


Atualmente, os dados são um ativo essencial para muitas organizações em vários setores. No entanto, há muitas organizações que estão coletando dados mais rapidamente do que conseguem processá-los. As técnicas de coleta e manipulação de dados influenciam as decisões de operações comerciais.
Como a qualidade da entrada afeta a saída, torna-se necessário garantir que seu sistema receba dados de boa qualidade. E é por isso que você precisa de uma boa arquitetura de pipeline de ingestão de dados para promover o fornecimento de insights acionáveis.
Neste guia, vamos esclarecer os pipelines de ingestão de dados, os tipos de ingestão de dados e os casos de uso comuns.
O que é ingestão de dados?
Uma das perguntas mais comuns que as pessoas fazem quando tentam entender o pipeline de ingestão é “o que é ingestão de dados?”
O termo ingestão de dados descreve o processo de coleta, classificação e organização de dados de várias fontes em um armazenamento central, como um datahub ou warehouse. Esse processo marca a primeira etapa na preparação de “dados brutos” para processamento e interpretação posteriores. A ingestão de dados é uma etapa muito importante no pipeline, pois é o estágio em que os dados são coletados de várias fontes que afetarão a forma como as empresas obtêm insights sobre o produto e vantagem competitiva.
Algumas das fontes de dados comuns para o pipeline são:
- Bancos de dados
- Internet das Coisas
- Centros de dados
- Plataformas de mídia social
- API
- Provedores de dados de terceiros
- Aplicativos SaaS
Benefícios da ingestão de dados
Toda empresa, independentemente do tamanho, pode se beneficiar da ingestão de dados, pois ela fornece insights sobre tendências de mercado, sentimentos dos consumidores, estratégias inovadoras e muito mais. Aqui estão alguns dos benefícios mais comuns da ingestão de dados:
Disponibilidade de dados
Um dos benefícios da ingestão de dados é que ela elimina a necessidade de silos de dados. Isso promove a disponibilidade de dados para análise, agregando dados de várias fontes em uma única fonte central.
Escalabilidade
À medida que as empresas crescem, cresce também a necessidade de dados de boa qualidade. Portanto, os pipelines de ingestão de dados desempenham um papel central no tratamento de grandes volumes de dados, garantindo validade, precisão e confiabilidade.
Análise em tempo real
Outro benefício do pipeline de ingestão de dados é que os dados são processados imediatamente ou em lotes, o que fornece acesso a insights atualizados. Como resultado, as empresas podem reagir rapidamente às tendências e tomar decisões oportunas que podem afetar a margem de lucro geral.
Eficiência
Como os pipelines de ingestão de dados são automatizados, isso elimina a necessidade de manuseio manual dos dados. Isso economiza tempo e recursos ao simplificar o processo de importação e armazenamento de dados enquanto a equipe se concentra em outras tarefas prioritárias.
Tipos de ingestão de dados
A coleta de dados de diferentes fontes em um armazenamento central parece bastante simples. No entanto, isso pode ser um pouco mais complicado, especialmente para o pipeline de dados. Veja a seguir os tipos mais comuns de ingestão de dados:
Ingestão de lotes
Esse é o processo pelo qual um grande volume de dados é coletado em intervalos específicos. Esses intervalos podem ser de hora em hora, diários ou até semanais, dependendo das necessidades de coleta de dados que você tiver. Portanto, a ingestão de dados em lote é adequada para ser usada por empresas que não precisam de dados em tempo real para a tomada de decisões.
Esse é o tipo de empresa que pode operar confortavelmente e tomar decisões com base em atualizações periódicas de dados.
Ingestão em tempo real
Essa técnica exige que os dados sejam recebidos no momento exato em que são criados. Essa técnica, portanto, permite o recebimento de novos insights de dados, que são muito importantes para a tomada de decisões. A ingestão em tempo real ajuda a reduzir o atraso entre o recebimento e o processamento dos dados. Alguns dos casos de uso de dados em tempo real são a detecção de fraudes, o processamento de dados de sensores e a atualização de painéis de controle em tempo real. O pipeline de ingestão de dados em tempo real pode processar dados em tempo real ou em partes enquanto eles estão sendo extraídos. Embora essa técnica forneça dados atualizados, o tratamento de erros e a escalabilidade são questões complexas.
Arquitetura Lambda
A arquitetura Lambda combina a ingestão em lote e em tempo real para oferecer um equilíbrio entre velocidade e precisão. Os dados em lote fornecem tendências históricas abrangentes, enquanto os dados em tempo real oferecem insights sobre as atividades atuais.
A abordagem Lambda é frequentemente usada em situações que exigem a manipulação de grandes volumes de dados com alta precisão. Posteriormente, ela permite que as empresas respondam rapidamente a eventos atuais sem perder o conhecimento de eventos anteriores do mercado.
O que é o pipeline de ingestão de dados?
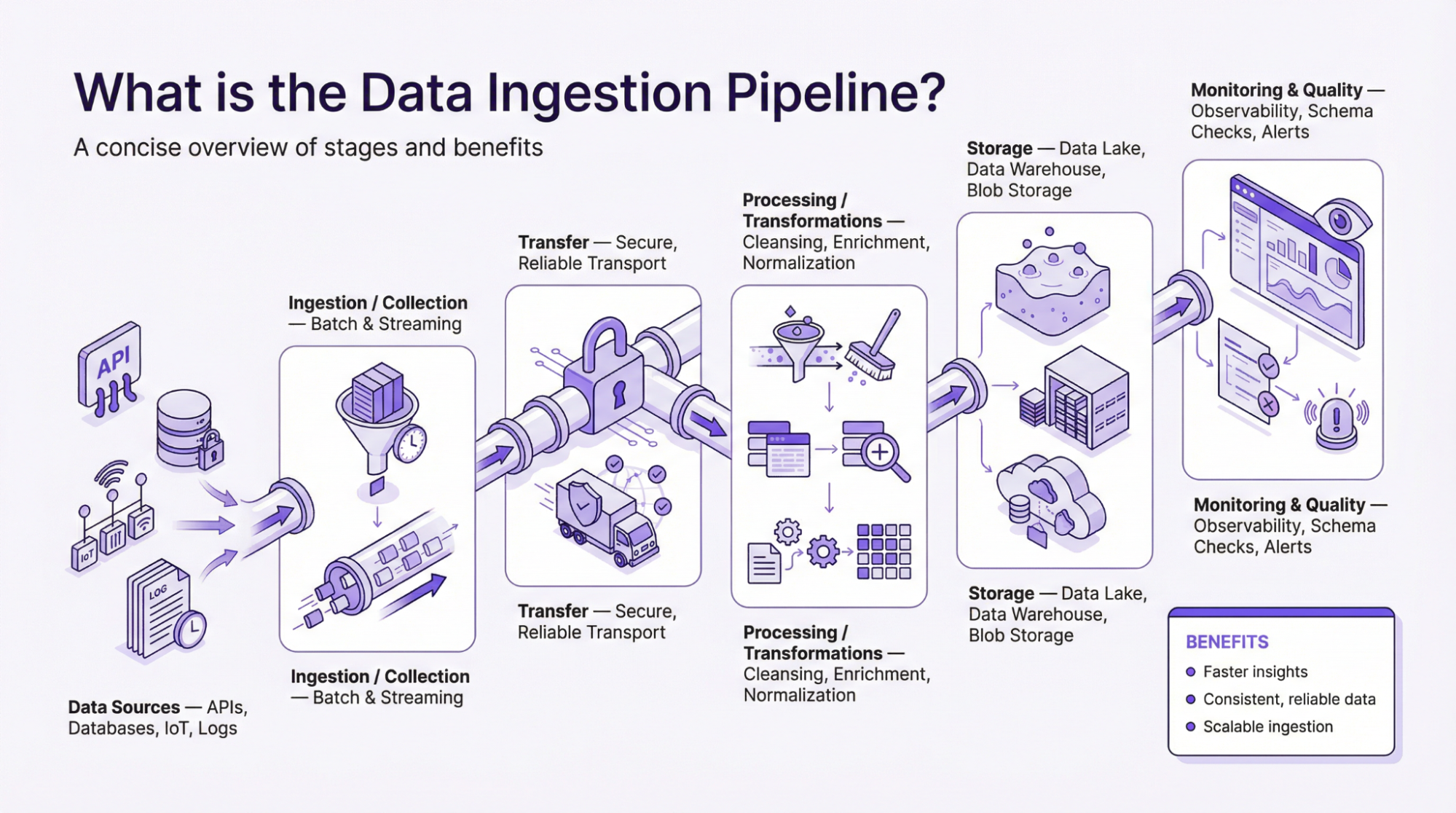
Para a pergunta principal:“O que é pipeline de ingestão de dados?” – O pipeline, geralmente descrito como uma estrutura, descreve o fluxo de dados desde o ponto de coleta até o momento em que são processados e aplicados para tomar decisões baseadas em evidências. Um pipeline de dados é simplesmente a forma como as informações fluem de um lado para o outro. É um conjunto de instruções que coleta dados de diferentes fontes, processa-os e os envia a um destino. Portanto, um pipeline de ingestão de dados adequado é necessário para que as organizações usem efetivamente os dados para impulsionar o crescimento, o lucro e o ROI.
Etapas para criar um pipeline de digestão de dados eficaz
Aqui estão algumas etapas fundamentais para você criar um pipeline de digestão de dados eficaz:
- Determinar as fontes de dados: A primeira etapa para criar um pipeline de digestão de dados eficaz é identificar a fonte de dados. Antes de definir as fontes de dados, você deve primeiro definir o tipo de dados, o volume, a velocidade e as metas organizacionais. A escolha de fontes de dados boas e sustentáveis desempenha um papel importante na precisão e na confiabilidade do resultado.
- Escolha o destino dos dados: Em seguida, você precisa determinar o destino dos dados. Esse é o local onde você armazenará todos os dados que está obtendo de diferentes fontes. O sistema de destino pode ser um lago de dados, um depósito ou outros tipos de armazenamento que você preferir.
- Selecione o método de ingestão de dados: Há diferentes tipos de métodos de ingestão de dados. Portanto, você precisa escolher o que melhor se adapta às necessidades exclusivas da sua empresa. Dependendo dos seus objetivos comerciais, você pode escolher entre ingestão em lote, ingestão em fluxo ou uma combinação de ambos.
- Projetar o processo de ingestão: Esse método envolve determinar como os dados serão coletados, processados e armazenados no sistema de destino. No mundo digital de hoje, o processo de ingestão é automatizado para promover a eficiência e reduzir os erros humanos. Outro motivo para automatizar o processo é a consistência. A automação do fluxo de dados no pipeline garante que os dados sejam movidos de acordo com o plano para evitar gargalos.
- Monitoramento e manutenção: Depois que o processo de ingestão de dados for implementado, você precisará monitorar seu desempenho. Isso envolve a implementação de alertas para tarefas com falha. O monitoramento regular ajuda a detectar problemas e a resolvê-los prontamente para garantir a consistência na disponibilidade dos dados.
Arquitetura do pipeline de dados
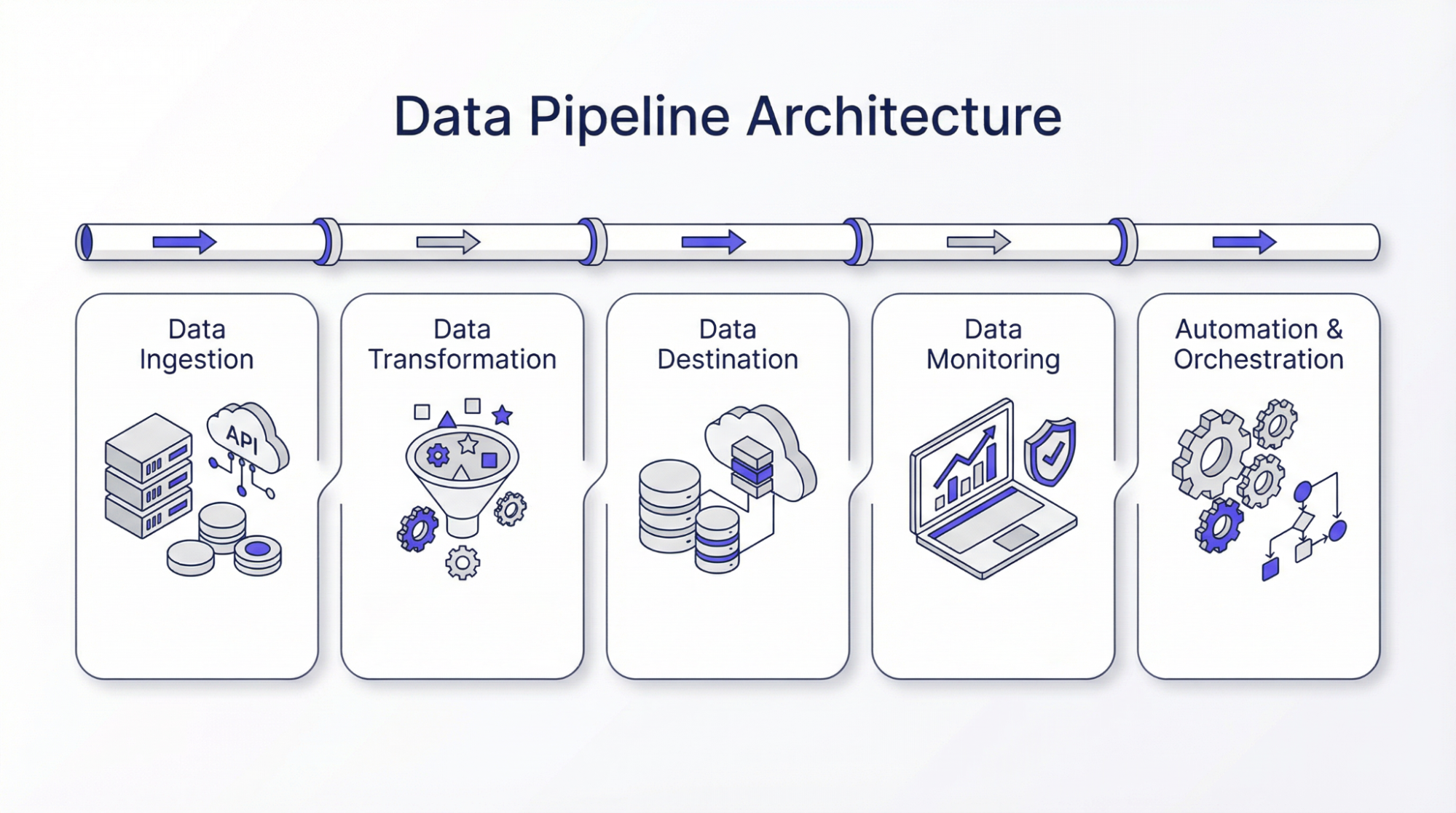
A seguir, você verá as etapas envolvidas na arquitetura do pipeline de dados:
Ingestão de dados
A primeira etapa da arquitetura do pipeline de dados é a coleta de dados de várias fontes. Dados de boa qualidade são sempre uma prioridade, pois isso afeta a autenticidade de todo o processo. Os dados ingeridos ou coletados podem ser estruturados ou não estruturados com base na tecnologia. Algumas pessoas preferem coletar dados somente quando necessário, enquanto outras coletam dados e os armazenam. Isso os ajuda a atualizar seus dados históricos e eles podem usar os dados para comparação. Nesse estágio, diferentes mecanismos são empregados para garantir a confiabilidade e a precisão dos dados. A implementação de medidas que promovem a resiliência e o dimensionamento garante um desempenho downstream tranquilo.
Transformação de dados
A transformação de dados é o processo de transformar os dados no formato necessário. Essa etapa é importante, pois os dados coletados podem não ter o mesmo formato. Por exemplo, os dados podem estar no formato JSON, e o JSON pode estar aninhado. Portanto, o principal objetivo dessa etapa, ou transformação de dados, é desenrolar o JSON para obter os principais dados para processamento posterior. Em outras palavras, a transformação de dados é necessária para trazer todos os dados para o formato desejado, ou melhor, para um formato padrão. O objetivo da transformação de dados é limpar, filtrar e aumentar o valor para as decisões de negócios. Vários algoritmos, como métodos computacionais, análise estatística ou aprendizado de máquina, podem ser empregados para gerar percepções acionáveis.
Destino dos dados
Os destinos de dados são onde os dados processados são armazenados na arquitetura do pipeline. Esses destinos podem ser data warehouses, bancos de dados baseados em nuvem ou data lakes. A escolha de um armazenamento adequado é importante, pois afeta a facilidade de acesso aos dados. Vários fatores, como tipo de dados, volume e finalidade, são considerados antes da escolha do destino dos dados.
Uma boa arquitetura de pipeline de dados é aquela que garante que os analistas possam acessar facilmente os dados dos destinos. Ela também deve ser desenvolvida para lidar com grandes volumes de dados de forma rápida e precisa. Nesse estágio, as políticas de proteção de dados são implementadas para garantir a segurança e a conformidade dos dados.
Monitoramento de dados
O monitoramento de dados é necessário para garantir a conformidade com políticas e regulamentos. Isso é necessário para manter a segurança e a integridade. Portanto, essa etapa inclui o destaque das funções de gerenciamento de dados, auditoria e implementação de controles de acesso. A estrutura de controle é fundamental para evitar o acesso não autorizado aos dados e a adesão a leis como o Regulamento Geral de Proteção de Dados. Além disso, o monitoramento da qualidade dos dados é útil para detectar anomalias e erros no pipeline. Portanto, a implementação de etapas de validação de dados e a detecção de erros garantem a confiabilidade e a precisão dos resultados. Além disso, as ferramentas de monitoramento fornecem uma visão geral do desempenho do pipeline de dados e detectam problemas para pronta resolução.
Automação e orquestração
A orquestração de dados pode ser definida como a coordenação da movimentação de dados ao longo do pipeline. Isso é necessário para garantir que os processos sejam executados da maneira correta. Essas ferramentas acionam fluxos de trabalho e gerenciam ações de recuperação, o que minimiza a intervenção manual. Uma boa estratégia de orquestração considera o dimensionamento dinâmico, o balanceamento de carga e o processamento paralelo. Portanto, elas desempenham um papel fundamental no desempenho dos pipelines de dados para garantir um fluxo de dados suave com o mínimo de interrupções.
Casos de uso de ingestão de dados
Abaixo você encontrará vários usos da ingestão de dados
Detecção de fraudes em finanças
Algumas organizações financeiras usam a arquitetura de integração de dados para detectar e prevenir fraudes. A integração de um sistema robusto de criptografia e mapeamento em finanças é fundamental para a detecção de fraudes. Isso leva a mais confiança e menos perdas financeiras.
Aprendizado de máquina
O aprendizado de máquina é um ramo da IA que usa dados para treinar grandes modelos de linguagem (LLMs) que são usados em vários setores. O aprendizado de máquina também é importante, pois usa dados para imitar a forma como os seres humanos raciocinam, se comunicam e resolvem problemas. Além disso, ele também pode ser utilizado para fazer previsões usando dados coletados de tendências passadas e atuais.
Análise e monitoramento
É provável que um cientista de dados também trabalhe com muitos dados para analisar e tirar conclusões inferenciais. Os pipelines de ingestão de dados ajudam nesse caso, pois fornecem dados em um formato que é facilmente categorizado. Posteriormente, isso permite que um analista de dados utilize facilmente as ferramentas de visualização de dados para analisá-los e tirar conclusões de forma eficiente.
Desafios associados à arquitetura de pipeline de dados
Apesar da simplicidade de uma arquitetura de pipeline de dados, ela tem seus desafios. Por exemplo, há desafios como:
Qualidade de dados inconsistente
Um dos problemas mais encontrados nos pipelines de ingestão de dados é a qualidade inconsistente dos dados. Isso pode levar a uma decisão errada e, consequentemente, à instabilidade das operações. Portanto, a arquitetura do pipeline de dados deve ser projetada com determinados componentes que possam medir e monitorar com eficácia a qualidade dos dados. A qualidade dos dados foi definida como dados de alta qualidade se os dados forem:
- Preciso
- Consistente
- Relevante
- Oportuno
- Completo
- Único.
Além disso, a automação do processo de limpeza de dados ajuda a evitar quaisquer erros que possam ser encontrados durante o processo. Portanto, esses componentes devem ser incluídos no pipeline de ingestão de dados para aumentar a relevância do resultado.
Preocupações com segurança e privacidade de dados
Muitos países conseguiram introduzir leis de proteção de dados para garantir a segurança dos dados na era atual de raspagem automatizada da Web. Essas leis também determinam o uso dos dados obtidos on-line. Assim, a adesão a essas leis ajuda a criar confiança com as partes interessadas, os parceiros e os clientes. É essencial proteger os dados contra acesso não autorizado e usá-los em conformidade com a lei. Portanto, é necessário que a arquitetura do pipeline de ingestão de dados incorpore uma criptografia forte para manter a privacidade dos dados.
Escalabilidade
Outro problema enfrentado na ingestão de dados é o dimensionamento, que se refere à capacidade de lidar com grandes quantidades de dados. Quando há um aumento na demanda por dados, há uma necessidade correspondente de que as estruturas de pipeline melhorem seu desempenho. No entanto, existe a opção de usar soluções baseadas em nuvem para melhorar a escalabilidade.
Gargalos de desempenho
Um problema recorrente de desempenho pode surgir devido à complexidade dos dados. Esse problema pode surgir em qualquer estágio da estrutura do pipeline.
Os gargalos de desempenho geralmente começam quando um estágio da estrutura está processando dados em um ritmo mais lento do que o estágio anterior, criando assim um atraso. O planejamento adequado e o uso das ferramentas certas podem ajudar a aliviar esse problema no pipeline de ingestão de dados.
Relação entre pipeline de dados e ETL
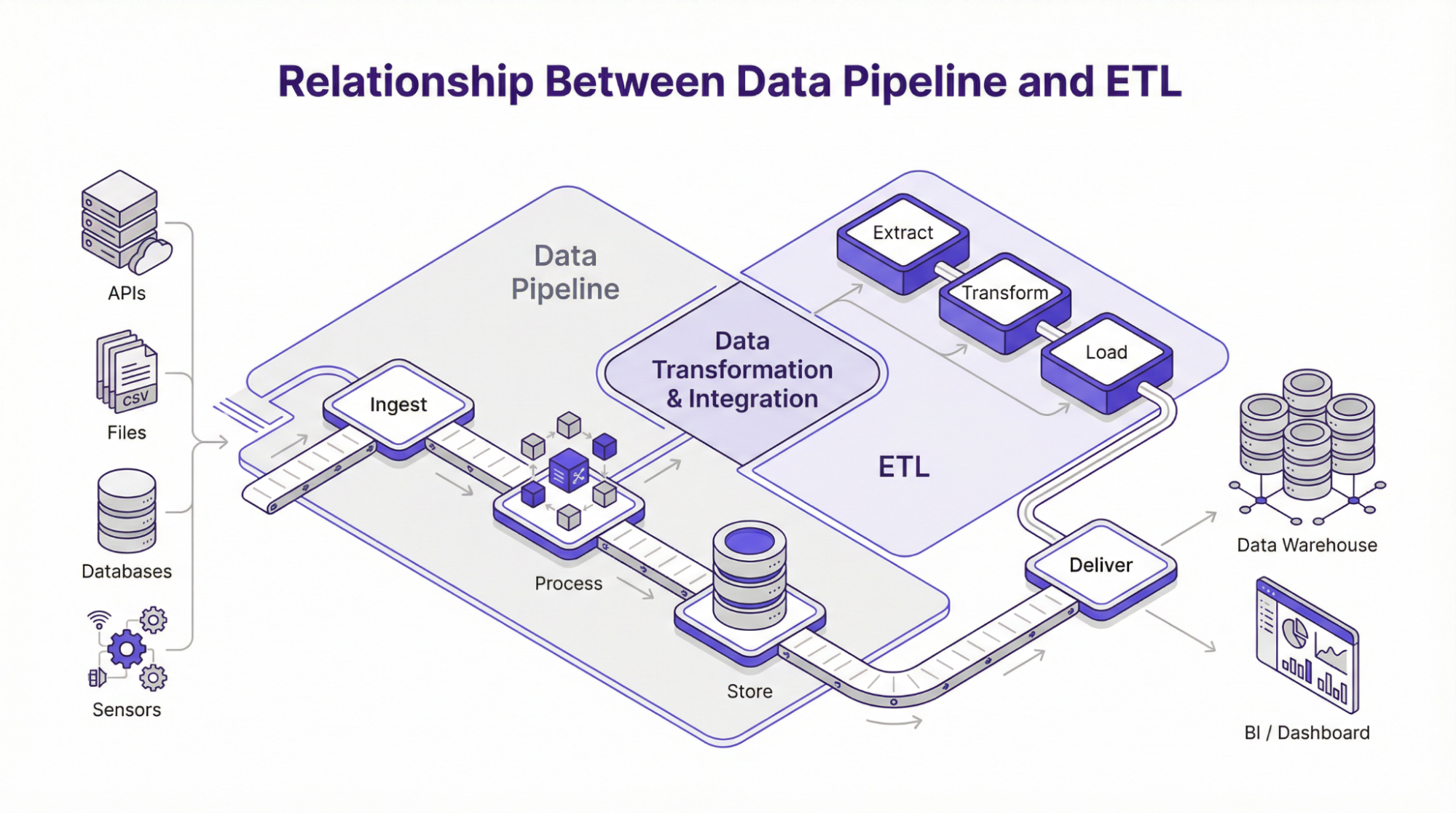
ETL, que significa extrair, transformar e carregar, é um dos métodos mais comuns para criar pipelines de dados. Como o nome sugere, ele define um caminho específico para os dados à medida que eles passam pelo sistema.
Em um pipeline de ETL padrão ou tradicional, os dados são extraídos de várias fontes. Em seguida, são transformados em uma camada de processamento, a partir da qual são carregados em uma unidade de armazenamento de destino, como um data warehouse. Esse processo é usado com frequência em estruturas de processamento em lote, em que os dados são coletados e processados em períodos programados. Além disso, essa estrutura é implementada quando os dados precisam ser validados, formatados ou transformados em um formato estruturado antes do armazenamento. No entanto, a arquitetura moderna de pipeline de dados oferece suporte a outras estruturas, como:
ELT – Extrair, carregar, transformar
O modelo ELT segue o carregamento de dados no armazenamento de destino imediatamente após a extração de várias fontes. Posteriormente, as transformações são realizadas em um período posterior com ferramentas como SQL ou BD. No entanto, a estrutura ELT é geralmente preferida em situações em que a computação e o armazenamento são unidades separadas, como visto em pipelines baseados em nuvem.
ETL reverso
Nessa estrutura, os dados se movem na direção oposta ao que vemos no ETL. Em outras palavras, os dados passam do warehouse para ferramentas externas, como sistemas de suporte ao cliente, modelos de aprendizado de máquina ou CRM. Posteriormente, as empresas podem integrar a análise às operações vinculando os dados do warehouse às ferramentas usadas pelas equipes de suporte, vendas ou marketing. Embora o ETL, o ELT e o ETL reverso movam os dados em diferentes direções, o objetivo permanece o mesmo: extrair dados de onde eles são gerados e enviá-los para onde são necessários. Portanto, a compreensão desses mecanismos de fluxo de dados informa as equipes sobre a melhor abordagem para criar um pipeline de ingestão de dados que seja relevante, dimensionável e esteja alinhado com as metas operacionais.
Considerações finais
As organizações precisam de muitos dados para manter a estabilidade. Ao mesmo tempo, elas estão ocupadas tentando ingerir dados mais rapidamente do que conseguem processá-los. A ingestão de dados é um sistema arquitetônico que pode ajudar a transformar todos esses dados em uma forma útil. Portanto, é eficiente criar um pipeline de ingestão de dados para utilizar recursos de várias fontes.
Alguns dos problemas enfrentados no processo de ingestão de dados incluem a qualidade dos dados, o desempenho, as preocupações com a segurança e o manuseio de grandes quantidades de dados. Apesar de todos esses problemas, é possível facilitar o processo de ingestão de dados usando as práticas recomendadas, como garantir a qualidade dos dados, a escalabilidade da estrutura de ingestão de dados e o monitoramento do desempenho do pipeline de dados.





