

Les données sont le nouvel or. Toutes les entreprises modernes prospèrent grâce à elles. Qu’il s’agisse d’informations sur leurs clients, leurs marchés cibles et leurs concurrents ou d’énormes ensembles de données pour l’entraînement de modèles d’IA, les données sont le moteur de l’économie numérique. Il existe principalement deux façons de collecter une grande quantité de données pertinentes : Soit vous les collectez auprès de vos utilisateurs, soit vous les récupérez sur internet.
Le scraping de données consiste à collecter des données accessibles au public sur des sites web et à les affiner pour trouver des informations utiles. Ces informations peuvent ensuite être utilisées pour former des modèles d’IA, étudier le comportement des consommateurs, les tendances du marché et bien plus encore. Ce blog explore les meilleurs services web pour le web scraping en 2026 qui vous offrent une expérience de data scraping sûre et facile. Chaque examen de service comprend mon expérience personnelle, des avis de clients provenant de plateformes de confiance et une liste récapitulative des avantages, des inconvénients et des prix.
Pourquoi a-t-on besoin de services automatisés de Web Scraping ?
Imaginez que vous souhaitiez vérifier le prix de vente d’un produit par vos concurrents. Vous voulez rechercher sur Ebay et Amazon les prix, les titres et les descriptions des produits, etc. et analyser comment vous allez positionner votre produit. Un service de web scraping vous aide à automatiser cette opération en recherchant automatiquement votre domaine cible et en collectant les données dans le format de votre choix.
Le web scraping n’est pas aussi simple que l’exemple ci-dessus. Des plateformes comme Amazon, Ebay et Meta déploient de puissants systèmes anti-scraping pour bloquer les racleurs de sites web. La raison en est simple : Elles ne veulent pas que des robots automatisés extraient des données sur les clients et chargent inutilement leurs serveurs. C’est là qu’interviennent les services de web scraping. Ils vous aident à extraire des données plus rapidement sans vous soucier de la gestion des proxys et des interdictions.
Les services de « web scraping » contournent les systèmes de détection des sites web pour récupérer des pages web en masse. Les sites web détectent les robots grâce à plusieurs signaux tels que le comportement de navigation, les mouvements de souris, les modèles de défilement, les déclencheurs CAPTCHA et la fréquence des demandes. Si le système de détection détecte l’un de ces signaux, vous risquez d’être banni. Les services de « web scraping » sont conçus pour échapper aux systèmes de détection en imitant le comportement humain réel.
Comment évaluer quel service de Web Scraping utiliser ?
D’après mon expérience personnelle, n’optez jamais pour un service de scraping qui offre plus de fonctionnalités sur le papier. Lisez toujours d’abord les commentaires des clients et essayez le service s’il propose un plan gratuit pour voir s’il fonctionnera à long terme. Si votre entreprise prospère grâce au scraping de données, vous avez besoin d’un service qui :
- Ne devrait pas se briser en cours de production
- Vos comptes ne risquent pas d’être bannis
- A une expérience client
- La protection de la vie privée est au centre des préoccupations
- met régulièrement à jour ses outils pour répondre aux exigences changeantes de l’internet
Idéalement, vous voulez un outil qui peut extraire des données sans que vous ayez à le surveiller. Voici donc les critères de base sur lesquels nous avons évalué les meilleures sociétés de scraping :
- Outils de déblocage : Comment il gère les CAPTCHAs, les WAFs, les 403/409 et les pages lourdes en JS.
- Automatisation : Niveau d’automatisation qu’il offre, comme la mise en lots, les tentatives, le rendu et la prise en charge de l’API.
- Clarté de la tarification : La tarification doit être suffisamment claire pour permettre de fixer des objectifs à long terme en matière de budget et de résultats.
- Convivialité pour les débutants : qualité de la documentation et facilité d’utilisation de l’interface utilisateur pour une prise en main rapide.
- Examens du marché : Ce que les clients de TrustPilot, G2 et Capterra pensent du service.
Les 10 meilleures entreprises de Web Scraping pour l’automatisation du Data Scraping
1. Floppydata : Meilleur service de scraping Web basé sur une API

Si vous voulez choisir une option qui ne pose pas de problème, optez pour Floppydata. Il vous offre deux choses : Un énorme pool d’IP propres avec un ciblage au niveau de la ville dans 195 pays, et une excellente API de scraping qui résout les CAPTCHA, scrape les pages lourdes en JS, et a un coût très minime.
J’ai aimé Floppydata pour sa simplicité. Vous pouvez tester n’importe quelle URL de site web en la collant dans leur champ de test et ils vous renvoient instantanément des données extraites. Ce contenu extrait vous aide à analyser ce que vous voulez extraire de ce HTML brut. Floppydata génère également des exemples de code en cURL, Python, JavaScript et R que vous pouvez utiliser dans votre workflow d’automatisation du scraping.
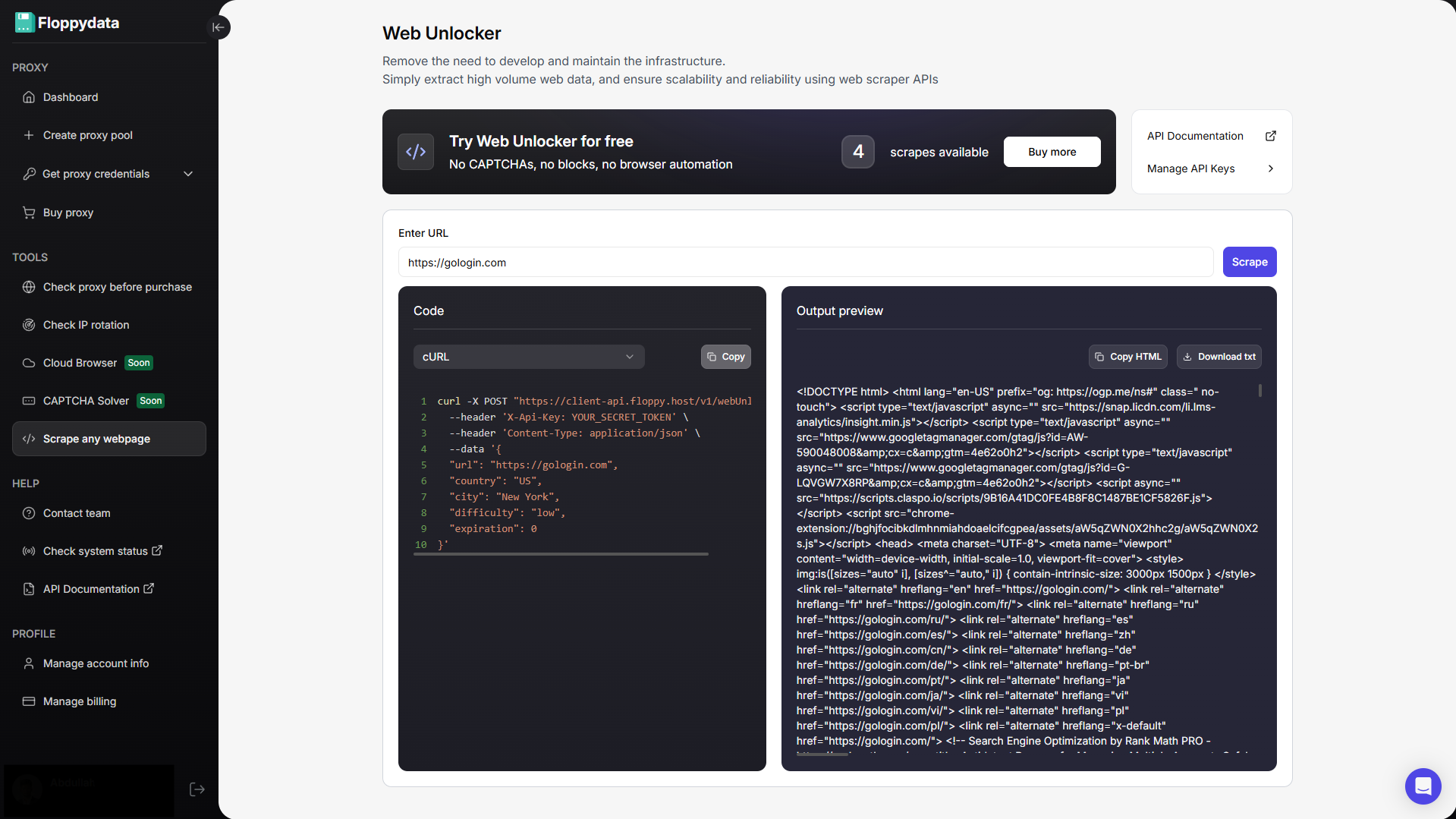
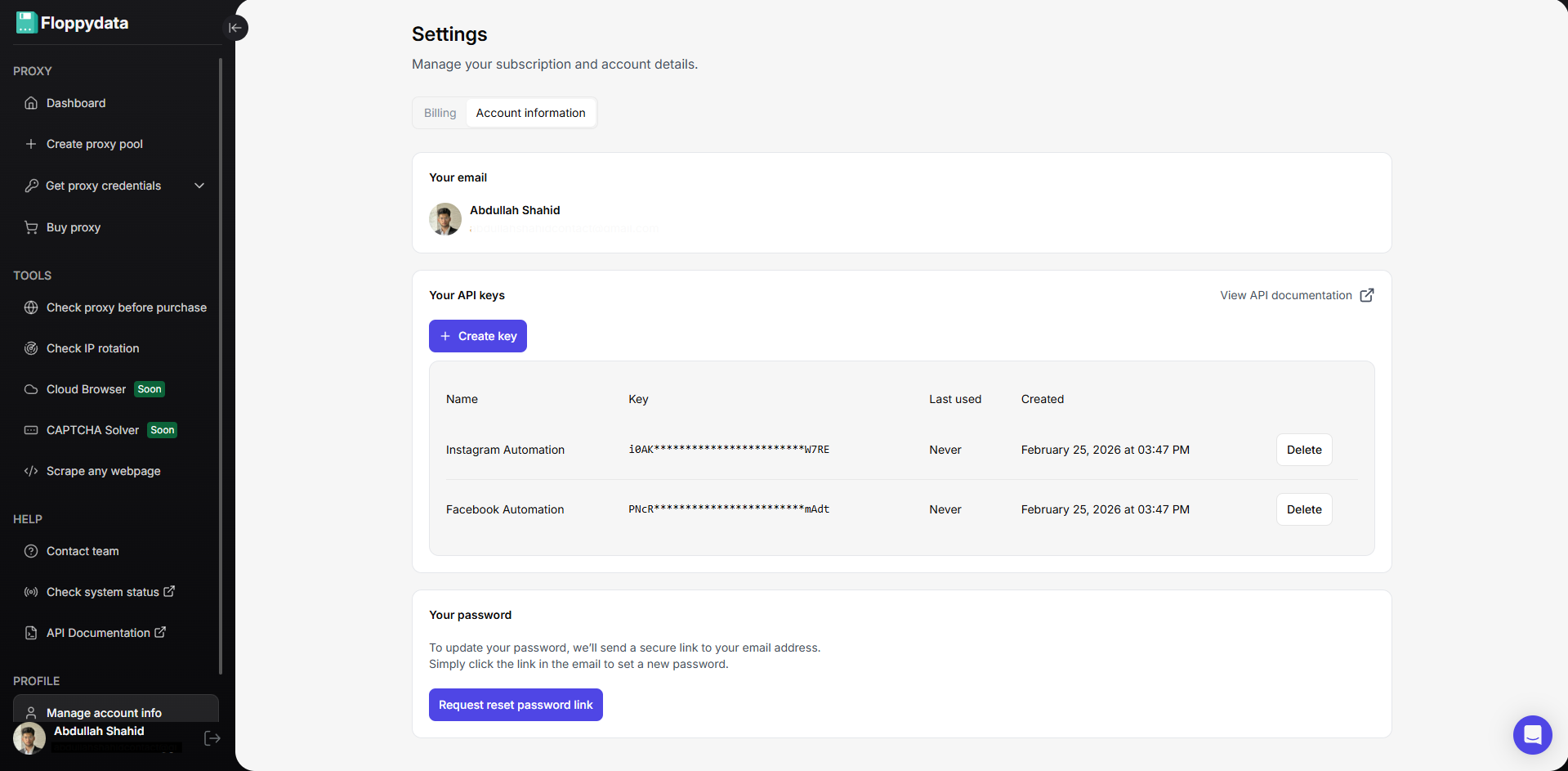
Après avoir vérifié que le domaine fonctionne, vous pouvez maintenant configurer une clé API et commencer à travailler. Vous pouvez l’ajouter à votre flux de travail de scraping comme vous le souhaitez. Voilà, c’est fait !
Tarification:
Floppydata est un excellent rapport qualité-prix car je n’ai pas besoin d’acheter et de configurer des proxies séparément. Ils choisissent automatiquement des proxies dans leur propre pool pour mes tâches d’automatisation web. Je ne paie que pour les extractions réussies (pas pour celles qui ont échoué ou si une page web a été retentée à partir de 10 proxys différents).
- Procès : 5 demandes gratuites
- Package de base : 9$ / 10K scraps réussis
- Package avancé : 89$ / 100K scrapes réussis
- Plan personnalisé : solution sur mesure basée sur les besoins du client
| Pros | Cons |
| Prix d’entrée élevé, convivialité de l’interface utilisateur | Ne fournit pas d’interface web pour la mise en place ou l’exécution de l’automatisation comme certains autres concurrents. |
| Web Unblocker conçu pour gérer les blocages 403/429, les CAPTCHAs, etc. | |
| Le scraping s’effectue dans le nuage et non sur votre appareil. | Vous devez avoir des connaissances en codage pour utiliser l’API |
2. Gologin : Meilleur navigateur antidétection pour l’automatisation de l’exploration du Web
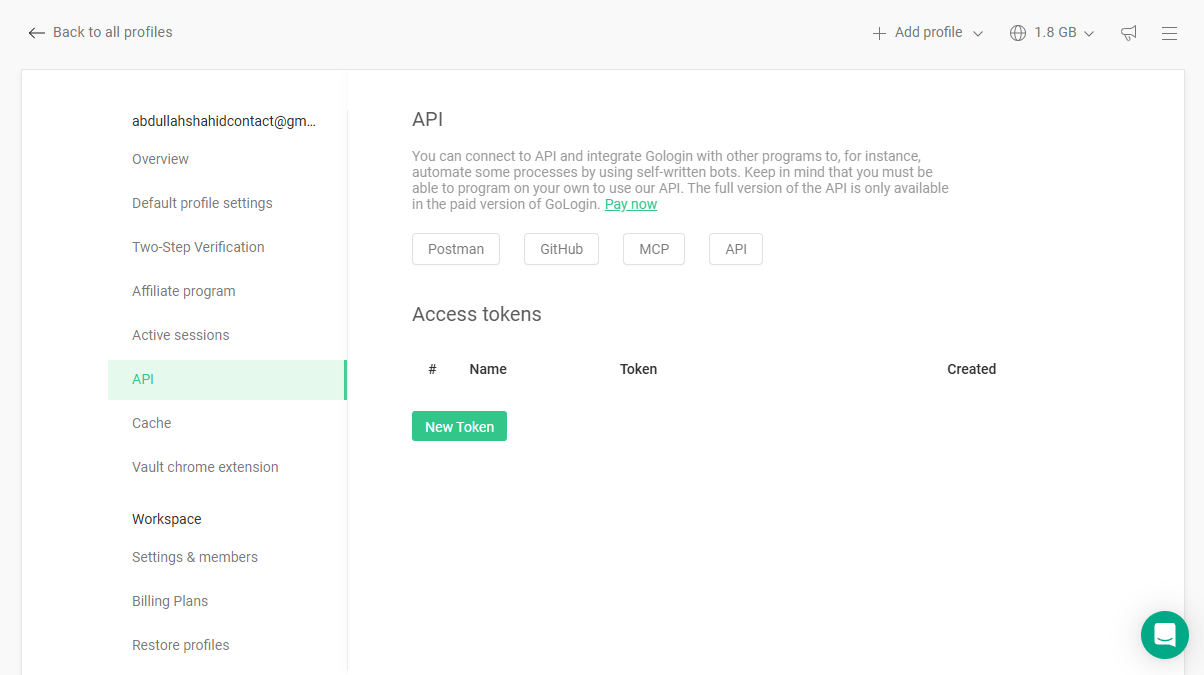
Bien que Gologin ne soit pas un fournisseur de proxy dédié, je l’ai placé en deuxième position en raison de ses capacités d’antidétection qui permettent d’exécuter des automatisations web sécurisées.
Vous pouvez exécuter des automatisations à l’aide de l’API de navigation dans le nuage de Gologin. Gologin vous aide à ajouter une couche de sécurité à votre automatisation grâce à sa fonctionnalité d’antidétection. Au lieu de risquer l’IP de votre réseau et l’empreinte digitale de votre appareil, Gologin vous fournit une empreinte digitale et une adresse IP uniques pour chaque profil de navigateur. Ainsi, chaque profil de navigateur Gologin ressemble à un appareil unique. Cela permet de protéger votre appareil et votre adresse réseau contre les interdictions lorsque vous exécutez des automatisations parallèles dans des milliers de profils Gologin en même temps, grâce à l’automatisation.
Pourquoi j’ai aimé Gologin :
Gologin ne se contente pas d’offrir un support API pour automatiser le scraping sur des centaines de profils de navigateurs simultanés, il dispose également d’un serveur MCP. Si vous ne savez pas ce qu’est un MCP, rappelez-vous ceci : Vous prenez la clé MCP de votre Gologin, vous la connectez à des outils d’intelligence artificielle comme Claude et maintenant cet outil d’intelligence artificielle peut accéder directement à Gologin. Vous pouvez alors demander à Claude d’exécuter certaines tâches dans Gologin. Cette fonctionnalité m’a permis d’exécuter des fonctions Web de base, comme la consultation de certains sites Web pour vérifier les prix, et de laisser Claude me rédiger une description du produit à partir des pages Web analysées.

Prix :
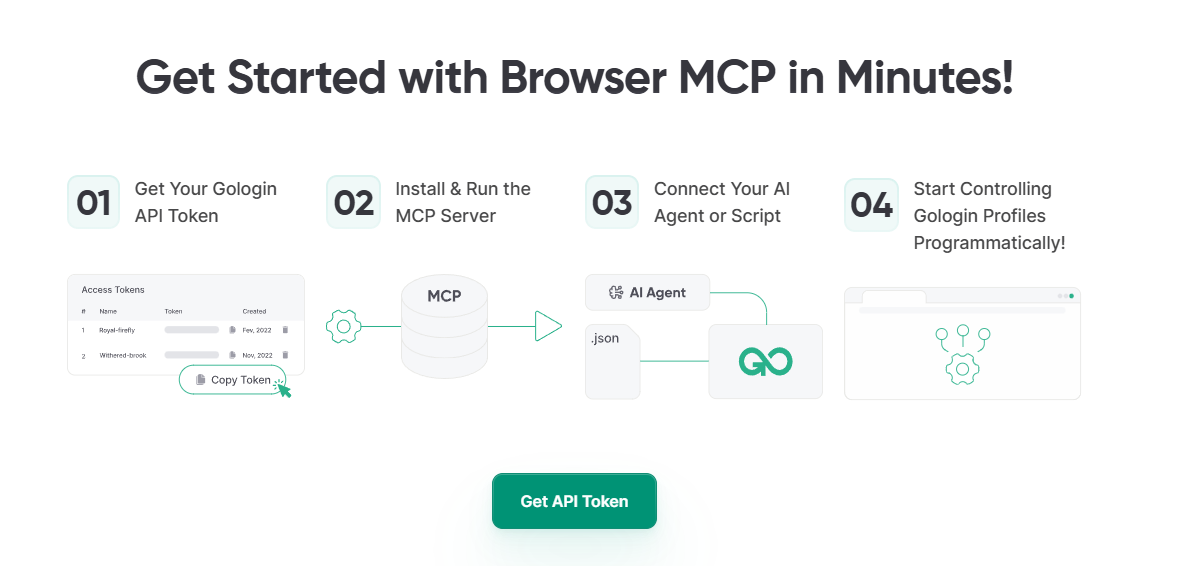
- Professionnel : 4$/mois, 100 profils, 10 partages de profils, 1 lancement dans le nuage, API REST (300 RPM)
- données de localisation, proxy résident de 2 Go
- Business : 59$/mois, 300 profils, 100 partages de profils, 2 lancements dans le nuage, API REST (500 RPM)
- Entreprise : 149 $/mois, 1000 profils, 1000 partages de profils, 3 lancements dans le nuage, API REST (800 RPM)
Des plans personnalisés sont disponibles. Les prix mentionnés sont annuels.
| Pros | Cons |
| Excellent navigateur anti-détection pour les flux de travail de scraping | Nécessite un couplage avec des proxys intégrés |
| Forte isolation des empreintes digitales par profil | Expérience de codage requise pour utiliser l’API |
| Abordable par rapport aux outils d’anti-détection d’entreprise |
3. Zyte : Infrastructure de scraping d’entreprise
Zyte (anciennement Scrapinghub) est l’un des plus anciens noms de l’industrie du web scraping depuis plus de 16 ans. Si vous recherchez un outil de qualité professionnelle, Zyte est une excellente option avec un modèle de tarification au fur et à mesure.
Ce qui m’a plu chez Zyte, c’est sa tarification simple pour trois types d’outils de web scraping. Ils ont une API Zyte pour le web scraping, une extension Zyte Copilot VScode pour les développeurs afin d’écrire des automatisations de scraping, et Zyte Cloud pour exécuter des automatisations dans le cloud et stocker des données dans des buckets de stockage AWS.
La plupart des API fonctionnent dans le nuage mais stockent les données sur votre appareil dans le format que vous avez demandé. Cependant, vous devez définir le format dans lequel les données doivent être extraites et stockées dans un format CSV ou Excel. Zyte fournit des formats prédéfinis pour l’extraction des données via son extension Zyte Cloud et Copilot.
Une autre excellente fonctionnalité offerte par Zyte est la gestion automatique des proxys. Ils décident quel type de proxy (centre de données, résidentiel, données mobiles) conviendra à chaque site web et utilisent ces proxys pour récupérer les données. Vous serez facturé en fonction du proxy choisi par Zyte.
Prix :
Zyte propose différents tarifs en fonction de l’outil que vous souhaitez utiliser pour le scraping.
- API Zyte : Réponse HTTP : 0,13 $ – 1,27 $ / 1 000 réponses / Rendu navigateur : 1,01 $ – 16,08 $ / 1 000 réponses. Le coût tombe à 0,06 $ – 0,10 $ avec un engagement mensuel.
- Scrapy Cloud : Gratuit pour toujours avec 1 unité cloud. Durée d’exploration d’une heure et rétention de 7 jours, 9 $ par unité/mois avec un nombre illimité d’explorations simultanées, une durée d’exploration illimitée, une rétention de données de 120 jours.
- Zyte Data : 500 $/mois pour des schémas standardisés, une fréquence d’exploration prédéfinie, une livraison JSON/CSV/XML OU 1 000 $/mois pour un schéma personnalisé, un calendrier d’exploration flexible, des formats de livraison personnalisés, un post-traitement avancé.
| Avantages | Inconvénients |
| Réputation de longue date dans le secteur | Coût plus élevé pour les plans avancés |
| Forte concentration sur la conformité | Moins adapté aux débutants |
| Gestion intelligente des procurations alimentée par l’IA | Peut nécessiter une intégration technique |
4. Apify : Modèles prêts à l’emploi pour le scraping Web
Apify n’est pas seulement une API de scraping, c’est une place de marché où vous pouvez créer ou utiliser des « acteurs » (scrapers) et des flux de travail préfabriqués. Au lieu de mettre en place une automatisation complète de Shopify, vous pouvez utiliser un acteur Shopify prêt à l’emploi qui vous aidera à récupérer les données nécessaires. Ces acteurs sont développés par la communauté et leur utilisation peut être payante.
Apify prospère grâce à son écosystème d’acteurs. Si vous souhaitez utiliser Apify, vous devez soit créer votre propre acteur, soit utiliser un acteur prédéfini, ce qui vous coûtera de l’argent. Certains des acteurs les plus populaires peuvent être très coûteux pour 1 000 résultats par rapport à l’utilisation d’une API et à l’écriture de vos propres scripts d’automatisation.
Apify propose une rotation de proxy, un serveur MCP, des intégrations de plateformes populaires pour créer votre acteur et un mécanisme anti-blocage pour un flux de travail de scraping sûr et automatisé. Si vous ne voulez pas écrire de code, Apify est un excellent point de départ.
Prix :
Le modèle de tarification d’Apify est déroutant. Vous bénéficiez d’un plan de base qui vous donne de la puissance de calcul. Vous pouvez acheter de la mémoire vive supplémentaire pour votre acteur si vous scrappez des sites web plus lourds. Les IP coûtent plus cher et si vous utilisez un acteur du marché, le coût pour 1 000 résultats diffère. En outre, les plans d’Apify se présentent comme suit :
- Démarrage : 29 $/mois, 0,3 $ par unité de calcul, 5 $ de crédits de magasin
- Échelle : 199 $/mois, 0,3 $ par unité de calcul, assistance par chat, 29 $ de crédits de magasin
- Entreprises: 999 $/mois, 0,25 $ par unité de calcul, assistance par chat prioritaire, 999 $ de crédits de magasin
Note : Les crédits du magasin peuvent être utilisés pour créer vos propres acteurs. Chaque type de compte offre des réductions plus importantes à l’achat si vous souhaitez utiliser des acteurs préconstruits par la communauté.
| Avantages | Inconvénients |
| Grand marché d’acteurs de scraping prêts à l’emploi | La tarification dépend de l’utilisation des ressources informatiques et peut évoluer de manière imprévisible. |
| Programmation intégrée, stockage et automatisation des flux de travail | Courbe d’apprentissage pour les débutants |
| Infrastructure complète de scraping dans une seule plateforme | Peut devenir coûteux à grande échelle |
| Prend en charge l’automatisation des navigateurs sans tête | Excessif si vous n’avez besoin que d’une API de scraping simple |
5. Octoparse : API Scraping pour les débutants
Octoparse est conçu pour les utilisateurs qui ne souhaitent pas écrire de scripts d’automatisation. Comme Apify, Octoparse propose des tonnes de modèles prêts à l’emploi que vous pouvez utiliser pour commencer à récupérer des données. Ils vont de l’extraction des descriptions de Youtube à l’extraction des prix des produits de Shopify. Il existe un modèle pour presque tous les cas d’utilisation.
Ce qui m’a plu chez Octoparse, c’est son constructeur visuel de flux de travail. Vous cliquez sur des éléments d’une page web, définissez ce qu’il faut extraire, et il construit la logique de scraping pour vous. Je peux personnaliser ce que je veux extraire et connecter des outils comme Slack, Google Drive, etc. pour stocker des données. Je peux exécuter des automatisations de scraping web à la fois localement et dans le nuage.
Tarification
- Plan gratuit : 10 tâches, exécution locale uniquement, limite d’exportation de 50K lignes/mois, pas d’automatisation dans le nuage.
- Plan standard : À partir de 83 $/mois, 100 tâches, 3 processus cloud simultanés, rotation IP, résolution CAPTCHA, exportations illimitées
- Plan professionnel : 299 $/mois, 250 tâches, 20 processus cloud simultanés, API avancée, surveillance du cloud, support prioritaire
- Plan Entreprise : Tarification personnalisée, 750+ tâches, 40+ processus cloud simultanés, serveurs haute performance, support dédié.
6. ScrapingAnt : L’API de scraping la plus abordable
ScrapingAnt se positionne comme l’API de scraping la plus économique, offrant 100 000 crédits d’API pour 19 $. Cependant, lorsque j’ai commencé à l’utiliser, j’ai réalisé que je devais gérer les proxies séparément, ce qui impliquait d’acheter de la bande passante pour les proxys et de les connecter ensuite à votre API. D’autres options comme Floppydata et Gologin incluent les proxies dans le prix indiqué pour l’API.
ScrapingAnt est un outil de scraping basé sur l’API qui bénéficie d’avis positifs sur Capterra. Vous exécutez un script d’automatisation de base avec une clé API et des URL de destination et il vous renvoie le HTML rendu. Cependant, cet outil n’offre rien de spécial, si ce n’est son prix par rapport à BrightData ou Zyte.
Tarification
- Plan gratuit : Gratuit, 10 000 crédits API par mois, adapté aux tests de petits projets.
- Enthusiast Plan : 19 $ par mois, 100 000 crédits API, idéal pour les indépendants et les petites tâches de scraping.
- Plan de démarrage : 49 $ par mois, 500 000 crédits API, conçu pour les petites équipes et les besoins croissants en matière d’automatisation.
- Business Plan: 249 $ par mois, 3 000 000 de crédits API, conçu pour des flux de travail de scraping plus importants.
- Business Pro Plan : 599 $ par mois, 8 000 000 de crédits API, volume plus élevé avec support prioritaire
- Plan personnalisé : Tarification personnalisée à partir de 699 $ par mois, 10M plus crédits API pour les entreprises.
| Pros | Cons |
| API REST simple et facile à intégrer | Outils d’entreprise avancés limités |
| Rendu JS intégré, rotation de proxy et gestion CAPTCHA | Petit écosystème comparé à Apify ou Zyte |
| Bonne documentation et configuration axée sur les développeurs | Moins de flexibilité par rapport aux outils d’automatisation du navigateur complet |
7. BrightData : Plate-forme de scraping au niveau de l’entreprise

BrightData est l’un des fournisseurs de proxy les plus connus et les plus anciens du marché. Il propose deux façons de récupérer des données : Un navigateur de scraping et une API de scraping. Un navigateur de scraping fonctionne comme Gologin et vous fournit une infrastructure en nuage pour vos scripts Selenium et Puppeteer. Cependant, leur API de scraping Web est puissante.
Ce que j’aime :
Ce que j’aime dans l’API de scraping Web de BrightData, c’est qu’elle propose à la fois la clé API et une version sans code du même scraper. Ainsi, si vous n’êtes pas à l’aise avec la gestion de la clé API et les scripts de scraping, vous pouvez utiliser leur scraper » plug-and-play » basé sur le panneau de contrôle qui rassemble les résultats et les fournit directement dans votre tableau de bord, prêts à être téléchargés.
Tarification
- Modèle de paiement au fur et à mesure : 1,5 $/1 000 résultats
- 510k Records : 499 $/mois à 0,98 $/1k records
- 1M d’enregistrements : 999 $/mois à 0,83 $/1k de résultats
- 2,5 millions d’enregistrements : 999 $/mois à 0,75 $/1k enregistrements
| Pros | Cons |
| Une infrastructure de proxy à la pointe de l’industrie | Cher par rapport à la plupart des concurrents |
| Taux de réussite très élevé sur les cibles difficiles | Configuration complexe pour les débutants |
| Ecosystème de scraping tout-en-un | La tarification peut évoluer rapidement pour les gros volumes |
8. ScrapingBee : API simple pour les développeurs

L’API de ScrapingBee est puissante, efficace et simple. Comme Floppydata, ScrapingBee fournit également des proxies rotatifs pour des centaines de sessions de navigation sans tête. Son API rend les formats JavaScript, HTML et CSS, et peut les convertir en fichiers JSON ou markdown.
Le web scraping présente deux défis majeurs. Le premier consiste à analyser la structure HTML de l’URL cible pour déterminer ce que vous devez extraire des données brutes et le second à convertir ces données en vrac dans un format exploitable et compréhensible.
Ce que j’aime vraiment chez ScrapingBee, c’est que vous pouvez connecter leur API à votre automatisation n8n ou Zapier, ce qui ouvre une autre dimension de possibilités avec le scraping et les données scrappées.
Prix :
La tarification de ScrapingBee n’est pas transparente. Il ne facture pas le résultat du scraping. Vous êtes facturé sur la base du nombre de crédits consommés pour le rendu JS et les proxies. Il n’y a donc aucun moyen de deviner combien de temps dureront vos crédits.
- Freelance: 49 $/mois, 250 000 crédits API
- Démarrage: 99 $/mois, 1 000 000 de crédits API
- Entreprises: 249 $/mois, 3 000 000 de crédits API
- Business+: 599 $/mois, 8 000 000 de crédits API
| Pros | Cons |
| API très facile à utiliser | Extensibilité limitée pour les entreprises |
| Une bonne documentation et une bonne prise en main | Le système de crédit peut être confus |
| Rotation du proxy et rendu JS intégrés | Moins de contrôle sur la logique de scraping avancée |
9. ScraperAPI : API de scraping conviviale pour les débutants

ScraperAPI est une autre API dans cette longue liste. Comme beaucoup d’autres options, ScraperAPI fournit également des modèles de scraping qu’elle appelle « points de terminaison structurés » pour des sites web célèbres. Si vous souhaitez scraper Reddit, vous pouvez utiliser leur point final pré-structuré au lieu d’écrire tout le script vous-même.
Comme Floppydata, ScraperAPI propose également la résolution des CAPTCHA et la rotation automatique des proxys. Vous n’avez pas besoin de configurer des proxys supplémentaires. Vous pouvez envoyer des milliers de requêtes asynchrones et il les traite par le biais d’une navigation en nuage sans tête.
Prix :
Contrairement à Floppydata qui ne vous facture que les extractions réussies, ScraperAPI vous facture chaque requête API effectuée.
- Hobby : 49 $/mois, 100 000 appels API, 20 threads simultanés
- Démarrage: 149 $/mois, 1 000 000 d’appels API, 50 threads simultanés
- Business: 299 $/mois, 3 000 000 d’appels API, 100 threads simultanés
- Évolution: 475 $/mois, 5 000 000 d’appels API, 200 threads simultanés
| Pros | Cons |
| Très convivial pour les débutants | Personnalisation limitée par rapport aux outils avancés |
| Aucune configuration de proxy n’est nécessaire | Les coûts augmentent avec un scraping lourd en JS |
| Intégration facile grâce à une API simple | Moins efficace pour les flux de travail complexes |
10. Oxylabs : Infrastructure de qualité supérieure pour les équipes d’entreprise

Oxylabs est un autre fournisseur d’API de scraping de niveau entreprise comme BrightData. En tant que fournisseur de proxy premium avec un pool de dizaines de millions de proxys dans plus de 195 pays, l’API de scraper web d’Oxylabs gère la gestion des cookies, la rotation des proxy, les CAPTCHA, les systèmes anti-bots et réajuste même l’analyseur pour s’adapter à la structure de la page HTML si elle change.
Oxylabs propose également une vaste bibliothèque de points de terminaison structurés pour tous les sites web célèbres. Leur bibliothèque de points de terminaison structurés est plus importante et plus abordable que celle de ScraperAPI. Oxylabs est un excellent choix pour les équipes de freelance et les logiciels d’entreprise qui utilisent des capacités de scraping grâce à une documentation d’installation détaillée et un excellent support client.
Prix :
- Essai gratuit: 2000 résultats
- Micro: 49$/mois à 0,50$/1k de résultats
- Démarrage: 99 $/mois à 0,45 $/1k de résultats
- Avancé: 249 $/mois à 0,40 $/1k de résultats
Derniers points à retenir
Si vous souhaitez créer des flux d’automatisation complexes, vous devriez choisir un service basé sur une API comme Floppydata, Gologin ou Zyte. Apify est parfait si le coût n’est pas un problème pour vous, mais dans le cas du scraping de données, les coûts s’accumulent plus vite que vous ne pouvez réagir puisque des milliers de liens peuvent être scrappés en l’espace d’une heure. Si vous optez pour des proxys rotatifs, les coûts augmentent encore plus.
Je recommande vivement Floppydata ou Gologin parce que vous pouvez facilement prévoir le coût, qu’ils gèrent la gestion du proxy et l’auto-rotation pour vous et qu’il n’est pas nécessaire d’installer des proxys supplémentaires.





