


En la actualidad, los datos son un activo esencial para muchas organizaciones de diversos sectores. Sin embargo, hay muchas organizaciones que recopilan datos más rápido de lo que pueden procesarlos. Las técnicas de recopilación y manipulación de datos influyen en las decisiones de funcionamiento de las empresas.
Dado que la calidad de la entrada afecta a la salida, es necesario asegurarse de que el sistema recibe datos de buena calidad. Por eso se necesita una buena arquitectura de canalización de la ingesta de datos que favorezca la obtención de información procesable.
Para esta guía, arrojaremos luz sobre las canalizaciones de ingestión de datos, los tipos de ingestión de datos y los casos de uso comunes.
¿Qué es la ingestión de datos?
Una de las preguntas más frecuentes cuando se intenta comprender el proceso de ingestión es «¿qué es la ingestión de datos?»
El término ingestión de datos describe el proceso de recopilación, clasificación y organización de datos procedentes de diversas fuentes en un almacenamiento central, como un datahub o un almacén. Este proceso marca el primer paso en la preparación de los «datos brutos» para su posterior procesamiento e interpretación. La ingesta de datos es un paso muy importante en el proceso, ya que es la etapa en la que se recopilan datos de diversas fuentes que afectarán a la forma en que las empresas obtienen información sobre los productos y ventajas competitivas.
Algunas de las fuentes de datos habituales para la canalización son:
- Bases de datos
- Internet de los objetos
- Centros de datos
- Plataformas de medios sociales
- API
- Terceros proveedores de datos
- Aplicaciones SaaS
Ventajas de la ingestión de datos
Todas las empresas, independientemente de su tamaño, pueden beneficiarse de la ingesta de datos, ya que proporciona información sobre las tendencias del mercado, los sentimientos de los consumidores, las estrategias innovadoras y mucho más. Estas son algunas de las ventajas más comunes de la ingesta de datos:
Disponibilidad de datos
Una de las ventajas de la ingestión de datos es que elimina la necesidad de silos de datos. Esto favorece la disponibilidad de los datos para el análisis al agregar datos de diversas fuentes en una única fuente central.
Escalabilidad
A medida que las empresas crecen, también lo hace su necesidad de datos de buena calidad. Por lo tanto, las canalizaciones de ingestión de datos desempeñan un papel fundamental en la gestión de grandes volúmenes de datos, al tiempo que garantizan su validez, precisión y fiabilidad.
Análisis en tiempo real
Otra ventaja de la canalización de ingesta de datos es que los datos se procesan inmediatamente o por lotes, lo que permite acceder a información actualizada. Como resultado, las empresas pueden reaccionar rápidamente a las tendencias y tomar decisiones oportunas que pueden afectar al margen de beneficio global.
Eficacia
Dado que los conductos de ingestión de datos están automatizados, se elimina la necesidad de manipular los datos manualmente. Esto ahorra tiempo y recursos al agilizar el proceso de importación y almacenamiento de datos mientras el equipo se centra en otras tareas prioritarias.
Tipos de ingestión de datos
Recopilar datos de distintas fuentes en un almacenamiento central parece bastante sencillo. Sin embargo, puede ser un poco más complicado, sobre todo para la canalización de datos. A continuación se presentan los tipos más comunes de ingesta de datos:
Ingestión por lotes
Es el proceso por el que se recoge un gran volumen de datos a intervalos determinados. Estos intervalos pueden ser horarios, diarios o incluso semanales, en función de sus necesidades de recogida de datos. La ingesta de datos por lotes es, por tanto, adecuada para su uso por parte de aquellas empresas que no requieren datos en tiempo real para la toma de decisiones.
Este es el tipo de empresas que pueden funcionar cómodamente y tomar decisiones basadas en actualizaciones periódicas de datos.
Ingestión en tiempo real
Esta técnica requiere que los datos se reciban en el momento exacto en que se crean. Por tanto, esta técnica permite recibir datos frescos, muy importantes para la toma de decisiones. La ingestión en tiempo real ayuda a reducir el retraso entre la recepción y el tratamiento de los datos. Algunos de los casos de uso de datos en tiempo real son la detección de fraudes, el procesamiento de datos de sensores y la actualización de cuadros de mando en tiempo real. El pipeline de ingesta de datos en tiempo real puede procesar los datos en tiempo real o en trozos mientras se extraen. Aunque esta técnica proporciona datos frescos, la gestión de errores y la escalabilidad son cuestiones complejas.
Arquitectura Lambda
La arquitectura Lambda combina la ingesta por lotes y en tiempo real para ofrecer un equilibrio entre velocidad y precisión. Los datos por lotes proporcionan tendencias históricas completas, mientras que los datos en tiempo real ofrecen información sobre las actividades actuales.
El enfoque lambda se utiliza a menudo en situaciones que requieren manejar enormes volúmenes de datos con gran precisión. Posteriormente, permite a las empresas responder rápidamente a los acontecimientos actuales sin perder el conocimiento de los acontecimientos anteriores del mercado.
¿Qué es el Data Ingestion Pipeline?
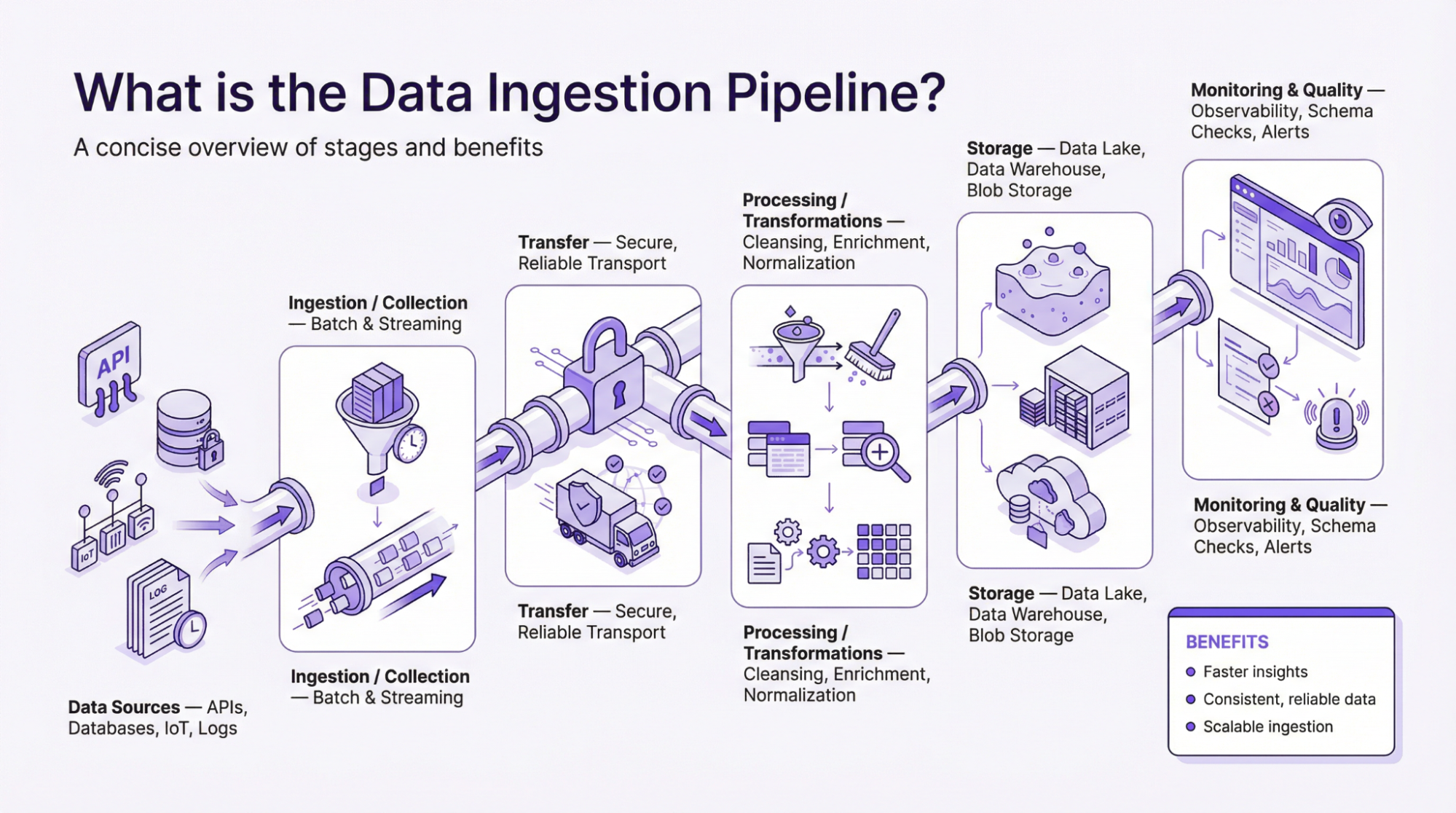
A la pregunta principal de«¿Qué es el pipeline de ingestión de datos?» – El pipeline, a menudo descrito como un marco, describe el flujo de datos desde el punto de recogida hasta que se procesan y aplican para tomar decisiones basadas en pruebas. Un pipeline de datos es simplemente cómo fluye la información de un extremo a otro. Es un conjunto de instrucciones que recoge datos de distintas fuentes, los procesa y los envía a un destino. Por lo tanto, es necesaria una canalización de ingestión de datos adecuada para que las organizaciones utilicen los datos de forma eficaz para impulsar el crecimiento, los beneficios y el retorno de la inversión.
Pasos para crear un proceso eficaz de digestión de datos
A continuación se indican algunos pasos clave para crear un proceso eficaz de digestión de datos:
- Determinar las fuentes de datos: El primer paso para construir un canal de digestión de datos eficaz es identificar la fuente de datos. Antes de definir las fuentes de datos, hay que definir el tipo de datos, el volumen, la velocidad y los objetivos de la organización. Elegir fuentes de datos buenas y sostenibles influye en la precisión y fiabilidad del resultado.
- Elija el destino de los datos: A continuación, debe determinar el destino de los datos. Aquí es donde almacenará todos los datos que obtenga de distintas fuentes. El sistema de destino puede ser un lago de datos, un almacén u otros tipos de almacenamiento, como prefieras.
- Seleccione el método de ingestión de datos: Existen diferentes tipos de métodos de ingestión de datos. Por lo tanto, debe elegir el que mejor se adapte a las necesidades específicas de su empresa. En función de sus objetivos empresariales, puede elegir entre la ingesta por lotes, la ingesta de flujos o una combinación de ambas.
- Diseñar el proceso de ingestión: Este método consiste en determinar cómo se recopilarán, procesarán y almacenarán los datos en el sistema de destino. En el mundo digital actual, el proceso de ingestión se automatiza para promover la eficiencia y reducir los errores humanos. Otra razón para automatizar el proceso es la coherencia. La automatización del flujo de datos en la cadena de suministro garantiza que los datos se muevan de acuerdo con el plan para evitar cuellos de botella.
- Supervisión y mantenimiento: Una vez implementado el proceso de ingesta de datos, es necesario supervisar su rendimiento. Para ello, hay que implementar alertas para las tareas fallidas. Una supervisión periódica ayuda a detectar problemas y a resolverlos rápidamente para garantizar la coherencia en la disponibilidad de los datos.
Arquitectura de canalización de datos
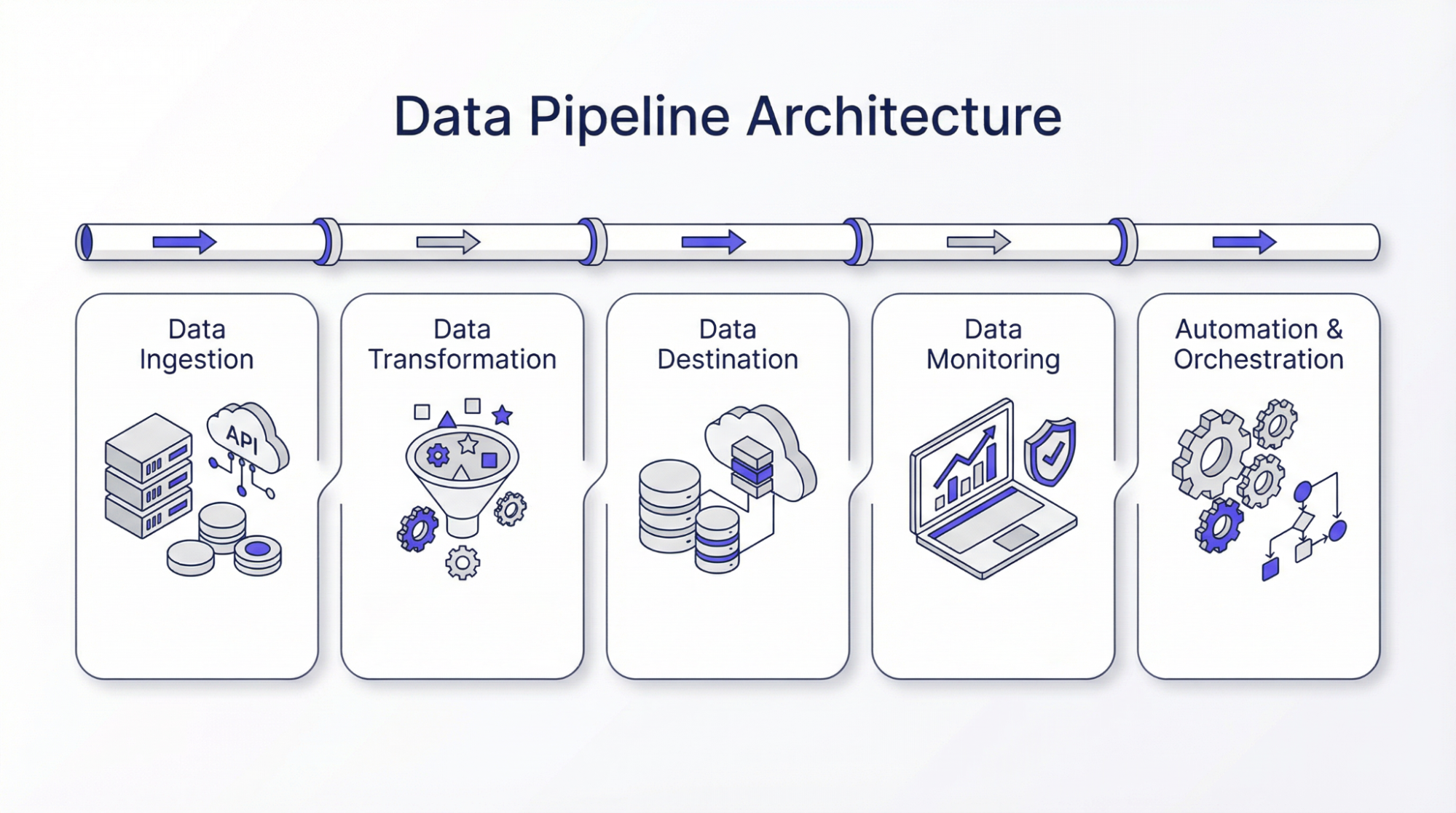
A continuación se describen los pasos de la arquitectura de canalización de datos:
Ingesta de datos
El primer paso en la arquitectura de canalización de datos es la recopilación de datos de diversas fuentes. Los datos de buena calidad son siempre una prioridad, ya que afectan a la autenticidad de todo el proceso. Los datos ingeridos o recopilados pueden ser estructurados o no estructurados en función de la tecnología. Hay quien prefiere recopilar datos sólo cuando es necesario, mientras que hay quien los recopila y los almacena. Esto les ayuda a actualizar sus datos históricos y pueden utilizar los datos para compararlos. En esta fase, se emplean distintos mecanismos para garantizar la fiabilidad y exactitud de los datos. La aplicación de medidas que promuevan la resistencia y la escalabilidad garantiza un rendimiento descendente sin problemas.
Transformación de datos
La transformación de datos es el proceso de transformar los datos a la forma requerida. Este paso es importante, ya que los datos recogidos pueden no tener la misma forma. Por ejemplo, los datos pueden estar en forma JSON, y JSON puede estar anidado. Por lo tanto, el objetivo principal de este paso, o transformación de datos, es desenrollar el JSON para obtener los datos clave para su posterior procesamiento. En otras palabras, la transformación de datos es necesaria para llevar todos los datos a la forma deseada, o mejor dicho, a una forma estándar. El objetivo de la transformación de datos es limpiar, filtrar y aumentar el valor para las decisiones empresariales. Se pueden emplear varios algoritmos, como métodos computacionales, análisis estadísticos o aprendizaje automático, para generar información procesable.
Destino de los datos
Los destinos de los datos son los lugares donde se almacenan los datos procesados en la arquitectura de canalización. Estos destinos pueden ser almacenes de datos, bases de datos en la nube o lagos de datos. La elección de un almacenamiento adecuado es importante, ya que afecta a la facilidad de acceso a los datos. Antes de elegir el destino de los datos, se tienen en cuenta varios factores, como el tipo de datos, el volumen y la finalidad.
Una buena arquitectura de canalización de datos es aquella que garantiza que los analistas puedan acceder fácilmente a los datos desde los destinos. También debe estar diseñada para manejar grandes volúmenes de datos con rapidez y precisión. En esta fase, se aplican las políticas de protección de datos para garantizar su seguridad y cumplimiento.
Supervisión de datos
La supervisión de los datos es necesaria para garantizar el cumplimiento de las políticas y normativas. Esto es necesario para mantener la seguridad y la integridad. Por lo tanto, esta etapa incluye destacar las funciones de gestión de datos, auditoría y aplicación de controles de acceso. El marco de control es crucial para evitar el acceso no autorizado a los datos y el cumplimiento de leyes como el Reglamento General de Protección de Datos. Además, la supervisión de la calidad de los datos es útil para detectar anomalías y errores en el proceso. Por tanto, la aplicación de medidas de validación de datos y detección de errores garantiza la fiabilidad y precisión de los resultados. Además, las herramientas de supervisión proporcionan una visión general del rendimiento de la canalización de datos y detectan problemas para su pronta resolución.
Automatización y orquestación
La orquestación de datos puede definirse como la coordinación del movimiento de datos a lo largo de la canalización. Esto es necesario para garantizar que los procesos se ejecutan de la manera correcta. Estas herramientas activan los flujos de trabajo y gestionan las acciones de recuperación, lo que minimiza la intervención manual. Una buena estrategia de orquestación tiene en cuenta el escalado dinámico, el equilibrio de carga y el procesamiento paralelo. Por lo tanto, desempeñan un papel clave en el rendimiento de las canalizaciones de datos para garantizar un flujo de datos fluido con interrupciones mínimas.
Casos prácticos de ingestión de datos
A continuación se indican varios usos de la ingestión de datos
Detección del fraude en las finanzas
Algunas organizaciones financieras utilizan la arquitectura de integración de datos para detectar y prevenir el fraude. Integrar un sistema robusto de encriptación y mapeo en finanzas es crucial para detectar el fraude. Esto genera más confianza y menos pérdidas financieras.
Aprendizaje automático
El aprendizaje automático es una rama de la IA que utiliza datos para entrenar grandes modelos lingüísticos (LLM) que se utilizan en diversos sectores. El aprendizaje automático también es importante porque utiliza datos para imitar la forma en que los seres humanos razonan, se comunican y resuelven problemas. Además, también puede utilizarse para hacer predicciones utilizando datos recogidos de tendencias pasadas y actuales.
Análisis y control
También es probable que un científico de datos trabaje con muchos datos para analizarlos y extraer conclusiones inferenciales. Las canalizaciones de ingestión de datos ayudan en este caso, ya que proporcionan datos en un formato que se puede categorizar fácilmente. Posteriormente, esto permite a un analista de datos utilizar fácilmente las herramientas de visualización de datos para analizar los datos y sacar conclusiones de manera eficiente.
Retos asociados a la arquitectura de canalización de datos
A pesar de la simplicidad de una arquitectura de canalización de datos, no está exenta de desafíos. Por ejemplo, hay retos como:
Calidad incoherente de los datos
Uno de los problemas más frecuentes de los conductos de ingestión de datos es la calidad incoherente de los datos. Esto tiene el potencial de conducir a una decisión equivocada y, en consecuencia, a la inestabilidad de las operaciones. Por lo tanto, la arquitectura del conducto de datos debe diseñarse con determinados componentes que puedan medir y supervisar eficazmente la calidad de los datos. La calidad de los datos se ha definido como datos de alta calidad si los datos son:
- Preciso
- Consistente
- Correspondiente
- A tiempo
- Complete
- Única.
Además, la automatización del proceso de limpieza de datos ayuda a evitar cualquier error que pueda encontrarse durante el proceso. Así pues, estos componentes deben incluirse en el proceso de ingestión de datos para mejorar la pertinencia de los resultados.
Seguridad de los datos y privacidad
Muchos países han conseguido introducir leyes de protección de datos para garantizar la seguridad de los mismos en la era actual del web scraping automatizado. Estas leyes también dictan el uso de los datos obtenidos en línea. Por tanto, el cumplimiento de estas leyes ayuda a generar confianza con las partes interesadas, los socios y los clientes. Es esencial proteger los datos de accesos no autorizados y utilizarlos de acuerdo con la ley. Por lo tanto, es necesario que la arquitectura del canal de ingestión de datos incorpore un cifrado fuerte para mantener la privacidad de los datos.
Escalabilidad
Otro problema de la ingesta de datos es la escalabilidad, que se refiere a la capacidad de manejar grandes cantidades de datos. Cuando aumenta la demanda de datos, es necesario que los marcos de canalización mejoren su rendimiento. Sin embargo, existe la opción de utilizar soluciones basadas en la nube para mejorar la escalabilidad.
Cuellos de botella en el rendimiento
Puede surgir un problema recurrente de rendimiento debido a la complejidad de los datos. Este problema puede surgir en cualquier fase de la estructura de canalización.
Los cuellos de botella en el rendimiento suelen empezar cuando una etapa de la estructura procesa los datos a un ritmo más lento que la etapa anterior, creando así un retraso. Una planificación adecuada y el uso de las herramientas adecuadas pueden ayudar a aliviar este problema en el canal de ingestión de datos.
Relación entre Data Pipeline y ETL
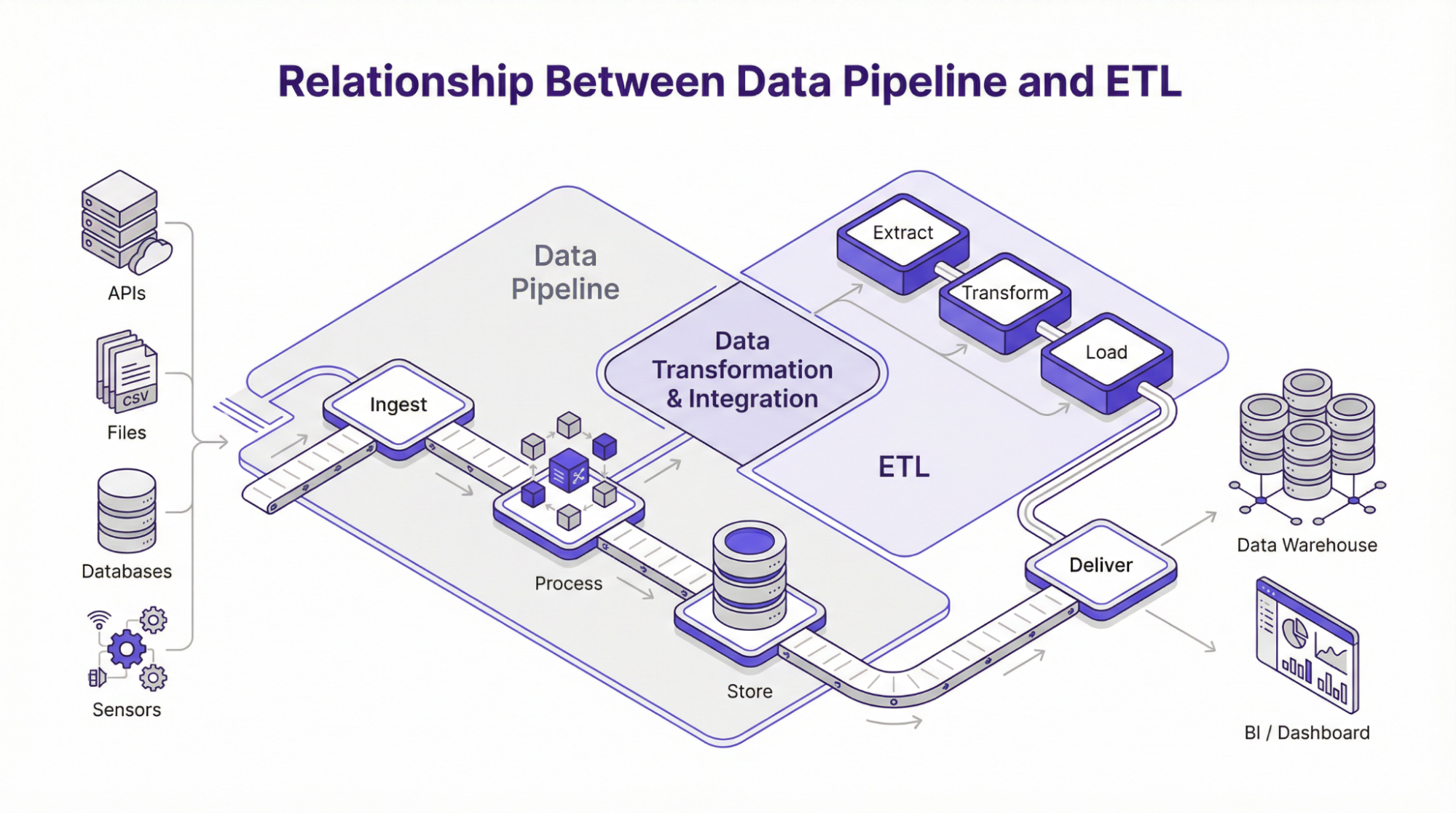
ETL, que significa extraer, transformar y cargar, es uno de los métodos más comunes para construir canalizaciones de datos. Como su nombre indica, define una ruta específica para los datos a medida que se desplazan por el sistema.
En una canalización ETL estándar o tradicional, los datos se extraen de varias fuentes. A continuación, se transforman en una capa de procesamiento, desde la que se cargan en una unidad de almacenamiento de destino, como un almacén de datos. Este proceso suele utilizarse en marcos de procesamiento por lotes, en los que los datos se recogen y procesan en periodos programados. Además, este marco se implementa cuando los datos deben validarse, formatearse o transformarse en un formato estructurado antes de su almacenamiento. Sin embargo, la arquitectura moderna de canalización de datos admite otros marcos, como:
ELT – Extraer, Cargar, Transformar
El modelo ELT consiste en cargar los datos en el almacenamiento de destino inmediatamente después de extraerlos de diversas fuentes. Posteriormente, las transformaciones se llevan a cabo a posteriori con herramientas como SQL o DB. Sin embargo, el marco ELT suele preferirse en situaciones en las que la computación y el almacenamiento son unidades separadas, como se observa en los pipelines basados en la nube.
ETL inverso
En este marco, los datos se mueven en la dirección opuesta a la que vemos en el ETL. En otras palabras, los datos pasan del almacén a herramientas externas como sistemas de atención al cliente, modelos de aprendizaje automático o CRM. Posteriormente, las empresas pueden integrar el análisis en las operaciones vinculando los datos del almacén a las herramientas utilizadas por los equipos de soporte, ventas o marketing. Aunque ETL, ELT y ETL inversa mueven los datos en diferentes direcciones, el objetivo sigue siendo el mismo: extraer los datos de donde se generan y enviarlos a donde se necesitan. Por lo tanto, la comprensión de estos mecanismos de flujo de datos informa a los equipos sobre el mejor enfoque para construir una canalización de ingestión de datos que sea relevante, escalable y se alinee con los objetivos operativos.
Reflexiones finales
Las organizaciones necesitan muchos datos para mantener la estabilidad. Al mismo tiempo, están ocupadas intentando ingerir datos más rápido de lo que pueden procesarlos. La ingestión de datos es un sistema arquitectónico que puede ayudar a transformar todos estos datos en una forma útil. Por lo tanto, es eficiente crear una tubería de ingestión de datos para utilizar recursos de múltiples fuentes.
Algunos de los problemas que se experimentan en el proceso de ingestión de datos son la calidad de los datos, el rendimiento, los problemas de seguridad y el manejo de grandes cantidades de datos. A pesar de todos estos problemas, es posible hacer que el proceso de ingestión de datos sea fluido utilizando las mejores prácticas, como garantizar la calidad de los datos, la escalabilidad del marco de ingestión de datos y la supervisión del rendimiento del canal de datos.





