


El web scraping de Reddit es el proceso de recopilación de datos disponibles públicamente en la plataforma. Los datos recopilados pueden incluir publicaciones, perfiles, comentarios y mucho más. Recopilar datos de Reddit manualmente puede llevar mucho tiempo, dar lugar a errores y ser ineficaz. Por lo tanto, los investigadores, los vendedores y los profesionales de SEO a menudo automatizan el raspado de Reddit con bots o scripts. La gestión de múltiples cuentas de Reddit para el scraping puede requerir el uso de un proxy. Para facilitar la extracción de datos, Reddit dispone de una API pública. Sin embargo, sus opciones son muy limitadas cuando realiza el scraping de Reddit con la API por un par de razones. En primer lugar, la API implementa límites de velocidad, lo que restringe el número de solicitudes que puedes enviar en un periodo de tiempo. Además, a menudo requiere datos de autenticación, lo que puede ralentizar todo el proceso.
¿Cómo funciona un Reddit Scraper?
Para extraer datos de Reddit, el scraper envía peticiones HTTP a la plataforma. La siguiente fase consiste en analizar las respuestas HTML o JSON. A continuación, se extraen los elementos necesarios, como el ID de usuario o los comentarios. Por último, los datos extraídos se limpian y almacenan en un formato predefinido. Entre los datos disponibles públicamente que se pueden scrapear en Reddit se incluyen:
- Títulos de los puestos
- Nombres de usuario
- Comentarios (hilos y respuestas)
- Puntuaciones ( upvotes y downvotes)
- Metadatos del subreddit
- Marcas de tiempo e historial de ediciones
Algunos de los retos asociados al uso de un scraper de Reddit incluyen CAPTCHAs, IPs bloqueadas, secciones de comentarios anidadas y límites de tasa. Aquí es donde las herramientas optimizadas desempeñan un papel crucial para llevar tus actividades de scraping al siguiente nivel.
Dónde conseguir Reddit Scraper
Los scrapers se pueden clasificar en 2 (dos) grupos: scrapers de código y scrapers sin código. Los raspadores de código utilizan un lenguaje de programación como Python, CSS, Java, etc. para crear un script que automatice la extracción de datos. Esta opción requiere algunas habilidades de codificación y conocimientos técnicos para escribir un código que pueda eludir CAPTCHA y los límites de velocidad para una extracción de datos eficaz. También puedes escribir un script para un raspador de imágenes de Reddit si el objetivo es únicamente extraer imágenes de la página.
Por otro lado, la opción sin código es una solución que no requiere codificación ni amplios conocimientos de lenguajes de programación. Para aquellos que buscan una opción fácil en cuanto a cómo raspar Reddit, las herramientas sin código son muy útiles. Vienen con diferentes características que le permiten extraer datos de plataformas como Reddit en unos pocos pasos. Uno de los lugares más fiables para obtener esta solución de scraping sin código es Floppydata. Esta herramienta optimiza el proceso de obtención de datos de Reddit con funciones que evitan CAPTCHA y prohibiciones de IP para una experiencia sin problemas. La herramienta Web Unblocker de Floppydata es excelente para escalar grandes volúmenes de datos sin necesidad de navegadores de automatización como Selenium, Puppeteer o Playwright.
Floppydata’s Web Unblocker es una herramienta que simplifica el web scraping saltándose bloqueos y CAPTCHAs automáticamente, permitiéndote recopilar datos sin necesidad de automatizar el navegador o configurar un proxy manualmente. Algunas de sus características incluyen:
- Resolución automática de CAPTCHA
- Eludir los mecanismos anti-bot con su avanzada huella digital del navegador
- Extrae datos de sitios web dinámicos de forma eficaz
- Rotación automática de proxy incorporada y lógica de reintento para permanecer en el anonimato.
Otro aspecto a tener en cuenta a la hora de adquirir un rascador es el precio. Floppydata se compromete a proporcionar soluciones de alta calidad a precios asequibles. Por lo tanto, Floppydata ofrece su Desbloqueador Web a precios altamente competitivos. Aunque hay una prueba gratuita, está limitada a 5 (cinco) scraps. Hay cuatro niveles de precios e incluyen:
- Plan de crecimiento – Desde 0,98 $ por 1.000 resultados
- Plan Profesional – Desde 0,75 $ por 1.000 resultados
- Plan de empresa – A partir de 0,60 $ por 1 000 resultados
- Plan Premium – Desde 0,45 $ por 1.000 resultados
- Plan personalizado – Póngase en contacto con el servicio de atención al cliente para obtener un plan personalizado
Ventajas del raspador sin código de Floppydata
- Los usuarios no técnicos pueden utilizarlo con facilidad
- Incorpora funciones de rotación de IP, CAPTCHA y contenidos dinámicos.
- Entrega los datos en formatos como CSV o JSON para facilitar su procesamiento.
- Opciones rentables para particulares y PYME
- Entrega rápida de datos
Contras
- Flexibilidad limitada para la personalización
Otras alternativas al raspado de datos de Reddit
Analicemos brevemente otros métodos que se pueden utilizar para scrapear datos de Reddit:
API oficial de Reddit
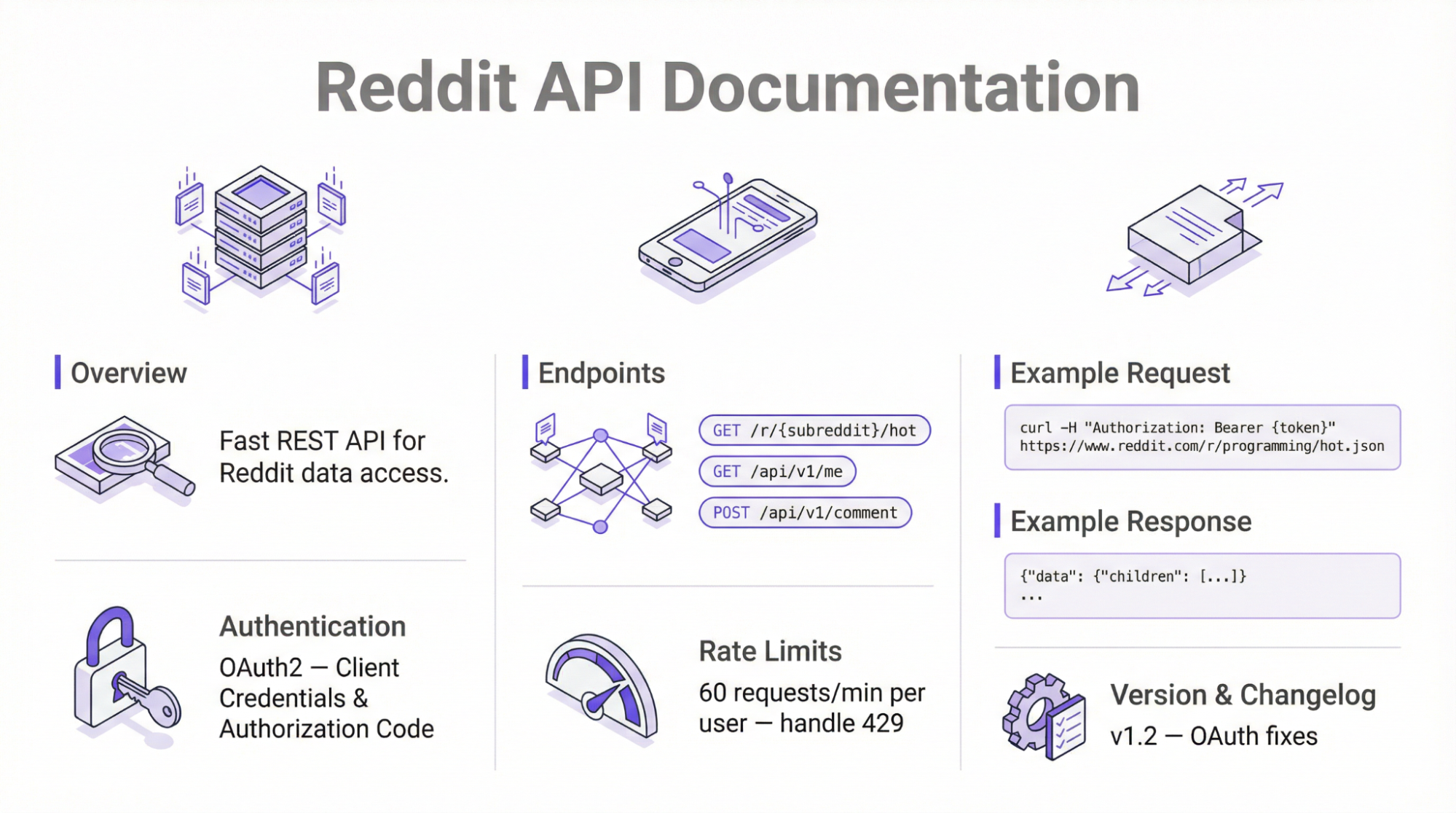
Si quieres hacer scraping de la plataforma sin herramientas de terceros, entonces deberías considerar el uso de la API oficial. Este enfoque utiliza los puntos finales de la API JSON de Reddit para raspar la información disponible públicamente utilizando simples peticiones HTTP.
El uso de la API oficial requiere autenticación OAuth2 y aplica los límites de tarifa: 100 QPM para el nivel gratuito. Según las actualizaciones de política introducidas en 2025, la API requiere la aprobación manual de la plataforma antes de recuperar los datos.
Siga los pasos que se indican a continuación para utilizar la API oficial de Reddit para la recopilación de datos:
- Regístrese para obtener acceso a la API
El primer paso es iniciar sesión en tu cuenta de Reddit o crear una si eres un usuario nuevo. Visita la página de Reddit Apps, haz clic en «crear una app» y sigue las instrucciones que aparecen en pantalla. Una vez hecho esto, aparecerá una nueva ventana con tu ID de cliente, secreto de cliente y cadena de agente de usuario.
- Autenticación
Utiliza OAuth para obtener un token de acceso. Para este paso, puede utilizar una biblioteca de programación, como la biblioteca PRAW de Python, y autenticarse con la API. Alternativamente, puede utilizar la biblioteca de solicitud , que implica el manejo manual de los tokens de acceso.
- Realizar solicitudes HTTP
El siguiente paso es utilizar un marco como la biblioteca de peticiones de Python para enviar peticiones GET a varios puntos finales.
- Analizar y guardar datos
Los datos brutos se extraen y procesan en formato JSON para facilitar su lectura.
N.B: El proceso descrito anteriormente sólo es eficaz para tareas sencillas de scraping. Además, requiere un buen conocimiento de lenguajes de programación y codificación.
Ventajas de la API oficial de Reddit
- Proporciona acceso oficial y fiable a los servidores de Reddit para recopilar datos
- Es una queja a las condiciones de uso de la plataforma
- Riesgo mínimo de prohibiciones siempre que no se supere el límite de tarifa.
- Admite la extracción de datos públicos sin restricciones anti-scraping.
Contras de la API oficial de Reddit
- Los datos son muy limitados
- No apto para personas con escasos o nulos conocimientos de programación.
- Los límites de velocidad dificultan la ampliación del proceso de raspado
- La extracción de grandes volúmenes de datos puede resultar bastante cara
Uso de Python

Python es un lenguaje de programación con una amplia biblioteca que soporta el web scraping. Para el scraping de Reddit, la mayoría de los desarrolladores utilizan PRAW (Python Reddit API Wrapper) para interactuar con el servidor y extraer datos.
Sin embargo, para extraer datos más allá de los límites de la API, se utilizan frameworks como BeautifulSoup. También desempeñan un papel crucial en el análisis sintáctico de datos HTML y su entrega en formato XML o JSON.
La estructura de Reddit cambia con frecuencia, lo que puede afectar al rendimiento del scraper. Por lo tanto, el scraper debe actualizarse periódicamente para adaptarse a las modificaciones de la plataforma.
Buenas prácticas para utilizar un scraper de Reddit en Python
Rotación de la dirección IP
Uno de los principales objetivos de la rotación de direcciones IP es el anonimato. Además, la plataforma puede detectar cuándo se originan solicitudes repetidas desde la misma dirección IP. Esto puede desencadenar un bloqueo de IP, lo que dificulta la recopilación completa de datos.
Gestión de CAPTCHA
Un scraper Python de Reddit no está equipado para manejar CAPTCHAs, que pueden aparecer como una forma de que la plataforma diferencie las actividades humanas de las de los bots. Para evitar los CAPTCHA, utilice navegadores sin cabeza como Selenium, Playwright y Puppeteer para imitar el patrón de navegación humano. Posteriormente, esto dificulta la detección de actividades automatizadas.
Navegadores sin cabecera para gestionar contenidos dinámicos
Al igual que los sitios web modernos, Reddit utiliza JavaScript para cargar contenido dinámico. Los raspadores normales normalmente sólo analizan el contenido HTML y pueden ser incapaces de cargar contenido dinámico. Una forma de manejar esto es integrar navegadores sin cabeza como Selenium
Ventajas de utilizar Python
- Al ser una biblioteca de código abierto, es gratuita.
- Altamente personalizable
- Fiable
Contras del uso de Python Scrapers
- Requiere conocimientos de programación en Python
- Limitado a datos públicos
- Restringido a los límites de la API de Reddit
Casos de uso de Reddit Data
El web scraping de Reddit proporciona acceso a datos que pueden utilizarse para diversos fines. Algunos de los casos de uso más comunes son:
Estudios de mercado
Muchos profesionales recopilan datos de Reddit para realizar estudios de mercado. La información recopilada puede clasificarse y analizarse para comprender el sentimiento del mercado, las tendencias actuales y la reputación de las distintas marcas. Por lo tanto, los datos se pueden interpretar en decisiones que influyen en los anuncios de productos, envases y precios que se adapten al mercado objetivo.
Análisis financiero
La mayoría de la gente desconoce que existe toda una comunidad de expertos financieros en Reddit. Desde temas financieros relacionados con valores, acciones, criptomonedas y mercados internacionales, Reddit alberga un gran volumen de datos. El análisis financiero es necesario antes de realizar cualquier inversión significativa para minimizar el riesgo de pérdidas. Estos datos pueden extraerse, analizarse e interpretarse para comprender las previsiones del mercado y tomar decisiones financieras con conocimiento de causa.
IA y aprendizaje automático
Los datos de Reddit pueden utilizarse para entrenar LLM (Large Language Models) con el fin de mejorar los resultados de búsqueda basados en IA. Los robots de IA sólo pueden rendir tanto como los datos que reciben. Por lo tanto, el gran número de visitantes diarios de Reddit lo convierte en una fuente ideal de datos. Un ejemplo es la IA nativa de Reddit, un LLM que se alimenta de datos de la plataforma para ofrecer páginas personalizadas a cada visitante.
Investigación social
Otro caso de uso de los datos de Reddit es la investigación social. La recopilación de datos de subreddits puede utilizarse para estudios sobre el patrón de interacción humana. La investigación social puede utilizarse para recopilar datos sobre tendencias y opiniones sobre temas como la privacidad y el consentimiento en línea. Además, los datos pueden utilizarse para entrenar a los chatbots para que ofrezcan asistencia 24 horas al día, 7 días a la semana, algo que no sería factible con agentes de asistencia humanos.
Cómo raspar datos de Reddit con Floppydata Web Unblocker
Usar el Desbloqueador Web de Floppydata como un raspador de Reddit es fácil y se puede lograr en pocos pasos. Aquí tienes una guía paso a paso sobre cómo scrapear datos de Reddit con Floppydata.
¡Vamos a ello!
Paso 1: Visita la página de Web Unblocker e inicia sesión para empezar
Paso 2: Inicie sesión en su cuenta de Reddit. Abra una página de resultados de búsqueda con filtros específicos que se ajusten a su caso de uso.
Paso 3: Ve al panel de Floppydata’s Web Unblocker y pega la URL
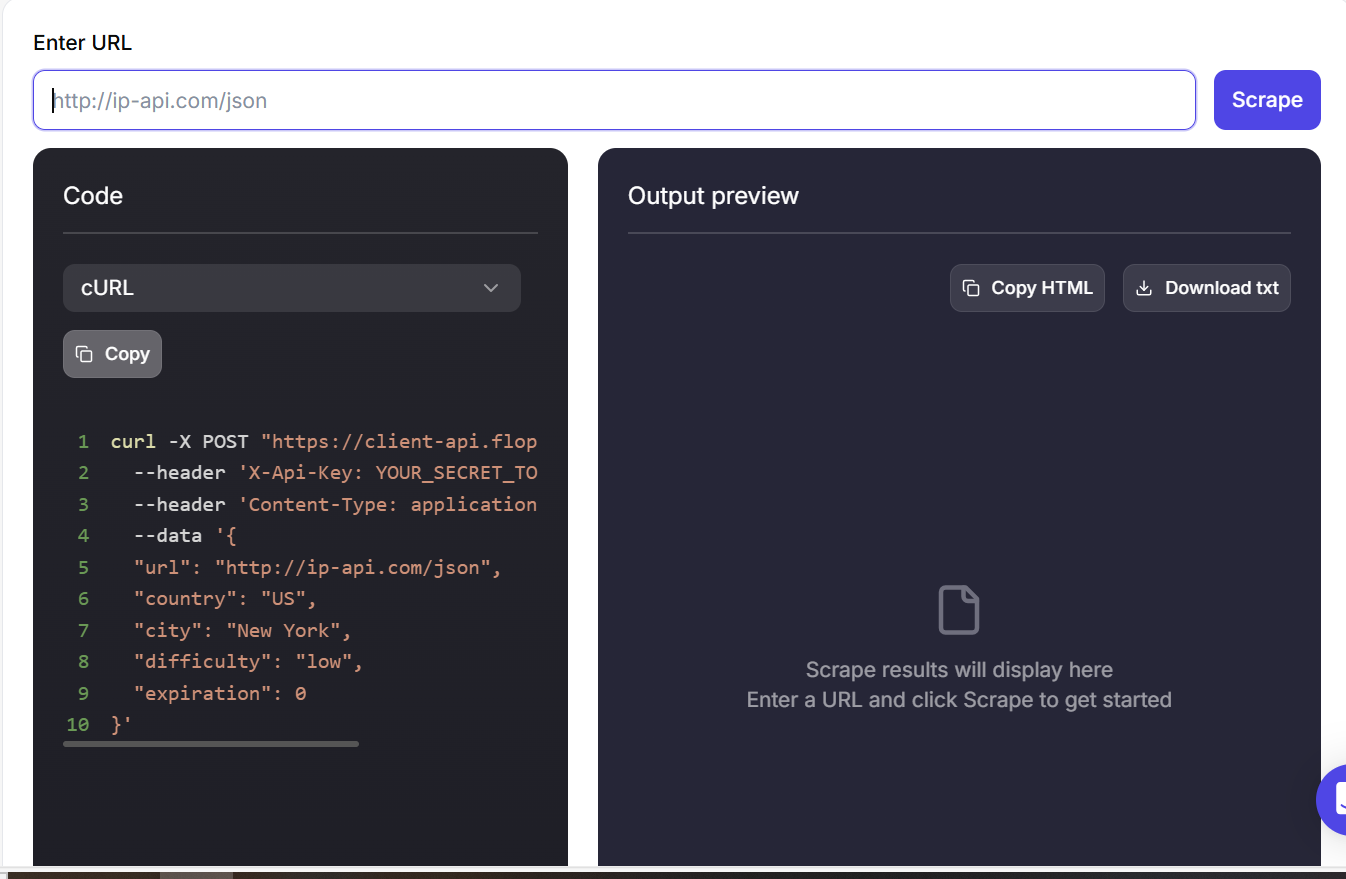
Paso 4: Los resultados estarán listos en unos minutos.
Conclusión
Aprender a scrapear datos de Reddit puede ser un poderoso activo para investigadores, particulares y empresas. Es una forma de recopilar información de una de las comunidades globales más grandes de la web. Para recopilar estos datos, puede escribir un script con un lenguaje de programación o utilizar una solución sin código.
Floppydata ofrece una completa solución de scraping sin código – Web Unblocker, que extrae datos de Reddit de forma efectiva y los entrega en el formato que prefieras. Los nuevos usuarios obtienen hasta 5 sesiones gratuitas para recopilar datos de cualquier plataforma.
Si quieres una experiencia fácil y sin problemas con el scraping de datos de Reddit, ¡prueba hoy mismo el Web Unblocker de Floppydata!





