


Les données sont aujourd’hui un atout essentiel pour de nombreuses organisations dans divers secteurs. Néanmoins, de nombreuses organisations collectent des données plus rapidement qu’elles ne peuvent les traiter. Les techniques de collecte et de manipulation des données influencent les décisions opérationnelles des entreprises.
Puisque la qualité de l’entrée influe sur la sortie, il est nécessaire de s’assurer que votre système reçoit des données de bonne qualité. C’est pourquoi vous avez besoin d’une bonne architecture de pipeline d’ingestion de données pour favoriser la production d’informations exploitables.
Dans ce guide, nous allons faire la lumière sur les pipelines d’ingestion de données, les types d’ingestion de données et les cas d’utilisation courants.
Qu’est-ce que l’ingestion de données ?
L’une des questions les plus fréquentes que l’on se pose lorsqu’on essaie de comprendre le pipeline d’ingestion est « qu’est-ce que l’ingestion de données ?
Le terme d’ingestion de données décrit le processus de collecte, de tri et d’organisation des données provenant de diverses sources dans un stockage central – comme un datahub ou un entrepôt de données. Ce processus marque la première étape de la préparation des « données brutes » en vue d’un traitement et d’une interprétation ultérieurs. L’ingestion de données est une étape très importante du pipeline, car c’est à ce stade que les données sont collectées à partir de diverses sources qui influenceront la manière dont les entreprises obtiennent des informations sur leurs produits et un avantage concurrentiel.
Voici quelques-unes des sources de données les plus courantes pour le pipeline :
- Bases de données
- Internet des objets
- Centres de données
- Plateformes de médias sociaux
- API
- Fournisseurs de données tiers
- Applications SaaS
Avantages de l’ingestion de données
Toutes les entreprises, quelle que soit leur taille, peuvent bénéficier de l’ingestion de données, qui leur permet de connaître les tendances du marché, les sentiments des consommateurs, les stratégies innovantes, etc. Voici quelques-uns des avantages les plus courants de l’ingestion de données :
Disponibilité des données
L’un des avantages de l’ingestion de données est qu’elle élimine le besoin de silos de données. Cela favorise la disponibilité des données pour l’analyse en regroupant les données provenant de diverses sources en une seule source centrale.
Évolutivité
La croissance des entreprises s’accompagne d’un besoin de données de bonne qualité. C’est pourquoi les pipelines d’ingestion de données jouent un rôle central dans le traitement de gros volumes de données tout en garantissant leur validité, leur exactitude et leur fiabilité.
Analyse en temps réel
Un autre avantage du pipeline d’ingestion de données est que les données sont traitées immédiatement ou par lots, ce qui permet d’accéder à des informations actualisées. Les entreprises peuvent ainsi réagir rapidement aux tendances et prendre des décisions opportunes susceptibles d’influer sur la marge bénéficiaire globale.
Efficacité
Les pipelines d’ingestion de données étant automatisés, il n’est plus nécessaire de traiter manuellement les données. Cela permet d’économiser du temps et des ressources en rationalisant le processus d’importation et de stockage des données pendant que l’équipe se concentre sur d’autres tâches prioritaires.
Types d’ingestion de données
Rassembler des données provenant de différentes sources dans un espace de stockage central semble assez simple. Cependant, cela peut s’avérer un peu plus compliqué, en particulier pour le pipeline de données. Vous trouverez ci-dessous les types d’ingestion de données les plus courants :
Ingestion par lots
Il s’agit du processus par lequel un grand volume de données est collecté à des intervalles particuliers. Ces intervalles peuvent être horaires, quotidiens ou même hebdomadaires, en fonction de vos besoins en matière de collecte de données. L’ingestion de données par lots convient donc aux entreprises qui n’ont pas besoin de données en temps réel pour prendre des décisions.
Il s’agit du type d’entreprises qui peuvent confortablement fonctionner et prendre des décisions sur la base de mises à jour périodiques des données.
Ingestion en temps réel
Cette technique exige que les données soient reçues au moment précis où elles sont créées. Cette technique permet donc de recevoir des données fraîches, qui sont très importantes pour la prise de décision. L’ingestion en temps réel permet de réduire le délai entre la réception et le traitement des données. Parmi les cas d’utilisation des données en temps réel, citons la détection des fraudes, le traitement des données provenant de capteurs et la mise à jour des tableaux de bord en temps réel. Le pipeline d’ingestion de données en temps réel peut traiter les données en temps réel ou par morceaux pendant qu’elles sont extraites. Bien que cette technique permette d’obtenir des données fraîches, la gestion des erreurs et l’évolutivité sont des questions complexes.
Architecture Lambda
L’architecture Lambda combine l’ingestion par lots et en temps réel pour offrir un équilibre entre vitesse et précision. Les données par lot fournissent des tendances historiques complètes, tandis que les données en temps réel offrent un aperçu des activités en cours.
L’approche Lambda est souvent utilisée dans des situations qui nécessitent de traiter d’énormes volumes de données avec une grande précision. Par la suite, elle permet aux entreprises de réagir rapidement aux événements actuels sans perdre la connaissance des événements antérieurs du marché.
Qu’est-ce que le pipeline d’ingestion de données ?
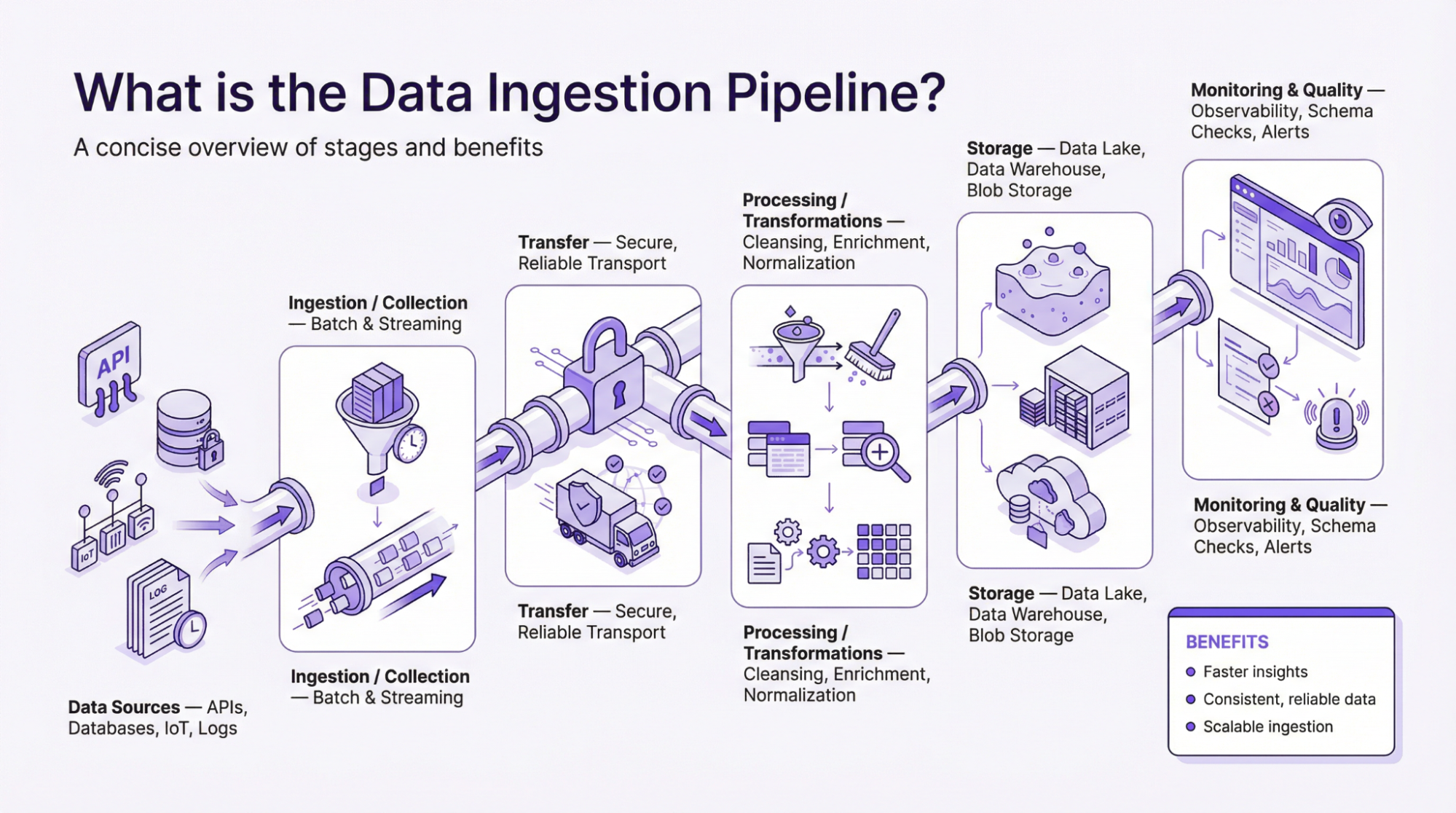
À la question principale« Qu’est-ce qu’un pipeline d’ingestion de données ? », nous répondons que lepipeline est souvent décrit comme un cadre. – Le pipeline, souvent décrit comme un cadre, décrit le flux de données du point de collecte jusqu’à ce qu’il soit traité et appliqué pour prendre des décisions fondées sur des preuves. Un pipeline de données est simplement la manière dont les informations circulent d’un bout à l’autre. Il s’agit d’un ensemble d’instructions qui collectent des données à partir de différentes sources, les traitent et les envoient à une destination. Par conséquent, un pipeline d’ingestion de données approprié est nécessaire pour que les organisations utilisent efficacement les données afin de stimuler la croissance, les bénéfices et le retour sur investissement.
Étapes de la construction d’un pipeline de digestion de données efficace
Voici quelques étapes clés pour construire un pipeline de digestion de données efficace :
- Déterminer les sources de données: La première étape de la construction d’un pipeline de digestion de données efficace consiste à identifier la source des données. Avant de définir les sources de données, vous devez d’abord définir le type de données, le volume, la vitesse et les objectifs de l’organisation. Le choix de sources de données fiables et durables joue un rôle dans la précision et la fiabilité des résultats.
- Choisissez la destination des données : Ensuite, vous devez déterminer la destination des données. C’est l’endroit où vous stockerez toutes les données que vous obtenez de différentes sources. Le système de destination peut être un lac de données, un entrepôt ou d’autres types de stockage, selon vos préférences.
- Sélectionnez la méthode d’ingestion des données: Il existe différents types de méthodes d’ingestion des données. Vous devez donc choisir celle qui répond le mieux aux besoins spécifiques de votre entreprise. En fonction de vos objectifs commerciaux, vous pouvez choisir entre l’ingestion par lots, l’ingestion en flux ou un mélange des deux.
- Concevoir le processus d’ingestion : Cette méthode consiste à déterminer comment les données seront collectées, traitées et stockées dans le système de destination. Dans le monde numérique d’aujourd’hui, le processus d’ingestion est automatisé afin de promouvoir l’efficacité et de réduire les erreurs humaines. Une autre raison d’automatiser le processus est la cohérence. L’automatisation du flux de données dans le pipeline permet de s’assurer que les données sont acheminées conformément au plan et d’éviter les goulets d’étranglement.
- Surveillance et maintenance: Une fois le processus d’ingestion des données mis en œuvre, vous devez surveiller ses performances. Cela implique la mise en place d’alertes en cas d’échec des tâches. Un contrôle régulier permet de détecter les problèmes et de les résoudre rapidement afin de garantir la cohérence de la disponibilité des données.
Architecture du pipeline de données
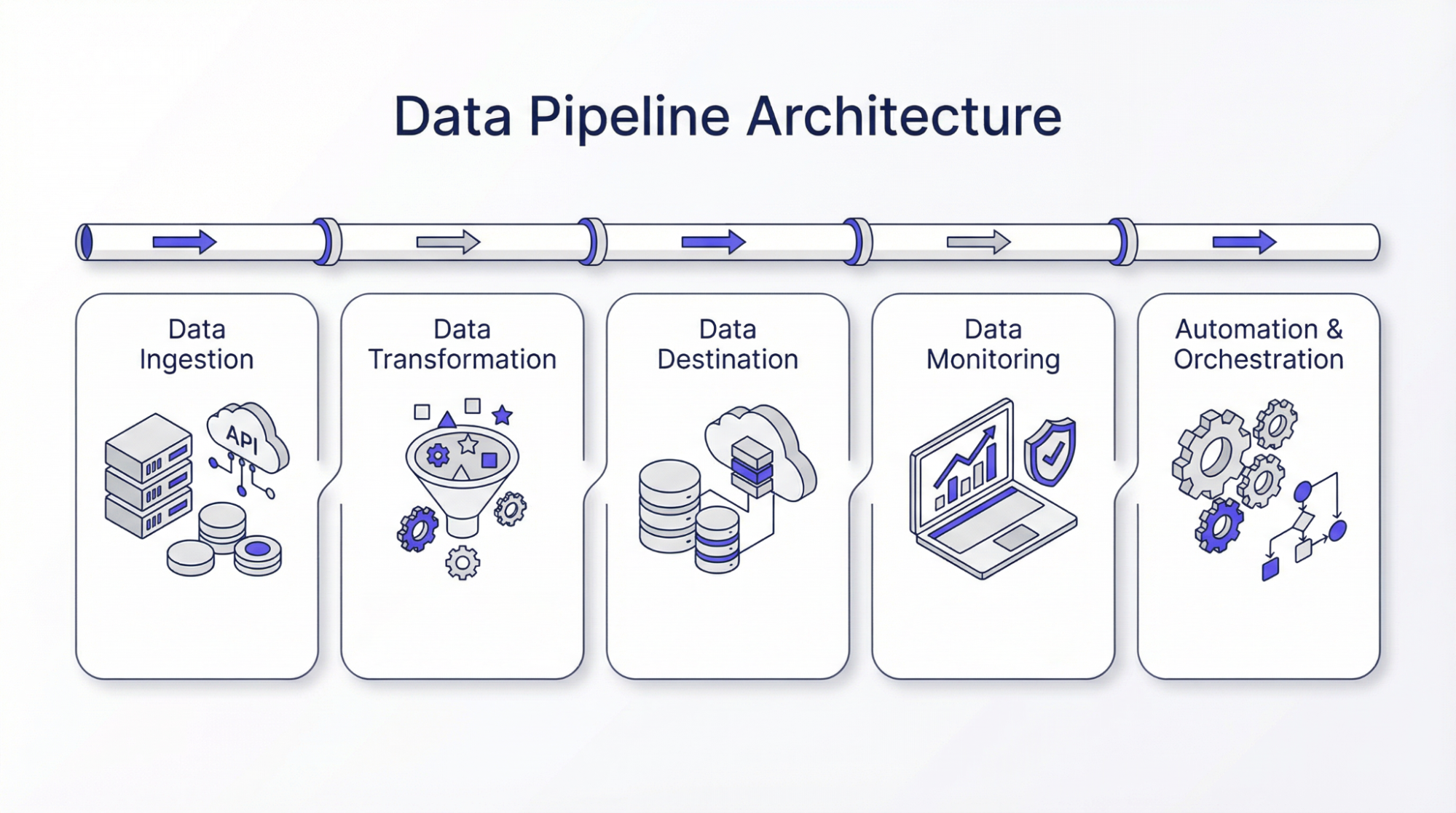
Voici les étapes de l’architecture d’un pipeline de données :
Ingestion de données
La première étape de l’architecture d’un pipeline de données est la collecte de données à partir de différentes sources. Des données de bonne qualité sont toujours une priorité, car elles affectent l’authenticité de l’ensemble du processus. Les données ingérées ou collectées peuvent être structurées ou non structurées en fonction de la technologie. Certaines personnes préfèrent collecter des données uniquement lorsque cela est nécessaire, tandis que d’autres collectent des données et les stockent. Cela leur permet de mettre à jour leurs données historiques et d’utiliser les données à des fins de comparaison. À ce stade, différents mécanismes sont utilisés pour garantir la fiabilité et l’exactitude des données. La mise en œuvre de mesures favorisant la résilience et l’évolutivité permet de garantir des performances fluides en aval.
Transformation des données
La transformation des données est le processus qui consiste à transformer les données dans la forme requise. Cette étape est importante, car les données recueillies peuvent ne pas se présenter sous la même forme. Par exemple, les données peuvent être sous forme de JSON, et le JSON peut être imbriqué. Par conséquent, l’objectif principal de cette étape, ou transformation des données, est de dérouler le JSON pour obtenir les données clés en vue d’un traitement ultérieur. En d’autres termes, la transformation des données est nécessaire pour mettre toutes les données dans la forme souhaitée, ou plutôt dans une forme standard. L’objectif de la transformation des données est de les nettoyer, de les filtrer et d’augmenter leur valeur pour les décisions de l’entreprise. Plusieurs algorithmes tels que les méthodes informatiques, l’analyse statistique ou l’apprentissage automatique peuvent être utilisés pour générer des informations exploitables.
Destination des données
Les destinations des données sont les endroits où les données traitées sont stockées dans l’architecture du pipeline. Il peut s’agir d’entrepôts de données, de bases de données en nuage ou de lacs de données. Le choix d’un stockage approprié est important car il influe sur la facilité d’accès aux données. Divers facteurs tels que le type de données, le volume et l’objectif sont pris en compte avant de choisir la destination des données.
Une bonne architecture de pipeline de données est celle qui garantit que les analystes peuvent facilement accéder aux données à partir des destinations. Elle doit également être conçue pour traiter rapidement et avec précision d’importants volumes de données. À ce stade, des politiques de protection des données sont mises en œuvre pour assurer la sécurité et la conformité des données.
Contrôle des données
Le contrôle des données est nécessaire pour garantir le respect des politiques et des réglementations. Il est nécessaire de maintenir la sécurité et l’intégrité. Par conséquent, cette étape comprend la définition des rôles pour la gestion des données, l’audit et la mise en œuvre des contrôles d’accès. Le cadre de contrôle est essentiel pour empêcher l’accès non autorisé aux données et le respect de lois telles que le Règlement général sur la protection des données. En outre, le contrôle de la qualité des données est utile pour détecter les anomalies et les erreurs dans le pipeline. Par conséquent, la mise en œuvre d’étapes de validation des données et la détection des erreurs garantissent la fiabilité et l’exactitude des résultats. En outre, les outils de contrôle fournissent une vue d’ensemble des performances du pipeline de données et détectent les problèmes afin de les résoudre rapidement.
Automatisation et orchestration
L’orchestration des données peut être définie comme la coordination du mouvement des données le long du pipeline. Cette coordination est nécessaire pour s’assurer que les processus sont exécutés correctement. Ces outils déclenchent des flux de travail et gèrent les actions de récupération, ce qui minimise les interventions manuelles. Une bonne stratégie d’orchestration tient compte de la mise à l’échelle dynamique, de l’équilibrage de la charge et du traitement parallèle. Ces outils jouent donc un rôle clé dans la performance des pipelines de données afin de garantir un flux de données fluide avec un minimum d’interruptions.
Cas d’utilisation de l’ingestion de données
Vous trouverez ci-dessous différentes utilisations de l’ingestion de données
Détection de la fraude en finance
Certaines organisations financières utilisent une architecture d’intégration de données pour détecter et prévenir la fraude. L’intégration d’un système robuste de cryptage et de cartographie dans le secteur financier est cruciale pour la détection de la fraude. Cela permet de renforcer la confiance et de réduire les pertes financières.
Apprentissage automatique
L’apprentissage automatique est une branche de l’IA qui utilise des données pour former de grands modèles de langage (LLM) utilisés dans divers secteurs. L’apprentissage automatique est également important dans la mesure où il utilise des données pour imiter la manière dont les êtres humains raisonnent, communiquent et résolvent les problèmes. En outre, il peut également être utilisé pour faire des prédictions à l’aide de données collectées à partir des tendances passées et actuelles.
Analyse et suivi
Un data scientist est également susceptible de travailler avec un grand nombre de données à analyser et à tirer des conclusions inférentielles. Les pipelines d’ingestion de données sont utiles dans ce cas, car ils fournissent des données dans un format facile à catégoriser. Par la suite, cela permet à un analyste de données d’utiliser facilement des outils de visualisation de données pour analyser les données et tirer des conclusions de manière efficace.
Défis associés à l’architecture du pipeline de données
Malgré sa simplicité, l’architecture d’un pipeline de données n’est pas sans poser de problèmes. Par exemple, il y a des défis tels que :
Qualité incohérente des données
L’un des problèmes les plus fréquemment rencontrés avec les pipelines d’ingestion de données est l’incohérence de la qualité des données. Cela peut conduire à une mauvaise décision et, par conséquent, à l’instabilité des opérations. L’architecture du pipeline de données doit donc être conçue avec certains composants capables de mesurer et de contrôler efficacement la qualité des données. La qualité des données a été définie comme des données de haute qualité si les données sont :
- Précision
- Cohérent
- Pertinent
- En temps utile
- Compléter
- Unique en son genre.
En outre, l’automatisation du processus de nettoyage des données permet d’éviter les erreurs susceptibles d’être rencontrées au cours du processus. Ces éléments doivent donc être inclus dans le pipeline d’ingestion des données afin d’améliorer la pertinence des résultats.
Sécurité des données et protection de la vie privée
De nombreux pays ont été en mesure d’introduire des lois sur la protection des données afin de garantir la sécurité des données à l’ère actuelle du web scraping automatisé. Ces lois dictent également l’utilisation des données obtenues en ligne. Le respect de ces lois permet donc d’instaurer un climat de confiance avec les parties prenantes, les partenaires et les clients. Il est essentiel de protéger les données contre tout accès non autorisé et de les utiliser dans le respect de la loi. Il est donc nécessaire que l’architecture du pipeline d’ingestion des données intègre un cryptage fort pour préserver la confidentialité des données.
Évolutivité
Un autre problème rencontré lors de l’ingestion de données est l’évolutivité, c’est-à-dire la capacité à traiter de grandes quantités de données. Lorsqu’il y a une augmentation de la demande de données, il est nécessaire d’améliorer les performances des pipelines. Toutefois, il est possible d’utiliser des solutions basées sur l’informatique dématérialisée pour améliorer l’évolutivité.
Goulets d’étranglement des performances
Un problème de performance récurrent peut apparaître en raison de la complexité des données. Ce problème peut survenir à n’importe quel stade du pipeline.
Les goulets d’étranglement commencent souvent lorsqu’une étape du cadre traite les données à un rythme plus lent que l’étape précédente, créant ainsi un arriéré. Une planification adéquate et l’utilisation des bons outils peuvent contribuer à atténuer ce problème dans le pipeline d’ingestion des données.
Relation entre le Data Pipeline et l’ETL
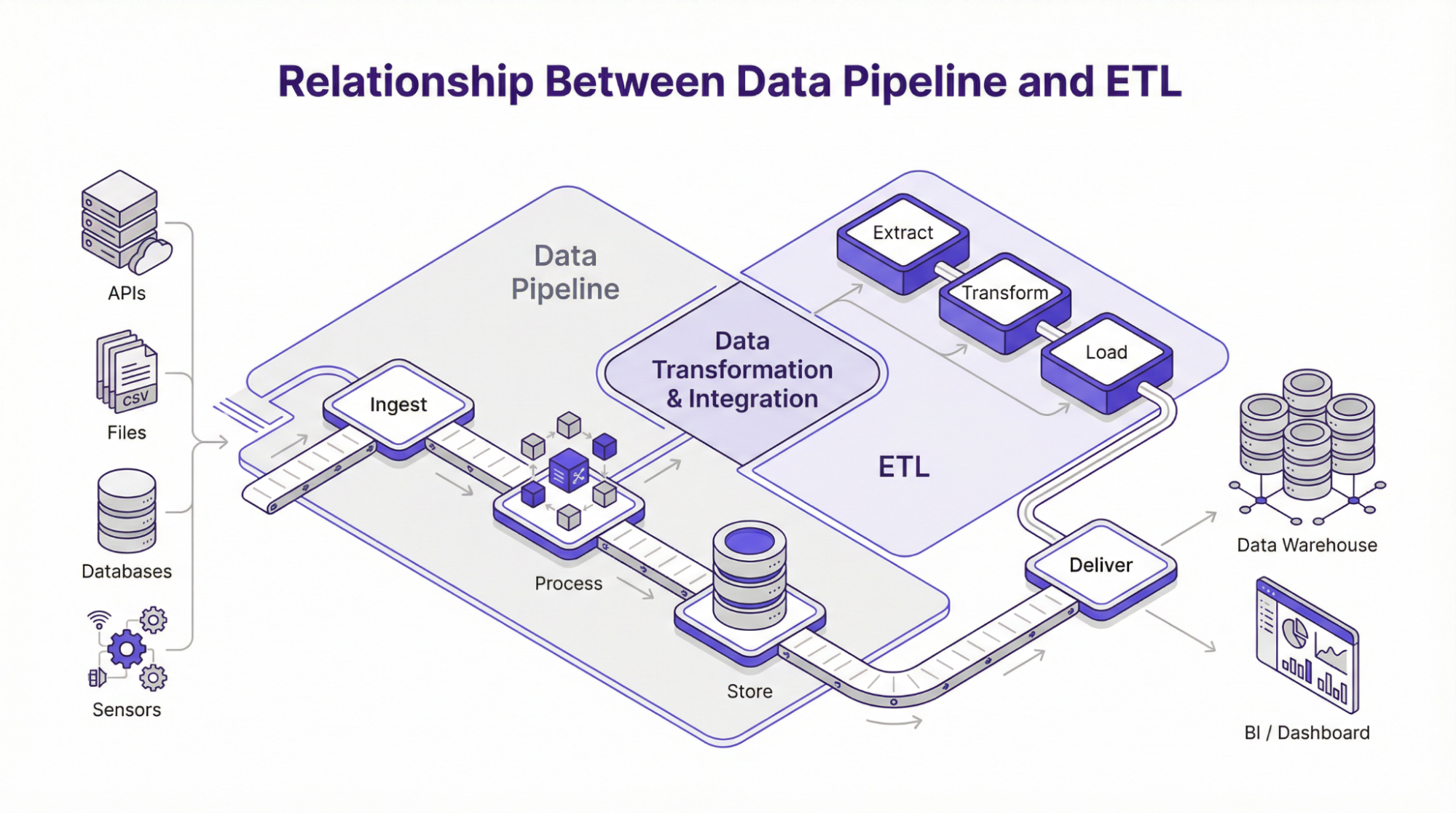
L’ETL, qui signifie extraction, transformation et chargement, est l’une des méthodes les plus courantes pour construire des pipelines de données. Comme son nom l’indique, elle définit un chemin spécifique pour les données au fur et à mesure qu’elles se déplacent dans le système.
Dans un pipeline ETL standard ou traditionnel, les données sont extraites de diverses sources. Elles sont ensuite transformées en une couche de traitement, à partir de laquelle elles sont chargées dans une unité de stockage de destination telle qu’un entrepôt de données. Ce processus est souvent utilisé dans des cadres de traitement par lots, où les données sont collectées et traitées à des périodes programmées. En outre, ce cadre est mis en œuvre lorsque les données doivent être validées, formatées ou transformées dans un format structuré avant d’être stockées. Cependant, l’architecture moderne des pipelines de données prend en charge d’autres cadres tels que :
ELT – Extraire, Charger, Transformer
Le modèle ELT consiste à charger les données dans le stockage de destination immédiatement après leur extraction de diverses sources. Les transformations sont effectuées ultérieurement à l’aide d’outils tels que SQL ou DB. Cependant, le cadre ELT est généralement préféré dans les situations où le calcul et le stockage sont des unités séparées, comme dans les pipelines basés sur le cloud.
ETL inversé
Dans ce cadre, les données se déplacent dans le sens inverse de ce que nous voyons dans l’ETL. En d’autres termes, les données passent de l’entrepôt à des outils externes tels que les systèmes d’assistance à la clientèle, les modèles d’apprentissage automatique ou la gestion de la relation client. Par la suite, les entreprises peuvent intégrer l’analyse dans les opérations en reliant les données de l’entrepôt aux outils utilisés par les équipes d’assistance, de vente ou de marketing. Bien que l’ETL, l’ELT et l’ETL inverse déplacent les données dans différentes directions, l’objectif reste le même : extraire les données de l’endroit où elles sont générées et les envoyer à l’endroit où elles sont nécessaires. Par conséquent, la compréhension de ces mécanismes de flux de données informe les équipes sur la meilleure approche pour construire un pipeline d’ingestion de données qui soit pertinent, évolutif et aligné sur les objectifs opérationnels.
Réflexions finales
Les organisations ont besoin de beaucoup de données pour assurer leur stabilité. En même temps, elles s’efforcent d’ingérer des données plus rapidement qu’elles ne peuvent les traiter. L’ingestion de données est un système architectural qui peut aider à transformer toutes ces données en une forme utile. Il est donc efficace de créer un pipeline d’ingestion de données pour utiliser des ressources provenant de sources multiples.
Parmi les problèmes rencontrés lors du processus d’ingestion de données, citons la qualité des données, les performances, les problèmes de sécurité et le traitement de grandes quantités de données. Malgré tous ces problèmes, il est possible de rendre le processus d’ingestion de données fluide en utilisant les meilleures pratiques telles que la garantie de la qualité des données, l’évolutivité du cadre d’ingestion de données et le contrôle des performances du pipeline de données.





