un nouvel utilisateur. Rendez-vous sur la page Reddit Apps, cliquez sur « create an app » et suivez les instructions qui s’affichent à l’écran. Une fois que vous avez réussi, une nouvelle fenêtre s’ouvre avec votre identifiant client, votre secret client et votre chaîne d’agent utilisateur.
- Authentification
Utilisez OAuth pour obtenir un jeton d’accès. Pour cette étape, vous pouvez utiliser une bibliothèque de programmation, telle que la bibliothèque PRAW de Python, et vous authentifier auprès de l’API. Vous pouvez également utiliser la bibliothèque de requêtes , ce qui implique une gestion manuelle des jetons d’accès.
- Effectuer des requêtes HTTP
L’étape suivante consiste à utiliser un cadre tel que la bibliothèque de requêtes Python pour envoyer des requêtes GET à différents points d’extrémité.
- Analyse et sauvegarde des données
Les données brutes sont extraites et traitées au format JSON pour une meilleure lisibilité.
N.B. : Le processus décrit ci-dessus n’est efficace que pour les tâches de scraping simples. En outre, il nécessite une bonne connaissance des langages de programmation et du codage.
Avantages de l’API officielle de Reddit
- Il fournit un accès officiel et fiable aux serveurs de Reddit pour collecter des données.
- Il s’agit d’une plainte concernant les conditions d’utilisation de la plateforme.
- Risque minime d’interdiction si vous ne dépassez pas la limite de taux
- Prise en charge de l’extraction de données accessibles au public sans restrictions anti-scraping.
Inconvénients de l’API officielle de Reddit
- Les données sont très limitées
- Ne convient pas aux personnes ayant peu ou pas de compétences en matière de codage.
- Les limites tarifaires rendent difficile la mise à l’échelle du processus de raclage.
- L’extraction de gros volumes de données peut s’avérer assez coûteuse
Utilisation de Python

Python est un langage de programmation doté d’une vaste bibliothèque qui prend en charge le web scraping. Pour le scraping de Reddit, la plupart des développeurs utilisent PRAW (Python Reddit API Wrapper) pour interagir avec le serveur afin d’extraire des données.
Cependant, pour extraire des données au-delà des limites de l’API, des frameworks tels que BeautifulSoup sont utilisés. Ils jouent également un rôle crucial dans l’analyse des données HTML et leur livraison au format XML ou JSON.
La structure de Reddit change fréquemment, ce qui peut affecter les performances du scraper. Par conséquent, le scraper doit être régulièrement mis à jour pour s’adapter aux modifications de la plateforme.
Meilleures pratiques pour l’utilisation d’un scraper Reddit en Python
Rotation de l’adresse IP
L’un des principaux objectifs de la rotation des adresses IP est l’anonymat. En outre, la plateforme peut détecter les demandes répétées provenant de la même adresse IP. Cela peut déclencher une interdiction d’IP, ce qui rend difficile la collecte complète des données
Traitement du CAPTCHA
Un scraper Reddit Python n’est pas équipé pour gérer les CAPTCHA, qui peuvent apparaître comme un moyen pour la plateforme de différencier les activités humaines de celles des robots. Pour contourner les CAPTCHA, utilisez des navigateurs sans tête comme Selenium, Playwright et Puppeteer pour imiter le modèle de navigation humain. Il est ainsi plus difficile de détecter les activités automatisées.
Utiliser des navigateurs sans tête pour gérer les contenus dynamiques
Comme les sites web modernes, Reddit utilise JavaScript pour charger du contenu dynamique. Les scrapers classiques n’analysent généralement que le contenu HTML et peuvent être incapables de charger du contenu dynamique. Une façon de gérer ce problème est d’intégrer des navigateurs sans tête comme Selenium
Avantages de l’utilisation de Python
- Comme il s’agit d’une bibliothèque open-source, elle est gratuite.
- Hautement personnalisable
- Fiable
Inconvénients de l’utilisation des scrapeurs Python
- Nécessite des connaissances en programmation Python
- Limité aux données publiques
- Limité aux limites de l’API de Reddit
Cas d’utilisation des données Reddit
Le web scraping de Reddit permet d’accéder à des données qui peuvent être utilisées à diverses fins. Voici quelques-uns des cas d’utilisation les plus courants :
Étude de marché
De nombreux professionnels collectent des données Reddit pour réaliser des études de marché. Les informations collectées peuvent être triées et analysées pour comprendre le sentiment du marché, les tendances actuelles et la réputation des différentes marques. Par conséquent, les données peuvent être interprétées pour prendre des décisions qui influencent les publicités, l’emballage et le prix des produits qui conviennent au marché cible.
Analyse financière
La plupart des gens ignorent qu’il existe toute une communauté d’experts financiers sur Reddit. Qu’il s’agisse de sujets financiers concernant les actions, les parts, les crypto-monnaies ou les marchés internationaux, Reddit contient un grand volume de données. L’analyse financière est nécessaire avant de réaliser tout investissement important afin de minimiser le risque de perte. Ces données peuvent être extraites, analysées et interprétées pour comprendre les prévisions du marché et prendre des décisions financières éclairées.
IA et apprentissage automatique
Les données de Reddit peuvent être utilisées pour former des LLM (Large Language Models) afin d’améliorer les résultats des recherches effectuées par l’IA. Les robots d’IA ne peuvent être plus performants que les données qu’ils reçoivent. Par conséquent, le grand nombre de visiteurs quotidiens de Reddit en fait une source de données idéale. L’IA native de Reddit, un LLM alimenté par les données de la plateforme pour fournir des pages personnalisées à chaque visiteur, en est un exemple.
Recherche sociale
La recherche sociale est un autre cas d’utilisation des données Reddit. La collecte de données sur les subreddit peut être utilisée pour des études sur les modèles d’interaction humaine. La recherche sociale peut être utilisée pour recueillir des données concernant les tendances et les opinions sur des sujets tels que la protection de la vie privée en ligne et le consentement. En outre, les données peuvent être utilisées pour former les chatbots à fournir une assistance 24 heures sur 24 et 7 jours sur 7, ce qui n’est pas toujours possible avec des agents d’assistance humains.
Comment récupérer les données de Reddit avec Floppydata Web Unblocker
Utiliser le Web Unblocker de Floppydata comme scraper Reddit est facile et peut être réalisé en quelques étapes. Voici un guide étape par étape sur la façon de scraper les données Reddit avec Floppydata.
Allons-y !
Étape 1 : Visitez la page Web Unblocker et connectez-vous pour commencer.
Étape 2 : Connectez-vous à votre compte Reddit. Ouvrez une page de résultats de recherche avec des filtres spécifiques correspondant à votre cas d’utilisation.
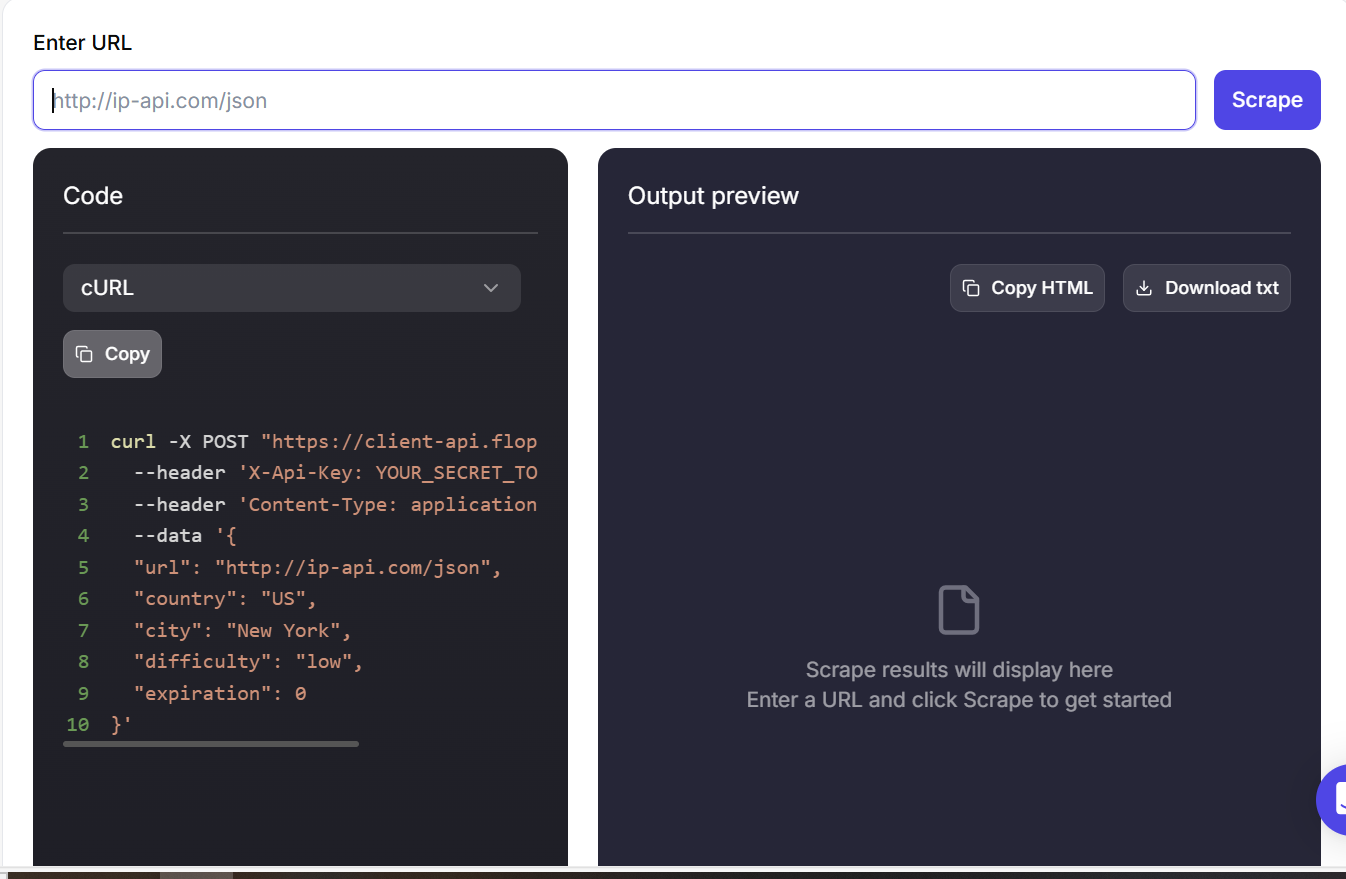
Étape 3 : Allez sur le tableau de bord de Floppydata’s Web Unblocker et collez l’URL
Étape 4 : Vos résultats sont prêts en quelques minutes.
Conclusion
Apprendre à récupérer les données de Reddit peut s’avérer très utile pour les chercheurs, les particuliers et les entreprises. C’est un moyen de recueillir des informations auprès de l’une des plus grandes communautés mondiales sur le web. Pour collecter ces données, vous pouvez soit écrire un script avec un langage de programmation, soit utiliser une solution sans code.
Floppydata propose une solution complète de scraping sans code – Web Unblocker, qui extrait efficacement les données de Reddit et les livre dans le format de votre choix. Les nouveaux utilisateurs bénéficient de 5 sessions gratuites pour collecter des données à partir de n’importe quelle plateforme.
Vous voulez une expérience facile et transparente avec les données de Reddit, essayez le Web Unblocker de Floppydata dès aujourd’hui !





