

eBay cuenta con una mina de oro de datos públicos sobre precios. Millones de anuncios activos de artículos de colección, electrónica, piezas descatalogadas… lo que se te ocurra: todos ellos útiles para el seguimiento de precios, la investigación de mercado o el análisis de la competencia. El problema es acceder a esos datos de forma fiable. Con un sencillo script de Python quizá consigas ver unas cuantas páginas antes de que eBay empiece a lanzarte CAPTCHAs.
Así que, en esta guía, te explicaré paso a paso cómo extraer datos de eBay correctamente utilizando Web Unlocker de Floppydata y conseguir resultados reales.
Cómo extraer datos de los anuncios de eBay sin perder tiempo con los CAPTCHA y los selectores que no funcionan
• eBay bloquea rápidamente los rastreadores básicos: CAPTCHAs, límites de velocidad, detección de bots… todo eso. Una simple solicitud en Python no es suficiente.
• La opción más sencilla es el Web Unlocker de Floppydata: se encarga de la capa antibots y te devuelve un código HTML limpio.
• A partir de ahí, solo necesitas Python y BeautifulSoup para extraer los datos de los anuncios con el fin de realizar un seguimiento de los precios, investigar y analizar.
• La mayoría de los tutoriales sobre scraping que hay por ahí ya no funcionan: eBay cambió de li.s-item a li.s-card y muchos selectores nunca se actualizaron.
• Las nuevas cuentas de Floppydata disponen de cinco extracciones gratuitas, por lo que puedes seguir esta guía sin tener que gastar nada por adelantado.
Entonces, ¿en qué consiste realmente el «scraping» en eBay?
La verdad es que es bastante sencillo. Solo tienes que extraer los datos de los anuncios disponibles públicamente de las páginas de eBay y convertirlos en un formato con el que puedas trabajar: un archivo CSV, un archivo JSON o lo que sea. En lugar de ir haciendo clic en los anuncios uno por uno, un rastreador recoge toda esa información de forma masiva.
Hay dos tipos de página que conviene conocer antes de entrar en el código propiamente dicho:
- Páginas de resultados de búsqueda: vista resumida con título, precio, estado, gastos de envío y un enlace al anuncio.
- Las páginas de detalles de los artículos, es decir, las URL del tipo
/itm/ITEM_ID, donde se encuentra la información más detallada, como las descripciones completas, las valoraciones de los vendedores, las características específicas de los artículos y las opciones de variantes.
En este tutorial nos centraremos en las páginas de resultados de búsqueda, ya que es por ahí por donde empieza la mayoría de la gente.
¿Por qué extraer datos de eBay?
Así que, una vez que tengas estos datos, la verdad es que hay un montón de cosas que puedes hacer con ellos. Las que yo utilizo son:
- Seguimiento de precios. Puedes ver de un solo vistazo a qué precio se están vendiendo realmente las cosas en miles de anuncios activos y vendidos, y los que están vendidos son el oro, porque ese es el precio que la gente ha pagado de verdad, no una cifra idealista que el vendedor ha puesto con la esperanza de que se vendiera.
- Análisis de la competencia. Puedes ver exactamente qué se está vendiendo, en qué estado se encuentra el artículo, quién lo está vendiendo y cuánto pide por él, así que, en lugar de tener que adivinar a qué precio ponerlo, simplemente lo sabes.
- Reventa y arbitraje. Esta es la parte que te permite pagar las facturas, porque ahora mismo hay propiedades a la venta a precios muy bajos, y los datos te permiten encontrarlas y hacerte con ellas antes incluso de que otra persona se dé cuenta de su existencia.
- Investigación de productos. Antes de invertir dinero real en abastecer una categoría, puedes analizar las cifras y determinar en un par de minutos si existe una demanda real o si simplemente estarías invirtiendo dinero en productos que nunca se venden.
- Seguimiento de los vendedores. Y cuando quieras echar un vistazo a un vendedor concreto, el procedimiento es exactamente el mismo: solo tienes que introducir la URL de su tienda en lugar de realizar una búsqueda y, de repente, tendrás todo su catálogo y sus precios justo delante de ti.
Si tu trabajo tiene que ver, aunque sea de forma indirecta, con la reventa, el comercio electrónico o la fijación de precios, este tipo de datos te ahorra una cantidad increíble de tiempo y te ayuda a tomar decisiones más acertadas con mucha mayor rapidez.
¿Por qué no utilizar simplemente la API oficial?
La verdad es que no es una mala opción para cosas sencillas. La API de Browse gestiona bastante bien las consultas de volumen moderado sobre anuncios activos. Pero hay que pasar primero por un proceso de aprobación, tiene límites de frecuencia que se activan bastante rápido y, sencillamente, no te ofrece todo lo que necesitas.
No aparecen los anuncios vendidos, no aparecen las reseñas, ni tampoco los datos completos de las variantes tal y como se muestran en la página real. Así que, cuando necesitas tener una visión completa, es decir, el tipo de datos que ve un usuario real al cargar la página, el scraping es, sencillamente, la opción más práctica.
Si eres nuevo en este ámbito, Floppydata ofrece una buena introducción sobre cómo funciona realmente un «web unlocker».
¿Por qué resulta tan difícil extraer datos de eBay?
No es imposible, pero sin duda hay factores que juegan en tu contra. Hay dos cosas concretas con las que se encuentra la mayoría de la gente.
Una de ellas es la detección de bots. eBay utiliza CAPTCHAs y limitación de frecuencia, y una IP de baja confianza te dará errores 403 muy rápidamente. Además, a principios de 2026 endurecieron las medidas, así que sé responsable: utiliza solo datos públicos, mantén una frecuencia de solicitudes normal y no realices ninguna acción relacionada con pedidos ni nada por el estilo. Necesitas direcciones IP residenciales y un comportamiento que se parezca realmente al de un navegador; de lo contrario, no obtendrás respuestas correctas.
El segundo es el margen de beneficio, y este es un poco engañoso. Mientras preparaba esto, me di cuenta de que eBay ya se había trasladado de li.s-item a li.s-card, junto con todo el contenido de .s-card__title, .s-card__price y .s-card__subtitle que había en él. La mayoría de las guías en línea siguen apuntando a la estructura antigua, por lo que ahora ya no funcionan. Tus selectores quedarán obsoletos en algún momento; así es como funciona eBay, así que incorpora desde el principio algunas comprobaciones preventivas para detectar campos que falten.
En fin, por eso lo gestiono todo a través del Web Unlocker de Floppydata en lugar de lidiar directamente con eBay.
Requisitos previos
Tres cosas:
- Python 3.10 o superior
- Una cuenta de Floppydata con una clave API de Web Unlocker. Cada nueva cuenta incluye cinco extracciones gratuitas, por lo que podrás seguir toda esta guía sin tener que pagar nada. La clave se encuentra en el panel de control de Web Unlocker.
- Dos bibliotecas:
requestsybeautifulsoup4
Instala primero las dos bibliotecas:
pip install requests beautifulsoup4
A continuación, la carpeta de tu proyecto:
mkdir ebay-scraper
cd ebay-scraper
touch ebay_scraper.py
Envío de la primera solicitud
Lo primero que probé fue una solicitud básica para ver qué pasaba:
import requests
url = "https://www.ebay.com/sch/i.html?_nkw=mechanical+keyboard"
response = requests.get(url)
print(response.status_code)
print(response.text[:500])
Bloquear página. No son anuncios, simplemente no hay nada útil. eBay detecta al instante una solicitud sencilla en Python: sin huella digital, sin IP de confianza… simplemente no va a funcionar. Así que, en lugar de perder el tiempo con eso, utilizo el Web Unlocker.
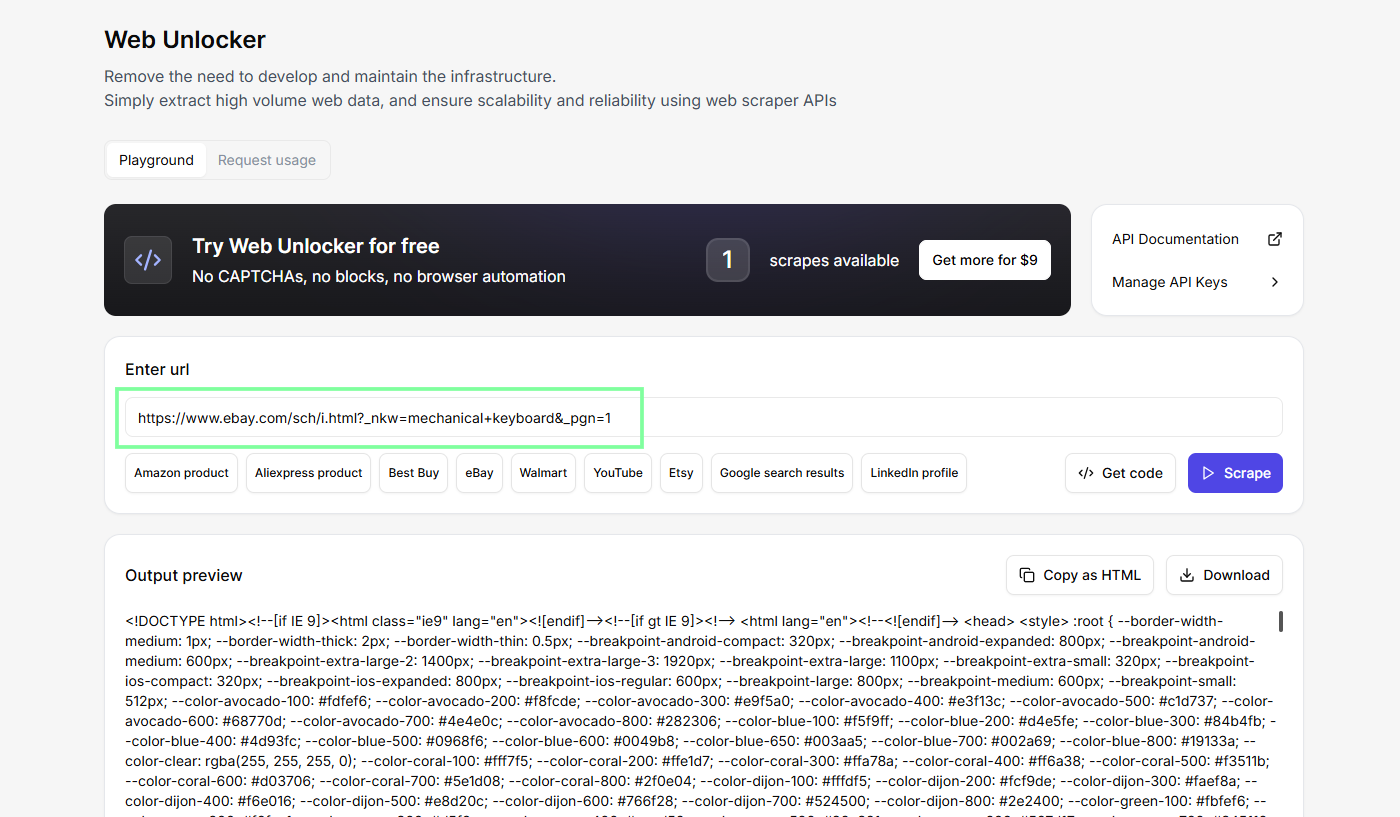
Extracción de datos de eBay con Floppydata Web Unlocker
Se encarga de todo lo molesto: la IP residencial, la huella digital del navegador y la visualización de la página, y te devuelve un código HTML limpio. Además, solo cobra por los rastreos que se realizan con éxito, así que no pierdes créditos en los que fallan.
Siempre hago pruebas en el entorno de pruebas del panel de control (entorno de pruebas de Web Unlocker sin código) antes de escribir nada. Pega la URL de búsqueda, pulsa «Scrape» y fíjate en los resultados. Es mucho más fácil crear un analizador sintáctico cuando ya sabes con qué estás trabajando.
Ya tenemos el código HTML, así que pasemos a programar.
Paso 1: Preparar la solicitud
import requests
import json
from bs4 import BeautifulSoup
API_URL = "https://api.floppydata.net/v1/webUnlocker"
API_KEY = "YOUR_API_KEY"
SEARCH_URL = "https://www.ebay.com/sch/i.html?_nkw=mechanical+keyboard&_pgn=1"
OUTPUT_FILE = "ebay_listings.json"
Sustituye YOUR_API_KEY por la clave que aparece en tu panel de control.
Además, _pgn=1 es simplemente el número de página. Si quieres la segunda página, cámbialo por _pgn=2. La tercera página, _pgn=3. Así de sencillo.
Paso 2: Obtener la página a través de Web Unlocker
def fetch_html(url):
response = requests.post(
API_URL,
headers={
"Content-Type": "application/json",
"X-Api-Key": API_KEY,
},
json={
"url": url,
"country": "US",
"city": "New York",
"difficulty": "medium",
"expiration": 0,
},
timeout=120,
)
response.raise_for_status()
data = response.json()
html = data.get("html")
if not html:
raise ValueError("Unlocker response did not include an 'html' field.")
return html
El país y la ciudad garantizan que la solicitud se redirija a través de una IP residencial de EE. UU., lo que afecta tanto a los precios como a los anuncios que realmente aparecen. La dificultad medium es la configuración adecuada para eBay específicamente, ya que cuenta con una protección antibots muy estricta. Si se establece un valor inferior, simplemente te bloquearán. La caducidad 0 obliga a cargar una página nueva cada vez, en lugar de recuperar una respuesta almacenada en caché. El código HTML generado aparece en el campo html del JSON, y eso es lo que BeautifulSoup analiza en el siguiente paso. Si quieres ver todos los parámetros disponibles, la referencia de la API de Web Unlocker los recoge todos.
Paso 3: Extraer los listados
Cada resultado de la página de búsqueda es un li.s-card contenedor. Para extraer los anuncios de eBay de forma limpia, recorremos todas las tarjetas y extraemos los campos que nos interesan, utilizando comprobaciones preventivas para que la ausencia de un campo nunca provoque un error en la ejecución:
def extract_listings(html):
soup = BeautifulSoup(html, "html.parser")
cards = soup.select("li.s-card")
listings = []
for card in cards:
title_el = card.select_one(".s-card__title")
title = title_el.get_text(" ", strip=True) if title_el else None
if title:
# eBay appends this as accessibility text
title = title.replace("Opens in a new window or tab", "").strip()
# Skip the placeholder card at the top of search results
if not title or title == "Shop on eBay":
continue
price_el = card.select_one(".s-card__price")
condition_el = card.select_one(".s-card__subtitle")
# Shipping info sits inside attribute rows
shipping = None
for row in card.select(".s-card__attribute-row"):
text = row.get_text(" ", strip=True)
if any(word in text.lower() for word in ("ship", "free", "delivery")):
shipping = text
break
# Grab the first link that points to an item detail page
url = None
for a in card.select("a.s-card__link"):
href = a.get("href")
if href and "/itm/" in href:
url = href.split("?")[0]
break
listings.append({
"title": title,
"price": price_el.get_text(" ", strip=True) if price_el else None,
"condition": condition_el.get_text(" ", strip=True) if condition_el else None,
"shipping": shipping,
"url": url,
})
return listings
Hay dos aspectos que conviene tener en cuenta.
- eBay siempre coloca una tarjeta de marcador de posición de «Shop on eBay» en la parte superior de los resultados de búsqueda. Si no la omites, el primer elemento de la lista de resultados no es más que basura inservible.
- El título también extrae «Se abre en una nueva ventana o pestaña» como texto de accesibilidad de la etiqueta de enlace, de modo que la línea de sustitución lo depura antes de que se añada nada.
Paso 4: Guardar los resultados
def main():
print(f"Fetching data from: {SEARCH_URL}")
html = fetch_html(SEARCH_URL)
listings = extract_listings(html)
if not listings:
raise SystemExit("No listings found. eBay may have changed its markup.")
with open(OUTPUT_FILE, "w", encoding="utf-8") as file:
json.dump(listings, file, indent=2)
print(f"Found {len(listings)} listings")
print(f"Saved results to {OUTPUT_FILE}")
if __name__ == "__main__":
main()
Ejecuta el script:
python ebay_scraper.py
Y deberías ver algo así como:
[
{
"title": "MSI Forge GK600 TKL Wireless Mechanical Keyboard RGB Bluetooth 2.4GHz",
"price": "$49.99",
"condition": "Brand New",
"shipping": "Free shipping",
"url": "https://www.ebay.com/itm/227344950627"
}
]
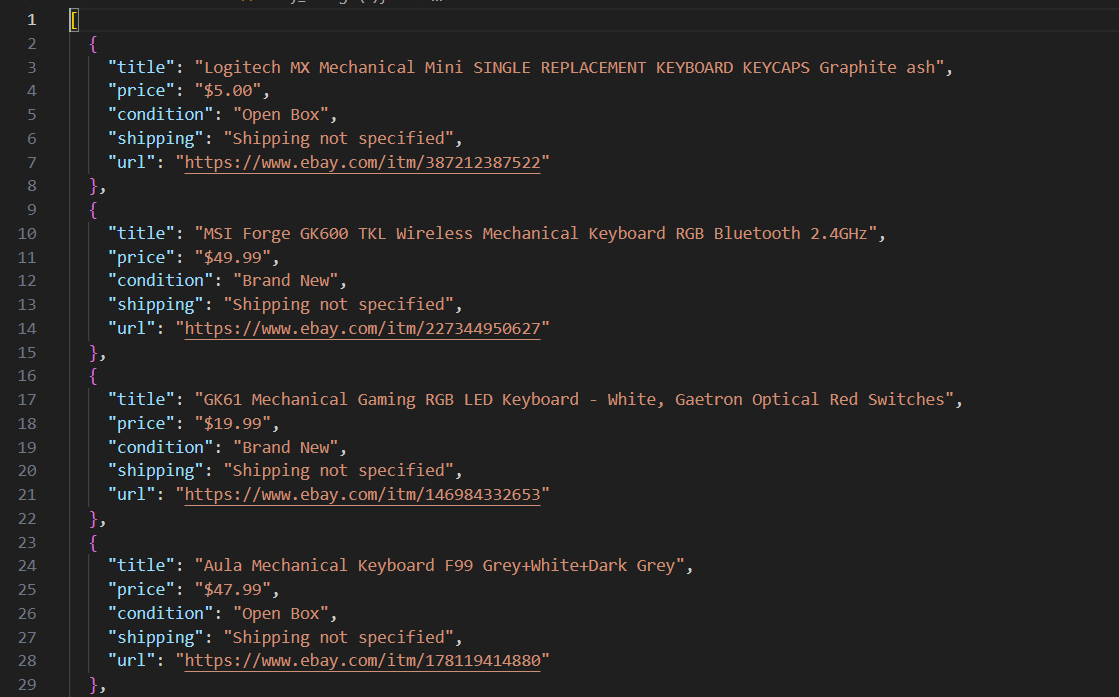
Así es como funciona el raspador básico.
A partir de aquí, para cambiar la palabra clave basta con modificar _nkw=mechanical+keyboard en la URL. Si quieres otra página, puedes pasar de _pgn=1 a _pgn=2, _pgn=3, y así sucesivamente.
Solución de problemas
Así que está claro: si sigues buscando en eBay el tiempo suficiente, es probable que te topes con algo así:
- Errores 403: eBay ha marcado tu dirección IP. La solución es conectarte a través de Web Unlocker con direcciones IP residenciales.
- Respuestas vacías: suele tratarse de un problema de visualización. Comprueba que estás leyendo el campo «
html» de la respuesta de Web Unlocker, y no el cuerpo JSON sin procesar. - Campos que faltan: no todos los anuncios incluyen información sobre el estado del artículo o los gastos de envío. Los controles de seguridad de
extract_listingsya se encargan de ello. - No hay ningún resultado: eBay ha vuelto a cambiar los nombres de las clases CSS. Vuelve al «playground», revisa el nuevo código y actualiza tus selectores.
Tu próximo paso
Mira, eBay no es precisamente la página más complicada de manejar, pero entre los CAPTCHAs, los límites de solicitudes y el hecho de que el margen de beneficio a veces cambia sin previo aviso, hacerlo sin la configuración adecuada solo te hará perder el tiempo. Utilizar un servicio que se encargue de todo eso te permite pasar directamente a trabajar con los datos.
En eso es en lo que destaca el Web Unlocker de Floppydata. Rotación de proxies residenciales, huellas digitales reales de navegadores, renderización de páginas completas, y solo pagas por las respuestas correctas, por lo que los intentos fallidos de extracción de datos no te cuestan nada. Si le añades unas cuantas líneas de BeautifulSoup, la verdad es que todo resulta bastante sencillo.
Con cada cuenta nueva se incluyen cinco rasca y gana gratis, para que puedas seguir toda esta guía sin tener que pagar nada.





