

Ejecutar automatizaciones de web scraping en 2026 no es fácil. Dado que muchas empresas de IA están tratando de raspar tantos datos de Internet como sea posible para el entrenamiento de modelos, plataformas como Reddit, Meta, X y otras despliegan sistemas de detección basados en IA para bloquear a los raspadores web y evitar que pongan sus manos en los datos públicos de los usuarios. Esta guía explora cómo escalar y automatizar el web scraping en 2026.
¿Por qué el Web Scraping es cada vez más difícil?

He aquí algunas razones por las que las empresas detectan y bloquean activamente las automatizaciones de web scraping.
- Los raspadores web sobrecargan innecesariamente los servidores, ya que envían cientos o incluso miles de solicitudes automáticas simultáneas.
- A los anunciantes no les gustan los bots porque los anuncios se muestran a un bot que rastrea datos de una página y el gasto publicitario se desperdicia.
- La mayoría de las empresas prefieren vender sus datos a otras empresas de IA o entrenar sus propios modelos. Por eso no quieren que los rascadores extraigan datos de su plataforma de forma gratuita.
No obstante, en 2026 todavía existen algunos métodos eficaces de raspado de datos que no solo son seguros de usar, sino que son escalables, fáciles de automatizar y funcionan para todos los sitios web. Dado que los sistemas anti-bot se están volviendo más inteligentes con la IA, los raspadores web también se están poniendo al día proporcionando la resolución automática de CAPTCHA, aleatorizando los movimientos y clics del ratón, rotando IPs, aleatorizando las huellas dactilares del navegador y mucho más.
¿Cómo escalar el Web Scraping?
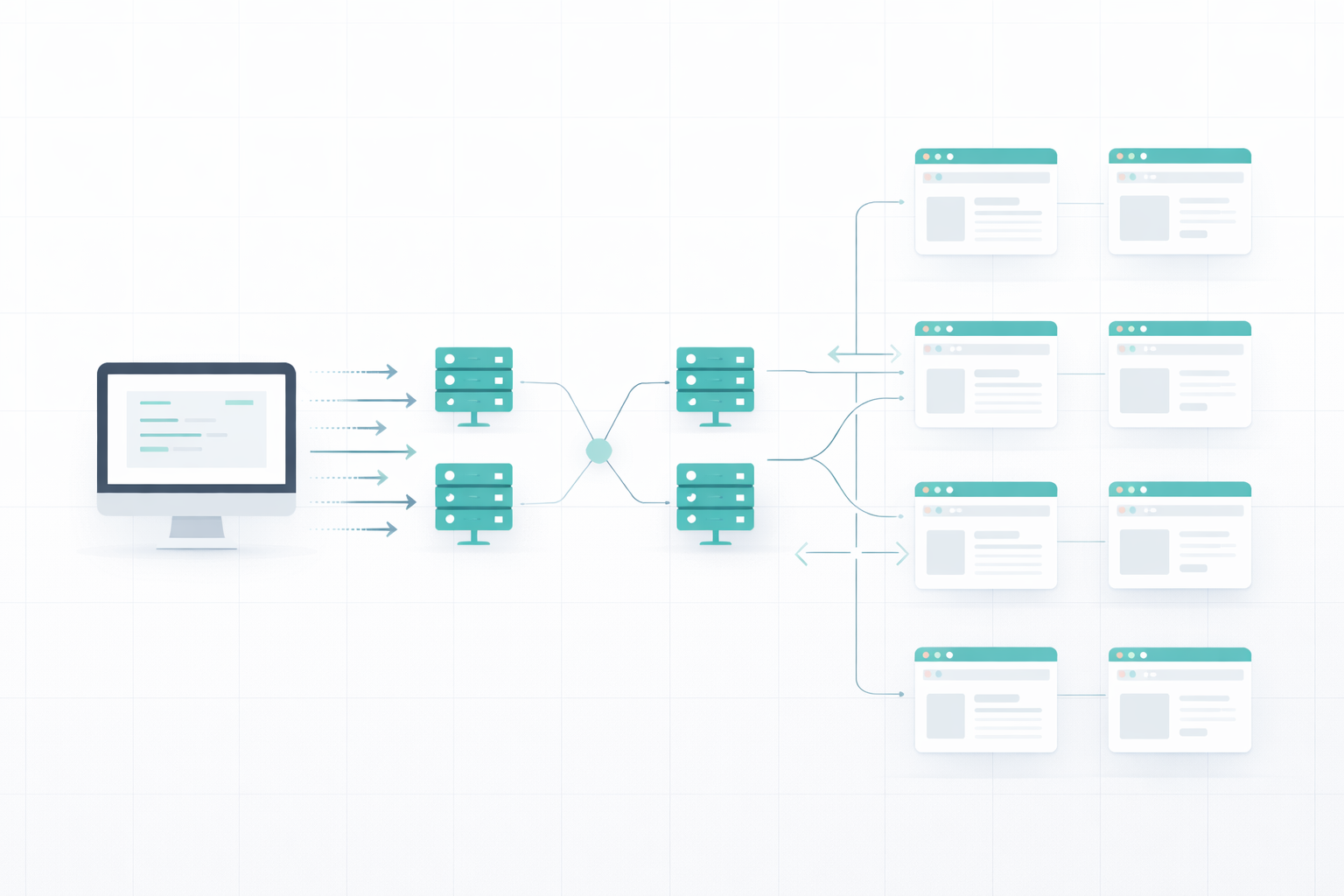
Raspar una o dos páginas web no es el problema, pero ¿cómo raspar miles de páginas web en unas pocas horas o días? No podemos abrir tantas pestañas en nuestro dispositivo debido a la limitación de RAM y velocidad de procesamiento, y si nuestra IP es baneada en los primeros minutos, tendremos que cambiar de dispositivo.
La ampliación del web scraping requiere comprensión y planificación. En primer lugar, conozcamos los retos del web scraping.
Desafíos del Web Scraping
Los sitios web ya no son sólo páginas HTML estáticas. Los sistemas anti-bot rastrean continuamente la actividad de los usuarios y la calidad del tráfico para garantizar que sólo los usuarios reales acceden a los sitios web y que los scrapers son bloqueados al instante. Estos son los retos a los que me enfrenté cuando empecé a hacer scraping:
- Limitación de la tasa de IP: Las plataformas hacen un seguimiento del número de peticiones por IP cada minuto y cada hora. Si una dirección IP intenta superar el límite, la cuenta se suspende o se inhabilita temporalmente por actividad de spam.
- Renderizado Javascript: Muchos sitios web ahora cargan el contenido dinámicamente. Cuando un scraper intenta obtener contenido HTML, obtiene campos que faltan porque algunas partes de la página no se cargaron.
- CAPTCHAs: Mis scripts de web scraping tenían dificultades para resolver los CAPTCHAs y seguían bloqueándome. Facebook incluso baneó mi IP y no pude volver a acceder a través de la misma IP.
- Detección de comportamiento: Los sitios web rastrean tu comportamiento como la actividad de desplazamiento, los movimientos del ratón, la aleatoriedad de los clics, etc. para ver si eres un bot o una persona real.
- Seguimiento de huellas dactilares: Las plataformas guardan y rastrean la huella digital de su navegador para identificar qué dispositivos están utilizando esta cuenta. Si se descubre que infringe los términos y servicios, pueden prohibir la huella dactilar e impedir que su navegador pueda acceder a la plataforma.
- Gestión de cookies: Probé a usar proxies y múltiples perfiles de navegador pero seguía encontrándome con problemas de contaminación cruzada de cookies. Como todos los perfiles guardan las cookies de mis sesiones de inicio de sesión, las plataformas pudieron identificar que tengo otras cuentas iniciadas desde el mismo dispositivo y que estoy realizando web scraping.
Creación de una estrategia de raspado web escalable
Existen algunos servicios de web scraping excelentes que le ayudan a crear un sistema de web scraping escalable sin preocuparse por todos los problemas descritos anteriormente. Estas herramientas de web scraping utilizan un conjunto de proxies y huellas de navegador aleatorias, ejecutan todas las sesiones de scraping en la nube para evitar sobrecargar su máquina, resuelven automáticamente los CAPTCHA, aíslan las cookies y gestionan la renderización de Javascript.
Los servicios de raspado web como Floppydata resuelven el problema de la escalabilidad:
- Ejecución de sesiones de navegador paralelas en la nube
- Utilizando IPs rotativas de su pool de 90 millones de proxies
- Gestión automática de CAPTCHAs y renderización JS
- Ampliación bajo demanda sin necesidad de infraestructura adicional
¿Cómo automatizar el Web Scraping?
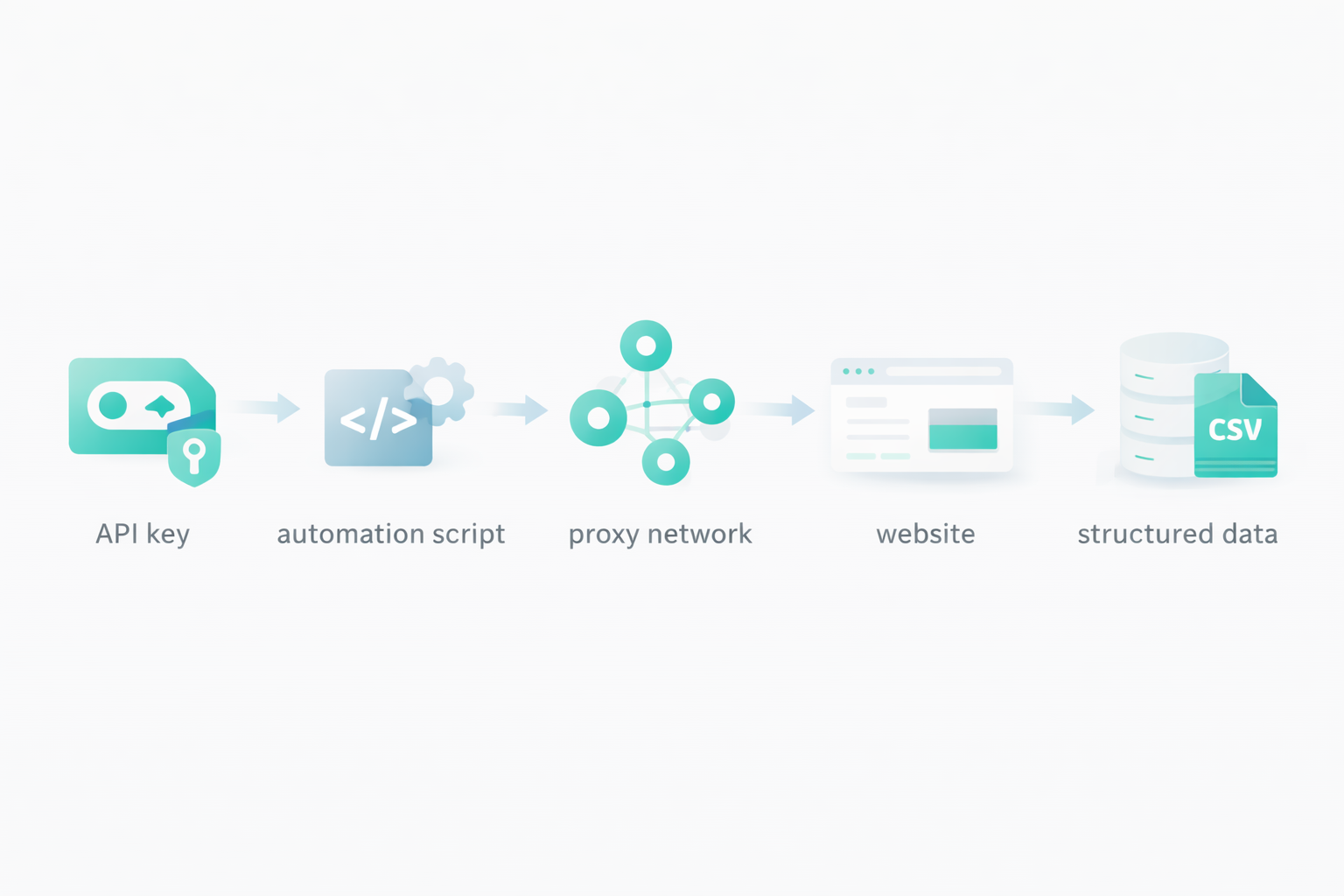
Cuando se dispone de una infraestructura escalable, es necesario crear un sistema automatizado para gestionar los proxies, las extracciones, los enlaces, el formato de los datos, etc. Aunque los servicios de scraping le proporcionen una infraestructura escalable para gestionar miles de solicitudes por hora, no puede hacerlo manualmente. Aquí es donde entran en juego los scripts de automatización para el scraping.
Algunos servicios de web scraping ofrecen plantillas configuradas para plataformas famosas como Reddit, Meta, Instagram, X, etc. Puedes elegir una plantilla, configurarla para tu caso de uso y empezar a raspar.
Otro método para la automatización del web scraping, y uno de los más populares, son las claves API. Los servicios de web scraping como Floppydata ofrecen sus claves API que le ayudan a enviar solicitudes de web scraping a su servidor en la nube y recibir a cambio el contenido extraído. Cuando se utiliza una API, las posibilidades son infinitas. Usted define su propio formato de extracción de datos, sus reglas de rotación de proxy, qué páginas extraer, qué campos extraer, cómo almacenarlos, cuánto retraso añadir entre cada solicitud, cuántas solicitudes simultáneas enviar, y mucho más.
Puede utilizar esta clave API para crear herramientas de scraping o integrarla en el sistema de su empresa. Todo lo que necesitas es una clave API, y servicios como Floppydata se encargarán del resto y te traerán los resultados finales.
Guía paso a paso para el scraping web escalable y automatizado
Aquí tienes una guía paso a paso para crear una automatización de raspado web con la API de Floppydata.
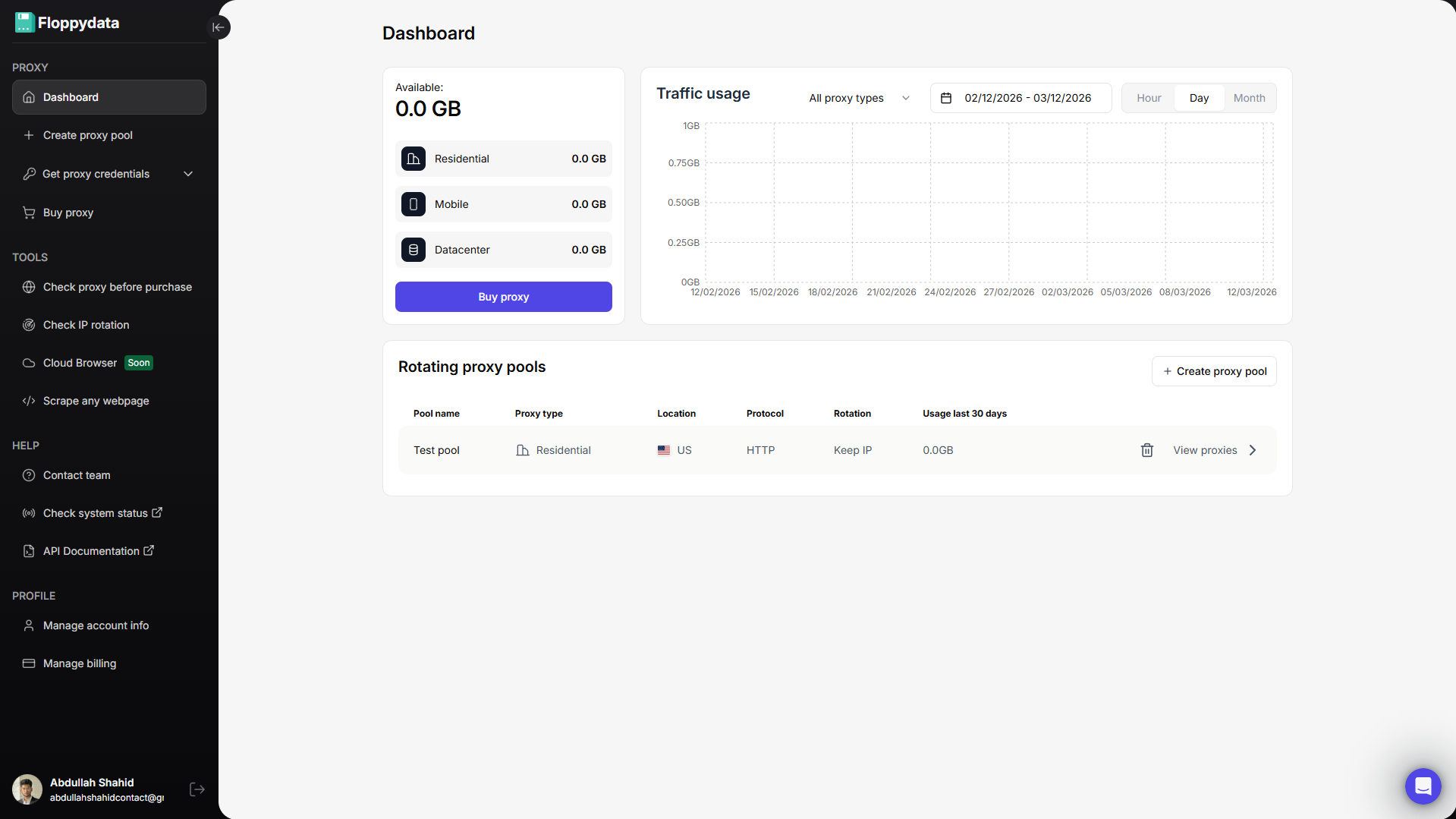
Paso nº 1: Crear una cuenta Floppydata
Regístrate en Floppydata y abre el panel de control. Aquí es donde puedes gestionar tus proxies y herramientas como el desbloqueador web.
Paso nº 2: Analizar la URL de destino
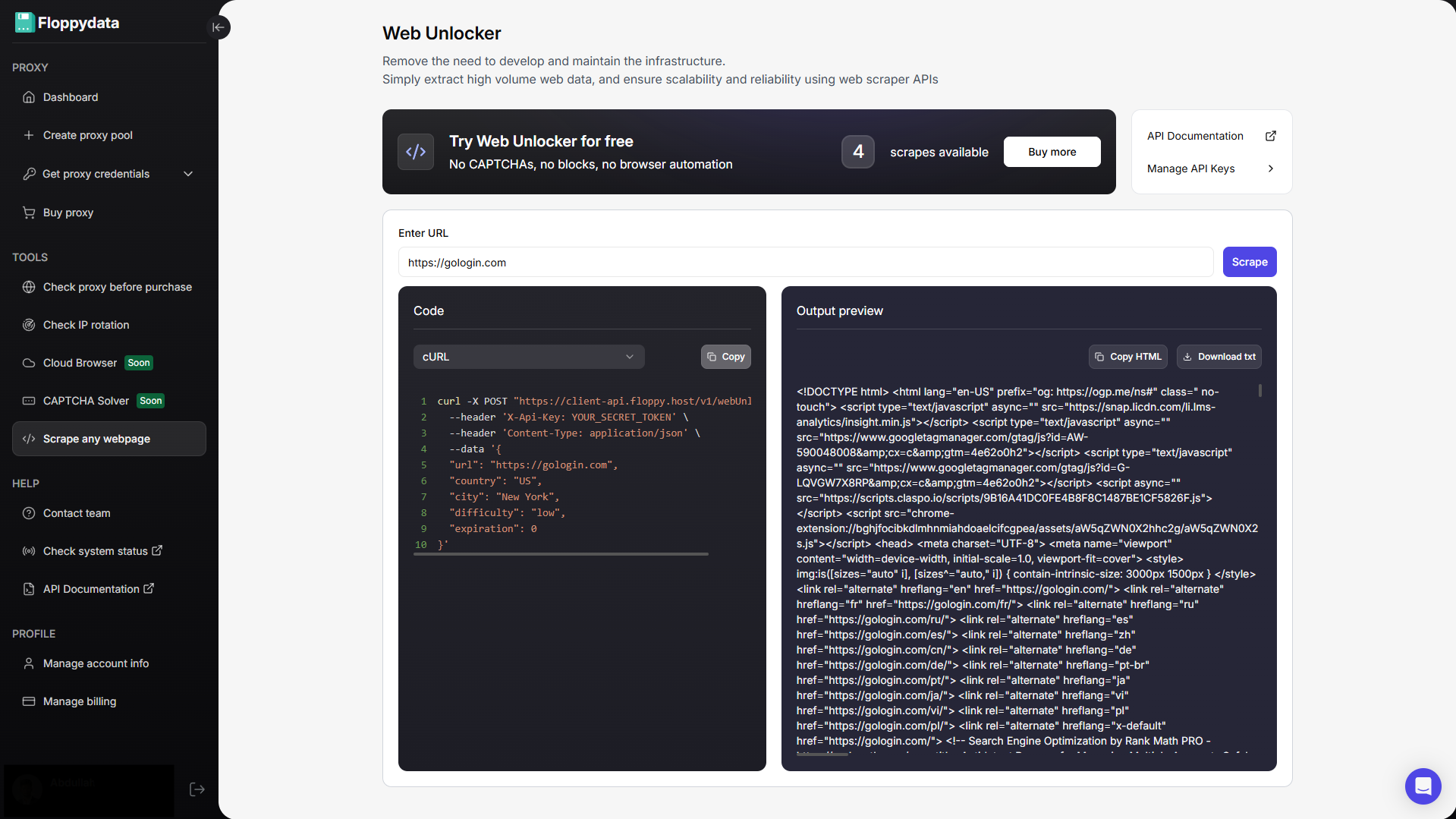
Pega tu URL en el campo mostrado y haz clic en scrape. Obtendrás el contenido HTML de esa página junto con un fragmento de código para añadir a la automatización de tu navegador. Si estás creando una automatización para obtener los precios de los productos de un sitio web, puedes utilizar esta función de análisis para identificar qué etiqueta HTML contiene los precios. Luego puedes escribir tu script de automatización para extraer específicamente las siguientes etiquetas y almacenarlas en tu archivo excel/csv.
Paso 3: Crear claves API para la automatización
Puedes crear claves API desde la configuración de tu cuenta. Estas claves API se utilizarán en su script de automatización del navegador para rotar proxies, desbloquear sitios web y raspar datos. Floppydata Web Unlocker raspa datos y los envía a su script a través de esta API.
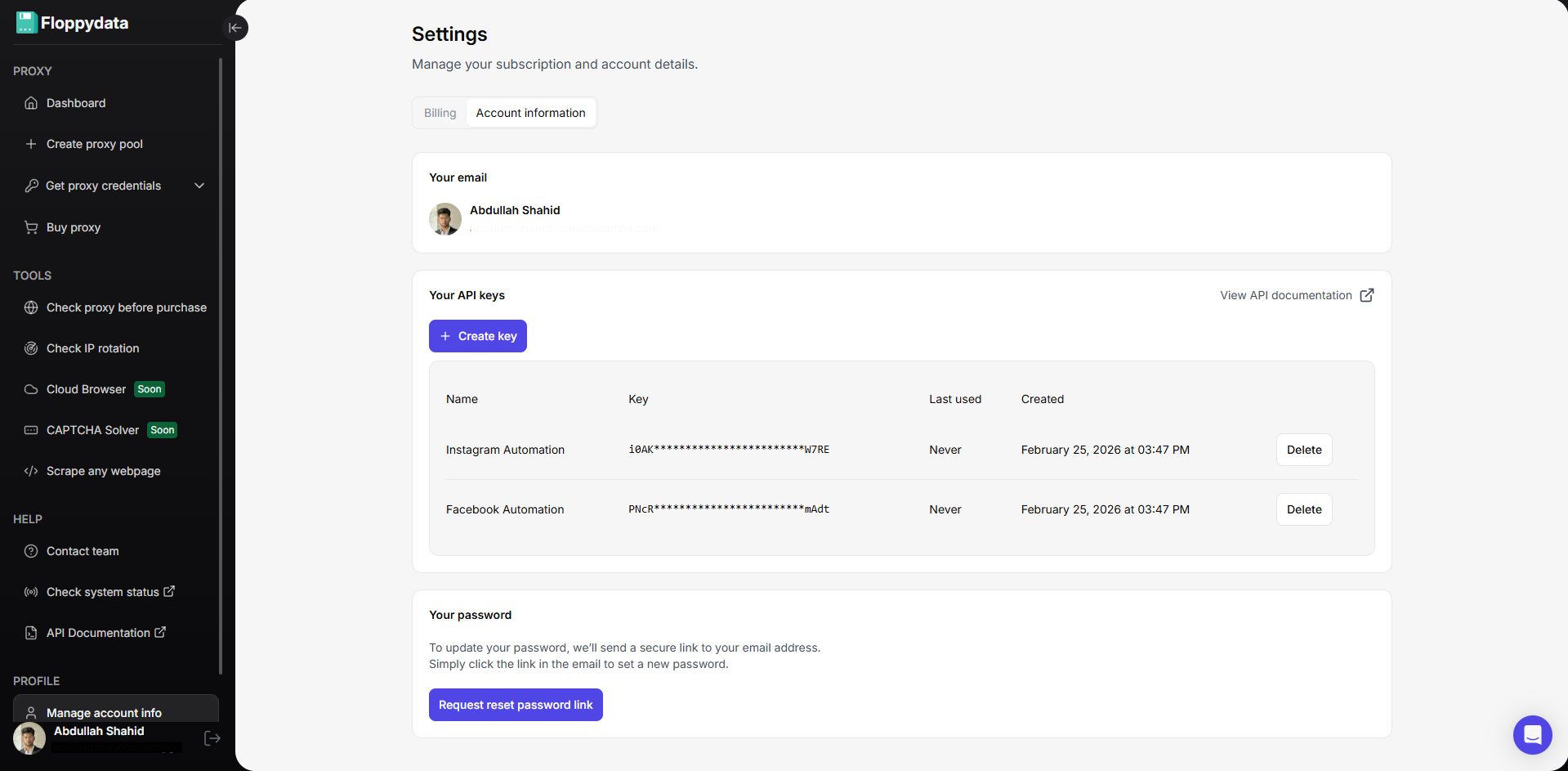
Paso 4: Escribir y ejecutar la automatización de Web Scraping
Ahora que tienes la clave API y los proxies, puedes crear un script de web scraping en Python, Javascript, C# o GO. Coloque su clave API en el fragmento de código que se muestra en la página del desbloqueador web junto con las URL. Aquí tienes un ejemplo rápido de un script en Python que puedo ejecutar en un intérprete de Python para extraer datos de un foro de discusión de Reddit:
httpx.post(
«https://client-api.floppy.host/v1/webUnlocker»,
headers={
«Content-Type»: «application/json»,
«X-Api-Key»: «YOUR_SECRET_TOKEN»
},
json={
«url»:
«https://www.reddit.com/r/automation/comments/1ntu327/top_5_antidetect_browsers_comparison_2025/»,
«country»: «US»,
«city»: «New York»,
«difficulty»: «baja»,
«caducidad»: 0
}
)
Puede cambiar el país, la ciudad y la URL para cambiar los enlaces proxy y de destino. Esto es sólo un fragmento de código ficticio. Puede crear automatizaciones complejas usando Claude Code o ChatGPT que explorarán dinámicamente toda su lista de URLs de destino, y extraer contenido útil en el formato de su elección.
Prácticas recomendadas y consejos para la automatización del Web Scraping
Al crear flujos de trabajo automatizados de web scraping, es importante priorizar la capacidad de recuperación y el rendimiento sobre la velocidad. Su flujo de trabajo debe tener una buena precisión. Si el 40% de sus solicitudes de raspado fallan, perderá el 40% de su presupuesto sin resultados que mostrar. Aunque Floppydata sólo le cobra por las extracciones de páginas realizadas con éxito, otros servicios cobran por cada 1.000 solicitudes, incluso si todas fallan.
Para crear una automatización que forme parte de su flujo de trabajo durante semanas o meses, debe asegurarse de algunas cosas clave:
- Rotación de IPs por trabajador o sesión
- Escalar el scraping con sesiones paralelas, no aumentando la velocidad o reduciendo los tiempos de espera.
- Utilice Web Unlockers para sitios con muchos bloques
- Prefiera las API cuando estén disponibles
- Aislar las huellas del navegador
- Registrar errores y reintentar de forma inteligente
- Probar a pequeña escala antes de ampliar
- Comprar proxies limpios a un proveedor de confianza
Usted no necesita preocuparse acerca de los proxies si está utilizando una herramienta de desbloqueo web de un proveedor de proxy como Floppydata, BrightData, Oxylabs, etc, ya que pueden incluir IPs limpias para su herramienta.
Principales conclusiones
Escalar y automatizar el web scraping todavía es posible en 2026 y puede ser muy efectivo si haces las cosas bien. Si sigues las estrategias que expliqué en este blog y priorizas la resiliencia sobre la velocidad, puedes crear una automatización repetible que durará meses antes de que necesites hacer cambios. Con una infraestructura adecuada, no necesitas preocuparte por ningún sistema anti-bot.





