


O web scraping do Reddit é o processo de coleta de dados disponíveis publicamente na plataforma. Os dados coletados podem incluir postagens, perfis, comentários e muito mais. A coleta manual de dados do Reddit pode ser demorada, propensa a erros e ineficiente. Portanto, pesquisadores, profissionais de marketing e de SEO geralmente automatizam a coleta de dados do Reddit com bots ou scripts. O gerenciamento de várias contas do Reddit para raspagem pode exigir o uso de um proxy. Para facilitar a extração de dados, o Reddit tem uma API pública. No entanto, suas opções são muito limitadas quando você faz scraping do Reddit com a API por alguns motivos. Primeiro, a API implementa limites de taxa, o que restringe o número de solicitações que você pode enviar em um período de tempo. Além disso, ela geralmente exige detalhes de autenticação, o que pode tornar todo o processo mais lento.
Como funciona um Reddit Scraper?
Para coletar dados do Reddit, o coletor de dados envia solicitações HTTP para a plataforma. A próxima fase envolve a análise das respostas em HTML ou JSON. Em seguida, os elementos necessários, como ID de usuário ou comentários, são extraídos. Por fim, os dados extraídos são limpos e armazenados em um formato predefinido. Os dados disponíveis publicamente que você pode extrair no Reddit incluem:
- Títulos dos posts
- Nomes de usuário
- Comentários (tópicos e respostas)
- Pontuações (votos positivos e negativos)
- Metadados do subreddit
- Carimbos de data/hora e histórico de edições
Alguns dos desafios associados ao uso de um scraper do Reddit incluem CAPTCHAs, IPs bloqueados, seções de comentários aninhadas e limites de taxa. É nesse ponto que as ferramentas otimizadas desempenham um papel crucial para que você leve suas atividades de raspagem para o próximo nível.
Onde você pode obter o Reddit Scraper
Os raspadores podem ser amplamente categorizados em 2 (dois) grupos: raspadores com código e sem código. Os raspadores de código utilizam uma linguagem de programação como Python, CSS, Java etc. para criar um script que automatiza a extração de dados. Essa opção requer algumas habilidades de codificação e conhecimento técnico para escrever um código que possa ignorar o CAPTCHA e os limites de taxa para uma extração de dados eficaz. Você também pode escrever um script para um raspador de imagens do Reddit se o objetivo for apenas extrair imagens da página.
Por outro lado, a opção sem código é uma solução que não exige codificação nem um amplo conhecimento de linguagens de programação. Para aqueles que buscam uma opção fácil de como fazer scraping do Reddit, as ferramentas sem código são úteis. Elas vêm com diferentes recursos que permitem que você extraia dados de plataformas como o Reddit em poucas etapas. Um dos lugares mais confiáveis para você obter essa solução de raspagem sem código é o Floppydata. Essa ferramenta otimiza o processo de obtenção de dados do Reddit com recursos que ignoram o CAPTCHA e as proibições de IP para que você tenha uma experiência tranquila. A ferramenta Web Unblocker da Floppydata é excelente para dimensionar grandes volumes de dados sem a necessidade de navegadores de automação como Selenium, Puppeteer ou Playwright.
O Floppydata’s Web Unblocker é uma ferramenta que simplifica a raspagem da Web, contornando bloqueios e CAPTCHAs automaticamente, permitindo que você colete dados sem precisar de automação do navegador ou configuração manual de proxy. Alguns de seus recursos incluem:
- Resolução automatizada de CAPTCHA
- Contornar mecanismos antibot com sua impressão digital avançada do navegador
- Extrai dados de sites dinâmicos com eficiência
- Rotação automática de proxy incorporada e lógica de repetição para manter o anonimato.
Outro aspecto que você deve considerar ao adquirir um raspador é o preço. A Floppydata tem o compromisso de fornecer soluções de alta qualidade a preços acessíveis. Portanto, a Floppydata oferece o Web Unblocker a um preço altamente competitivo. Embora haja uma avaliação gratuita, ela é limitada a 5 (cinco) raspagens. Há quatro níveis de preços e eles incluem:
- Plano de crescimento – A partir de US$ 0,98 por 1 mil resultados
- Plano profissional – A partir de US$ 0,75 por 1 mil resultados
- Plano de negócios – A partir de US$ 0,60 por 1 mil resultados
- Plano Premium – A partir de US$ 0,45 por 1.000 resultados
- Plano personalizado – Entre em contato com o suporte ao cliente para obter um plano personalizado
Prós do raspador sem código da Floppydata
- Usuários não técnicos podem usá-lo com facilidade
- Vem com recursos integrados que lidam com rotação de IP, CAPTCHAs e conteúdo dinâmico
- Fornece dados em formatos como CSV ou JSON para facilitar o processamento
- Opções econômicas para pessoas físicas e PMEs
- Entrega rápida de dados
Contras
- Flexibilidade limitada para personalização
Outras alternativas para raspagem de dados do Reddit
Vamos analisar brevemente outros métodos que podem ser usados para extrair dados do Reddit:
API oficial do Reddit
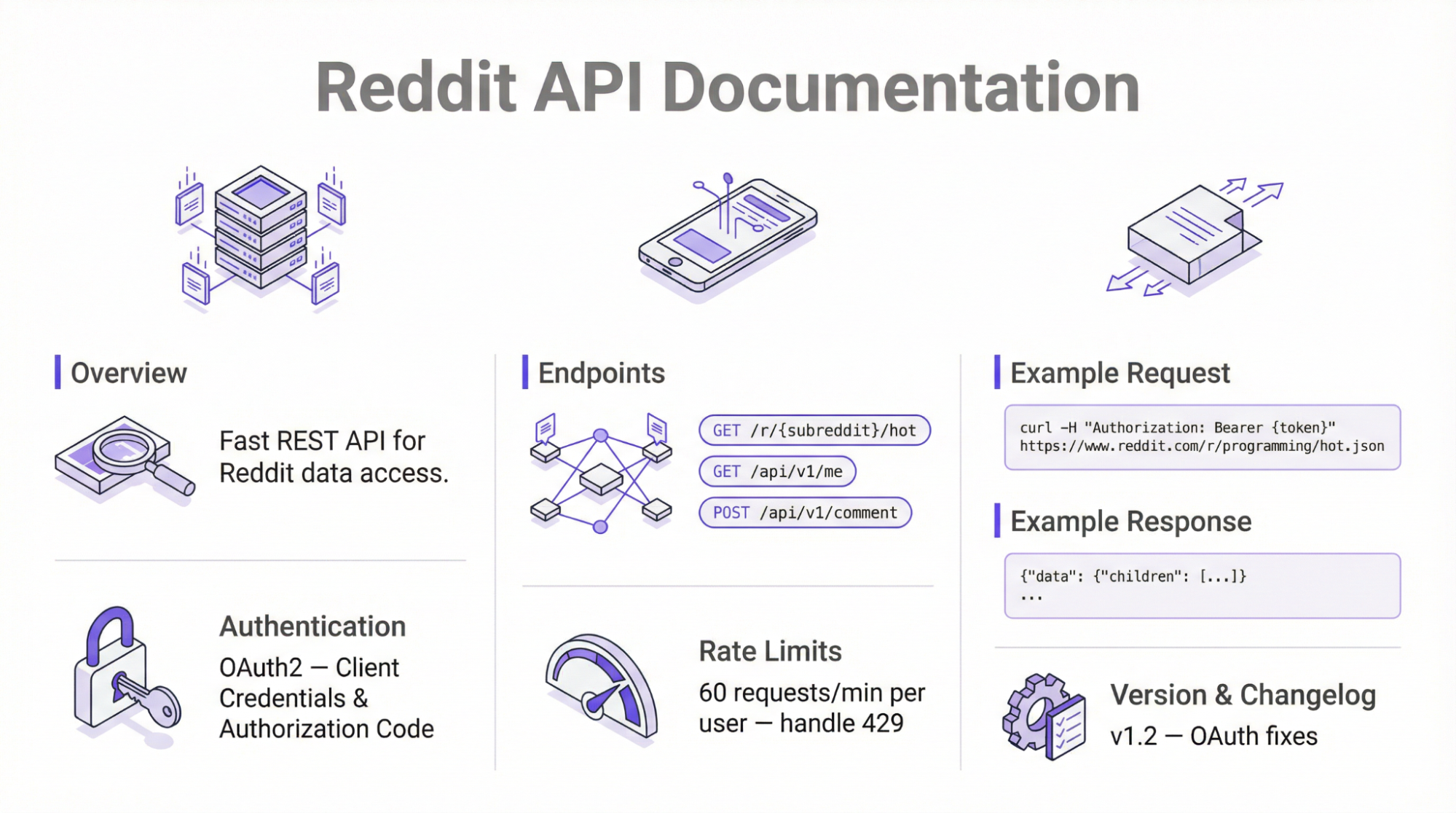
Se você quiser extrair informações da plataforma sem ferramentas de terceiros, considere usar a API oficial. Essa abordagem usa os pontos de extremidade da API JSON do Reddit para coletar informações publicamente disponíveis usando solicitações HTTP simples.
O uso da API oficial exige autenticação OAuth2 e impõe os limites de taxa – 100 QPM para a camada gratuita. De acordo com as atualizações da política lançadas em 2025, a API requer aprovação manual da plataforma antes da recuperação de dados.
Siga as etapas abaixo para usar a API oficial do Reddit para coleta de dados:
- Registre-se para obter acesso à API
A primeira etapa é fazer login na sua conta do Reddit ou criar uma, se você for um novo usuário. Visite a página Aplicativos do Reddit, clique em “criar um aplicativo” e siga as instruções na tela. Quando isso for feito com sucesso, uma nova janela será exibida com o ID do cliente, o segredo do cliente e a string do agente do usuário.
- Autenticação
Use o OAuth para obter um token de acesso. Para essa etapa, você pode usar uma biblioteca de programação, como a biblioteca PRAW do Python, e autenticar com a API. Como alternativa, você pode usar a biblioteca de solicitações , que envolve o manuseio manual dos tokens de acesso.
- Fazer solicitações HTTP
A próxima etapa é usar uma estrutura, como a biblioteca de solicitações do Python, para enviar solicitações GET a vários pontos de extremidade.
- Analisar e salvar dados
Os dados brutos são extraídos e processados no formato JSON para facilitar a leitura.
Observação: o processo descrito acima só é eficiente para tarefas simples de raspagem. Além disso, ele requer um bom conhecimento de linguagens de programação e codificação.
Prós da API oficial do Reddit
- Ele fornece acesso oficial e confiável aos servidores do Reddit para coletar dados
- Trata-se de uma reclamação sobre os termos de uso da plataforma
- Risco mínimo de proibições, desde que você não exceda o limite da taxa
- Oferece suporte à extração de dados disponíveis publicamente sem restrições anti-scraping.
Contras da API oficial do Reddit
- Os dados são muito limitados
- Não é adequado para pessoas com pouca ou nenhuma habilidade de codificação
- Os limites de taxa tornam difícil dimensionar o processo de raspagem
- A extração de dados em grandes volumes pode ser bastante cara
Usando Python

Python é uma linguagem de programação com uma extensa biblioteca que oferece suporte à raspagem da Web. Para a raspagem do Reddit, a maioria dos desenvolvedores usa o PRAW (Python Reddit API Wrapper) para interagir com o servidor e extrair dados.
No entanto, para extrair dados além dos limites da API, são usadas estruturas como a BeautifulSoup. Elas também desempenham um papel fundamental na análise de dados HTML e no fornecimento deles no formato XML ou JSON.
A estrutura do Reddit muda com frequência, o que pode afetar o desempenho do raspador. Portanto, o raspador precisa ser atualizado regularmente para se adaptar às modificações na plataforma.
Práticas recomendadas para usar um coletor de dados do Reddit em Python
Girar endereço IP
Uma das principais finalidades da rotação de endereços IP é o anonimato. Além disso, a plataforma pode detectar quando solicitações repetidas são originadas do mesmo endereço IP. Isso pode acionar um bloqueio de IP, o que dificulta a conclusão da coleta de dados
Manuseio do CAPTCHA
Um raspador Python do Reddit não está equipado para lidar com CAPTCHAs, que podem ser exibidos como uma forma de a plataforma diferenciar atividades humanas e de bots. Para contornar o CAPTCHA, use navegadores sem cabeça como Selenium, Playwright e Puppeteer para imitar o padrão de navegação humana. Posteriormente, isso torna mais difícil a detecção de atividades automatizadas.
Use navegadores sem cabeça para lidar com conteúdo dinâmico
Semelhante aos sites modernos, o Reddit usa JavaScript para carregar conteúdo dinâmico. Os raspadores comuns geralmente analisam apenas o conteúdo HTML e podem não conseguir carregar o conteúdo dinâmico. Uma maneira de lidar com isso é integrar navegadores sem cabeça, como o Selenium
Prós de usar Python
- Como se trata de uma biblioteca de código aberto, ela é gratuita
- Altamente personalizável
- Confiável
Contras de usar o Python Scrapers
- Requer conhecimento de programação em Python
- Limitado a dados públicos
- Restrito aos limites da API do Reddit
Casos de uso de dados do Reddit
O web scraping do Reddit fornece acesso a dados que podem ser usados para várias finalidades. Alguns dos casos de uso mais comuns são:
Pesquisa de mercado
Muitos profissionais coletam dados do Reddit para pesquisa de mercado. As informações coletadas podem ser classificadas e analisadas para que você entenda o sentimento do mercado, as tendências atuais e a reputação de diferentes marcas. Portanto, os dados podem ser interpretados em decisões que influenciam anúncios de produtos, embalagens e preços adequados ao mercado-alvo.
Análise financeira
A maioria das pessoas não sabe que há uma comunidade inteira de especialistas financeiros no Reddit. O Reddit contém um grande volume de dados sobre tópicos financeiros que envolvem ações, ações, criptomoedas e mercados internacionais. A análise financeira é necessária antes de você fazer qualquer investimento significativo para minimizar o risco de perda. Esses dados podem ser extraídos, analisados e interpretados para que você entenda a previsão do mercado e tome decisões financeiras informadas.
IA e aprendizado de máquina
Os dados do Reddit podem ser usados para treinar LLMs (Large Language Models) para melhorar os resultados de pesquisa orientados por IA. Os bots de IA só podem ter o mesmo desempenho que os dados que recebem. Portanto, o grande número diário de visitantes do Reddit o torna uma fonte ideal de dados. Um exemplo é a IA nativa do Reddit, um LLM que é alimentado com dados da plataforma para fornecer páginas personalizadas para cada visitante.
Pesquisa social
Outro caso de uso dos dados do Reddit é a pesquisa social. A coleta de dados do subreddit pode ser usada para estudos sobre o padrão de interação humana. A pesquisa social pode ser usada para coletar dados sobre tendências e opiniões sobre tópicos como privacidade e consentimento on-line. Além disso, os dados podem ser usados para treinar chatbots para fornecer suporte 24 horas por dia, 7 dias por semana, o que pode não ser viável com agentes de suporte humanos.
Como extrair dados do Reddit com o Floppydata Web Unblocker
Usar o Web Unblocker da Floppydata como um raspador do Reddit é fácil e pode ser feito em algumas etapas. Aqui você encontra um guia passo a passo sobre como extrair dados do Reddit com a Floppydata.
Vamos lá!
Etapa 1: Visite a página do Web Unblocker e faça login para começar
Etapa 2: Faça login na sua conta do Reddit. Abra uma página de resultados de pesquisa com filtros específicos que se alinham ao seu caso de uso.
Etapa 3: Vá para o painel do Floppydata’s Web Unblocker e cole o URL
Etapa 4: Seus resultados estarão prontos em poucos minutos.
Conclusão
Aprender a extrair dados do Reddit pode ser um recurso poderoso para pesquisadores, indivíduos e empresas. É uma maneira de obter insights de uma das maiores comunidades globais da Web. Para coletar esses dados, você pode escrever um script com uma linguagem de programação ou usar uma solução sem código.
O Floppydata oferece uma solução abrangente de raspagem sem código, o Web Unblocker, que extrai dados do Reddit com eficiência e os entrega no formato que você preferir. Novos usuários recebem até 5 sessões gratuitas para coletar dados de qualquer plataforma.
Se você deseja ter uma experiência fácil e perfeita com a coleta de dados do Reddit, experimente o Web Unblocker da Floppydata hoje mesmo!





