


Зараз дані є важливим активом для багатьох організацій у різних секторах. Тим не менш, є багато організацій, які збирають дані швидше, ніж можуть їх обробити. Методи збору даних та маніпулювання ними впливають на рішення щодо бізнес-операцій.
Оскільки якість вхідних даних впливає на вихідні, необхідно забезпечити, щоб ваша система отримувала якісні дані. Саме тому вам потрібна хороша архітектура конвеєра надходження даних , щоб сприяти отриманню дієвих інсайтів.
У цьому посібнику ми розповімо про пайплайн збору даних, типи збору даних та поширені випадки використання.
Що таке збір даних?
Одне з найпоширеніших запитань, яке люди задають, намагаючись розібратися в конвеєрі прийому, – це “що таке збір даних?”
Термін “збір даних” описує процес збору, сортування та організації даних з різних джерел у центральному сховищі, такому як датахаб або сховище. Цей процес є першим кроком у підготовці “сирих даних” для подальшої обробки та інтерпретації. Отримання даних є дуже важливим етапом, оскільки саме на цьому етапі збираються дані з різних джерел, які впливатимуть на те, як бізнес отримає уявлення про продукт і конкурентні переваги.
Деякі з поширених джерел даних для пайплайну є наступними:
- Бази даних
- Інтернет речей
- Центри обробки даних
- Платформи соціальних мереж
- API
- Сторонні постачальники даних
- Додатки SaaS
Переваги поглинання даних
Кожен бізнес, незалежно від розміру, може отримати вигоду від поглинання даних, оскільки це дає розуміння ринкових тенденцій, споживчих настроїв, інноваційних стратегій та багато іншого. Ось деякі з найпоширеніших переваг аналізу даних:
Доступність даних
Однією з переваг поглинання даних є те, що воно усуває потребу в ізоляції даних. Це сприяє підвищенню доступності даних для аналізу завдяки об’єднанню даних з різних джерел в єдине центральне джерело.
Масштабованість
Зі зростанням бізнесу зростає і його потреба в якісних даних. Тому конвеєри надходження даних відіграють центральну роль в обробці великих обсягів даних, забезпечуючи при цьому їхню достовірність, точність і надійність.
Аналітика в реальному часі
Ще одна перевага конвеєра надходження даних полягає в тому, що дані обробляються миттєво або партіями, що забезпечує доступ до оновлених інсайтів. Як результат, бізнес може швидко реагувати на тенденції та приймати своєчасні рішення, які можуть вплинути на загальну норму прибутку.
Ефективність
Оскільки конвеєри надходження даних автоматизовані, це усуває необхідність ручної обробки даних. Це економить час і ресурси, спрощуючи процес імпорту та зберігання даних, а команда зосереджується на інших пріоритетних завданнях.
Типи збору даних
Збір даних з різних джерел до центрального сховища звучить досить просто. Однак це може бути трохи складніше, особливо для конвеєра даних. Нижче наведено найпоширеніші типи надходження даних:
Збір великих обсягів
Це процес, за допомогою якого збирається великий обсяг даних через певні проміжки часу. Ці інтервали можуть бути погодинними, щоденними або навіть щотижневими, залежно від ваших потреб у зборі даних. Тому пакетний збір даних підходить для використання тими компаніями, які не потребують даних у режимі реального часу для прийняття рішень.
Це ті підприємства, які можуть комфортно працювати і приймати рішення на основі періодичного оновлення даних.
Збір в режимі реального часу
Цей метод вимагає, щоб дані були отримані в той самий час, коли вони були створені. Таким чином, ця технологія дозволяє отримувати свіжі дані, які є дуже важливими для прийняття рішень. Поглинання в режимі реального часу допомагає зменшити затримку між отриманням і обробкою даних. Деякі з випадків використання даних в режимі реального часу – це виявлення шахрайства, обробка даних з датчиків та оновлення дашбордів в режимі реального часу. Конвеєр надходження даних в режимі реального часу може обробляти дані в режимі реального часу або фрагментами під час їх вилучення. Хоча цей метод забезпечує свіжі дані, обробка помилок і масштабованість є складним питанням.
Лямбда-архітектура
Лямбда-архітектура поєднує в собі пакетне поглинання і поглинання в реальному часі, щоб забезпечити баланс швидкості і точності. Пакетні дані надають вичерпні історичні тренди, тоді як дані в режимі реального часу дають уявлення про поточну діяльність.
Лямбда-підхід часто використовується в ситуаціях, які вимагають обробки величезних обсягів даних з високою точністю. Згодом це дозволяє бізнесу швидко реагувати на поточні події, не втрачаючи знання про попередні події на ринку.
Що таке пайплайн збору даних?
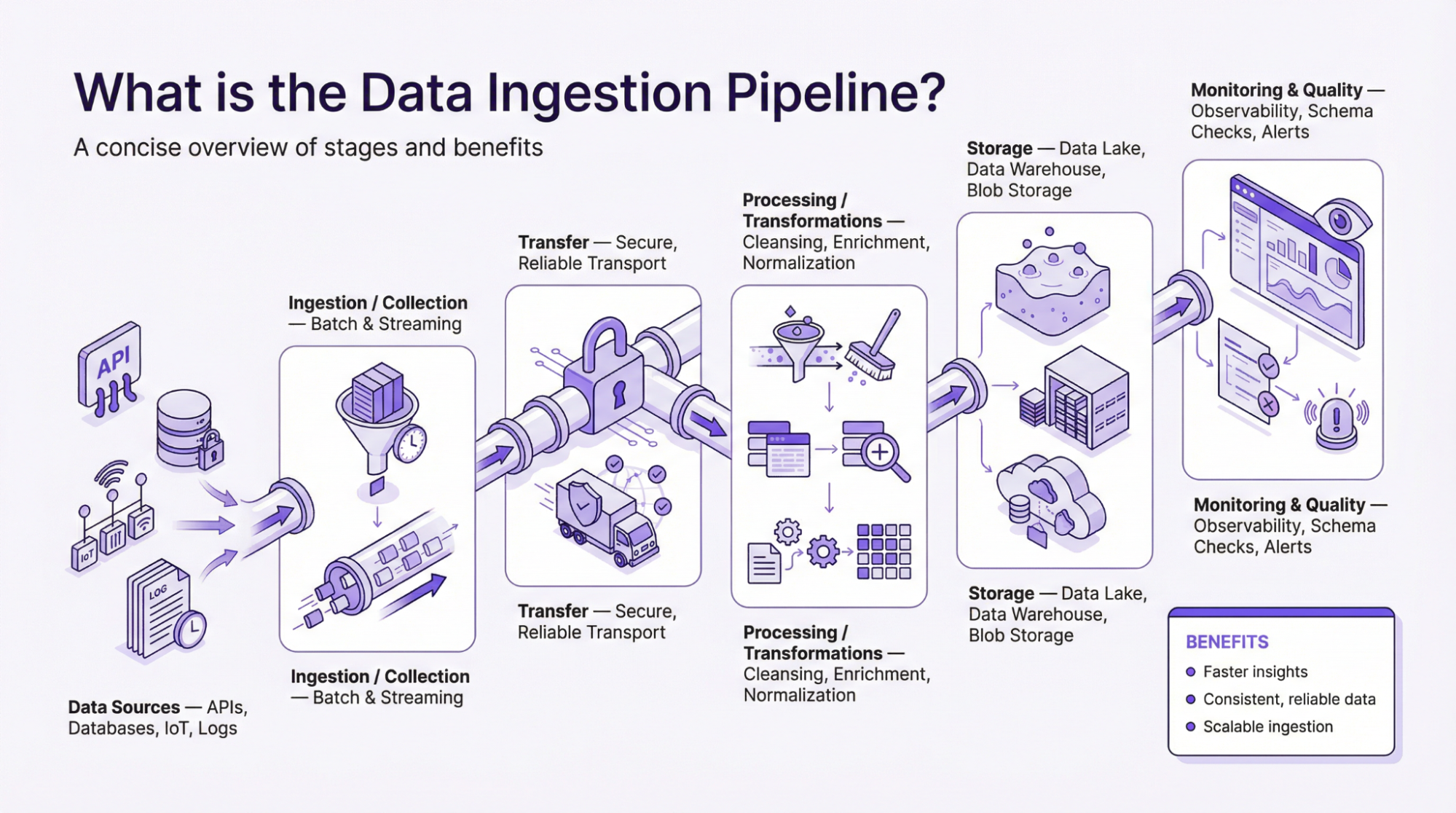
До головного питання“Що таке пайплайн надходження даних?” – Конвеєр, який часто називають структурою, описує потік даних від моменту збору до моменту їх обробки та застосування для прийняття рішень, що ґрунтуються на фактах. Конвеєр даних – це просто те, як інформація рухається від одного кінця до іншого. Це набір інструкцій, які збирають дані з різних джерел, обробляють їх і надсилають до місця призначення. Тому належний конвеєр надходження даних необхідний для того, щоб організації могли ефективно використовувати дані для зростання, прибутку та рентабельності інвестицій.
Кроки до побудови ефективного конвеєра обробки даних
Ось кілька ключових кроків до побудови ефективного конвеєра обробки даних:
- Визначте джерела даних: Першим кроком у створенні ефективного конвеєра обробки даних є визначення джерела даних. Перш ніж визначити джерела даних, ви повинні спочатку визначити тип даних, обсяг, швидкість та організаційні цілі. Вибір хороших і стабільних джерел даних відіграє важливу роль у точності та надійності результатів.
- Виберіть пункт Призначення даних: Далі вам потрібно визначити місце призначення даних. Це місце, де ви будете зберігати всі дані, які ви отримуєте з різних джерел. Система призначення може бути озером даних, сховищем або іншими типами сховищ на ваш розсуд.
- Виберіть метод збору даних: Існують різні типи методів збору даних. Тому вам потрібно вибрати той, який найкраще відповідає унікальним потребам вашого бізнесу. Залежно від ваших бізнес-цілей, ви можете обирати між пакетним, потоковим або комбінованим збором даних.
- Спроектуйте процес поглинання: Цей метод передбачає визначення того, як дані будуть збиратися, оброблятися і зберігатися в системі призначення. У сучасному цифровому світі процес збору даних автоматизовано, щоб підвищити ефективність і зменшити кількість помилок, пов’язаних з людським фактором. Ще однією причиною автоматизації процесу є узгодженість. Автоматизація потоку даних у трубопроводі гарантує, що дані рухаються відповідно до плану, щоб уникнути вузьких місць.
- Моніторинг та обслуговування: Після того, як процес збору даних впроваджено, вам потрібно відстежувати його ефективність. Це передбачає впровадження сповіщень про невдалі завдання. Регулярний моніторинг допомагає виявити проблеми та оперативно їх вирішити, щоб забезпечити стабільність доступності даних.
Архітектура пайплайну даних
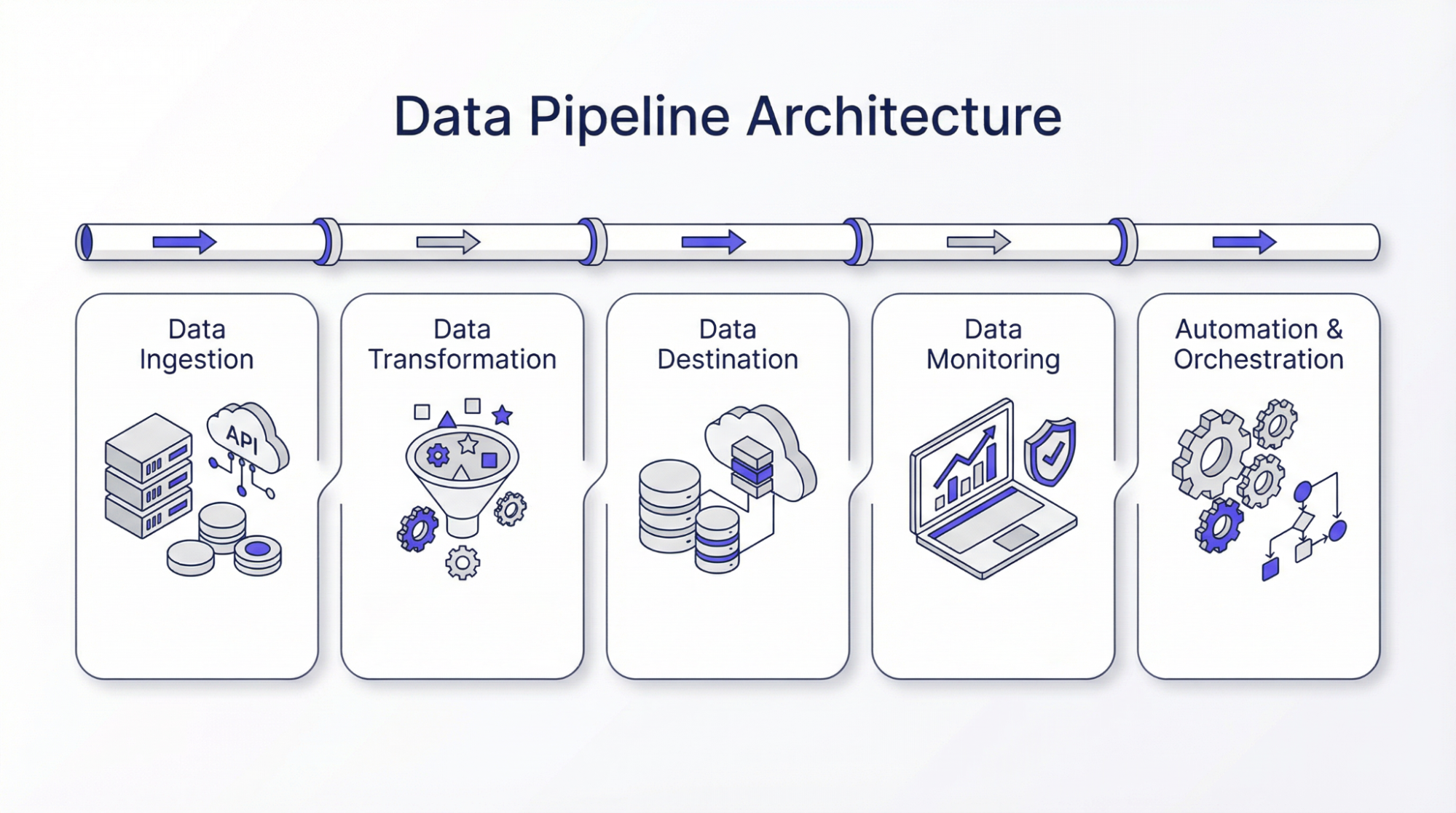
Нижче наведено кроки, пов’язані з архітектурою конвеєра даних:
Збір даних
Першим кроком в архітектурі конвеєра даних є збір даних з різних джерел. Якісні дані завжди є пріоритетом, оскільки це впливає на достовірність всього процесу. Отримані або зібрані дані можуть бути структурованими або неструктурованими залежно від технології. Є люди, які вважають за краще збирати дані тільки тоді, коли це необхідно, а є ті, хто збирає дані і зберігає їх. Це допомагає їм оновлювати свої історичні дані, і вони можуть використовувати їх для порівняння. На цьому етапі використовуються різні механізми для забезпечення надійності та точності даних. Впровадження заходів, що сприяють відмовостійкості та масштабованості, забезпечує безперебійну роботу на наступних етапах.
Трансформація даних
Трансформація даних – це процес перетворення даних у необхідну форму. Цей крок є важливим, оскільки зібрані дані можуть мати різну форму. Наприклад, дані можуть бути у формі JSON, а JSON може бути вкладеним. Тому основною метою цього кроку, або трансформації даних, є розгортання JSON для отримання ключових даних для подальшої обробки. Іншими словами, трансформація даних необхідна для того, щоб привести всі дані до потрібного вигляду, а точніше, до стандартного вигляду. Мета трансформації даних – очистити, відфільтрувати та підвищити цінність для прийняття бізнес-рішень. Для отримання дієвих інсайтів може бути використано кілька алгоритмів, таких як обчислювальні методи, статистичний аналіз або машинне навчання.
Призначення даних
Пункти призначення даних – це місця, де оброблені дані зберігаються в архітектурі конвеєра. Це можуть бути сховища даних, хмарні бази даних або озера даних. Вибір відповідного сховища є важливим, оскільки він впливає на легкість доступу до даних. При виборі місця зберігання даних враховуються різні фактори, такі як тип, обсяг і призначення даних.
Хороша архітектура конвеєра даних – це така архітектура, яка забезпечує аналітикам легкий доступ до даних з місць призначення. Вона також повинна бути побудована таким чином, щоб швидко і точно обробляти великі обсяги даних. На цьому етапі впроваджуються політики захисту даних для забезпечення їхньої безпеки та відповідності нормативним вимогам.
Моніторинг даних
Моніторинг даних необхідний для забезпечення дотримання політик і правил. Це необхідно для підтримки безпеки та цілісності. Тому на цьому етапі виділяють ролі для управління даними, аудиту та впровадження контролю доступу. Система контролю має вирішальне значення для запобігання несанкціонованому доступу до даних і дотримання законів, таких як Загальний регламент захисту даних. Крім того, моніторинг якості даних корисний для виявлення аномалій і помилок у процесі роботи. Таким чином, впровадження етапів перевірки даних і виявлення помилок забезпечує надійність і точність вихідних даних. Крім того, інструменти моніторингу надають огляд продуктивності конвеєра даних і виявляють проблеми для швидкого вирішення.
Автоматизація та оркестрування
Оркестровку даних можна визначити як координацію руху даних вздовж трубопроводу. Це необхідно для забезпечення правильного виконання процесів. Ці інструменти запускають робочі процеси та керують діями з відновлення, що мінімізує ручне втручання. Хороша стратегія оркестрування враховує динамічне масштабування, балансування навантаження та паралельну обробку. Тому вони відіграють ключову роль у продуктивності конвеєрів даних, забезпечуючи безперебійний потік даних з мінімальними збоями.
Варіанти використання зібраних даних
Нижче наведено різні способи використання збору даних
Виявлення шахрайства у фінансах
Деякі фінансові організації використовують архітектуру інтеграції даних для виявлення та запобігання шахрайству. Інтеграція надійної системи шифрування та мапування у фінансовій сфері має вирішальне значення для виявлення шахрайства. Це призводить до більшої довіри та менших фінансових втрат.
Машинне навчання
Машинне навчання – це галузь штучного інтелекту, яка використовує дані для навчання великих мовних моделей (БММ), що застосовуються в різних галузях. Машинне навчання також важливе тим, що воно використовує дані для імітації того, як люди міркують, спілкуються та вирішують проблеми. Крім того, його можна використовувати для прогнозування, використовуючи дані, зібрані з минулих і поточних тенденцій.
Аналітика та моніторинг
Наукові специ зі збору даних, аналітики також працює з великою кількістю даних, щоб аналізувати їх і робити висновки. Пайплайни даних допомагають у цьому випадку, оскільки вони надають дані у форматі, який легко класифікувати. Згодом це дозволяє аналітику даних легко використовувати інструменти візуалізації даних для ефективного аналізу та висновків.
Проблеми, пов’язані з архітектурою пайплайну даних
Незважаючи на простоту архітектури конвеєра даних, вона не позбавлена проблем. Наприклад, існують такі проблеми, як
Непослідовна якість даних
Однією з найпоширеніших проблем, пов’язаних з конвеєрами надходження даних, є непослідовна якість даних. Це може призвести до прийняття неправильного рішення і, як наслідок, до нестабільності роботи. Таким чином, архітектура конвеєра даних повинна бути розроблена з певними компонентами, які можуть ефективно вимірювати і контролювати якість даних. Якість даних визначається як високоякісні дані, якщо вони є такими:
- Точний
- Послідовний
- Актуально
- Своєчасно
- Завершено
- Унікальний.
Крім того, автоматизація процесу очищення даних допомагає уникнути помилок, які можуть виникнути під час цього процесу. Таким чином, ці компоненти повинні бути включені в конвеєр збору даних, щоб підвищити релевантність результату.
Безпека даних та конфіденційність
Багато країн змогли запровадити закони про захист даних, щоб забезпечити їхню безпеку в нинішню епоху автоматизованого веб-скрепінгу. Ці закони також диктують використання даних, отриманих в Інтернеті. Таким чином, дотримання цих законів допомагає побудувати довіру зі стейкхолдерами, партнерами та клієнтами. Важливо захистити дані від несанкціонованого доступу та використовувати їх відповідно до закону. Отже, існує потреба в тому, щоб архітектура конвеєра прийому даних включала надійне шифрування для збереження конфіденційності даних.
Масштабованість
Ще однією проблемою, з якою стикаються при поглинанні даних, є масштабованість, тобто здатність обробляти величезні обсяги даних. Коли попит на дані зростає, виникає відповідна потреба у підвищенні продуктивності конвеєрних фреймворків. Однак, для покращення масштабованості можна використовувати хмарні рішення.
Вузькі місця в продуктивності
Через складність даних може виникнути повторювана проблема з продуктивністю. Ця проблема може виникнути на будь-якому етапі конвеєра.
Вузькі місця в продуктивності часто виникають, коли один етап фреймворку обробляє дані повільніше, ніж попередній, створюючи таким чином відставання. Належне планування та використання правильних інструментів може допомогти вирішити цю проблему в конвеєрі надходження даних.
Зв’язок між пайплайном даних та ETL
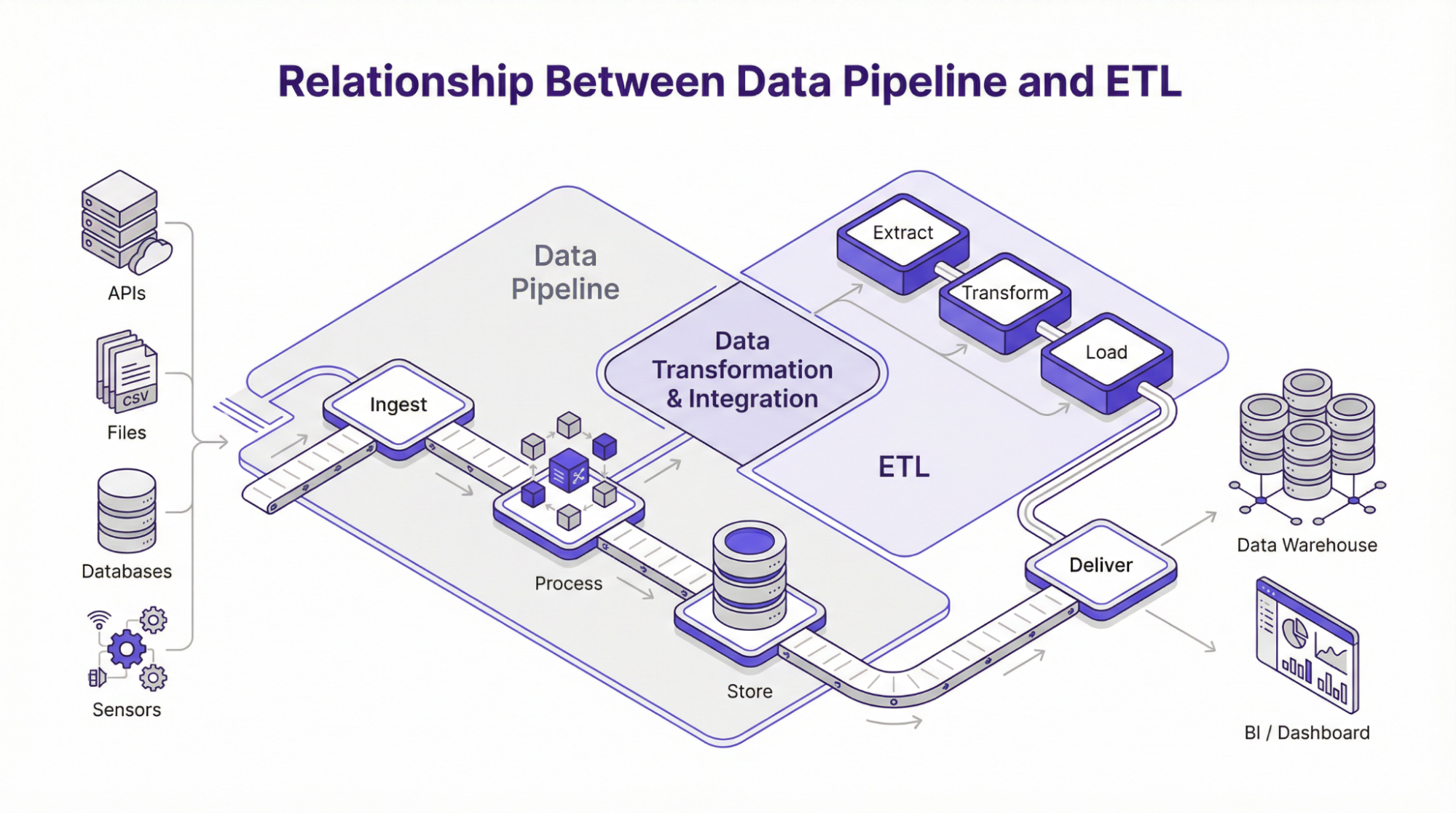
ETL, що розшифровується як “витягнути, перетворити і завантажити”, є одним з найпоширеніших методів побудови конвеєрів даних. Як випливає з назви, він визначає певний шлях для даних під час їхнього руху через систему.
У стандартному або традиційному конвеєрі ETL дані витягуються з різних джерел. Потім вони перетворюються на рівень обробки, з якого завантажуються в кінцеве сховище, наприклад, сховище даних. Цей процес часто використовується у фреймворках пакетної обробки, де дані збираються та обробляються у заплановані періоди. Крім того, цей фреймворк застосовується, коли дані потрібно перевірити, відформатувати або перетворити в структурований формат перед зберіганням. Однак сучасна архітектура конвеєрів даних підтримує й інші фреймворки, такі як:
ELT – Витягти, завантажити, перетворити
Модель ELT передбачає завантаження даних у сховище призначення одразу після вилучення з різних джерел. Згодом перетворення здійснюються пізніше за допомогою таких інструментів, як SQL або БД. Однак фреймворку ELT зазвичай надають перевагу в ситуаціях, коли обчислення і зберігання є окремими блоками, як, наприклад, у хмарних конвеєрах.
Зворотний ETL
У цьому фреймворку дані рухаються в протилежному напрямку від того, що ми бачимо в ETL. Іншими словами, дані переміщуються зі сховища до зовнішніх інструментів, таких як системи підтримки клієнтів, моделі машинного навчання або CRM. Згодом компанії можуть інтегрувати аналіз в операції, пов’язуючи дані зі сховища з інструментами, що використовуються командами підтримки, продажів або маркетингу. Хоча ETL, ELT і зворотна ETL переміщують дані в різних напрямках, мета залишається незмінною – витягнути дані з того місця, де вони згенеровані, і відправити їх туди, де вони потрібні. Тому розуміння цих механізмів руху даних допоможе командам визначити найкращий підхід до побудови конвеєра надходження даних, який буде релевантним, масштабованим і відповідатиме операційним цілям.
Висновок
Організації потребують багато даних для підтримки стабільності. У той же час, вони намагаються отримувати дані швидше, ніж можуть їх обробити. Поглинання даних – це архітектурна система, яка може допомогти перетворити всі ці дані у корисну форму. Тому ефективно створити конвеєр поглинання даних, щоб використовувати ресурси з різних джерел.
Деякі з проблем, з якими стикаються в процесі збору даних, включають якість даних, продуктивність, проблеми з безпекою та обробку великих обсягів даних. Незважаючи на всі ці проблеми, можна зробити процес збору даних безпроблемним, використовуючи найкращі практики, такі як забезпечення якості даних, масштабованість фреймворку збору даних та моніторинг продуктивності конвеєра даних.





